 夜雨聆风
夜雨聆风





2026本地AI神器!一键测电脑能跑哪些大模型,新手零踩坑
2026本地AI神器!一键测电脑能跑哪些大模型,新手零踩坑
想本地跑AI大模型,却不知道电脑能扛动哪款?算显存、估速度踩了无数坑?这个神器一键帮你全搞定。
90%的人本地跑AI,都踩了这个致命坑
2026年,本地部署AI大模型早就不是极客专属,不管是日常写文案、敲代码,还是玩逻辑推理、多模态生成,很多人都想摆脱在线API的限制,搞一套属于自己的本地AI环境。
但绝大多数新手,甚至不少老玩家,都卡在了最核心的第一步:不知道自己的电脑,到底能稳定跑哪些大模型。
我见过太多人踩坑:兴冲冲下载了几十G的70B大模型,结果显存不够直接打不开;好不容易找了8B模型,选错了量化等级,跑起来每秒1个token,卡到连对话都费劲;还有人为了跟风跑大模型,花大几千升级显卡,结果日常用根本用不上这么高性能,纯纯花了冤枉钱。
更别说不同模型的显存占用、上下文窗口、运行速度千差万别,光靠自己手动算参数、一个个下载试错,不仅浪费时间流量,还特别容易劝退。
直到我发现了www.canirun.ai这个宝藏网站,才发现原来本地跑AI的第一步,居然能这么简单。
2026本地AI玩家必备!这个网站到底有多香
这是一个专为本地AI玩家打造的大模型适配检测工具,不用下载安装、不用注册登录,打开浏览器就能用,核心功能精准戳中了所有本地AI玩家的痛点,用过一次就再也离不开。
一键自动识硬件,不用懂参数也能秒出结果
