 夜雨聆风
夜雨聆风





我翻了 Codex App的插件后,开始相信 skills pipeline 才是 AI 系统的主线
今天群里在聊 Agent。有人强调线程、脚本集群、专事专办;也有人说 Skill 里照样有身份和角色。这个分歧最后会落到一个更硬的问题上:AI 系统的核心组织单元,到底是角色,还是一条由 skills 组成的 pipeline?
我今天真正被说服,不是因为又看到一套 Agent 叙事,而是因为我顺手翻了本机这段目录:
~/.codex/plugins/cache/openai-curated
这段目录里放的是 Codex 官方挑选并同步到本机的那批插件。每个插件下面还有一层 skills/。我原本以为会看到“架构师”“测试负责人”“部署专家”这类名字,结果没有。
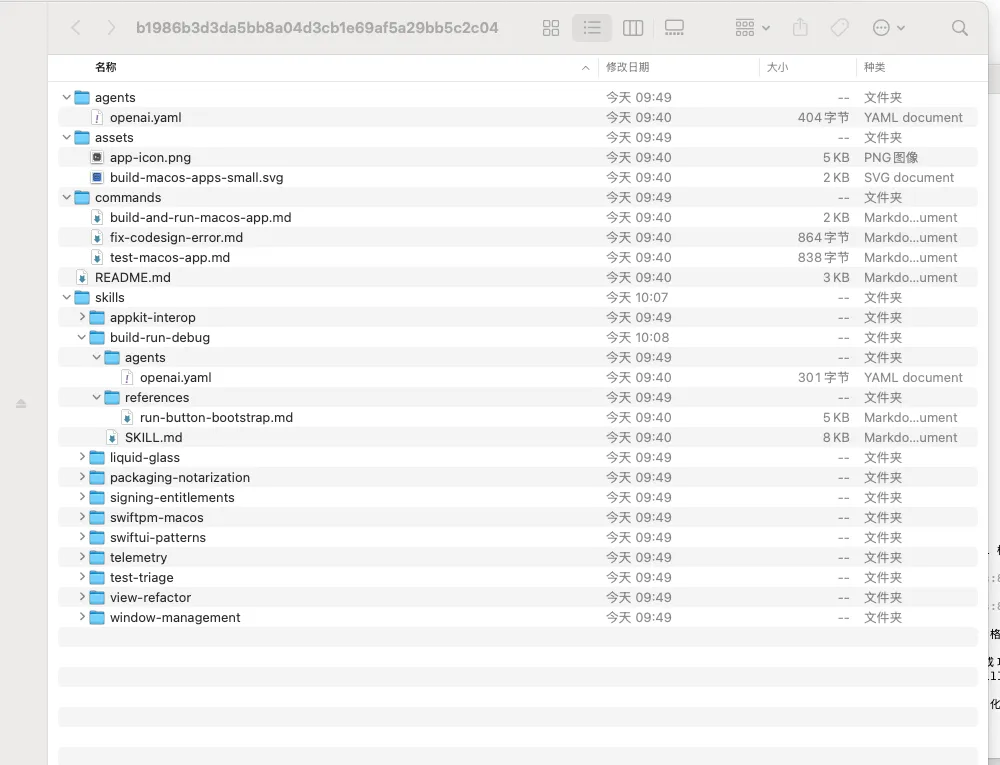
build-macos-apps 下面是 test-triage、window-management、signing-entitlements、packaging-notarization。render 下面是 render-debug、render-monitor、render-deploy、render-workflows。plugin-eval 下面是 evaluate-skill、evaluate-plugin、improve-skill、metric-pack-designer。
这些名字几乎都不是“你是谁”,而是“你现在要处理什么问题”。这不是命名细节,而是两条路线的分叉:
-
• 一条路线按岗位组织,让 AI 扮演产品、架构、开发、测试,再在这些角色之间传递任务。 -
