 夜雨聆风
夜雨聆风





爆款对口型视频复刻智能体 – 完整开发文档
本智能体可分析爆款视频文案,自动生成N个差异化脚本,通过TTS配音+Wav2Lip对口型技术,将人物空白动作视频合成为逼真的口播视频,实现批量产出爆款风格短视频。
一、项目简介 爆款视频复刻智能体 是一个全自动Python应用,功能链路如下:
输入:爆款视频URL/文件 + 人物空白动作视频(面部清晰、无口型)
处理:
提取原视频音频 → Whisper语音识别 → 获取文案 GPT分析爆款要素(Hook、结构、情感、金句) GPT生成N个不同角度/风格的短视频口播脚本 Edge TTS为每个脚本生成自然配音 Wav2Lip将配音与人物视频合成 → 对口型视频 (备选)若Wav2Lip失败,自动降级为普通合成+字幕 输出:N个对口型口播视频,可直接发布
二、系统架构图
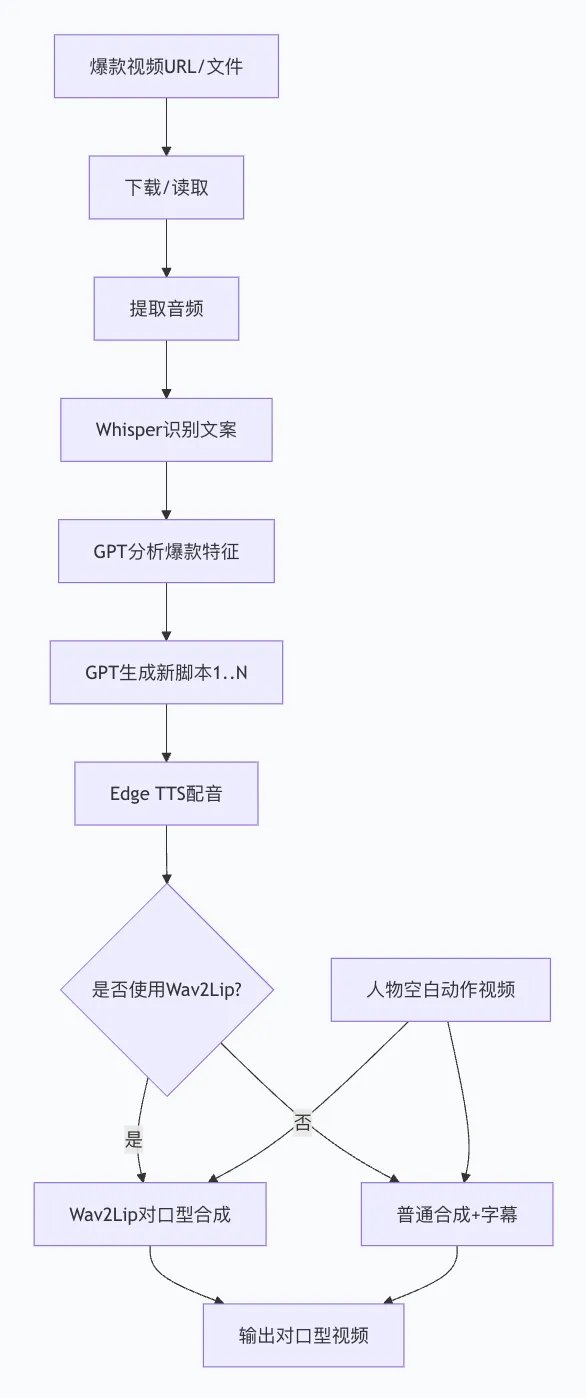
三、环境准备 3.1 系统要求 操作系统:Windows / Linux / macOS(推荐Ubuntu 20.04+)
CPU:4核+,内存8GB+(Wav2Lip建议使用GPU)
GPU:NVIDIA显卡,显存4GB+(可加速Wav2Lip,非必须)
软件预装:
Python 3.9+ (下载)
FFmpeg (下载)
Git
3.2 安装FFmpeg Windows:下载ffmpeg-release-full.7z,解压并添加bin目录到PATH
Linux:sudo apt install ffmpeg
macOS:brew install ffmpeg
3.3 克隆Wav2Lip仓库 bash git clone https://github.com/Rudrabha/Wav2Lip.git cd Wav2Lip pip install -r requirements.txt # 安装Wav2Lip依赖
下载预训练模型
mkdir checkpoints wget ‘https://iiitaphyd-my.sharepoint.com/personal/radrabhamresearchiiitacin/layouts/15/download.aspx?share=EdjI7bZlgApMqsVoEUUXpLsBxqXbn5z8VTmoxp55YNDcIA’ -O checkpoints/wav2lip_gan.pth cd .. 3.4 Python虚拟环境(推荐) bash python -m venv venv source venv/bin/activate # Linux/macOS
或 venv\Scripts\activate # Windows
3.5 安装项目依赖 创建 requirements.txt:
text yt-dlp>=2023.12.30 openai-whisper>=20231117 moviepy>=1.0.3 pydub>=0.25.1 edge-tts>=6.1.9 openai>=1.0.0 torch>=2.0.0 # Wav2Lip需要,也可从Wav2Lip的requirements安装 numpy tqdm opencv-python face_recognition 安装命令:
bash pip install -r requirements.txt 3.6 获取OpenAI API Key(用于GPT分析&生成脚本) 访问 platform.openai.com 注册并创建API Key
或使用兼容的代理(如OneAPI),修改代码中的base_url
四、项目文件结构 text project/ ├── agent.py # 主程序脚本(见后续代码) ├── requirements.txt # Python依赖 ├── Wav2Lip/ # 克隆的Wav2Lip仓库(必须与agent.py同级) │ ├── inference.py │ ├── checkpoints/ │ │ └── wav2lip_gan.pth │ └── … ├── temp/ # 临时文件(自动创建) ├── output/ # 最终视频输出(自动创建) └── README.md # 本文档 五、完整代码实现 将以下所有代码保存为 agent.py 放置在项目根目录。
python
–– coding: utf-8 ––
“”” 爆款对口型视频复刻智能体 作者: Viral Video Agent 版本: 2.0 (集成Wav2Lip) “””
import os import re import subprocess import argparse import asyncio from pathlib import Path from typing import List, Dict, Optional
音频处理
import whisper import edge_tts from pydub import AudioSegment
视频处理
from moviepy.editor import ( VideoFileClip, AudioFileClip, CompositeVideoClip, TextClip, concatenate_videoclips )
LLM
