 夜雨聆风
夜雨聆风





从一个群消息,到上线一个 AI 工具,我只花了不到一天

木木造 · AI 产品实践 · PicPrompt产品地址:www.picprompt.art
睡觉前,我在群里看到一个朋友发了个东西。
那是一个 Chrome 浏览器插件,可以从图片里反向提取 AI 提示词。
我点进去看了一下,功能方向是对的,确实是一个真实需求。但很快,我就发现了两个问题:
-
1. 需要付费 -
2. 只支持国外 API,国内接口完全用不了
我当时的第一反应是:
这个东西不难做,而且完全可以做得更好。
那时候已经晚上 12 点了,但我越想越睡不着。
于是我又爬起来,把这个需求直接丢给了 AI。接下来,它就开始吭哧吭哧地帮我开发。
第二天睡醒,我发现:AI 已经把第一版开发完了。
我先做了一个浏览器插件 PicPrompt。功能跑通后,提交到 Chrome 应用商店审核,然后就开始等待。
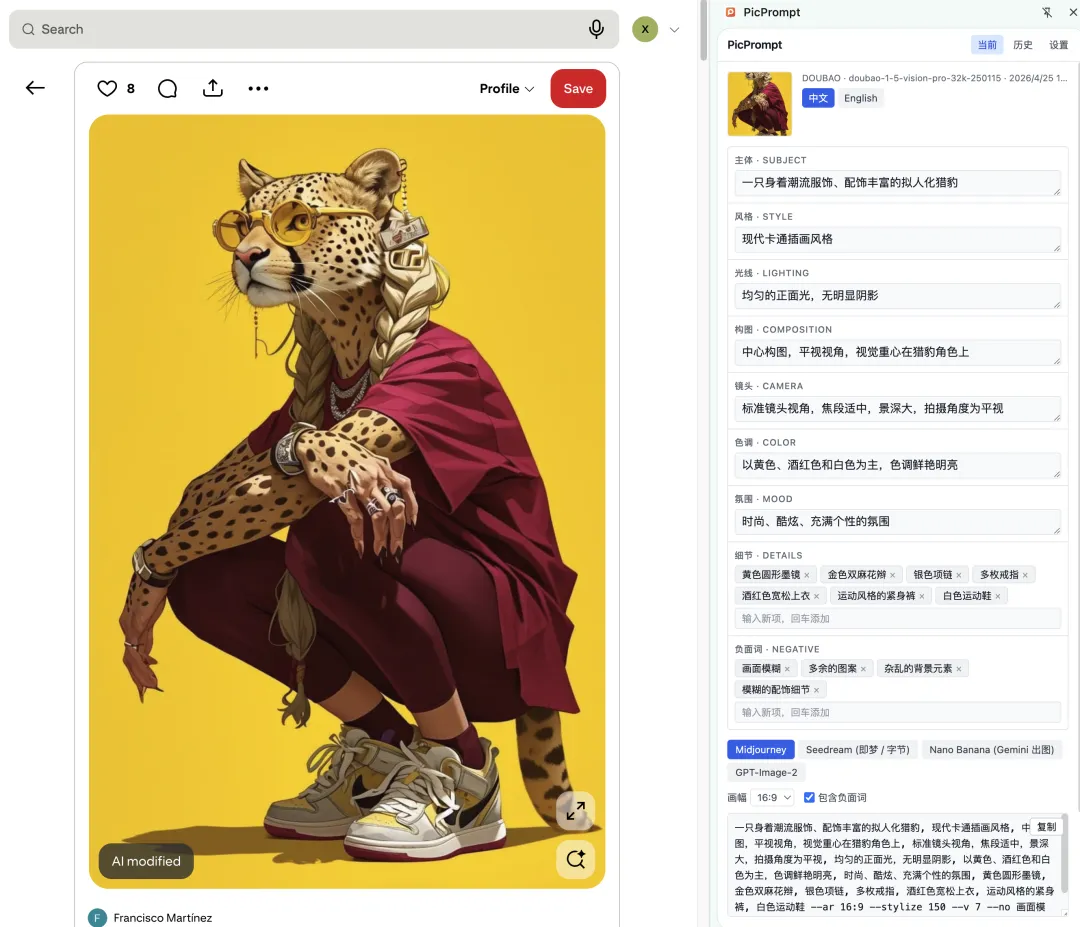
但 Chrome 审核一般要 3–7 天。
我等不住了。
于是第二天白天,我又抽了点时间,把插件改成了网站,直接部署上线。
从看到那条群消息,到 picprompt.art 上线,前后不到一天。
这篇文章,就是这个产品从想法到上线的完整复盘。
01 为什么“描述图片”不等于“写提示词”
在开始做之前,我先想清楚了一个核心问题:
AI 画图的提示词,到底是什么?