• 另一条路线按能力组织,让 AI 调用一串 skill,由运行时把它们排成 pipeline。
我的判断很明确:单个 Skill 当然重要,但真正的主线是 skills pipeline。
。
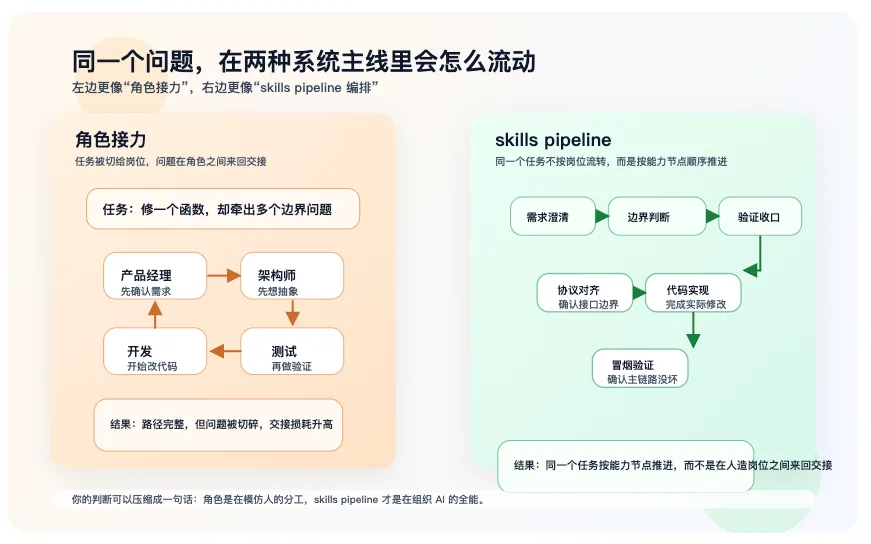
一、为什么“角色型 Agent”会这么自然地流行起来
角色型 Agent 很自然,因为人类组织就是按岗位分工的。但这套直觉直接平移到 AI 上有个问题:人类需要岗位,是因为能力分散;AI 的问题却不是能力不够,而是能力过宽、边界不稳。
所以重角色设定经常只是风格约束,不是治理约束。真正决定它会不会跑偏的,通常不是“它像谁”,而是:
-
• 这次到底要解决什么问题 -
• 需要读什么上下文 -
• 按什么步骤推进 -
• 哪些边界不能越 -
• 最后产出什么
这些东西更像 Skill,也更适合被接成 pipeline。
二、Codex 真正给我的启发,不是单个 Skill,而是它背后的 pipeline 倾向
真正让我确认这一点的,不只是名字,而是 SKILL.md 里面的写法。(点击展开原图)
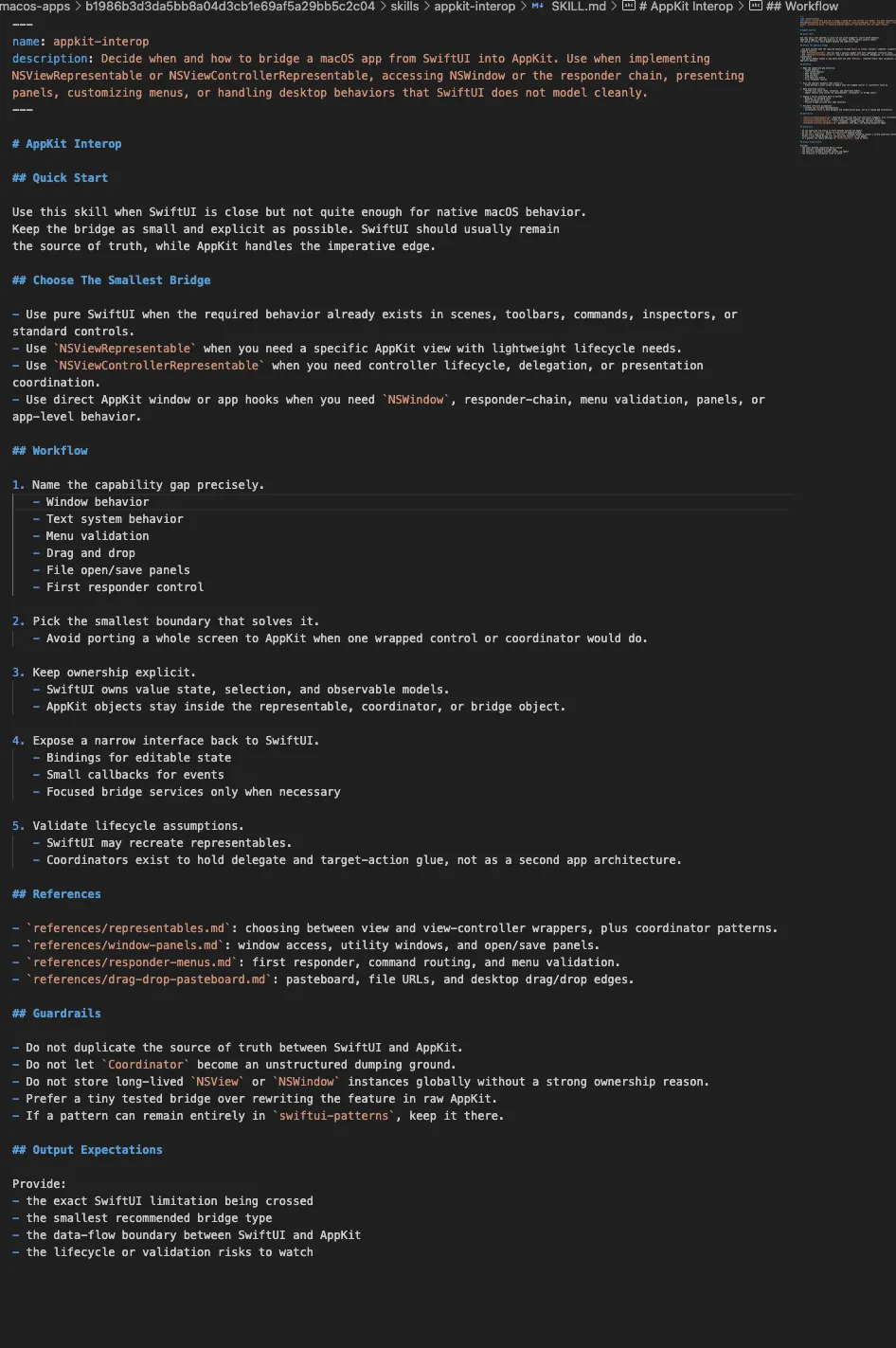
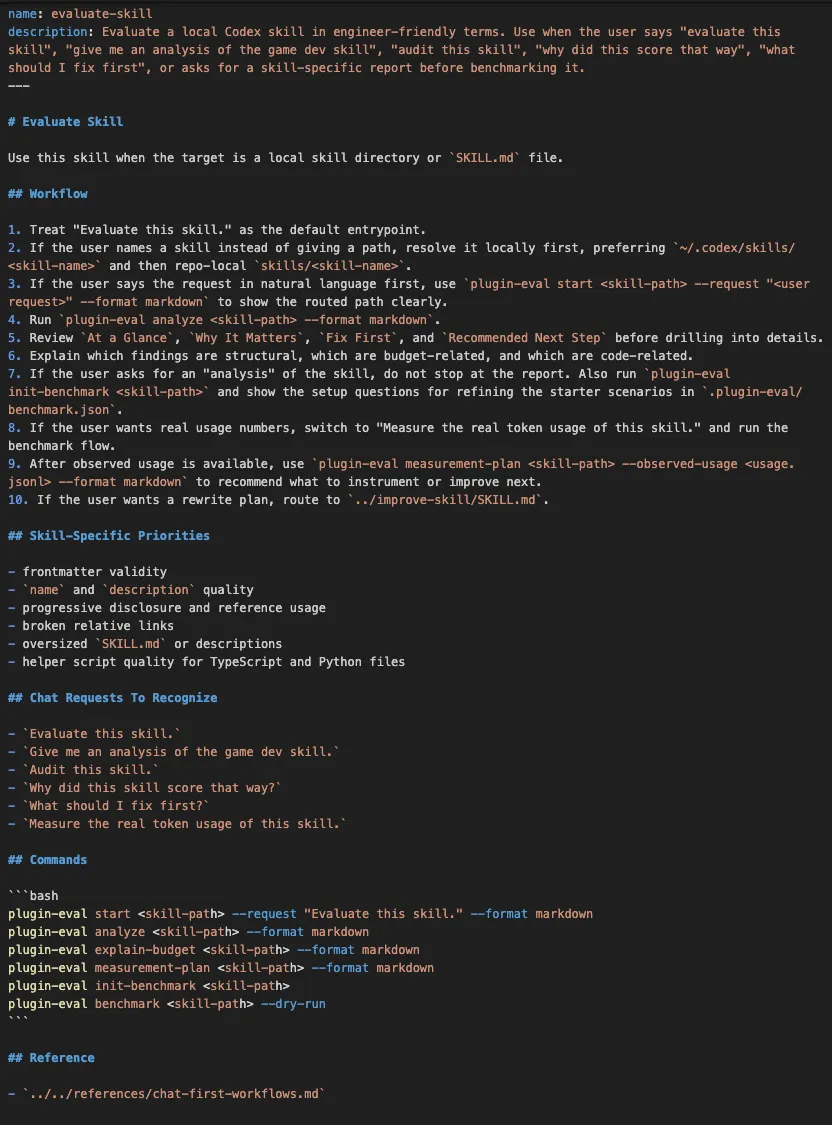
比如 test-triage,重点不是“扮演测试工程师”,而是识别 harness、缩小范围、分类失败、决定重跑。evaluate-skill 也一样,重点是定位目标、执行评估、读取结果、决定下一步。
 |
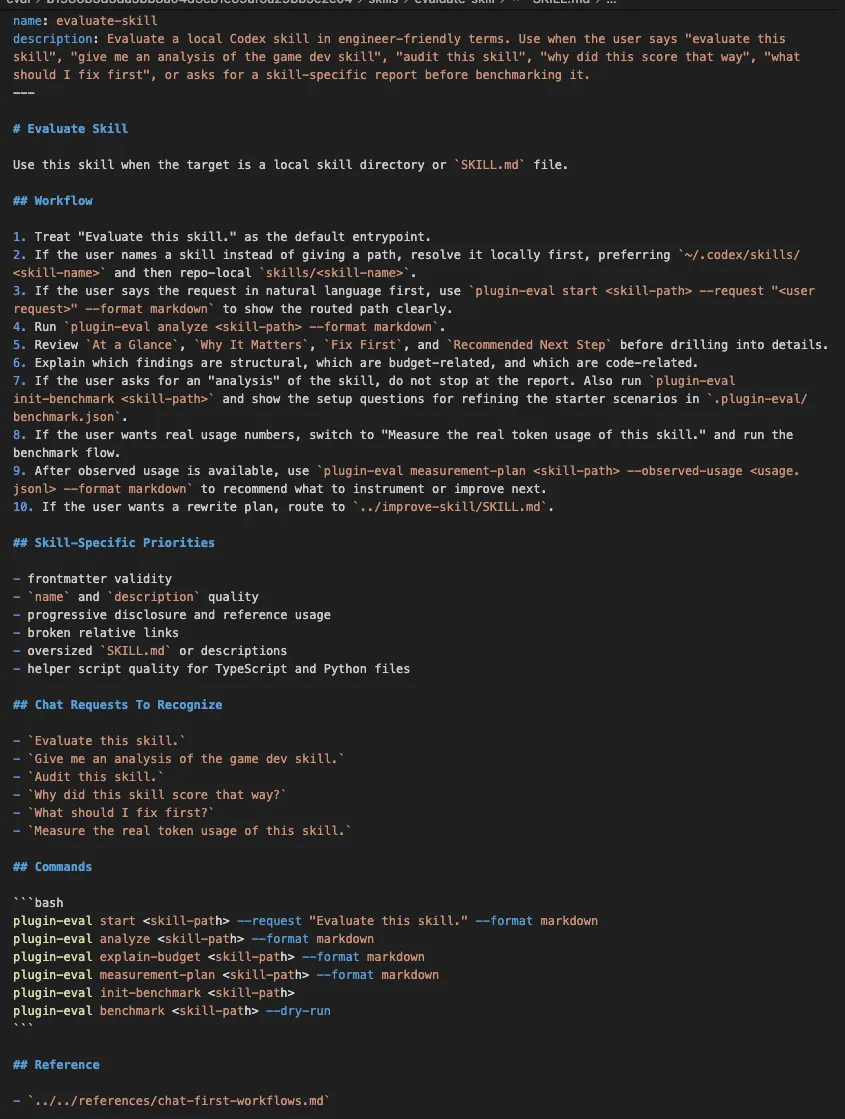 |
想详细的可以下载Codex App 桌面端,然后安装插件查看。
