 夜雨聆风
夜雨聆风





中美 AI 算力差 3 倍?那是单卡,系统级差距远不止于此(上)
理工馆-AI Infra 分馆 · 深度分析 · 上篇
导语
4 月 23 日,斯坦福肖博士发了一段白板视频,在朋友圈刷了一轮屏。
视频里他用三列数字,把中美 AI 芯片的成本和功耗差距讲得很清楚——以等效华为 910C(530 亿晶体管)为基准,国产路线相比国际先进路线,单卡功耗 2.2 倍、BOM 成本 2.8 倍。结论是一句:”AI 架构需要重大突破。”
这两个数字本身没问题。
但它们停在了单卡这一层。
AI 训练的真实战场不在一颗芯片上,而在万卡集群里。从单卡到集群,中间有四层硬件要逐层穿透:芯片、模组、节点、集群。每一层都有差距,而且这些差距不是相加,是相乘。
把这四层乘起来,中美 AI 算力的真实差距远超 3 倍——基于公开信息的粗略估算,综合 TCO 差距大概在 5 到 8 倍这个量级。这是个数量级判断,不是精确数字,具体差距会因模型类型、训练框架、集群规模、电价区域剧烈波动。
而且这个 5-8 倍里,有一部分是劣势,有一部分——可能反而是中国 GPU 产业能存活并融资到现在的根本原因。
这是上下两篇的第一篇。上篇做论证:把肖博士的”芯片视角”延伸成”系统视角”,看清楚为什么真实差距是 5-8 倍量级。下篇做判断:讨论这个差距未来会怎么演化,以及哪一层最可能率先突破。
一、先把白板讲透:3 倍成本是怎么来的
肖博士这块白板的信息密度很高,值得先把它的逻辑完整复述一遍——但我会在每一行后面补一层”白板没说的”。
1.1 三种工艺路线的对比
锚点是”等效华为 910C 的算力,FP16 口径对齐”。在这个前提下:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
肖博士在白板下半段用两个除法把结论压成两个数字:
-
单卡功耗:500W ÷ 225W ≈ 2.2 倍 -
BOM 成本:1,750 ≈ 2.8 倍
这两个数字本身没有问题。问题在于它们容易被简单理解为”国产芯片就是落后 3 倍”——但这只是单卡 BOM 层面的差距,真正决定 AI 训练成本的不是单卡。
而且,国产那一列的 $5,000 究竟贵在哪里,白板没有展开。这是这一节要补的关键。
1.2 国产 $5,000 BOM,贵在哪?
国产先进路线的方案是:多重曝光 7nm + chiplet 双芯拼接。这条路在工艺上是成立的——多重曝光能在 7nm 设备上做出等效更先进制程的密度,chiplet 能把单颗芯片的面积压力分摊到两颗甚至四颗小芯片上。但代价是良率和封装的双重损耗。
把 BOM 翻一倍以上的因素,主要来自三项叠加:
第一,良率折损
7nm 单次曝光的成熟良率较高,行业惯例普遍在 80%+ 区间。但多重曝光的等效先进制程,工程实现复杂度高得多,良率显著下降——具体下降幅度因厂商工艺成熟度而异,公开拆解和行业研报的估算口径有较大波动。
良率下降的代价不是线性的:良率每降低一截,每颗合格芯片需要分摊的废片成本就上升一倍以上。这部分隐性成本会直接进入 BOM。
第二,先进封装
chiplet 双芯拼接的本质是”用封装弥补工艺”——既然单颗芯片做不到等效先进制程的密度,就把多颗小芯片拼起来。但这一步本身也有代价:KGD(已知良好裸片)良率要乘 KGD 良率,再乘封装良率,层层叠加。
而且更关键的是——CoWoS 类先进封装的产能本身被台积电掌控。国产 SoIC 类替代方案在工程上爬坡中,KGD 管理、热应力控制、信号完整性这些细节,都是要靠产能跑出来的经验。
第三,HBM 溢价
这是 AI GPU 真正的”卡脖子里的卡脖子”。HBM 在整卡 BOM 中占据相当大的比重——SK 海力士、三星、美光三家垄断 HBM 全球供应,产能本身就紧张。美国对中国直接限制 HBM3、HBM3e 的出口,这是比限制 GPU 本身还硬的卡点。
国产先进路线只能用 HBM2e 或更早代次,价格相对 HBM3e 没有优势,容量和带宽还更低。这部分的”被迫溢价”直接体现在 BOM 上。