最让新手友好的一点,是它完全不用你手动输入复杂的硬件参数。
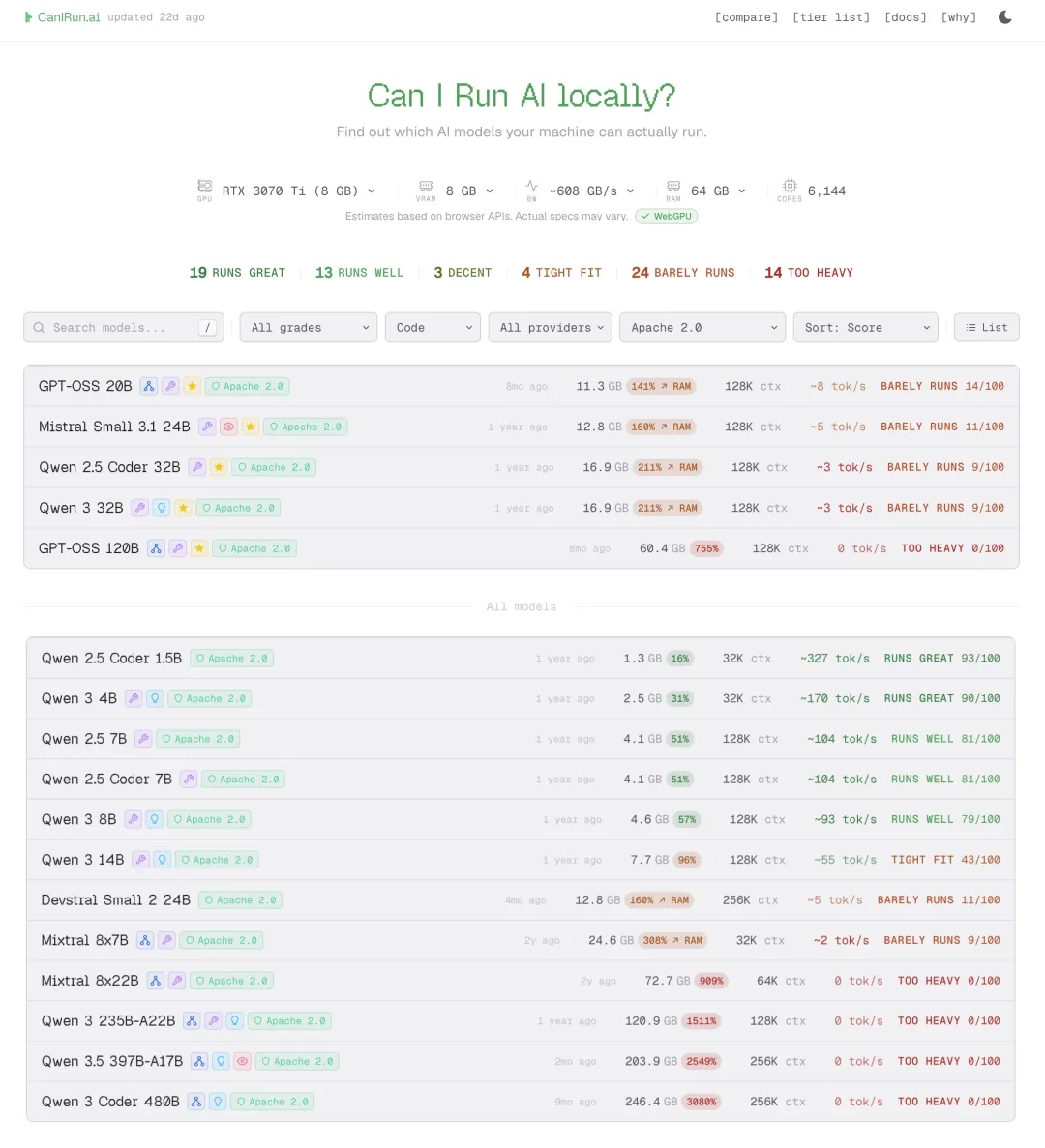
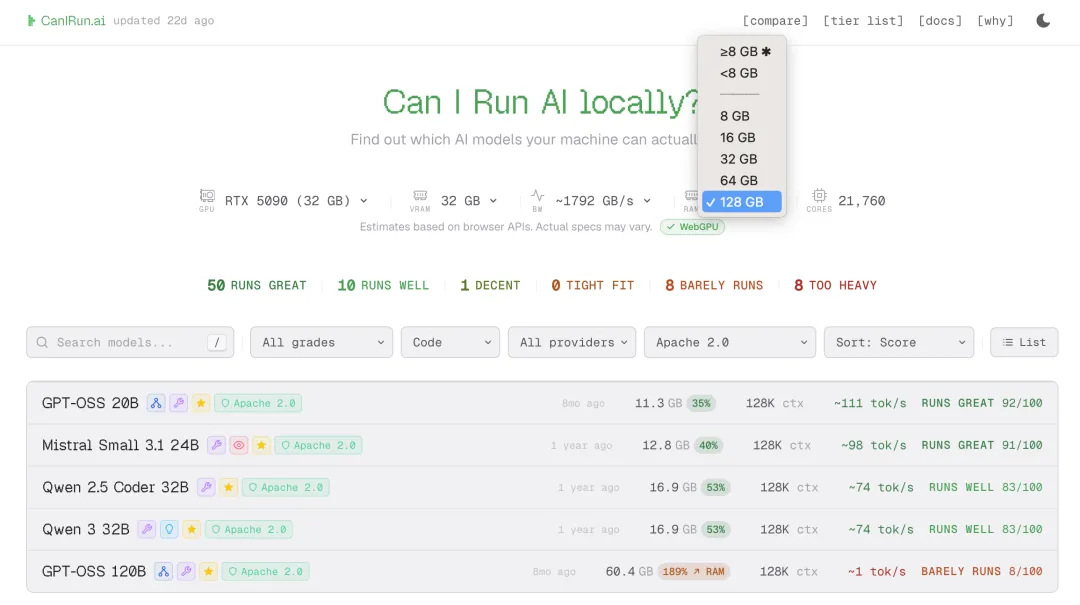
打开网站,它会通过浏览器API自动识别你电脑的全部核心配置,GPU型号、显存大小、显存带宽、运行内存、CPU核心线程数,1秒就能全部识别完成,同步生成专属的大模型适配报告。
全程不用你动手查参数、不用手动填数据,哪怕你完全不懂电脑硬件,也能一键看清自己的机器能跑哪些模型。我用自己的8G显存机器实测,打开网站瞬间就完成了识别,所有适配结果一目了然,连我这种折腾了好几年本地AI的老玩家,都觉得省心到不行。
精准分级评级,能不能跑、跑得多好一眼看清
这是网站最核心的功能,也是最实用的一点:它会根据你的硬件配置,给每个模型做清晰的运行评级,适配度、运行效果、预计速度全部标明白,不用你自己猜。
评级一共分为6个梯度,每个梯度都有明确的适配建议,新手也能一秒看懂:
-
RUNS GREAT:流畅运行,显存占用低,推理速度拉满,日常用无压力 -
RUNS WELL:表现优秀,效果与速度完美平衡,适合日常主力使用 -
DECENT:表现尚可,能稳定运行,速度略有下降,适合常规场景 -
TIGHT FIT:勉强适配,显存占用接近上限,能跑但不建议新手尝试 -
BARELY RUNS:几乎跑不动,速度极慢,仅适合极限测试 -
TOO HEAVY:完全带不动,硬件配置不达标,不用浪费时间下载