很多人以为,提示词就是“把图片内容用文字描述出来”。
这个理解没错,但不够用。
真正的 AI 提示词,更像是给一位视觉导演的拍摄指令。
它不只是在说:
图里有什么。
而是在说:
用什么风格、什么光线、什么构图、什么情绪,去呈现这个内容。
举个例子:
“一个女孩站在窗边,光线透过百叶窗打进来。”这是描述。
而下面这种,才更像是 AI 绘图平台真正需要的提示词:
“soft cinematic lighting, shallow depth of field, film grain, 35mm lens, warm tones, –ar 4:5 –stylize 120”
同样的画面内容,两种表达方式,生成出来的图会完全不一样。
不同 AI 绘图平台,对提示词的“语法”要求也不一样。
-
• Midjourney 喜欢逗号分隔的关键词链,再加精确参数控制。 -
• 即梦 / Seedream 更接近中文自然语言,要像给导演写故事板一样,把情绪和氛围说清楚。 -
• GPT-Image-2 更适合段落式结构化描述,细节越丰富越好。 -
• Nano Banana 基于 Gemini,更适合带镜头类型、光线来源、情绪标签的英文指令。
所以,如果你想把豆包生成的一张图,拿到 GPT-Image-2 里复现,不能只是复制图片描述。
你需要把图片信息重新翻译成 GPT-Image-2 能读懂的语法。
这就是 PicPrompt 想解决的问题。
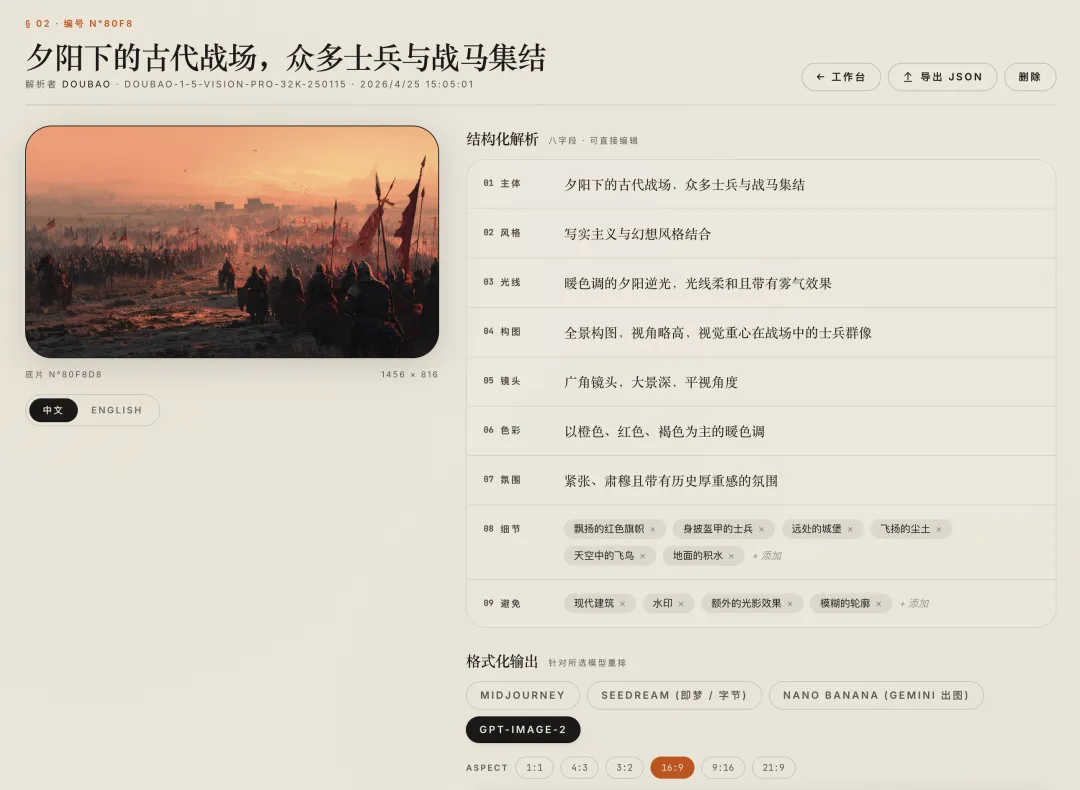
02 实战案例:从豆包图片,到 GPT-Image-2 复现
理论说完,直接看一个真实使用场景。
这是我用 PicPrompt 最频繁的场景之一:
在即梦或豆包里生成了一张好图,想拿到 GPT-Image-2 里重新跑一遍,对比效果。
第一步:找到那张图
我先用豆包生成了一张日系风格的咖啡馆室内图。
画面里有:
-
• 暖光打在木质桌面上 -
• 窗外是虚化的绿植 -
• 整体是安静、松弛、有点午后感的氛围
这种图,如果我直接用自然语言告诉 GPT-Image-2:
生成一张日系咖啡馆照片。
它大概率会给我一张“明亮的咖啡馆照片”。
但它很可能会丢掉:
-
• 轻微过曝感 -
• 胶片颗粒 -
• 浅景深 -
• 侧光氛围 -
• 低饱和色调
也就是那张图真正好看的部分。

