 夜雨聆风
夜雨聆风





上海AI Lab开源具身操作仿真测评框架EBench:五维能力诊断+四类泛化测试重构评测方法论

极市导读
具身操作模型的评测,不应停留在总分比较,而应进一步回答模型“强在哪里、弱在哪里,以及这种能力是否真正可泛化”。围绕这一目标,EBench 从任务标签体系、泛化维度设计与评测协议三方面,对具身操作 benchmark 的方法论进行了系统重构。>>加入极市CV技术交流群,走在计算机视觉的最前沿
具身基座模型正在快速迭代,但社区对模型能力的理解仍然偏粗。我们常能感受到某个模型“更强了”,却很难回答:
它究竟强在长程任务、跨场景迁移、指令理解,还是精细操作?
更关键的是,benchmark 上更高的分数,究竟对应真实泛化能力,还是对特定测试集的适配结果?
这并非单个模型的问题,而是当前评测体系的共性限制:
-
真机评测成本高、复现难,难以支撑大规模标准化比较; -
许多仿真 benchmark 虽然具备标准化优势,但仍主要停留在成功率或总分层面,只能回答“是否做成”,难以解释“为什么做成”或“为什么失败”; -
当验证与测试边界不清时,benchmark 还可能退化为调参目标,导致评测结果与真实泛化能力脱钩。
基于此,上海 AI Lab 物理智能中心推出 EBench。它的设计目标并不是再提供一个总分榜,而是为具身操作建立一套可复现、可拆解、可比较的能力分析框架。在这套框架中,评测结果更像一份能力诊断报告,而不是单纯的成绩单。
目前,EBench 共包含 26 种任务,并从场景、原子技能、时长、精度、操作模式五个维度进行任务标注;同时覆盖物体、背景、指令、组合四类泛化维度,共 794 条测试任务,用于支撑对模型能力边界的细粒度分析。

相关链接
项目开源地址: https://github.com/InternRobotics/EBench
评测集 Hugging Face 下载链接: https://huggingface.co/datasets/InternRobotics/EBench-Dataset
评测集 ModelScope 下载链接: https://modelscope.cn/datasets/InternRobotics/EBench-Dataset
在线仿真评测平台: https://internrobotics.shlab.org.cn/eval
01 不止于“抓与放”的多样化移动操作任务集
为了反映真实环境中操作的时空多样性,EBench任务突破了单一场景内的拾取-放置循环,覆盖多样化场景下的单步抓放、移动操作、长程协同等操作模式,对模型的通用能力提出系统性挑战。