同时每个模型还会标注清楚最低显存占用、内存占用、上下文窗口大小、预计推理token速度、全系列量化等级,从Q2_K到F16的所有量化方案都给你列全了,你可以根据自己的需求,直接选到兼顾效果和速度的最优解。
自定义硬件参数,想换配置提前预判效果
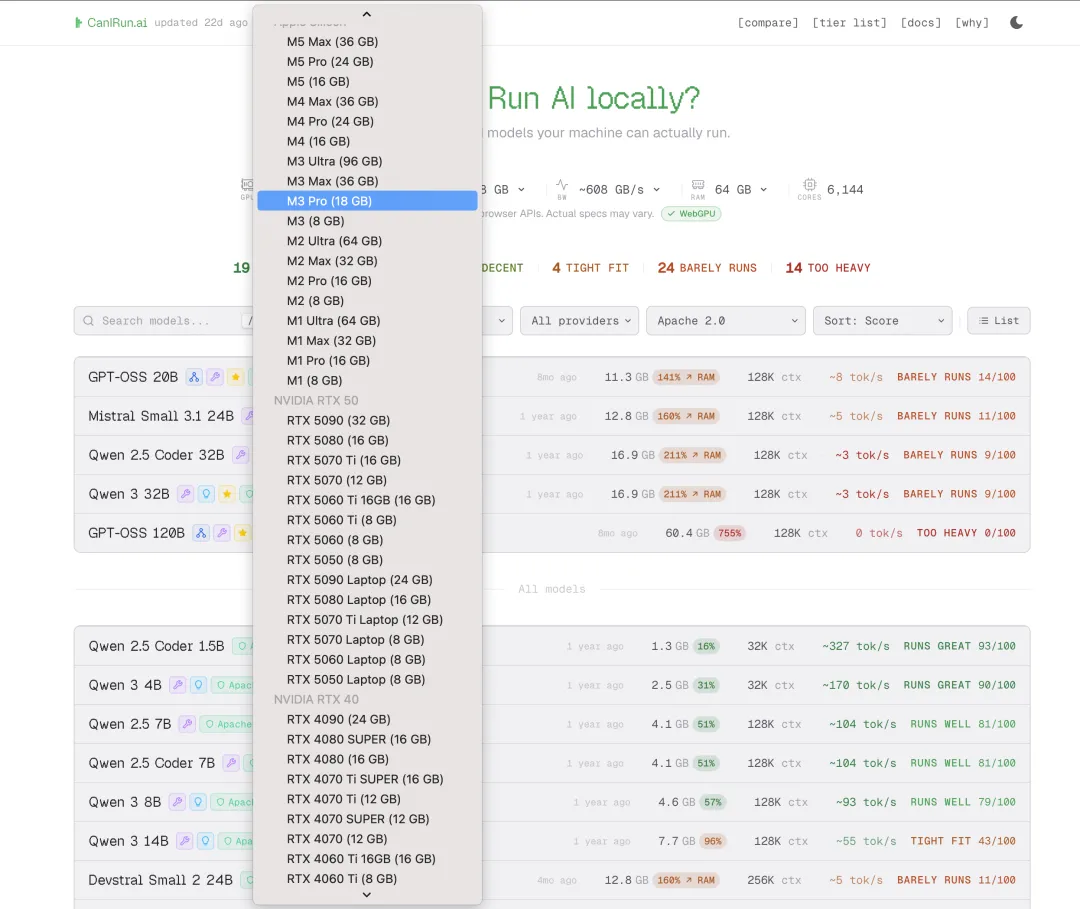
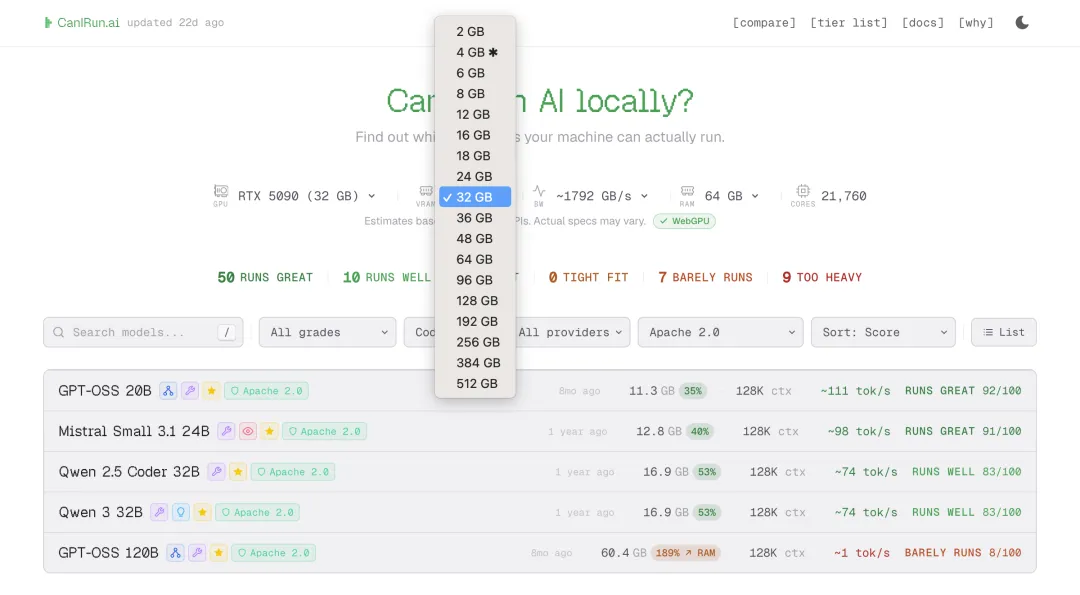
除了自动识别本机配置,网站还支持全手动自定义硬件参数,这对想升级硬件、或者准备入坑本地AI的玩家来说,简直是神器。
你可以自由选择:
-
GPU型号:从苹果M1-M3 Ultra全系列Mac,到NVIDIA RTX20/30/40/50系全型号显卡,全覆盖无遗漏 -
显存大小:2GB到512GB全档位可选,精准匹配你的目标硬件 -
显存带宽、运行内存、CPU核心数:所有核心参数均可手动调整
选好参数后,网站会实时生成对应配置的模型适配结果,不用等买回来才发现硬件不够用,提前预判效果,彻底告别盲目消费。
全模型实时更新,从边缘小模型到千亿大模型全覆盖
网站的模型库更新非常及时,覆盖了2026年市面上所有主流的开源大模型,完全不用担心找不到你想玩的型号。
从Qwen3 0.6B、Llama3.2 1B这种超轻量边缘模型,到Llama3.1 8B、Qwen3.5 9B这种主流中量级模型,再到几十B、几百B甚至上千B的旗舰大模型,比如DeepSeek R1、Llama4、Kimi K2,全都收录在内。
