 夜雨聆风
夜雨聆风





当AI开始“看”病:谷歌x斯坦福AI QUESTS第二章《昏暗沙丘》完整通关笔记,走进医疗的伦理世界

沙漠里的求救:一个关于光明的故事
游戏的背景设置在沙丘地带。由于长期医疗条件的限制以及糖尿病的高发,越来越多的居民患上了一种会悄无声息吞噬视力的眼疾——根据游戏设定,这映射的正是现实中的糖尿病视网膜病变(Diabetic Retinopathy,简称DR) 。
什么是糖尿病视网膜病变?全球糖尿病患者中,大约每三个人就有一个可能会出现视网膜病变。长期被高糖血液侵蚀的视网膜微毛细血管会像老化的水管一样不断渗血、破裂,最终夺走一个人的光明。而最可怕的是,患者在视力严重受损之前往往毫无察觉。也就是说,这是一种“沉默的视力杀手”。

游戏种一位名叫Visus的医生和他的助手Arlo在沙漠中艰难地支撑着仅有的医疗点,他是沙丘中唯一的一位眼科医生,由于严重的资源紧缺,人手不足,Visus医生向“我”和AI导师Skye教授发出了求援——他们需要训练一个能够自动诊断糖尿病视网膜病变的AI模型。

第一关:审查患者数据——AI开发从保护隐私开始
摆在面前的第一项任务,是“审查并清理数据” ——只不过这次清理的不是噪点和异常值,而是患者隐私。
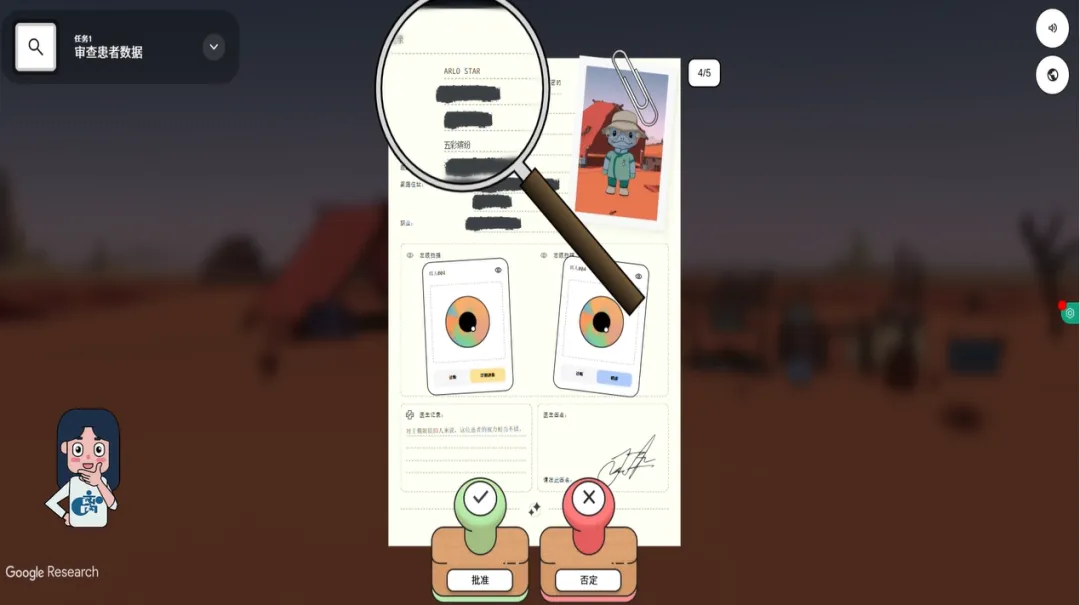
游戏呈现了数份患者档案,每一份都包含姓名、照片和住址等敏感信息。这个步骤叫做“审查患者数据” 。玩家必须逐份审核这些档案,将涉及隐私的档案标记为“否定”,并用笔在每一份档案上划掉姓名、相片、住址,确保完全匿名化之后,才能将这些数据投入后续的训练。
这个看似简单的环节,实际上蕴含着AI伦理最重要的第一课。在现代医疗AI的实际开发中,数据隐私保护是绝对不能绕过的红线。谷歌在其AI开发者原则中明确写道,“确保从数据集中移除所有个人身份信息”是构建负责任AI的基本要求。如果一个AI模型在开发过程中没有做好数据脱敏,一旦模型泄露或者被攻击,数以万计的患者隐私就会瞬间暴露,后果不堪设想。
完成数据清洗和脱敏后,玩家正式开始用这些“干净”的数据训练AI模型。模型很快训练完成,紧接着进入了评估阶段——玩家用一张全新的眼底扫描照片交给模型判断,得到一个AI诊断结论,同时和眼科专家的结论进行对比核对。
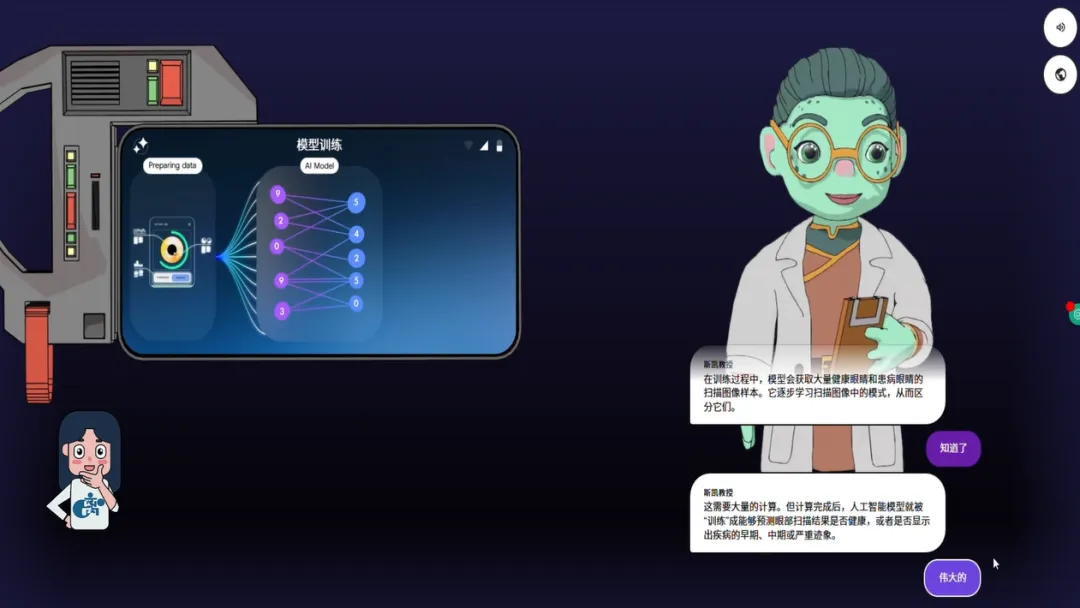
这一步的训练和测试,实际上教给玩家的就是监督学习的基础流程——AI通过学习带标签的数据找出规律,然后用从未见过的测试数据进行评估,验证模型到底有没有“学到位”。

