 夜雨聆风
夜雨聆风





技术解析|Daft v0.7.5:插件系统、5倍速Parquet与实时查询调试器

本文翻译自 Daft
作者:Daft Team

通过稳定 C ABI 实现的原生扩展、实时查询仪表盘,以及对嵌套类型的 Parquet 读取速度提升 2-5 倍
作者:Daft 团队
过去,扩展一个数据引擎通常意味着需要分叉源码、接管内部类型,并祈祷下一个版本不会破坏你的补丁。Daft v0.7.5 改变了这一切。该版本通过稳定的 C ABI(应用程序二进制接口)提供了一个原生扩展框架——这种插件系统曾将 PostgreSQL 和 DuckDB 从数据库转变为生态系统。再加上实时查询仪表盘,以及对嵌套类型实现 2-5 倍速度提升的 Parquet 读取能力,v0.7.5 标志着 Daft 开始成为你可以在其之上构建的基础设施。
通过稳定 C ABI 实现的原生扩展
任何能够生成与 C 兼容的共享库的语言,现在都可以扩展 Daft 的查询引擎。
该扩展框架由 @rchowell 设计,并参照了 PostgreSQL 的扩展系统,引入了五个新的包来定义扩展边界,并建立了一个稳定的二进制接口契约。数据使用 Arrow C Data Interface 跨越扩展边界——零拷贝、无序列化开销。
从 Python 侧来看,效果如下:
import daftimport hello # your pip-installable extension packagedaft.load_extension(hello)df = daft.from_pydict({"name": ["John", "Paul"]})df = df.select(hello.greet(df["name"]))
该版本附带两个示例扩展:`hello`(一个教程)和 `dvector`——一个作为原生扩展、为 Daft 带来向量操作的 pgvector 克隆。第二个示例就是有力的证明:曾驱动 PostgreSQL 向量生态系统的同一模式,如今也能在分布式 DataFrame 引擎中发挥作用。
这一功能由 3,774 行新代码实现。这绝不是一个原型。
实时查询仪表盘
如果你曾盯着进度条思考究竟是哪个操作符真正拖慢了速度,那么这个版本就是为你准备的。@samstokes 提交了三个 PR,将 Daft 仪表盘彻底改造为一个实时查询调试器:
– 交互式计划树—— 优化前后的查询计划以可折叠树的形式呈现,而非原始 JSON。节点按操作符类型进行颜色编码。点击任一节点即可查看其谓词、投影、排序键或连接条件。
– 实时操作符统计—— 物理计划树显示每个节点的输入/输出行数,在执行过程中实时更新。边框颜色反映操作符状态:橙色表示执行中,绿色表示已完成,红色表示失败。
– 挂钟时间和 CPU 耗时—— 每个操作符卡片现在都显示实时更新的挂钟持续时间(在执行过程中不断跳动),展开统计区域还可查看 CPU 时间。无需接入性能分析器,你就能准确知道查询时间花在哪里。
– 查询结果预览—— 仪表盘中新增的“结果”选项卡允许你直接查看查询输出,因此你可以在查看执行计划的同时验证结果,无需切换回笔记本或终端(#6327)。
你可以在树视图、表格和 JSON 模式之间切换,选择自己偏好的调试方式。原有的进度表仍然存在,只是它不再是唯一的选择。
Parquet 读取:嵌套类型速度提升 2-5 倍