这说明 Codex 生态里被沉淀下来的,不是人格,而是工作流。长期资产不是“某种说话方式”,而是“某类问题该怎么处理”。这些处理方式一旦能被稳定调用、稳定组合,就会自然长成 pipeline。
这也是角色型 Agent 最容易出问题的地方:它让任务在人造岗位之间反复交接。代码世界里的问题却天然跨边界。你改一个函数,可能同时碰到协议、状态、测试、构建、权限。需要的不是角色接力,而是把这些边界按能力节点串起来。
三、Google 那篇 Skill 设计模式文章往前推一层
Google Cloud Tech 那篇《5 Agent Skill design patterns every ADK developer should know》[1] 其实也在往同一个方向走。它的重点已经不是 SKILL.md 格式,而是 Skill 里面的内容设计。Google 总结了五种模式:
-
• Tool Wrapper -
• Generator -
• Reviewer -
• Inversion -
• Pipeline
这篇文章的意义在于,它已经默认接受了一件事:真正值得设计的,不是角色设定,而是 Skill 结构。
但我想再往前推一步:单个 Skill 的模式只是单点设计,真正决定交付质量的是这些模式如何接成 skills pipeline。下一步的竞争,不只是 skill design,而是 pipeline design。
四、研究结论也在往同一个方向收敛:Persona 不是稳定增益
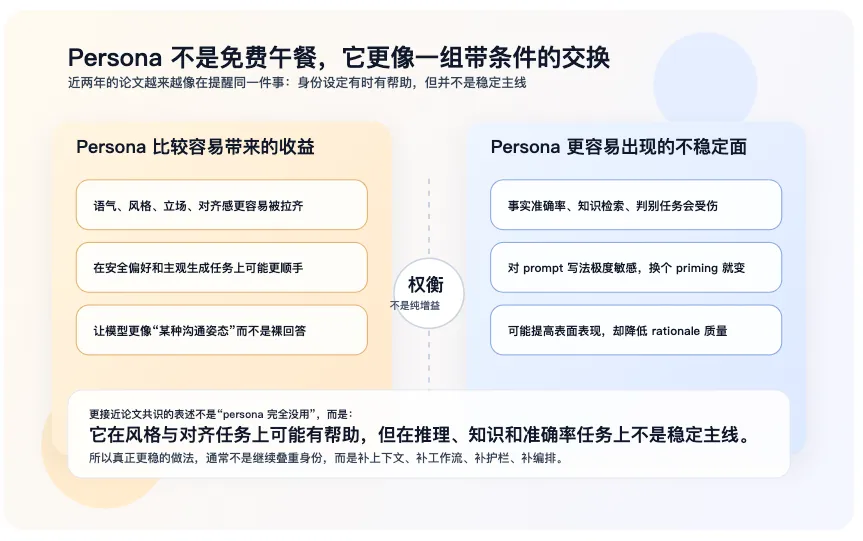
如果这只是工程直觉,还不够。我后来顺着“重身份设定是不是负优化”去翻论文,发现近两三年的结论也很一致:persona prompting 不是稳定、普适、无副作用的增强手段。