-
空间操作从二维平面走向三维纵深: 传统 benchmark 多将物体平铺于桌面,而 EBench 将交互对象嵌入具有纵深和层级的空间结构中:如洗碗机装载,需要在狭窄空间内完成下拉等纵向操作。
-
精度要求从粗放抓取走向毫米级对齐与动态调整: 齿轮安装不仅是插入,还涉及旋转角度的对齐与配合后的稳定性验证;这些任务将“放下去”提升为“调到位”,考验的是策略的细粒度控制与错误恢复能力,而非单纯的定位精度。
-
时序结构从单步动作走向长程规划与重规划: 水瓶装箱任务涉及多个物体的连续抓取、姿态调整与空间排布,任何中途失误都需触发重规划;这些任务天然要求模型具备跨步骤的动态纠错能力。
-
操作主体从单臂孤立走向双手与移动底盘的协同: 做水果奶昔任务要求双手配合完成物体的交接与姿态转换,这种多自由度、多执行器的协同模式,大大超出了单一机械臂在固定工位上的“抓-放”范式。
这些任务并非孤立地测试某一种原子技能,而是将抓取(Grasp)、放置(Place)、插装(Insert)、倒入(Pour)、翻面(Flip)、推扫(Sweep)、递交(Handover)等 11 种动作原语融合在具有真实操作语义的情境中。
每一个任务都被标注了五维标签:所属场景、涉及的原子技能、时序长度、精度等级、是否依赖底盘移动,使得评测天然具备诊断属性。
在此基础上,验证集与测试集的严格隔离,以及背景、指令、物体、组合四种泛化维度的独立扰动,确保了评测指向的是真实的跨分布能力,而非训练记忆。
02 五维原子诊断:把成功率拆成能力画像
传统 benchmark 往往用单一成功率概括复杂系统能力。这个数字直观,但对于具身操作模型来说,压缩得过于厉害。
一个较高分数,可能来自低精度任务上的稳定表现,也可能来自对某些任务配置的充分适配;但它并不能直接说明模型是否具备长程任务能力、精细控制能力,或在不同操作形态下是否稳定。
EBench 的思路,是把“任务成功”进一步拆解到具体能力维度中。
围绕具身操作中的关键能力因素,EBench 建立了五维任务标签体系:场景、原子技能、任务时长、操作精度和操作模式。其中,场景维度用于观察模型在不同视觉环境中的表现差异;原子技能维度用于拆解模型在基础操作技能上的能力分布;任务时长维度用于区分短程与长程任务中的稳定性差异;操作精度维度用于分析模型面对不同精度要求时的表现;操作模式维度则用于比较灵巧操作与移动操作之间的能力差异。
这样一来,benchmark 输出的不再只是一个总成功率,而是一组可拆解的能力画像。研究者可以进一步判断:某次性能提升究竟来自移动操作增强,还是来自低精度任务表现改善;某类失效主要发生在高精度操作中,还是出现在更长任务链条里。
换句话说,EBench 希望把“模型做成了没有”,进一步推进到“模型为什么能做成,以及在哪些条件下做不成”。
03 训测隔离:评估泛化,而不是记忆
当前具身评测中,一个常见但容易被低估的问题,是评测结果与训练过程之间的边界不够清晰。
如果验证任务和最终报告任务之间缺少隔离,benchmark 很容易变成一个可被反复适配的目标。模型分数提升,未必一定来自更强的泛化能力,也可能来自对固定任务模式、固定物体组合或固定场景配置的持续适应。
在这种情况下,分数上升并不等于能力提升。
为避免这一问题,EBench 采用验证集—测试集分离机制。验证集用于日常调参与快速迭代;小规模隔离测试集(Test)则用于在分布外条件下考察模型面对新物体、新背景、新指令和组合变化时的适应能力。
在此基础上,EBench 进一步构建了四类泛化测试:
-
物体泛化:考察模型面对新物体时的适应能力;
-