import openai from openai import OpenAI
全局配置
OPENAIAPIKEY = “YOURAPIKEY” # 替换为实际Key,或使用环境变量 OPENAIBASEURL = None # 可选:代理地址,如 “https://api.openai.com/v1”
如果 OPENAIAPIKEY 为默认占位符,且环境变量中没有,则模拟模式生效
if OPENAIAPIKEY == “YOURAPIKEY”: OPENAIAPIKEY = os.environ.get(“OPENAIAPIKEY”, None)
client = OpenAI( apikey=OPENAIAPI_KEY, baseurl=OPENAIBASE_URL ) if OPENAIAPIKEY else None
路径设置
BASE_DIR = Path(file).parent OUTPUTDIR = BASEDIR / “output” TEMPDIR = BASEDIR / “temp” WAV2LIPDIR = BASEDIR / “Wav2Lip” WAV2LIPCHECKPOINT = WAV2LIPDIR / “checkpoints” / “wav2lip_gan.pth”
OUTPUTDIR.mkdir(existok=True) TEMPDIR.mkdir(existok=True)
语音参数
DEFAULTTTSVOICE = “zh-CN-XiaoxiaoNeural” # 中文女声,可改为其他Edge TTS支持的声音
1. 视频与音频处理
def downloadvideo(url: str, outputpath: Path) -> str: “””下载网络视频(支持抖音、B站、YouTube等)””” print(f”[下载] 开始下载: {url}”) cmd = [ “yt-dlp”, “-f”, “bestvideo+bestaudio”, “–merge-output-format”, “mp4”, “-o”, str(output_path), url ] subprocess.run(cmd, check=True, capture_output=True) print(f”[下载] 完成: {output_path}”) return str(output_path)
def extractaudio(videopath: str, audio_path: str) -> str: “””从视频中提取音频为WAV””” video = VideoFileClip(video_path) video.audio.writeaudiofile(audiopath, logger=None, verbose=False) video.close() return audio_path
2. 语音识别
def transcribeaudio(audiopath: str) -> Dict: “””Whisper识别,返回完整文本和时间戳片段””” model = whisper.load_model(“base”) # 可选 “tiny”,”base”,”small”,”medium” result = model.transcribe(audiopath, wordtimestamps=True) return { “text”: result[“text”], “segments”: result[“segments”] # 每个段落的起止时间、文本 }
3. GPT 分析与文案生成
def analyzeviraltext(transcript: str) -> str: “””分析爆款要素””” if not client: return “[模拟分析] Hook吸引人,情绪递进,结尾号召。” prompt = f””” 你是一位顶级短视频运营专家。请分析以下爆款视频文案的成功要素: – 开头的Hook技巧(前3秒) – 内容结构(提出问题-反转-解决方案-金句) – 情感曲线(哪里高潮) – 高频关键词和记忆点
文案内容: {transcript[:2000]}
要求:简洁条目输出,不超过300字。 “”” try: response = client.chat.completions.create( model=”gpt-3.5-turbo”, messages=[{“role”: “user”, “content”: prompt}], temperature=0.5, max_tokens=500 ) return response.choices[0].message.content except Exception as e: print(f”[GPT错误] 分析失败: {e}”) return “分析失败,使用默认模板。”
def generateplans(analysis: str, originaltext: str, n: int = 3) -> List[str]: “””生成N个差异化脚本””” if not client: return [f”(模拟方案{i+1})这是一个参考原视频风格的爆款脚本示例。”] for i in range(n)]