每个模型都标注得清清楚楚:发布时间、开源协议、模型架构、核心优势,甚至连适合的场景(对话、代码、推理、多模态)都给你分好了,新手也能快速找到适合自己的模型。
实测数据不忽悠,彻底告别无效试错
网站里的所有数据都不是凭空估算的,而是基于实际运行的实测结果,完全不会出现“标注能跑,实际根本带不动”的情况。
就拿我这台8G显存的机器来说,网站精准标注了:
-
Qwen3 0.6B超轻量模型,显存占用仅10%,推理速度可达每秒44token,流畅运行,日常对话完全够用 -
Llama3.2 3B模型,显存占用25%,推理速度每秒18token,表现尚可,写文案、敲代码都很流畅 -
Llama3.1 8B模型,Q2_K量化下显存占用57%,推理速度每秒8token,勉强能跑,适合想体验中量级模型的玩家 -
14B以上的密集模型,显存占用直接超过96%,完全带不动,直接帮你避雷,不用再浪费时间下载试错
想搭本地AI环境?它还是你的硬件选购神器
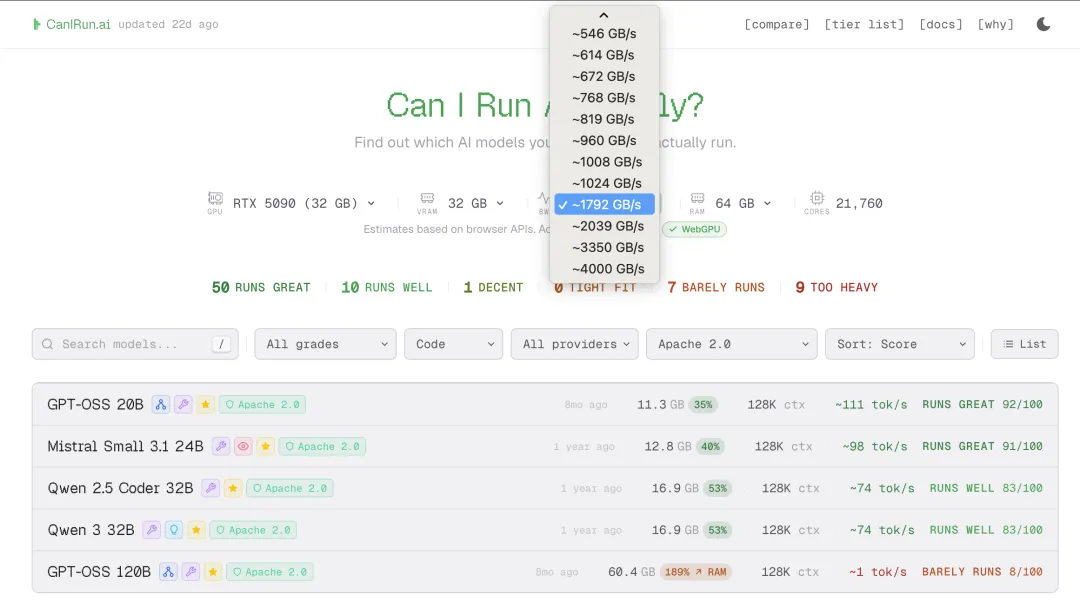
很多准备入坑本地AI的新手,都会遇到一个终极难题:到底该买什么显卡、配多大内存,才能满足自己的需求?
这个网站直接把这个难题解决了。
如果你想入手硬件搭建自己的本地AI大模型环境,完全不用瞎看攻略、听别人乱推荐,只需要在网站里输入你想跑的目标模型,再调整对应的硬件参数,就能精准判断这套配置能不能满足你的需求。