背景泛化:考察模型面对新环境变化时的稳定性;
-
指令泛化:考察模型面对不同任务表达方式时的理解与执行能力;
-
组合扰动:考察多种变化同时发生时的整体表现。
这四类泛化维度通过相对受控的方式进行设计,使性能变化能够更具体地归因到不同泛化因素,而不是停留在“换了测试集以后分数下降”的笼统判断。
此外,考虑到不同模型的能力边界并不一致,EBench 还提供 Specialist 与 Generalist 双轨入口。前者面向灵巧操作或移动操作等专项能力评测,后者则面向同时具备桌面与移动能力的模型进行统一测试,从而兼顾专项能力分析与通用能力比较。
04 从排行榜工具到能力测量框架
从方法论上看,EBench 并不是单纯增加任务数量,也不是把已有任务简单拼接成更大的 benchmark。它更关注的是:如何让评测结果能够稳定映射到模型能力本身。
五维原子诊断解决的是“能力如何拆开看”的问题;训测隔离与四类泛化测试解决的是“能力是否真实可迁移”的问题;高效评测基础设施则保证这套机制能够进入日常研发流程,而不是只服务一次性展示。
具身操作评测通常链路长、资源重、反馈慢。如果一次评测成本过高,再精细的指标体系也很难真正进入模型迭代流程。为此,EBench 开源了分布式评测工具,支持研究者进行本地高吞吐验证。
在 8 卡 4090 配置下,约 30 分钟即可完成验证集评测,便于模型训练过程中的快速回归测试。同时,平台也提供 7×24 小时在线评测服务,用户无需自行搭建完整运行环境,即可在统一协议下发起标准化评测。
因此,EBench 更像是一套具身操作模型的能力测量框架。它关心的不是谁又多涨了几分,而是这些分数对应了哪种能力,这种能力能否迁移到分布外任务中,以及模型的真实短板究竟位于哪里。
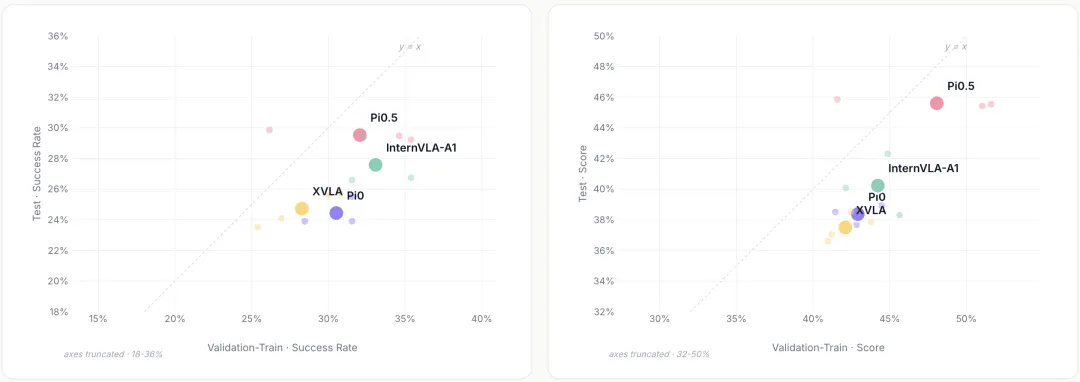
目前,EBench 已在 π0、π0.5、XVLA、InternVLA-A1 等代表性模型上完成首轮验证。结果显示,即使整体成功率处于相近区间,不同模型的能力结构仍可能明显不同。
例如,InternVLA-A1 在移动操作上表现突出,但在桌面固定操作上下降明显;π0 则在两类操作形态之间更加均衡。精度维度上,低精度任务中各模型差距有限,但进入高精度操作后,π0 仍保持相对领先,而 XVLA 与 π0.5 的表现下降明显。
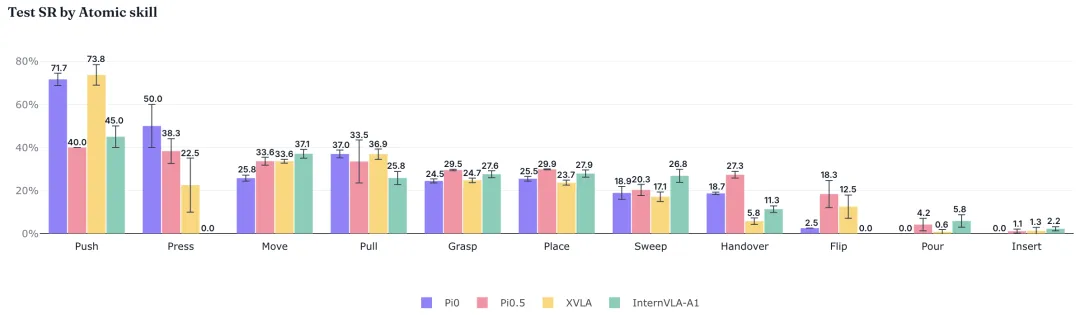
原子技能结果也显示,不同模型的优势并不完全重合。π0 在拉(Pull)技能上表现更好;XVLA 在推(Push)上更具优势,但在交接 / 递送(Handover)任务上相对较弱。
泛化测试进一步说明,背景变化和指令变化相对容易适应;新物体和多因素同时变化则更具挑战。
整体来看,物体泛化和组合扰动是当前模型更容易失守的两个环节。
在泛化性上,π0.5同样处于当前领先位置,在背景、物体、组合3个泛化维度上均优于其他模型,其中背景和前景物体泛化维度的优势最为明显。这在一定程度上解释了社区普遍对于π0.5预训练“好用”的体验——模型经过后训练微调仍具有较好的泛化性。
这也进一步说明,对于具身操作模型而言,单一总分并不足以支撑全面判断。更有效的评测体系,需要能够拆解能力、归因变化,并帮助研究者建立对模型泛化边界的清晰认知。
写在最后
欢迎感兴趣的伙伴体验在线仿真评测平台:
https://internrobotics.shlab.org.cn/eval

公众号后台回复“数据集”获取100+深度学习各方向资源整理
极市干货
点击阅读原文进入CV社区
收获更多技术干货