prompt = f””” 根据以下爆款分析结果和原文案,生成{n}个全新的短视频口播文案(每个80-150字)。 要求: – 每个文案必须有不同的切入角度,例如:反转揭秘、情感共鸣、高效干货、对立观点、猎奇开头。 – 保留原视频的节奏感和Hook技巧。 – 文案需包含完整的口播内容,适合直接配音。 – 用【方案一】、【方案二】…标识每个文案。
分析结果: {analysis[:500]}
原文案参考: {original_text[:1200]}
请直接输出。 “”” try: response = client.chat.completions.create( model=”gpt-3.5-turbo”, messages=[{“role”: “user”, “content”: prompt}], temperature=0.8, max_tokens=1500 ) content = response.choices[0].message.content # 按【方案X】分割 plans = re.split(r’【方案[一二三四五六七八九十\d+]+】’, content) plans = [p.strip() for p in plans if p.strip()] if len(plans) < n: # 不足则补充 plans += [f”备选文案{i+1}: 基于原文风格改编。”] * (n – len(plans)) return plans[:n] except Exception as e: print(f”[GPT错误] 生成方案失败: {e}”) return [f”默认脚本{i+1}:这是一个通用的爆款口播内容。”] for i in range(n)]
4. Edge TTS 配音
async def ttsasync(text: str, outputaudio: str, voice: str = DEFAULTTTS_VOICE): communicate = edge_tts.Communicate(text, voice) await communicate.save(output_audio)
def texttospeech(text: str, output_audio: str) -> str: “””同步调用TTS””” asyncio.run(ttsasync(text, output_audio)) return output_audio
5. 对口型合成(Wav2Lip)
def wav2lipsync(facevideopath: str, audiopath: str, outputvideopath: str) -> bool: “”” 调用Wav2Lip官方inference.py生成对口型视频 成功返回True,失败返回False “”” if not WAV2LIP_DIR.exists(): print(“[Wav2Lip] 未找到Wav2Lip目录,跳过”) return False if not WAV2LIP_CHECKPOINT.exists(): print(“[Wav2Lip] 预训练模型不存在,请下载到 checkpoints/wav2lip_gan.pth”) return False
cmd = [ “python”, str(WAV2LIP_DIR / “inference.py”), “–checkpointpath”, str(WAV2LIPCHECKPOINT), “–face”, facevideopath, “–audio”, audio_path, “–outfile”, outputvideopath, “–pads”, “0”, “10”, “0”, “0”, # 裁剪边界(上右下左) “–resize_factor”, “1”, “–nosmooth” # 速度优先 ] try: print(f”[Wav2Lip] 开始合成: {outputvideopath}”) # 隐藏输出,只显示错误 subprocess.run(cmd, check=True, timeout=180, capture_output=True, text=True) print(“[Wav2Lip] 合成成功”) return True except subprocess.TimeoutExpired: print(“[Wav2Lip] 超时失败”) return False except Exception as e: print(f”[Wav2Lip] 错误: {e}”) return False
6. 备选方案:普通视频合成 + 字幕