第二关:发现偏差
训练出第一版模型后,玩家开始为真正的志愿者扫描眼睛。

前两位志愿者来自沙丘,而第三位志愿者来自另一个部落。当把这个志愿者的扫描结果给AI进行诊断时——AI给出了一个和专家意见完全相悖的结论:AI把它诊断错了。
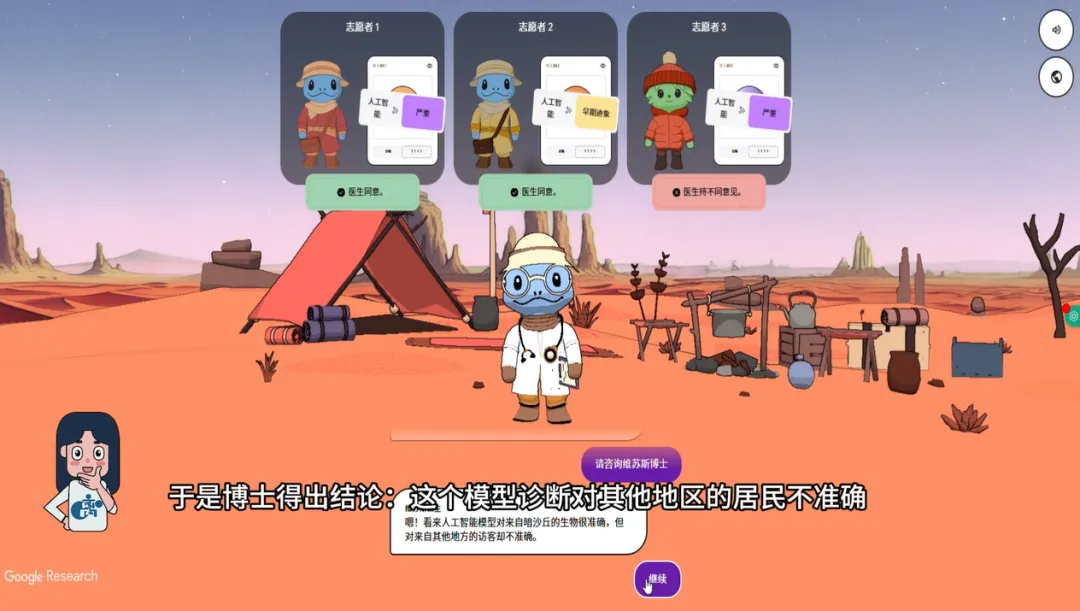
Visus医生和Arlo立刻意识到了问题的根源。通过分析数据和反复验证,博士做出结论:“这个模型对其他地区的居民不准确。”