最直接的一篇,是 2026 年 3 月的 arXiv 论文《Expert Personas Improve LLM Alignment but Damage Accuracy: Bootstrapping Intent-Based Persona Routing with PRISM》[2]。这篇论文的结论几乎可以直接翻译成一句人话:专家 persona 对对齐型、生成型任务可能有帮助,但它会明显伤害判别型任务和事实准确率。换句话说,身份设定不是没有收益,而是它的收益和代价是绑在一起出现的。
再往前看,2024 年 EMNLP Findings 的论文《When “A Helpful Assistant” Is Not Really Helpful: Personas in System Prompts Do Not Improve Performances of Large Language Models》[3] 做得更朴素也更有说服力。作者系统评测了 162 个角色、2410 个事实问题,最后得到的结论并不复杂:在客观任务上,把 persona 放进 system prompt 里,并不能稳定提升表现。
2025 年还有两篇很值得放在一起看。一篇是《Persona is a Double-Edged Sword: Rethinking the Impact of Role-play Prompts in Zero-shot Reasoning Tasks》[4],标题已经把态度说得很清楚了,persona 是双刃剑。另一篇是《The Prompt Makes the Person(a): A Systematic Evaluation of Sociodemographic Persona Prompting for Large Language Models》[5],它进一步说明,这类 persona prompt 对写法极其敏感,稍微换一种 priming 方式,结果就会明显变化。这意味着它不是一个特别稳定的控制变量。
2026 年 EACL 的《Persona Prompting as a Lens on LLM Social Reasoning》[6] 又把问题往前推了一步。它发现 persona prompting 在某些更主观的社会推理任务上可能提高分类表现,但同时会降低解释质量,而且并不能真正消除底层偏见。
合在一起看,结论很明确:身份设定在风格、立场、对齐类任务上可能有帮助,但在事实准确率、知识检索、推理和判别任务上并不稳定,甚至经常带来副作用。它不是系统的第一性组织单元。
五、很多 Skill 里也有角色描述?
这个反驳成立一半。很多 Skill 里确实会有 debugger、reviewer 这类词,但这不等于系统是按角色组织的。关键不在于文案里有没有角色词,而在于系统最后拿什么作为稳定复用的抽象单元。
从 Codex 这批插件来看,真正稳定存在的不是岗位,不是人格,而是能力边界、问题域和工作流。角色词只是辅料,不是主菜。
六、所以“skills pipeline 更重要”
我在群里说过一句话:Agent 是底层,skills runtime 才是基础。
更完整地说:
-
• Agent解决执行问题 -
• Skill解决边界问题 -
• Runtime解决组合问题
真正对外体现为生产力的,不是某一个 Skill,而是三者共同形成的 skills pipeline。