把三项加在一起看,国产 GPU 贵,不是某一个环节贵,是被工艺受限逼出的全链路溢价。良率、封装、HBM 三个环节互相强化:工艺受限 → 良率下降 → 需要 chiplet 拼接 → 封装代价上升 → HBM 又被卡 → 整卡 BOM 翻倍。
这不是国产厂商不努力,是在受限工艺条件下做产品的必然结果——工程上能做出来已经是产业能力的体现,但代价就是这个 BOM。
1.3 但这只是第一层
到这里,肖博士白板的内容基本讲透了。
如果文章在这里结束,读者会得到一个清晰但不完整的印象:中国造一颗等效 H100 的芯片,要多花 3 倍的钱、烧 2 倍的电。
这个结论在单芯片层面是对的。
但如果你真的去训一个千亿参数的大模型,你会发现现实里的差距远不止 3 倍——因为 AI 训练根本不是在”一张卡”上发生的事。
下一节,我们把视角从一颗芯片拉到一个机柜、一个机房、一个万卡集群,看看每一层会再叠加多少差距。
二、从单卡到系统:真实战场在四层
要理解为什么”3 倍”只是冰山一角,需要先建立一个简单的画面——

一张 GPU 不会自己训练大模型。
它要先变成一张”卡”(加 HBM、加供电、加散热),再变成”一台机”(8 卡互联),再变成”一个机柜”(几十台机互联),最后变成”一个集群”(几千上万台机互联)。每往上一层,都要解决一个新的工程问题,也都会叠加新的中美差距。
这是 AI 算力真正的四层结构:
|
|
|
|
|
|
|---|---|---|---|---|
| Tier 1 芯片 |
|
|
|
|
| Tier 2 模组 |
|
|
|
|
| Tier 3 节点 |
|
|
|
|
| Tier 4 集群 |
|
|
|
|
下面逐层拆。
2.1 Tier 2:模组层——HBM 和卡间互联
一颗裸 die 不能直接拿去训模型,必须先封装成”卡”。这一步的核心是两件事:配多少 HBM,以及卡和卡怎么连。
HBM 容量与带宽
这是 AI GPU 真正的”硬指标”——它直接决定一张卡能装多大的模型分片、多长的 KV cache。容量不够,再强的算力也喂不饱。
按公开规格对比:
-
H100: 80GB HBM3 -
H200: 141GB HBM3e -
B200: 192GB HBM3e -
B300: 288GB HBM3e
国产先进路线目前主流方案以 HBM2e 为主,部分新方案在向 HBM3 推进,容量在 64-128GB 区间(具体配置因厂商和型号而异)。
容量上的差距是一方面,带宽差距更值得关注。HBM3e 的带宽接近 5 TB/s,HBM2e 在 1.6-1.8 TB/s 区间。一张卡每秒能”喂”给计算单元多少数据,是决定大模型训练效率的核心瓶颈之一——尤其是在长上下文、大 batch size 的场景下,带宽不足直接导致计算单元空转。
卡间互联
这一项的差距比 HBM 还大。
英伟达系(公开规格):
-
NVLink 4(H100):每卡 900 GB/s -
NVLink 5(B200):每卡 1.8 TB/s
国产卡间互联协议(如华为 HCCS、寒武纪 MLU-Link 等)在公开规格上,带宽普遍在 NVLink 同代产品的 1/4 到 1/3 区间——具体数字因厂商、型号、代次而异。
为什么这一项致命?因为大模型训练里,模型并行(TP)和流水线并行(PP)的本质就是”切开了让多张卡协同计算”——切完之后,每一步前向、反向都要在卡之间交换中间结果。互联带宽不够,卡再多,大部分时间是在等数据,不是在算。
这也是为什么很多国产 GPU “跑分不差但训不出大模型”——单卡 TFLOPS 数字好看,集群一组起来,有效算力就开始流失。
2.2 Tier 3:节点层——整机功耗和散热效率
8 张卡装进一台服务器,整机功耗不是简单的 8 × 单卡功耗。还要加上 CPU、内存、网卡、风扇、电源转换损耗。
按公开数据:
-
DGX H100(8×H100):整机峰值约 10.2 kW -
DGX B200(8×B200):整机峰值约 14.3 kW -
国产 8 卡服务器(基于 500W 卡):整机约 6-8 kW
乍一看国产整机功耗反而低?