第二步:把图片拖进 PicPrompt
打开 picprompt.art,把图片直接拖进上传区域。
不需要注册,不需要登录。配置好自己的 API Key,就可以使用。
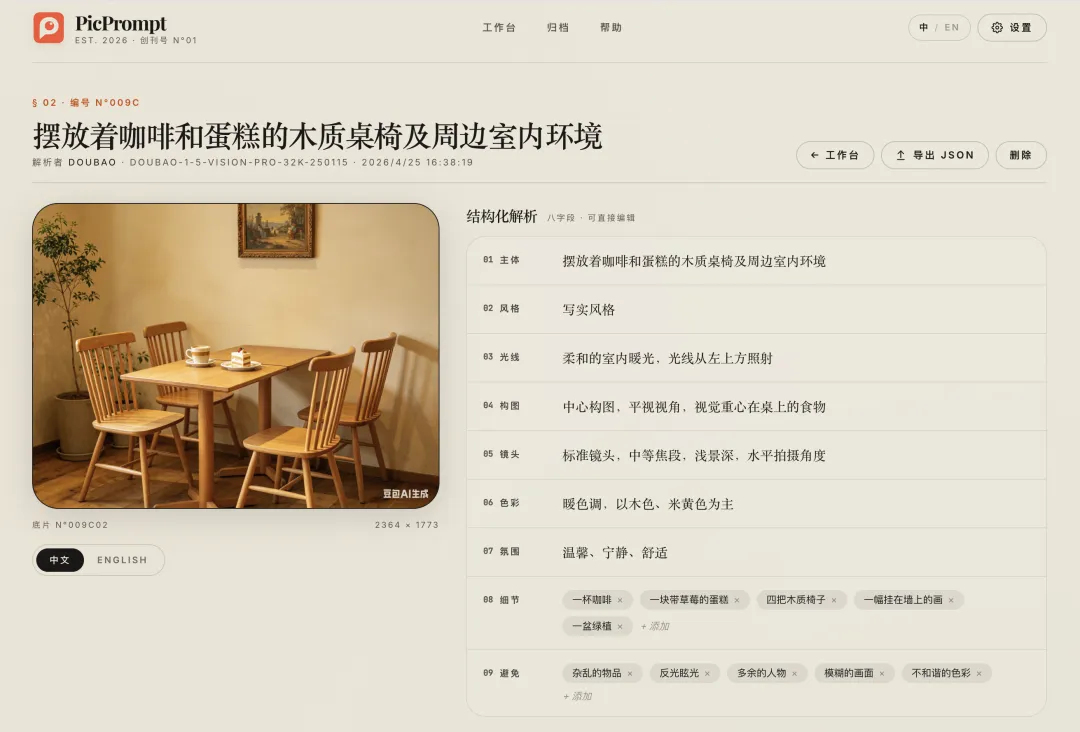
PicPrompt 会用视觉 AI 对图片进行多维度分析,并拆解成 8 个结构化字段:
|
|
|
| 主体 |
摆放着咖啡和蛋糕的木质桌椅及周边室内环境 |
| 风格 |
日系胶片风格,带轻微过曝感,增强日系胶片质感 |
| 光线 |
自然光从窗户侧面进入,暖色调,强化侧光氛围,有明显光影对比 |
| 构图 |
中心构图,平视视角,视觉重心在桌上的食物 |
| 色彩 |
暖色调,以木色、米黄色为主,营造暖色午后感 |
| 镜头 |
标准镜头,中等焦段,增强浅景深虚化效果,水平拍摄角度 |
| 氛围 |
温馨、宁静、舒适 |
| 细节 |
一杯咖啡、一盆绿植、一块带草莓的蛋糕、四把木质椅子、一幅挂在墻上的画 |
这一步完成后,我得到的不是一段普通描述,而是这张图片的结构化“基因图谱”。
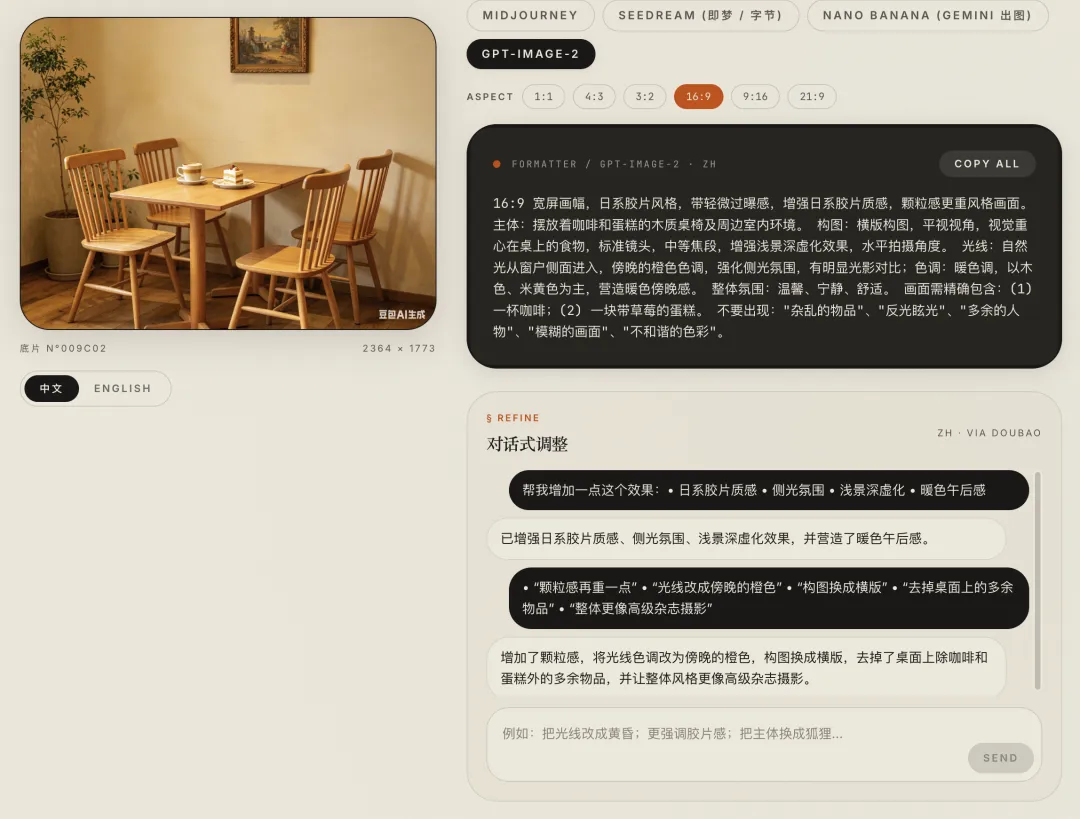
第三步:选择 GPT-Image-2 格式,一键转换
接下来,在右侧选择目标平台:
GPT-Image-2
PicPrompt 会自动把刚才提取出来的结构化信息,重新组装成 GPT-Image-2 更适合理解的提示词格式:
16:9 宽屏画幅,日系胶片风格,带轻微过曝感,增强日系胶片质感风格画面。主体:摆放着咖啡和蛋糕的木质桌椅及周边室内环境。 构图:中心构图,平视视角,视觉重心在桌上的食物,标准镜头,中等焦段,增强浅景深虚化效果,水平拍摄角度。 光线:自然光从窗户侧面进入,暖色调,强化侧光氛围,有明显光影对比;色调:暖色调,以木色、米黄色为主,营造暖色午后感。 整体氛围:温馨、宁静、舒适。 画面需精确包含:(1) 一杯咖啡;(2) 一块带草莓的蛋糕;(3) 四把木质椅子;(4) 一幅挂在墙上的画;(5) 一盆绿植。 不要出现:”杂乱的物品”、”反光眩光”、”多余的人物”、”模糊的画面”、”不和谐的色彩”。
这段提示词跟“请描述这张图片”得到的大白话完全不同。
它不只是告诉 AI:
画什么。
它还在告诉 AI:
怎么画。
第四步:拿去 GPT-Image-2 生成,看效果