原因很简单:我们用来训练模型的眼底照片,全部来自沙丘的居民。当这位来自东极地的患者出现时,模型就“看不懂”了。
这一幕太真实了。游戏把AI开发中一个极其严肃的命题推到了玩家面前——数据多样性决定诊断的公平性。
在真实的医疗AI发展中,这恰恰是一个困扰全球研究者的难题。谷歌与印度Aravind眼科医院合作开发的ARDA(Automated Retinal Disease Assessment)系统,正是在大规模真实世界部署中经受住了这样的考验。该系统在印度泰米尔纳德邦45家诊所进行了部署,覆盖超过100个卫星视光中心,面对的是真实世界中的设备差异、技术水平参差、患者人口结构变化等种种变量。最终ARDA系统在检测重度糖尿病视网膜病变时,敏感度达到97%,特异度达到96.4%——这个成绩固然令人赞叹,但在实际落地的过程中,开发者必须不断面对来自新地区、新人种的数据挑战。
Visus医生发现后提出了要求,收集更多的数据。

第三关:收集多样化的数据
游戏在地图上标注了星球上不同地区的居住地,玩家必须根据紫外线强度等级,分别采集低、中等、高、非常高四个等级的眼底照片数据。
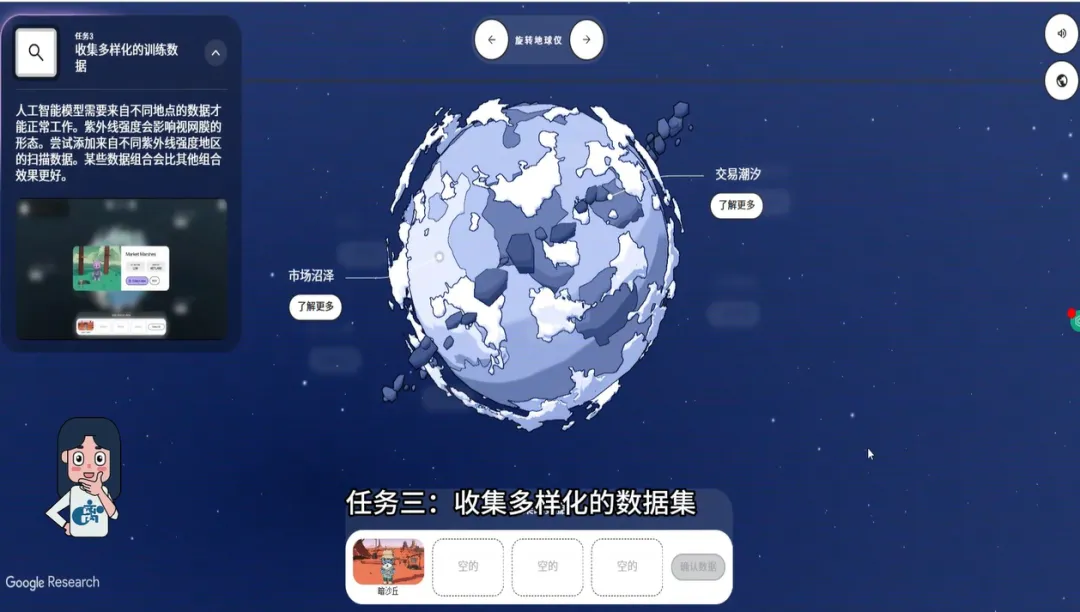
我们需要浏览这些环境迥异的地区,确保每一个等级有足够的数据样本。
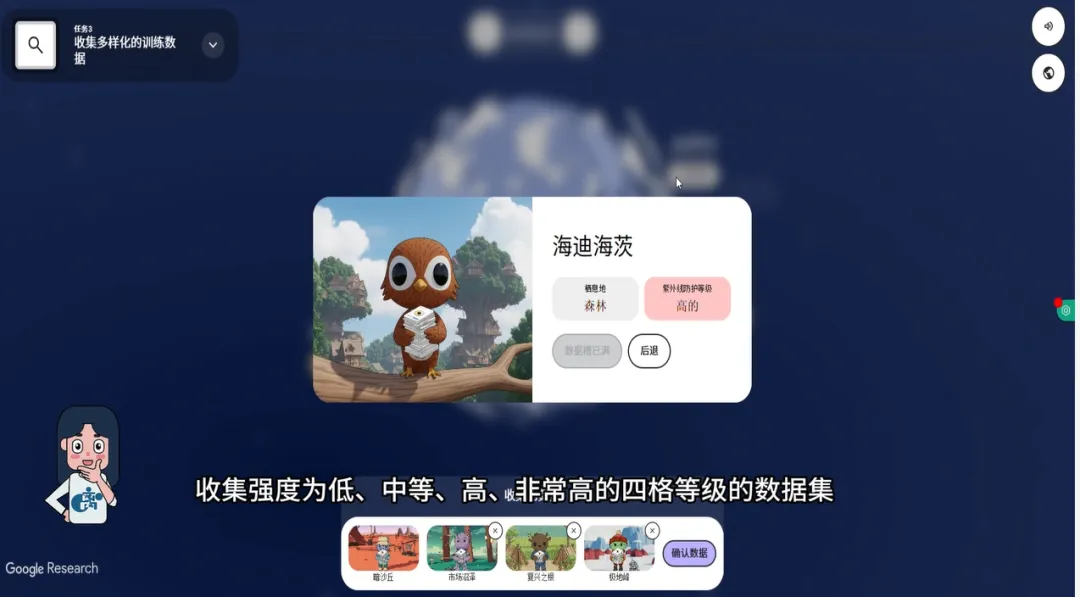
这一关的设计极其精巧。它用紫外线强度作为游戏机制,实际上传递了一个核心信息:高质量、高覆盖度的数据,比单一来源的大数据量更宝贵。
第四关:标注新数据——当三位医生意见不一致时
更全面的数据采集完成后,我们迎接第四个任务:对新数据进行标注。
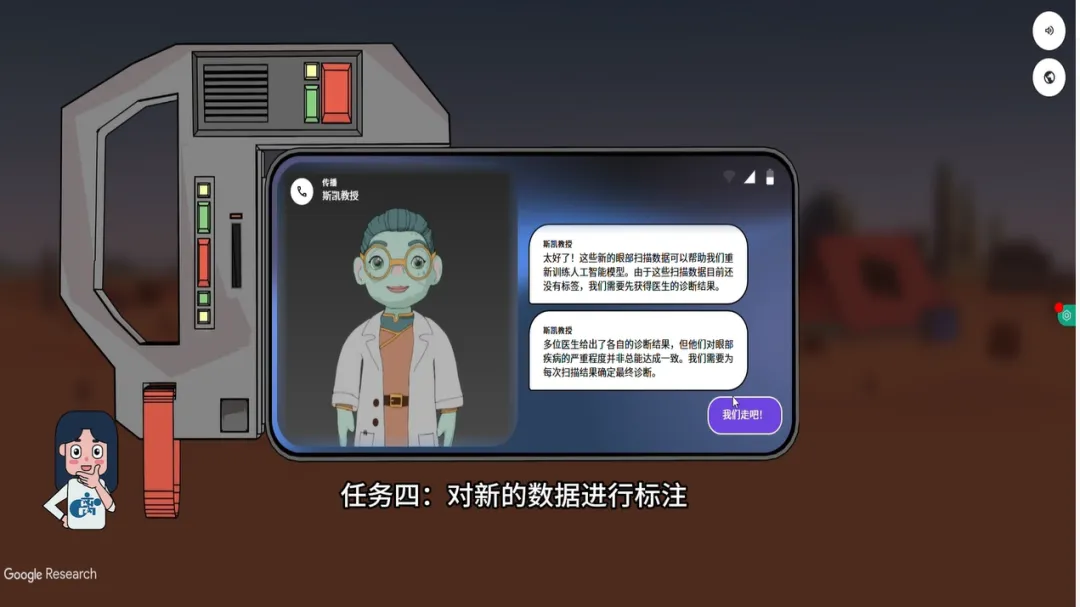
每一张新拍回来的眼底照片,右侧都同时显示着三位眼科医生给出的独立诊断结论。有时候三位医生意见一致,但有时候,也有分歧,如果三位医生各执一词,我该怎么办?游戏的解决方案启动了一个现实世界AI开发中的关键机制:邀请医生们进行讨论。