@desmondcheongzx 为 `arrow-rs` Parquet 读取器实现了延迟物化,其基准测试结果值得反复品味。
– 过滤下推:Daft 不再先解码所有列再在读取后进行过滤,而是首先仅解码谓词列,评估过滤条件,然后仅对匹配的行解码其余列。在 1% 的选择率下(点查的常见情况),过滤读取比旧的 `parquet2` 读取器快 2.1-2.6 倍。
– 嵌套类型:`arrow-rs` 读取器在处理结构体(struct)、映射(map)和列表(list)时的速度显著提升:
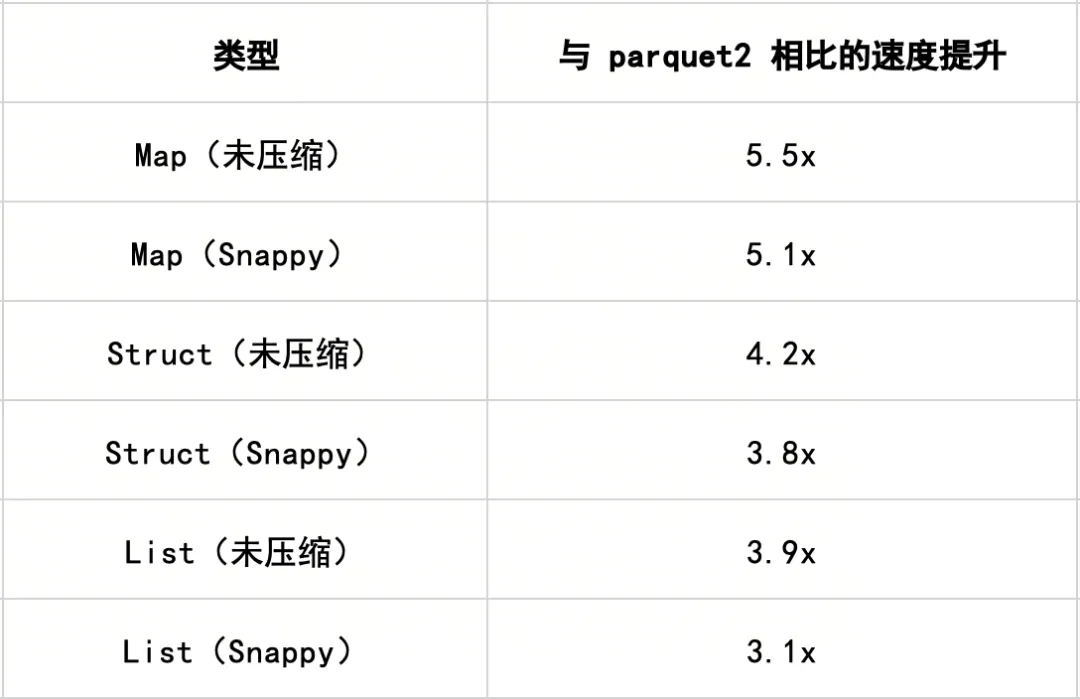
页面索引(page index)已针对本地读取启用,因此行级过滤可以基于页面级的最大值/最小值统计信息,直接在列块内跳过整个页面。Iceberg 的位置删除(positional delete)也得到了高效处理——删除的行在解码期间即被跳过,而非在之后进行掩码处理。
并行流处理路径也已落地:每个行组的解码作为异步任务进行分发,并行处理数量上限为可用的 CPU 核心数(`num_cpus.min(num_row_groups)`)。
write_sql:SQL 故事至此完整
之前你可以从 SQL 数据库中读取数据。现在,你还可以将数据写回。
@huleilei 实现了 `DataFrame.write_sql()`——一个构建在 SQLAlchemy 之上的分布式 SQL 数据写入器:
df.write_sql(table_name="results",conn="postgresql://user:pass@host/db",write_mode="overwrite", # or "append" or "fail"dtype={"embedding": Vector(384)}, # explicit SQLAlchemy types)该实现处理了其中的难点:驱动侧的表初始化、工作器侧采用独立连接生命周期(无套接字序列化问题)的并行写入,以及当你需要精确控制目标 schema 时提供的显式 `dtype` 参数。支持 PostgreSQL、SQLite 以及 SQLAlchemy 能够连接的任何其他数据库。
parquet2 的终结
从这个版本开始,Daft 的 Parquet 读取器将完全过渡到 `arrow-rs`。
来自 @desmondcheongzx 和 @universalmind303 的六个重构 PR 彻底移除了 `parquet2` 读取管线,并使 `arrow-rs` 成为默认读取器。CSV 读取器、JSON 读取器以及函数序列化层也完成了迁移。`DaftParquetMetadata` 适配器现在将下游 crate 与 `parquet2` 的类型解耦。
这在实践中的意义是:Daft 的 I/O 层现在与 Rust 数据生态系统的其他部分使用相同的 Arrow 方言。随着此迁移过程中的每一个 PR 落地,与 `arrow-rs`、DataFusion 以及其他 Apache Arrow 项目的兼容性变得愈发简单。
由于这是一个核心子系统的完整移植,我们希望能听到你的反馈。如果你遇到任何破坏性的行为变化、性能回退,或者——同样有价值的是——在你的工作负载上出现意想不到的速度提升,请在 Daft 的 GitHub 仓库中提交 issue。来自真实世界的反馈将直接决定后续工作的优先级。