def createsubtitleclips(text: str, audioduration: float, videosize: tuple) -> List[TextClip]: “””根据文案和音频总时长,简单拆分句子并生成字幕片段””” # 按句子分割 sentences = re.split(r'[。!?;]’, text) sentences = [s.strip() for s in sentences if s.strip()] if not sentences: return [] # 估算每个字符占用的时间 total_chars = sum(len(s) for s in sentences) if total_chars == 0: return [] timeperchar = audioduration / totalchars clips = [] current_time = 0.0 for sent in sentences: duration = len(sent) * timeperchar if duration <= 0: continue txt_clip = TextClip( sent, fontsize=40, font=”SimHei”, color=”white”, strokecolor=”black”, strokewidth=1, method=”caption”, size=(video_size[0]*0.9, None) ) txtclip = txtclip.setstart(currenttime).set_duration(duration) txtclip = txtclip.setposition((“center”, videosize[1]*0.8)) clips.append(txt_clip) current_time += duration return clips
def fallbackvideogeneration(script: str, facevideopath: str, outputvideopath: str): “””降级方案:将配音和字幕叠加到人物视频上(人物不张嘴)””” print(f”[降级] 为脚本生成普通视频: {outputvideopath}”)
# 1. 配音 audiopath = TEMPDIR / f”fallbackaudio{os.getpid()}.mp3″ texttospeech(script, str(audio_path)) audioclip = AudioFileClip(str(audiopath)) duration = audio_clip.duration
# 2. 处理人物背景视频 faceclip = VideoFileClip(facevideo_path) if face_clip.duration < duration: # 循环拼接 n = int(duration // face_clip.duration) + 1 faceclip = concatenatevideoclips([face_clip] * n) faceclip = faceclip.subclip(0, duration).setaudio(audioclip)
# 3. 生成字幕 subtitleclips = createsubtitleclips(script, duration, faceclip.size) finalclip = CompositeVideoClip([faceclip] + subtitle_clips)
# 4. 输出 finalclip.writevideofile( str(outputvideopath), codec=”libx264″, audio_codec=”aac”, fps=24, logger=None, verbose=False ) final_clip.close() audio_clip.close() face_clip.close() print(f”[降级] 完成: {outputvideopath}”)
7. 主控智能体
class LipSyncViralAgent: def init(self, openaikey: Optional[str] = None, openaibase: Optional[str] = None): global client if openai_key: client = OpenAI(apikey=openaikey, baseurl=openaibase) elif not client and openai_key is None: print(“[警告] 未提供OpenAI Key,LLM功能将使用模拟模式。”)
def process(self, originalvideo: str, facevideo: str, n_plans: int = 3): “”” 主流程 :param original_video: 爆款视频的本地路径或URL :param face_video: 人物空白动作视频(无口型,面部清晰)本地路径 :param n_plans: 生成不同脚本的数量 “”” # ———- Step 1: 提取原视频的文案 ———- print(“=”*50) print(“Step 1: 获取原视频文案”) print(“=”*50) if original_video.startswith((“http://”, “https://”)): videofile = TEMPDIR / “source_video.mp4” downloadvideo(originalvideo, video_file) sourcevideopath = str(video_file) else: sourcevideopath = original_video