把这段提示词复制到 ChatGPT 的图像生成界面,选择 GPT-Image-2 生成。
结果很接近我想要的方向。
它不是完美复刻。毕竟不同模型的底层逻辑不同。
但那种:
-
• 日系胶片质感 -
• 侧光氛围 -
• 浅景深虚化 -
• 暖色午后感
都被保留下来了。
和我最初直接用自然语言描述生成的版本相比,这一版明显更接近原图的味道。

跨平台图像复现,本质上是一个语言翻译问题。PicPrompt 做的,就是把图片翻译成不同模型听得懂的提示词语言。
还可以继续用 AI 对话调整
如果生成结果有某个方向不对,也不需要重新上传图片。
PicPrompt 内置了 AI 对话功能。
你可以直接对它说:
-
• “颗粒感再重一点” -
• “光线改成傍晚的橙色” -
• “构图换成横版” -
• “去掉桌面上的多余物品” -
• “整体更像高级杂志摄影”
它会在原有提示词基础上继续修改,而不是重头来过。
这个功能省了我很多来回上传图片、反复复制提示词的时间。尤其是在调整风格细节时,非常顺手。

03 四大平台提示词规范,我是怎么做进去的
PicPrompt 目前支持四个平台的提示词格式。
每个平台都有自己的语法逻辑,不能混用。
|
|
|
| Midjourney |
--ar 16:9、--stylize 150、--v 7、--no text。风格词放前,参数放最后,越精确越好。 |
| Seedream / 即梦 |
|
| Nano Banana |
Shot type、Lighting、Mood 等标签。 |
| GPT-Image-2 |
|
研究这四套规范,花了我不少时间。
它们不只是格式不同,背后的生成思路也不同。
Midjourney:关键词压缩能力很重要
Midjourney 的用户习惯把图像风格压缩成一串关键词。
它适合:
-
• 风格词 -
• 镜头词 -
• 材质词 -
• 光影词 -
• 参数控制
提示词要精炼,参数要清楚。
即梦:中文语境下的“导演说明书”
即梦更接近中文表达。
与其写:
温暖自然光
不如写:
傍晚的橙色斜光从窗户照进来,轻轻落在白墙和木桌上。
具体、有画面、有情绪,效果会更好。
GPT-Image-2:细节越清楚,还原越稳定
GPT-Image-2 对结构化细节很友好。
你把主体、光线、色彩、镜头、氛围拆清楚,它会更稳定地理解你的需求。