医生们一起讨论病例,有时在一场讨论之后,其中一位医生会改变自己的初步判断达成一致。而更棘手的情况也会出现——讨论后仍然意见不一,两位医生的立场依然对立。这时候游戏规则告诉我:那就标注大多数医生都认同的诊断结果。

这一幕让我感到格外震撼。它揭示了AI数据标注中一个极少被普通人知道的真相——医学诊断本身就带有一定的主观性和不确定性。 即使是专业医生对同一张眼底照片的判断也可能不完全一致。因此,在谷歌开发ARDA系统的过程中,他们采用了“多数专家共识”的验证方法。例如在研究报告中,ARDA算法训练集标注使用了54位美国执业眼科医生和眼科住院。在现实的医疗AI里,这就是科学的推进方式。
第五关:重新训练、再次测试
标注完成后,我们把之前清洗、收集、标注好的所有数据投入模型,重新训练。
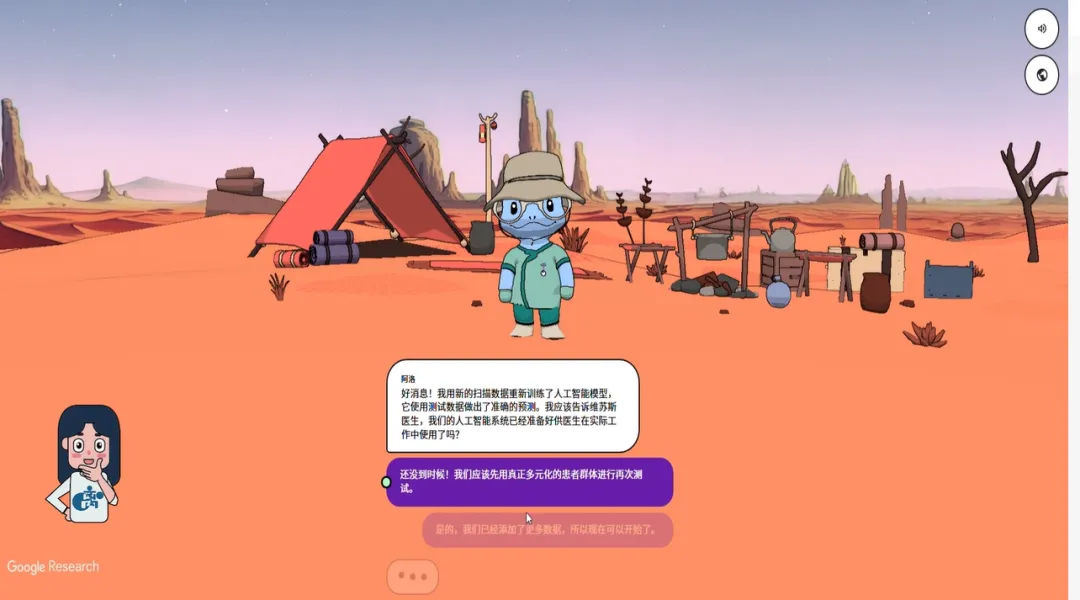
训练结束后,玩家将再次为来自不同地区的志愿者患者进行扫描,这一次,所有志愿者的扫描诊断结果和专家判断完全吻合。
这一次,VISUS医生开心的宣布:”模型可以正式投入使用了。”