audiopath = TEMPDIR / “source_audio.wav” extractaudio(sourcevideopath, str(audiopath)) transcript = transcribeaudio(str(audiopath)) original_text = transcript[“text”] print(f”原视频文案摘要: {original_text[:150]}…”)
# ———- Step 2: 爆款分析 ———- print(“\n” + “=”*50) print(“Step 2: GPT分析爆款要素”) print(“=”*50) analysis = analyzeviraltext(original_text) print(f”分析结果:\n{analysis}”)
# ———- Step 3: 生成N个脚本 ———- print(“\n” + “=”*50) print(f”Step 3: 生成 {n_plans} 个差异化脚本”) print(“=”*50) scripts = generateplans(analysis, originaltext, n_plans) for idx, script in enumerate(scripts): print(f”方案{idx+1}:\n{script[:100]}…\n”)
# ———- Step 4: 为每个脚本生成对口型视频 ———- print(“\n” + “=”*50) print(“Step 4: 合成对口型视频”) print(“=”*50) for idx, script in enumerate(scripts): print(f”\n>>> 处理方案 {idx+1}/{len(scripts)}”) # 4.1 TTS配音 audioplan = TEMPDIR / f”plan{idx}audio.mp3″ texttospeech(script, str(audio_plan))
# 4.2 输出路径 outvideo = OUTPUTDIR / f”lipsyncresult{idx+1}.mp4″
# 4.3 对口型或降级 success = wav2lipsync(facevideo, str(audioplan), str(outvideo)) if not success: fallbackvideogeneration(script, facevideo, str(outvideo)) else: print(f”✓ 对口型视频生成: {out_video}”)
print(“\n” + “=”*50) print(f”全部完成!共生成 {len(scripts)} 个视频,保存在: {OUTPUT_DIR}”) print(“=”*50)
8. 命令行入口
def main(): parser = argparse.ArgumentParser( description=”爆款对口型视频复刻智能体”, formatter_class=argparse.RawDescriptionHelpFormatter, epilog=””” 示例: python agent.py –video “https://v.douyin.com/xxxx” –facevideo “actor.mp4” –nplans 3 –openai_key “sk-…” “”” ) parser.add_argument(“–video”, required=True, help=”爆款视频URL或本地路径”) parser.addargument(“–facevideo”, required=True, help=”人物空白动作视频(面部清晰,无口型)”) parser.addargument(“–nplans”, type=int, default=3, help=”生成视频数量(默认3)”) parser.addargument(“–openaikey”, help=”OpenAI API Key(也可以设置环境变量 OPENAIAPIKEY)”) parser.addargument(“–openaibase”, help=”OpenAI API基础URL(如使用代理)”)
args = parser.parse_args()
agent = LipSyncViralAgent(openaikey=args.openaikey, openaibase=args.openaibase) agent.process(args.video, args.facevideo, args.nplans)
if name == “main“: main() 六、使用方法 6.1 准备素材 爆款视频:一个你希望模仿风格的短视频,可以是本地 .mp4 或网络 URL。
人物空白动作视频:一个 MP4 文件,画面中的人物面部清晰、全程不开口说话(可以微笑、眨眼、做动作)。建议长度 ≥ 最终配音时长(程序会自动循环)。
6.2 配置OpenAI Key(可选,但推荐) 方式一:修改 agent.py 中的 OPENAIAPIKEY = “sk-…”
方式二:命令行参数 –openai_key “sk-…”
方式三:环境变量 export OPENAIAPIKEY=”sk-…”