这是个错觉。因为口径要从”单台机器功耗”换成”完成同等训练任务的总功耗”。
国产卡的有效算力低于同代英伟达卡(具体差距在 Tier 4 那一层会展开),意味着完成同样的训练任务,国产路径需要更多机器、更多电、更复杂的散热。把”完成同等任务”作为口径,国产路径的总能耗显著高于英伟达路径——具体倍数取决于工作负载,但方向是确定的。
更隐性的代价是数据中心层面。AI 服务器的 PUE(电源使用效率)关键看散热:
-
风冷数据中心:PUE 通常 1.4-1.6 -
液冷数据中心:PUE 可降到 1.1-1.2
液冷渗透率方面,国产数据中心正在快速提升,但目前仍低于美国新建 AI 集群的水平。这意味着每烧 1 度电用于计算,中国数据中心要额外烧 0.4-0.6 度用于散热;美国新建液冷集群只要额外烧 0.1-0.2 度。
这一层的差距在小规模时不显眼,但放到万卡级集群上,电费的乘数效应会被放大——具体怎么算,我们留到第三部分。
2.3 Tier 4:集群层——MFU 才是真正的底牌
这一层是全文最关键的一节。
衡量 AI 集群真实战斗力的指标不是 TFLOPS,是 **MFU(Model FLOPs Utilization,模型算力利用率)**。它的定义很简单:
MFU = 实际有效算力 ÷ 硬件理论算力
英伟达 H100 集群训练大模型时,公开论文报告的 MFU 普遍在 35-50% 区间。这是个跨多家公司的综合区间——Meta LLaMA 3 训练日志报告的 MFU 在 38-43%,Mistral、各类开源模型的训练报告也多在这个范围。
国产万卡集群训练大模型的 MFU,公开数据相对较少——已披露的部分数据普遍低于英伟达水平,但因厂商、模型、训练框架差异,具体数字波动较大。
仅从公开信息能得出的判断是:国产集群与英伟达集群在 MFU 上存在显著差距,这是中美 AI 算力差距中最难补的一项。
这意味着什么?
意味着即使国产单卡的纸面 TFLOPS 和 H100 一样(假设),在集群层面,国产能跑出来的有效算力仍会显著低于 H100 集群。同样训一个千亿参数模型,要么多用卡,要么多用时间——通常两者都要。
MFU 上不去的根本原因有三个:
-
互联带宽不够(已在 Tier 2 讲过) -
集群拓扑设计差距:英伟达有 Spectrum-X、Quantum InfiniBand、NVLink Switch 这一整套从单卡到机房的互联体系;国产万卡集群多以 RoCE(基于以太网)为主,在延迟和稳定性上还在追赶 -
训练框架成熟度:CUDA + cuDNN + NCCL + Megatron-LM 的工具链经过十几年打磨,国产 CANN、自研框架还在追赶——同样的硬件,框架不同,MFU 差几个百分点是常态
这就是为什么”国产算力够用”和”国产算力好用”是两件事。够用是说理论 TFLOPS 够,好用是说 MFU 够。前者靠堆芯片就能解决,后者要整个软硬件栈一起追。
2.4 入场券和真正的底牌
回到开头那张表。
白板上的 2.2 倍功耗、2.8 倍成本,只是这场竞争的入场券——它是 Tier 1 的差距,真实存在,但不是决定胜负的层级。
真正决定胜负的,是 Tier 2 到 Tier 4 这三层的系统级差距叠加。其中 Tier 4 的 MFU 差距是最致命也最难补的——因为它考验的不是单点技术突破,是整个软硬件栈的成熟度。
这种成熟度,英伟达用了 20 年(从 2006 年 CUDA 1.0 到现在)。国产路线要追上,需要的不是一个白板上的”重大突破”,而是一整套生态的工程时间。
下一节,我们具体讨论:这四层差距叠加起来,到底意味着什么。
三、为什么差距是相乘的
肖博士白板上的两个除法,做的是”芯片对芯片”的对比——这种对比方式天然只能得出”几倍”的结论。
但 AI 训练不是单芯片的事。当你把视角拉到”训出一个等效模型”的实际任务上,四层差距会同时发生作用,而不是依次叠加。
3.1 一个具体场景:训一个千亿参数模型
设想两条路径在做同一件事:训出一个千亿参数、效果对标某主流开源模型的大模型。