第六关:完成流程排序——从零到一的AI项目复盘
最后一步,是“任务报告”。
游戏要求我把从零开始到模型成功部署的完整流程按照正确的顺序排列:
-
审查并清理数据(保护患者隐私)
-
首次训练模型
-
利用扫描数据对模型进行测试
-
收集更多样性的扫描数据
-
在医生的帮助下标注数据(包含专家讨论和共识)
-
重新训练和测试
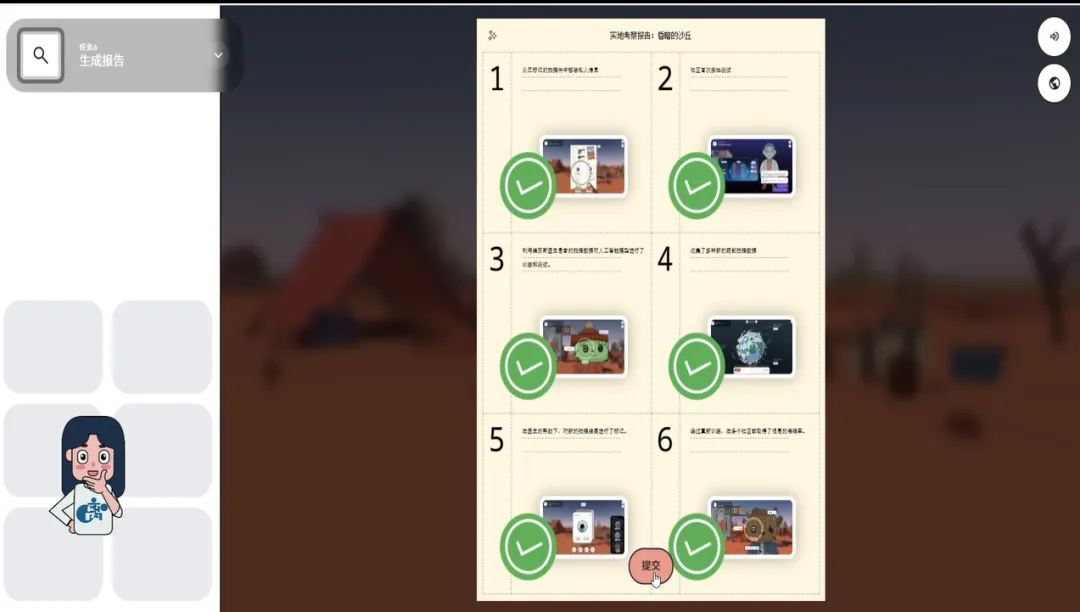
这看起来像是一个简单的排序题,但当你把整个流程走完一遍之后,你会发现,这套流程本身就是一本极简版的《AI项目开发规范手册》。它涵盖了数据伦理、监督学习、偏差纠正、模型迭代。
尾声:沙漠之外的真实——谷歌在印度的AI眼科医生
游戏结束时,屏幕里出现了两名谷歌研究员的真实影像。他们对着镜头告诉我们:这不仅仅是游戏。

谷歌真实落地的AI眼科医生项目——Automated Retinal Disease Assessment系统,已经在全球范围内支持了超过60万次筛查。

在游戏最后,两位研究员强调:这个系统不是在抢眼科医生的饭碗,而是在帮眼科医生挡住那些永远做不完的基础筛查,把珍贵的专家时间留给最复杂的病例。
结语:从防洪到医疗,不变的是对数据的敬畏
在《沼泽市场》,我们了解了如何用AI预测洪水,守护的是人们的家园。
在《昏暗沙丘》,我们了解如何用AI诊断眼疾,守护的是人们的光明。
这两件事跨度极大,但核心的AI原理其实一脉相承:数据质量决定一切,数据多样性决定公平性,而伦理性是数据不可触碰的底线。
谷歌和斯坦福用六个精巧的任务环节,让我们在短短的几十分钟里体验了一整个医疗AI项目从立项到落地所必须经历的全部困局和取舍。
我在剪辑的视频中完整记录了从数据清洗到模型部署的全部通关过程。如果你也想亲自动手制作自己的第一个医学诊断AI,别忘了去AI QUESTS免费体验《昏暗沙丘》。
如果你打算带孩子或在课程设计中参考这一章,可以尝试以下三个点:
| 维度 | 教学重点 | 创意结合建议 |
| 批判性思维 | 机器与医生的“协作” | 讨论:如果 AI 判断错了,医生该如何做最终决策? |
| 元认知 | 识别过程的复盘 | 询问孩子:你是根据什么视觉特征(红点、白斑)来判断病变的?AI 会用同样的方式吗? |
| STEAM 融合 | 图像识别原理 | 结合arduino以及 摄像头模块,尝试做一个简单的颜色/形状识别实验,模拟 AI 寻找“出血点”的过程。 |
这一章通过“救人”的使命感,完美地平衡了硬核的技术逻辑与柔软的人文温度。继“洪水预测”和“盲症预防”之后,第三章 《极地巅峰》(Polar Peaks) ,它将挑战更复杂的脑科学(Connectomics),带孩子去绘制人类大脑的神经网络图谱,也非常值得期待。
未来的教育,不在于教孩子如何被机器取代,而在于教他们如何用技术去关怀世界。
你是如何带孩子接触 AI 的?评论区聊聊你的心得吧!