比如你想日常主力跑32B量级的模型,只需要在网站里选好对应模型,就能看到需要多大显存、多高带宽,再去选购对应的硬件,既不会买了低配用不了,也不会花大价钱买了性能过剩的硬件,把每一分钱都花在刀刃上。
2026本地AI玩家,用这个工具能省多少事
对新手来说,它直接帮你跨过了本地AI最高的门槛:不用再啃晦涩的硬件参数,不用再学怎么算显存占用,不用再一个个模型下载试错,打开网站就知道自己的电脑能玩什么,照着清单选,10分钟就能搞定本地部署。
对老玩家来说,它是最高效的选型工具:不用再反复测试不同量化等级的运行效果,不用再为了一个模型反复调试环境,网站直接给你实测好的速度和显存占用数据,快速筛选出最适合自己硬件的模型,少走无数弯路。
对想入坑的新手来说,它是最靠谱的选购指南:不用再被五花八门的硬件攻略绕晕,提前预判目标硬件的适配效果,按需选购,不花一分冤枉钱。
最后说句心里话:本地AI的快乐,从来都不是堆硬件
很多人觉得,本地跑AI就要上万的旗舰显卡,就要大显存、高性能,其实根本不是这样。
就像折腾黑苹果的快乐,从来不是用最贵的硬件装出最完美的系统,而是把手里的老硬件潜力榨干,用最少的钱,打造出最适合自己的环境。本地AI也是一样。
用对工具,哪怕是几百块的老电脑、普通的核显轻薄本,也能找到适合自己的模型,体验到本地部署AI的快乐,不用跟风升级硬件,不用为了用不上的性能花冤枉钱。
这个网站最难得的地方,就是它把本地AI的门槛,降到了几乎为零,让每个想玩本地AI的人,都能轻松找到属于自己的打开方式。