英伟达路径需要消化:
-
N 张 H100,以每张卡的硬件成本买入 -
持续运行若干个月,消耗对应的电费 -
集群整体在 35-50% 的 MFU 区间运行 -
数据中心 PUE 在 1.1-1.2 之间
国产路径需要消化:
-
单卡 BOM 显著高(Tier 1 差距) -
HBM 容量更小,意味着模型需要切得更碎,需要更多卡参与并行(Tier 2 差距) -
互联带宽更低,卡间通信开销更大,MFU 进一步压低(Tier 2 → Tier 4 传导) -
同等任务需要更多机器,总功耗显著上升(Tier 3 差距) -
散热效率更低,数据中心 PUE 更高,电费再上一个台阶(Tier 3 差距)
注意这五项的关系——它们不是五个独立的成本项相加,而是互相放大:
HBM 容量小 → 需要更多卡 → 互联开销更大 → MFU 更低 → 又需要更多卡补偿 → 又烧更多电 → 散热代价又上升……
这就是”相乘”的真实含义。每一层差距都在为下一层差距提供乘数。
3.2 量级判断:大概是 5-8 倍
把这五项叠在一起,基于公开信息做一个粗略估算:完成同等训练任务,国产路径的综合 TCO(总拥有成本,含硬件 + 电费 + 数据中心运营),大概在英伟达路径的 5-8 倍量级。
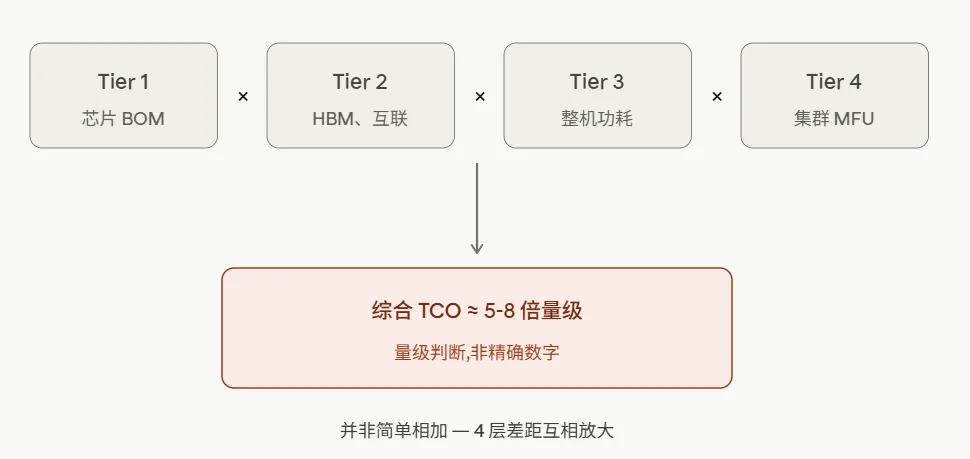
这是一个数量级判断,不是精确数字。
需要明确的限定:
-
具体倍数会因模型类型剧烈波动——稠密模型 vs MoE 模型,差距能差出 2 倍以上 -
训练框架成熟度差异,会让 MFU 浮动 5-10 个百分点,直接影响最终倍数 -
集群规模越大,通信开销占比越高,差距越显著 -
不同电价区域、不同散热方案,电费占 TCO 的比重不同
所以”5-8 倍”这个数字应该这样理解:它是个产业经验性区间,不是精算结果。读者可以拿它做”差距的量级感”,但不应该拿它做精确决策依据。
3.3 5-8 倍意味着什么
如果接受这个量级判断,几件原本不太好理解的产业现象,就有了解释:
为什么国内大模型公司的训练预算动辄按几十亿人民币计?
不是模型本身贵,是用国产算力达到等效效果的系统级溢价。同样一个训练任务,如果硬件路径贵 5-8 倍,预算自然要按这个倍数放大。
为什么字节、阿里、腾讯仍然在尽可能采购英伟达,即使有一堆国产替代摆在面前?
不是这些公司不支持国产,是5-8 倍的系统级溢价对企业的成本结构是真实压力。在管制允许的范围内,优先用英伟达是经济理性的选择;管制收紧后才被迫切到国产,这是产业现实。
为什么国产 GPU 公司估值能撑住,即使产品力距离英伟达还有差距?
因为这 5-8 倍的溢价对应着同样规模的产业空间——它既是负担,也是市场。国产 GPU 公司能存在并融资到现在,本质上是在分这个被迫产生的市场。
上篇小结
到这里,论证完成。
读者应该带走的结论:
第一,肖博士白板讲清楚了 Tier 1(芯片层)的差距——单卡 2.2 倍功耗、2.8 倍 BOM。
第二,真正的 AI 算力战场在 Tier 2-4 三个系统层级。HBM、卡间互联、整机功耗、集群 MFU,每一层都有差距,而且差距互相放大。
第三,把四层叠在一起,完成同等训练任务的综合 TCO 差距大概在 5-8 倍量级——这是产业经验性区间,不是精确数字,但它解释了几个原本不太好理解的产业现象。
下篇预告
5-8 倍这个量级会一直保持下去吗?
不一定。
未来 2-3 年,真正会决定中美算力差距走向的,不是制程,也不是 GPU 架构,而是三个肖博士白板上没出现的暗变量——先进封装、HBM 国产化、电力国情。它们决定了这 5-8 倍未来会变大,还是会缩小。
但更值得讨论的是另一个问题:这 5-8 倍的差距,有没有可能既是中国 AI 算力的劣势,也是中国 GPU 产业能存活到现在的根本原因?
下篇,我们会:
-
讲清楚三个暗变量的演化方向 -
完成基调翻转——这是落后,还是工程艺术? -
给出四条突破路径的概率排序,以及我自己押的方向
下篇见。
— 理工馆 · AI Infra 分馆