 夜雨聆风
夜雨聆风





对接文档不靠谱,我是怎么用 SQL 把数据摸清的

最近在做一个 AI Coding 的项目,需要从别的系统同步老师和学生数据。
问题来了:对方给了数据库接入,但字段说明几乎没有。
比如我现在要同步“学生”,但有一个关键问题:
❓ 学生有哪些状态?(正常?休学?退学?删除?)
如果不知道这个,我就没法写同步逻辑,比如:
-
要不要同步“退学”的?
-
“删除”和“注销”是不是一回事?
-
有没有历史状态?
01|最开始的路径:交互界面点点点(但很低效)
我一开始是用 DBeaver 直接在表里筛选,类似于Excel的筛选(这样👇)
这种方式的问题是:
-
只能“看”,不能“总结”
-
很难快速知道:有多少种状态?每种状态多少条数据?
-
非常依赖人工扫表
02|关键转折:学会这4行 SQL
后来刘老师教了我一个非常关键的方法:
SELECT -- 看哪个字段FROM -- 哪张表WHERE -- 条件(可选)GROUP BY -- 按什么分类
看起来很基础,但用在这里——直接起飞,接下来分享一下实战。我的问题是:❓ 学生到底有哪些“状态”?文档没有写,只能靠自己查。我怎么搞清楚“学生状态”的呢?

第一步:先找到“可能有用的字段”
打开学生表,开始“扫字段名”,发现了一个很像答案的字段:xsdqzt(学生当前状态)。
第二步:先别急着写复杂 SQL,只做一件事
看看这个字段到底有哪些值,最简单的写法是:
SELECT xsdqztFROM jinzhi_midd.t_xsjbxx
但这样有个问题:会出来几万条数据,根本看不过来。
第三步:用 group by 一键“去重 + 分类 + 统计”
这一步是关键👇
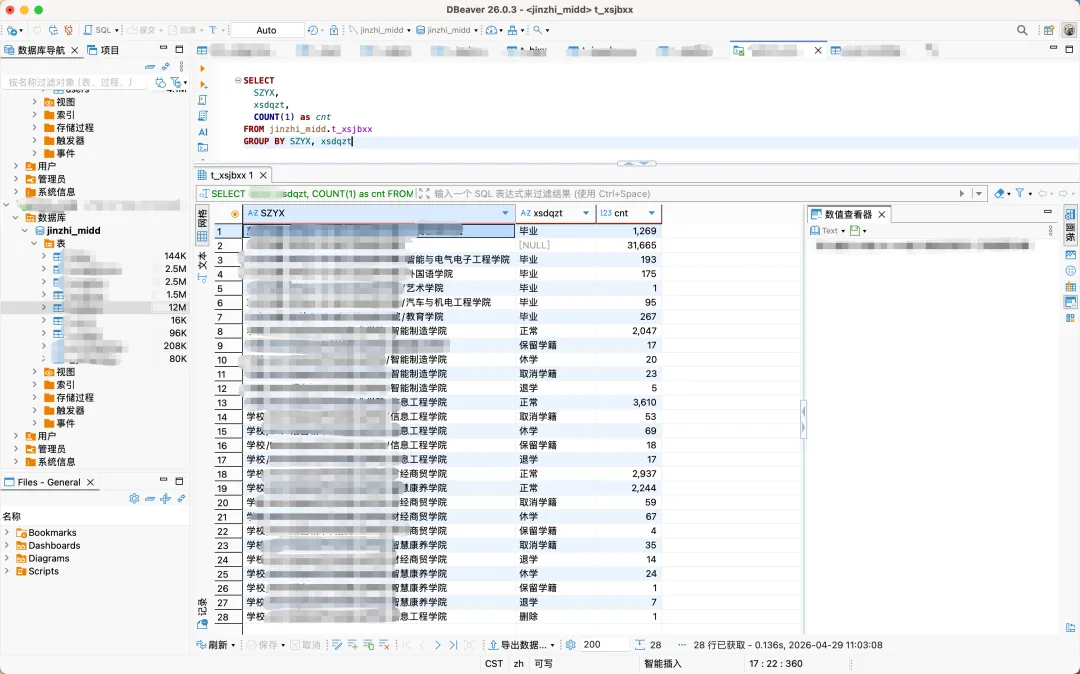
SELECTSZYX, -- 学院xsdqzt, -- 学生状态COUNT(1) as cnt -- 每种情况有多少条FROM jinzhi_midd.t_xsjbxxGROUP BY SZYX, xsdqzt
一眼就能看出:有哪些状态(枚举值)、每种状态大概多少人、不同学院有没有差异。
03|这一招到底解决了什么问题?
这一步其实做了三件非常关键的事情:
1. 枚举所有可能的状态,我不需要文档,数据库就是“真相”,可以看到:
-
正常
-
休学
-
退学
-
取消学籍
-
删除
2. 知道每种状态的数据量,对我判断“要不要同步”非常关键,比如:
-
正常:3000+
-
休学:几十
-
删除:极少
3. 反向推业务规则,比如:
-
“删除”是不是脏数据?
-
“取消学籍”和“退学”是否要区分?
-
只同步
正常 + 休学是否合理?
04|进阶一点:还可以这样用
✅ 加条件,只看某个学院
SELECT xsdqzt, COUNT(1)FROM t_xsjbxxWHERE szyx LIKE '%信息工程学院%'GROUP BY xsdqzt
✅ 分类统计,一下子就看出不同校区的差异SELECTCASEWHEN szyx LIKE '%哈尔滨%' THEN 'ha'ELSE 'yan'END AS city,xsdqzt,COUNT(1)FROM t_xsjbxxGROUP BY city, xsdqzt
✅ 找异常数据,快速发现奇怪的数据
SELECT *FROM t_xsjbxxWHERE xsdqzt NOT IN ('正常','休学','退学')
05|这件事让我重新理解 AI Coding

这次最大的感受是:AI 不会替你理解数据,它只会执行你的理解;
就像:我让 AI 同步学生数据,但没说清楚哪些学生要同步,那它只能瞎努力
不会 SQL,不影响你写代码但不会用 SQL 探数据,一定会拖慢做项目的进度