其他改进
– `read_text` API —— 新增 `daft.read_text()` 函数,用于将文本文件读入 DataFrame,作为对现有 `read_csv`、`read_json` 和 `read_parquet` API 的补充(#6111)。
– 并行化图像操作 —— 图像解码与转换操作现在使用 `rayon` 进行并行执行,提升了多核机器上的吞吐量(#6333)。
– 移除 11 个依赖 —— @universalmind303 内联了小型工具 crate,并移除了 11 个传递性依赖,缩减了构建图并减少了编译时间(#6364)。
– glob 中的数值范围扩展 —— glob 模式现在支持数值范围(例如 `file_{1..10}.parquet`),使得在不逐个列出每个文件的情况下也能更方便地定位特定分区(#6127)。
– 异步 UDF 的 `max_concurrency` 修复 —— 异步 UDF 上的 `max_concurrency` 参数现在能正确限制并行度,而不再被静默忽略(#6302)。
– 零拷贝 URL 上传 —— @universalmind303 通过创建对底层 Arrow 缓冲区共享所有权的 `bytes::Bytes` 切片,消除了 `url_upload` 中每行的内存拷贝。之前每一行在上传前都会被完整复制到一个新的 `Vec<u8>` 中。
– Lance 惰性导入 —— `import daft` 不再急切地加载 Lance 库,从而减少了启动时间。Lance 用户需要显式触发导入。
– 人类可读的查询名称 —— @samstokes 将基于 UUID 的查询标识符替换为人类可读的名称,使日志和仪表盘更易于追踪。
– `write_sql` 查询名称 —— @plotor 在 `EXPLAIN` 输出中添加了 Python 函数数据源信息,因此你在调试查询计划时可以准确看到是哪个 Python 函数生成了你的数据。
– 破坏性变更:`stddev` 默认改为 `ddof=1` —— @aaron-ang 使 Daft 的 `stddev` 与 pandas 和 numpy 的惯例保持一致。样本标准差现在是默认值。如果你需要总体标准差,请显式传入 `ddof=0`。
社区贡献
本版本的实现离不开社区的贡献:
– @singularityDLW —— glob 中的数值范围扩展、Azure Blob 连接池修复、SQL 中重复 CTE 的拒绝
– @huleilei —— `write_sql` 分布式 SQL 写入器、Lance 分布式标量索引支持
– @plotor —— `EXPLAIN` 输出中的 `write_sql` 查询名称
– @aaron-ang —— `stddev` 的 `ddof=1` 对齐
– @yewleb —— 工作区 lint 继承
升级
uv add "daft>=0.7.5"或尝试最新的 nightly 版本:
uv pip install daft --pre --extra-index-url https://nightly.daft.ai请查看完整的更新日志https://github.com/Eventual-Inc/Daft/releases/tag/v0.7.5以获取所有变更的详细列表。