它不是只看关键词,而是更像在读一份完整的视觉说明。
Nano Banana:更吃镜头语言和情绪标签
Nano Banana 对镜头类型、光线来源和情绪标签比较敏感。
如果提示词里加入:
-
• shot type -
• camera angle -
• lighting direction -
• mood -
• cinematic texture
生成结果通常会更稳定。
这四套规范在 PicPrompt 里是完全独立的格式模块。
切换平台时,它不是简单替换文字,而是重新走一遍流程:
图片结构化信息 → 目标平台语法 → 可直接使用的提示词
同一张图,四个平台的提示词语言风格和结构完全不同。但底层图片信息只需要提取一次。
这就省掉了大量重复分析成本。
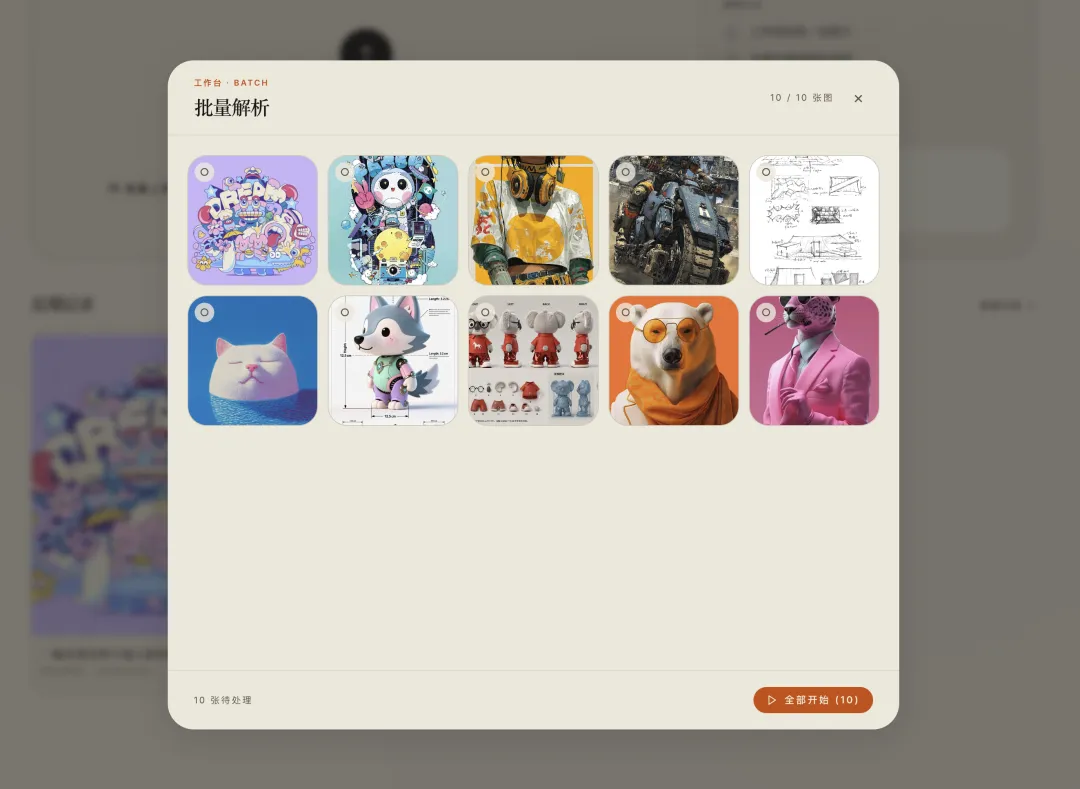
04 批量处理:设计师真正需要的不是“一张图”
PicPrompt 支持批量上传。
一次最多可以处理 10 张图。
这个功能不是为了显得“功能很多”,而是因为我自己真的需要。
做内容、做 AI 视频、做视觉参考时,我经常会一次性收集一组参考图。
比如在做一组 AI 视频之前,我会先收集 15–20 张风格参考图,然后提取它们的提示词,分析这些图共同的风格语言,再用来指导后续生成。
如果一张一张处理,这个过程非常耗时。
批量处理之后,我可以一次选好图片,去喝杯水,回来就能看到全部结果。
处理过程中,每张图的状态也会清楚显示:
-
• 待处理 -
• 处理中 -
• 已完成 -
• 出错
哪张卡住了,一眼就知道。
05 设计决策:为什么它看起来“不像工具”
整个项目里,我花时间最多的部分不是功能,而是设计。
在动手做之前,我问了自己一个问题:
如果有两个功能完全一样的提示词提取工具,一个长得像普通 SaaS 工具,白底、蓝按钮、卡片布局;另一个长得像设计杂志,奶油底色、衬线字体、杂志分栏;用户会更愿意把哪个分享给朋友?
答案很明显。
所以从一开始,我就把一个目标写进了产品里:
它要好看到让人想截图分享。
字体:内容严肃,形式优雅

标题用了 Playfair Display。
这是一款带古典气质的衬线字体,适合做大标题,有一点杂志感和设计感。
正文用了 Inter。
它的可读性很好,和 Playfair Display 形成了对比:
标题优雅,正文清晰。