如果不提供API Key,程序将使用模拟模式(生成占位文案和分析结果),仍可正常合成视频。
6.3 运行命令 bash python agent.py –video “https://www.douyin.com/video/123456789” –facevideo “myactor.mp4″ –n_plans 3 6.4 输出文件 output/lipsyncresult1.mp4
output/lipsyncresult2.mp4
output/lipsyncresult3.mp4
每个视频都是根据新脚本生成的带口型同步的短视频。
七、高级配置 7.1 更换TTS语音 Edge TTS 支持多种语言和音色,例如:
zh-CN-XiaoxiaoNeural (女,默认)
zh-CN-YunxiNeural (男)
zh-CN-XiaoyiNeural (女,活泼)
修改 DEFAULTTTSVOICE 变量即可。
7.2 调整字幕样式 在 createsubtitleclips 函数中修改 TextClip 参数:fontsize、color、stroke_width 等。
7.3 使用GPU加速Wav2Lip 如果机器有NVIDIA GPU,Wav2Lip会自动使用(需安装CUDA版PyTorch)。安装方式:
bash pip install torch torchvision –index-url https://download.pytorch.org/whl/cu118 7.4 跳过Wav2Lip强制降级 如果不想使用对口型,直接删除 wav2lipsync 调用部分,或在代码开头设置 WAV2LIPDIR = None。
7.5 自定义GPT参数 在 analyzeviraltext 和 generateplans 函数中修改 model、temperature、maxtokens 等。
八、常见问题及解决 Q1: 下载报错 “yt-dlp: command not found” A: 确保安装了 yt-dlp:pip install yt-dlp,或重启终端。
Q2: Wav2Lip 运行时提示 “No module named ‘face_recognition’” A: 进入 Wav2Lip 目录,执行 pip install face_recognition(可能需要 dlib 编译,建议使用预编译包)。
Q3: 生成的视频口型不同步或效果差 A:
确保人物视频中面部角度正、光照充足、无遮挡。
调节 –pads 参数(默认 0 10 0 0),可参考 Wav2Lip 文档。
使用更高质量的视频源(分辨率≥256×256)。
Q4: 视频循环拼接后音频不同步 A: 程序会自动截取或循环使背景视频长度匹配配音时长,理论上不会出现不同步。
Q5: 字幕出现乱码 A: font=”SimHei” 在 Windows 有效;Linux/macOS 需改用中文字体,如 “WenQuanYi Zen Hei” 或提供完整路径。
Q6: 内存不足 A: 减小视频分辨率,或分批处理较长的视频。也可在 moviepy 调用时设置 audio_codec=’aac’ 减少内存占用。
九、扩展建议 接入更多对口型API:如 D-ID、Heygen,只需修改 wav2lip_sync 函数为HTTP请求。
自动加背景音乐:分析原视频BGM情绪,使用 pydub 混合背景音。
支持多语言:修改 TTS 语音和 Whisper 模型语言参数(如 language=”en”)。
Web 界面:用 Gradio 或 Streamlit 封装,上传素材即可生成视频。
批量处理:增加 –batch 参数,一次性处理多个爆款视频。
十、版权与伦理提示 本工具仅用于学习研究、内容创作辅助。请遵守各视频平台的服务条款,不用于恶意搬运或侵权。
生成的口型视频若涉及真实人物,需获得肖像授权。
OpenAI API 按 token 计费,注意控制生成字数。
附录:快速启动脚本(start.sh) bash #!/bin/bash
一键安装与运行(Linux/macOS)
python -m venv venv source venv/bin/activate pip install -r requirements.txt
克隆Wav2Lip(若未克隆)
if [ ! -d “Wav2Lip” ]; then git clone https://github.com/Rudrabha/Wav2Lip.git cd Wav2Lip pip install -r requirements.txt mkdir checkpoints wget -O checkpoints/wav2lipgan.pth ‘https://iiitaphyd-my.sharepoint.com/personal/radrabhamresearchiiitacin/_layouts/15/download.aspx?share=EdjI7bZlgApMqsVoEUUXpLsBxqXbn5z8VTmoxp55YNDcIA’ cd .. fi
运行
python agent.py –video “$1” –facevideo “$2” –nplans “$3” 用法:./start.sh “视频URL” “人物视频.mp4”