这个分层的意义在于:不要把所有期待都压到 Agent 这个词上。它只是执行器。真正值得产品化和治理化的,是 Skill 与 Runtime;而两者一旦被接成可复用、可组合、可验证的执行链,表达出来的就是 skills pipeline。
七、AI coding 我会建议先拆 skills pipeline
如果你在做 AI Coding 系统,最该先问的不是“要不要做前端 Agent、测试 Agent、运维 Agent”,而是:
-
• 高频任务是什么 -
• 最容易失控的边界是什么 -
• 哪些问题必须有固定工作流 -
• 哪些输出必须有格式和护栏
顺着这几个问题拆出来的,通常不会是岗位名,而会是 code-review、test-triage、release-check、incident-debug 这类能力节点。再往前一步,你真正要设计的也不是一堆孤立 Skill,而是它们如何接力、并行、收口,也就是一条 skills pipeline。
就拿笔者正在开发的 Lime[7] 来说,真正要拆的也不是“几个开发岗位”,而是从需求判断、产品定义、协议边界、实现验证,到发布、观测、治理收口的一整条 pipeline。
八、这套观点并不只适用于 AI Coding
这套方法不只适用于 AI Coding。任何天然跨阶段、跨边界、跨反馈闭环的复杂工作,都更适合被拆成 skills pipeline。
比如 AI 产品从 0 到 1,就不是“产品经理提需求,设计师出稿,开发实现,运营推广”这么简单。它更像是从机会洞察、产品定义、原型构建、验证上线到增长迭代的一整条 pipeline:
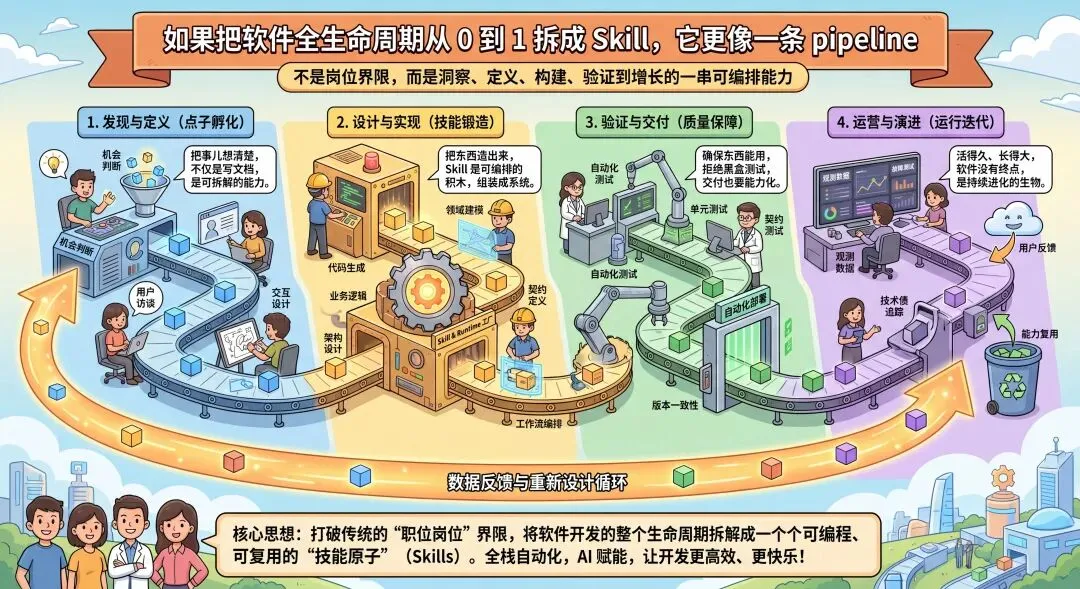
内容生产也一样。它不是“一个会写的人”完成的,而是选题判断、资料核验、结构写作、视觉包装、平台分发、反馈复用组成的内容 pipeline:
甚至连创业公司 CEO 这件事,也不是“当老板”这么抽象,而是战略、产品、组织、收入、财务这些高杠杆能力的组合:
所以真正有价值的,不是给 AI 发明更多好听的岗位名称,而是把那些本来被岗位包住的复杂工作,重新拆回它们真实的 skills pipeline。
九、总结一下:
-
我的结论很简单: -
• Agent更像基础设施 -
• 单个 Skill只是能力切片 -
• skills pipeline才是最终面向交付的主线
角色当然有用,它可以约束语气、风格和对齐感;但如果目标是稳定交付、边界清晰、长期复用,主线不该是继续堆身份设定,而是把能力拆细、把工作流写清、把护栏做实,最后接成 pipeline。
PS:笔者正在开发的 Lime[7] 正是朝这个方向走的一套系统。也正因为自己就在做这件事,所以我会对 Agent、Skill、Runtime 这些边界格外敏感。
引用来源
-
1. https://x.com/GoogleCloudTech/article/203395357982475885 -
2. https://arxiv.org/abs/2603.18507 -
3https://aclanthology.org/2024.findings-emnlp.888/ -
4. https://aclanthology.org/2025.findings-ijcnlp.51/ -
5. https://aclanthology.org/2025.findings-emnlp.1261/ -
6. https://aclanthology.org/2026.eacl-long.52/ -
7. Lime 项目仓库 -
https://github.com/limecloud/lime/