配色:温暖,但不软弱
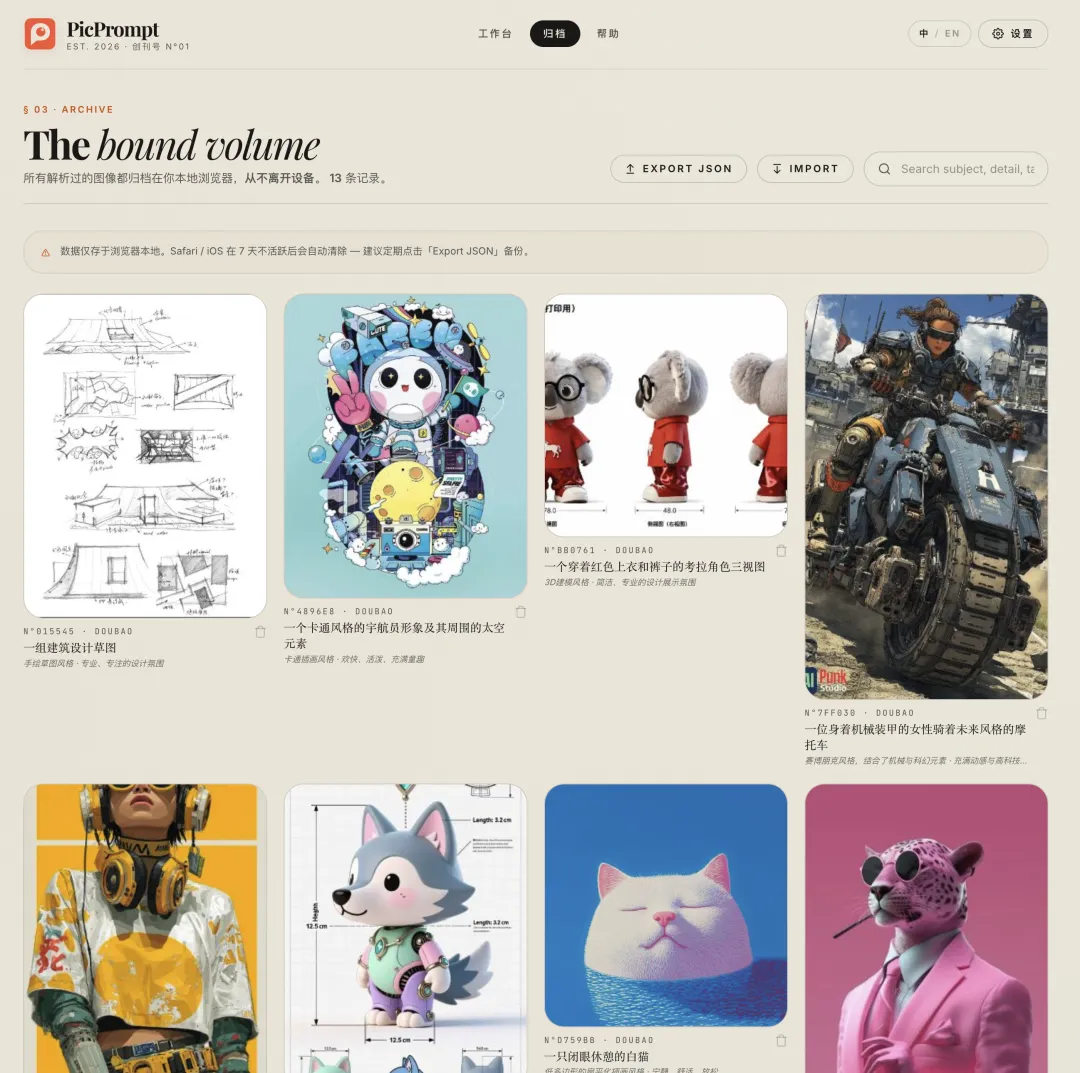
主背景是奶油米色:
它有一点纸质感,不像纯白那么刺眼。
主强调色用了烧橙色。
在奶油底色上,烧橙色很有力量感:温暖,但不软;有设计感,但不花哨。
文字没有用纯黑,而是用了炭灰色。这样整体阅读会更柔和,也更高级。
布局:更像设计杂志,而不是普通后台
首页用了杂志式大标题布局。
功能区采用分栏结构。
参考的是设计师工具和编辑型产品,而不是常见 SaaS 的“填表单式布局”。
界面的质感是一种无声的信号。它在告诉用户:做这个东西的人,在不在乎。
06 技术选择:纯前端,没有后端
PicPrompt 是一个纯前端项目。
没有服务器。没有数据库。所有东西都在浏览器里运行。
这样做有几个原因。
1. 隐私更清楚
你的图片不会上传到我的服务器。你的 API Key 也只保存在本地。
我完全看不到。
2. 速度更快
本地处理,没有额外的后端转发延迟。
用户配置好 API Key 后,可以直接调用对应模型。
3. 成本更低
没有服务器,就没有服务器成本。
这也意味着这个工具可以长期免费开放,用户只需要使用自己的 API Key。
4. 维护更轻
纯前端项目几乎没有运维负担。
我可以把更多精力放在:
-
• 功能迭代 -
• 体验优化 -
• 提示词格式 -
• 工作流设计
而不是服务器维护。
技术栈
目前使用的技术栈包括:
-
• React -
• TypeScript -
• Tailwind CSS -
• Dexie -
• IndexedDB -
• Vite
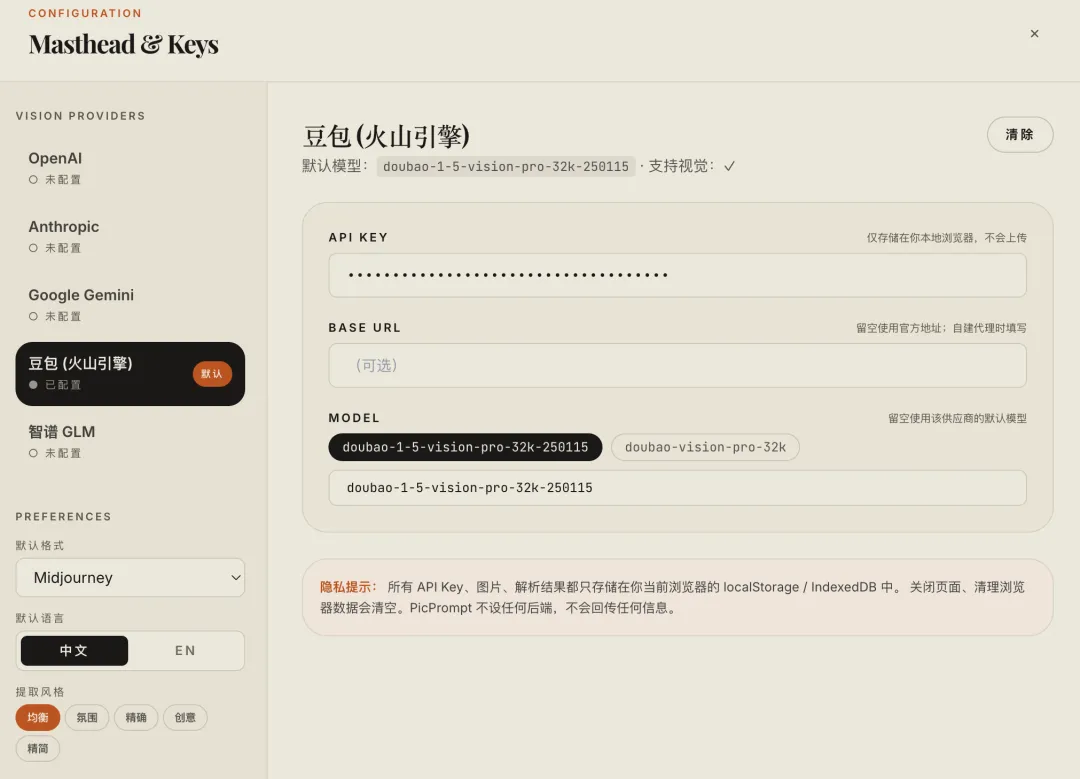
Vision API 接入了五个方向:
-
• OpenAI / GPT-4o Vision -
• Anthropic / Claude -
• Google Gemini -
• 豆包 -
• 智谱 GLM
国内用户可以直接配置豆包或智谱的 API Key,不需要科学上网。
我自己日常用得最多的,也是豆包。在图片理解和提示词拆解这个场景里,它的表现很稳定。
07 细节打磨:从“能用”到“想用”
基础版本跑通之后,我又花了很多时间打磨细节。
这些细节单独看都不大,但叠加起来,会直接决定一个工具到底是:
偶尔想起来用一下。
还是:
每天都想打开。
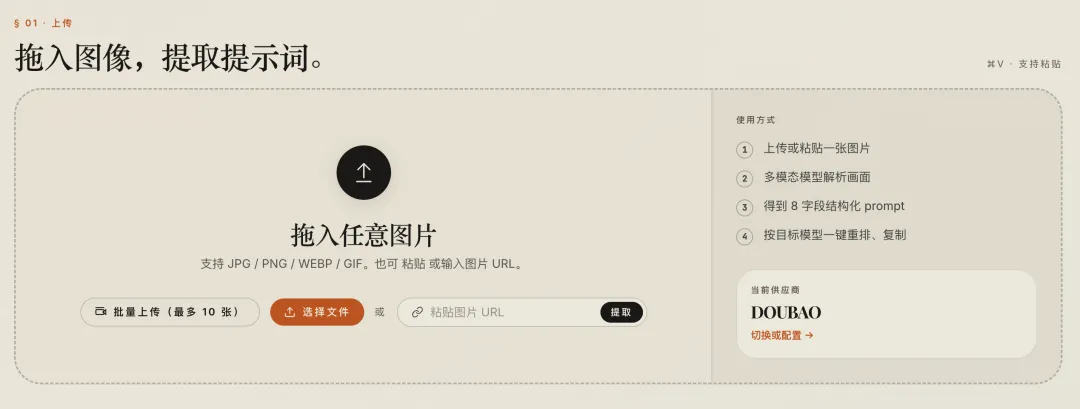
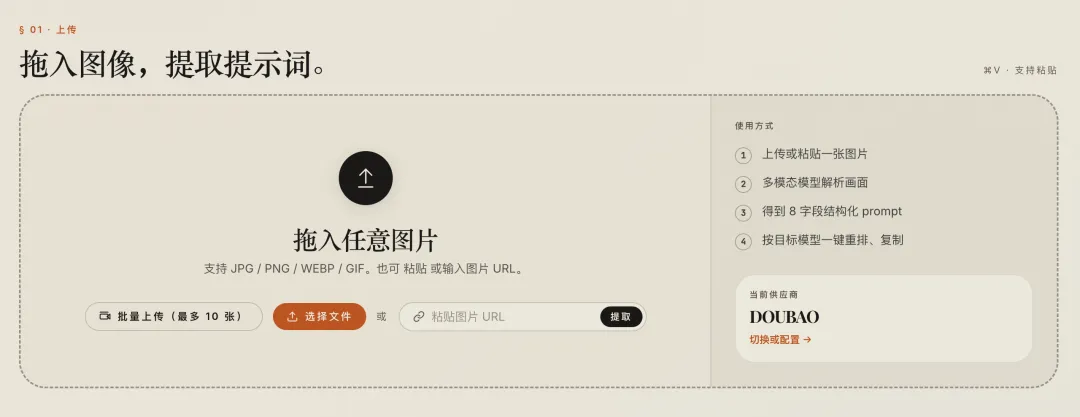
拖拽上传 + 粘贴支持
上传图片有三种方式:
-
1. 拖拽图片 -
2. 点击选择文件 -
3. 粘贴图片 URL 或截图
“粘贴”这个功能是后来加的。
因为我发现自己最常用的方式其实是:
截图之后,直接
Cmd + V粘贴进来。
这比点任何按钮都快。
实时编辑提示词
提示词生成后,可以直接在界面里编辑。
不用复制到别的地方修改,再粘回来。
AI 生成的提示词不一定 100% 准确。能够直接在原地修改,是最自然的操作流。
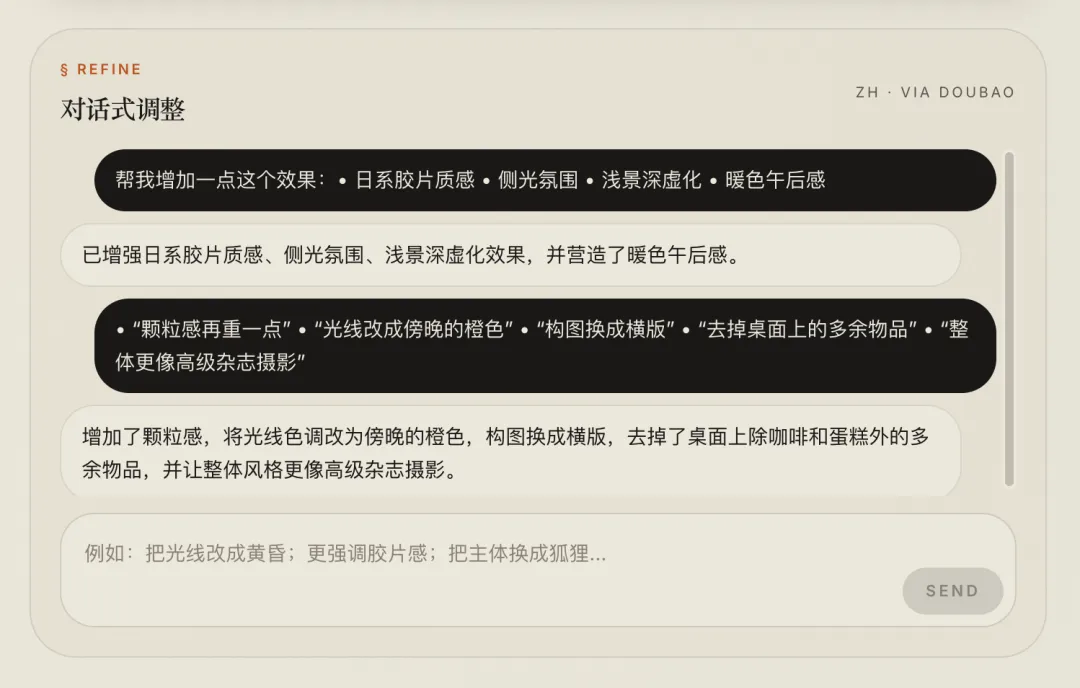
AI 对话调整
生成结果出来后,下方有一个对话框。
你可以继续说:
-
• “把颗粒感的描述去掉” -
• “光线方向改成正面光” -
• “加入雨天元素” -
• “整体更高级一点” -
• “改成适合小红书封面的竖版构图”
AI 会在原有提示词基础上修改,而不是重新生成一遍。
多语言 UI
界面支持中英文切换。
右上角一键切换,所有 UI 文案都会同步变化。
这里我没有用 i18n 库,而是手写了一套翻译系统。
这样可以更好地控制中英文的表达习惯,而不是生硬直译。
多种导出格式
PicPrompt 支持三种导出方式(右上角可导出 JSON):

|
|
|
| 复制到剪贴板 |
|
| 导出为纯文本 |
|
| 导出为 JSON |
|
完全免费
目前 PicPrompt 是免费开放的。
用户只需要配置自己的 API Key,就能正常使用。
08 用 AI 做产品,设计师的优势在哪里
做完这个项目后,我对“设计师用 AI 做产品”这件事,有了更具体的感受。
技术门槛确实在降低。
Vision API 的调用逻辑并不复杂。React 组件化开发在 AI 辅助下,上手速度也快了很多。
但我越来越觉得:
设计师的优势,不是比程序员更快学会写代码。
真正的优势在于判断力。
设计师知道什么叫“好用”
好用不是功能完整。
好用是:
-
• 流程顺畅 -
• 不需要思考 -
• 每一步都在用户预期里 -
• 用户不会卡住 -
• 用户知道下一步该做什么
设计师知道什么叫“好看”
好看不是把按钮做漂亮。
好看是:
-
• 整体视觉有层次 -
• 页面有呼吸感 -
• 信息有主次 -
• 字体、颜色、留白都服务于内容 -
• 用户愿意截图分享
设计师知道什么叫“值得分享”
一个工具能不能传播,不只看功能。
还要看用户用了它之后,会不会觉得:
这个东西让我显得更专业。
如果一个工具能让用户产生这种感觉,他就更愿意推荐给朋友。
AI 帮我加速了执行。
但每一个:
这样不对,重来。
都是我自己判断的。
那些判断,AI 没有,也给不了。
09 接下来想做什么
PicPrompt 现在的核心流程是:
上传图片 → 提取提示词 → 切换平台格式 → AI 辅助调整 → 复制使用
用了一段时间后,我发现还有几个方向值得继续做。
1. Figma 插件
设计师的主战场是 Figma。
如果 PicPrompt 能以插件形式嵌入 Figma,直接在设计文件里选中一个图层,就能提取提示词,这个工作流会顺畅很多。
2. 风格记忆
如果 PicPrompt 能记住我过去常用的提示词风格,在分析新图片时自动偏向我的偏好,就能大大减少后期调整时间。
比如我经常喜欢:
-
• 胶片质感 -
• 奶油色调 -
• 浅景深 -
• 杂志感构图 -
• 小红书封面风格
那它以后就可以自动向这些方向靠近。
3. 浏览器插件
在网页上看到一张好图,右键一下直接提取提示词。
不需要截图。不需要切换工具。不需要重新上传。
这个场景发生得非常高频。
目前浏览器插件版本已经做完,正在 Chrome 应用商店审核中。
最后
这个产品从看到那条群消息,到网站上线,前后不到一天。
我不是想炫耀速度。
速度本身不是目标。
这件事真正让我感受到的是:
在 AI 工具足够好用的今天,“想法到产品”的距离,已经被压缩得非常短。
真正的门槛不再只是技术。
而是:
你有没有想清楚,要做什么。以及,你想把它做成什么样。
一个“小而美”的工具,往往比一个“大而全”的平台更容易打动人。
当你的产品只做一件事,但做得足够好:
-
• UI 很舒服 -
• 流程很顺 -
• 结果能直接用 -
• 用户愿意截图分享
它就会自然地被推荐出去。
你可以去试试 www.picprompt.art。
上传一张你觉得好看的图,看看它能帮你挖出什么。
如果有 bug、有建议,或者你也想要某个功能,欢迎来找我聊。
我是木木。正在用 AI 造一些好看、能用、值得分享的小工具。
— 木木造