 夜雨聆风
夜雨聆风





驾驭工程:一个面向AI驱动软件工程的治理框架
26年3月来自韩国汉阳大学的论文“Harness Engineering: A Governance Framework For AI-driven Software Engineering”。
驾驭工程(Harness Engineering)——即将机器可执行的架构约束嵌入开发工具链中的实践——已在探索AI-驱动的软件工程各个组织中独立出现,但缺乏共享的分析词汇或正式定义。本文提供一个初步的概念框架。将一个驾驭(harness)定义为代码工件结构一致性的治理系统,并从三个维度组织架构工程:(1)上下文——为智体提供信息的声明性和过程性知识;(2)约束——管理智体输出的规则,涵盖代码生成前的指导和生成后的执行;(3)收敛——评估约束、识别差距并完善规则的迭代过程,直至驾驭达到结构幂等性:即重新应用不再产生任何结构变化的状态。本文阐明这种三元结构在包括 OpenAI、HashiCorp、Toss 和 Thoughtworks 在内的独立实践者中反复出现,他们在没有共享词汇的情况下,最终形成了类似的实践。该框架为新兴的治理实践提供一个共享的分析词汇,这种实践将注意从限制谁编写代码转移到限制哪些代码结构是允许的。
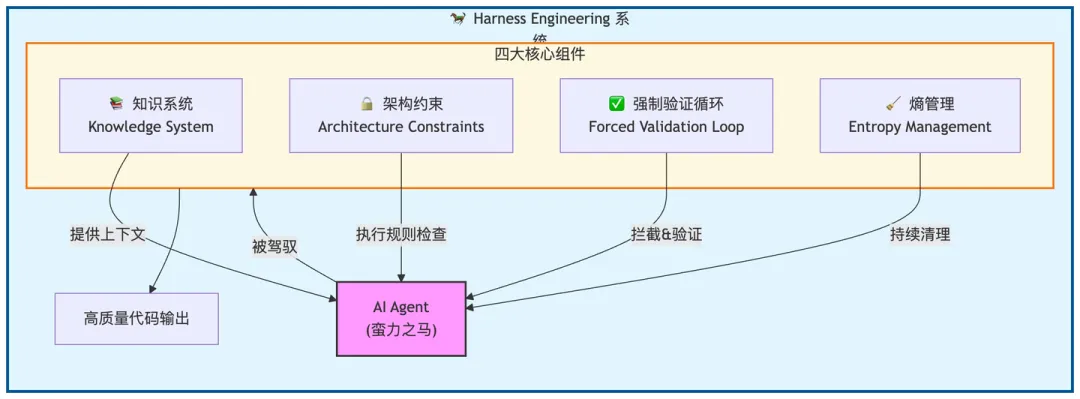
1 驾驭工程的出现
2026年2月,OpenAI发布《Harness Engineering: Leveraging Codex in an Agent-First World》[Lopopolo, 2026]一文,描述了一个由三名工程师组成的团队如何构建了一个包含百万行代码的产品,且没有一行代码是手动编写的。该文引入“harness engineering”一词,用以描述一种实践,即工程师的角色从编写代码转变为“设计环境、明确意图,并构建反馈循环,使Codex智体能够可靠地工作”。同时,Shoemaker [2026]等从业者主张放弃逐行代码审查,转而采用规范驱动、harness优先的验证方法,而Toss的行业工程师[Kim, 2026a]则提议通过插件市场建立组织级harness系统,以跨团队标准化人工智能工作流程。
这些观点都源于一个共同的认识:在代码日益由人工智能智体生成的世界里,代码的约束比代码本身更为重要。然而,现有的所有处理方法都是非正式的——博客文章、推特帖子、会议演讲——缺乏严格推理驾驭系统、比较实现或预测其属性所需的理论精确性。
2 前体:治理已追踪生产
确定性结构治理的需求并不新鲜;新的是概率代码生成所带来的紧迫性。之前的实践确立驾驭工程所依赖的原则。Ruby on Rails 推广了约定优于配置的理念[Hansson, 2004],通过将治理嵌入框架的生成器中,减少了结构决策。Protocol Buffers 和 Prisma 等模式(schema)驱动工具使声明式规范成为代码结构的唯一来源,消除了所有类别的结构差异。最直接的是,基础设施-即-代码工具——尤其是 Hashimoto 创建的 Terraform[2026]——将幂等(idempotent)状态收敛确立为工程规范:无论应用配置多少次,基础设施都会收敛到相同的声明状态[Hummer et al., 2013, Morris, 2016]。静态分析工具从漏洞检测[Johnson, 1978]演变为架构执行[Beller et al., 2016],尽管它们在特定于项目的结构治理中的应用仍未得到充分探索。
这些实践中的每一种都解决了其各自生产范式中的结构性差异。当前时刻的不同之处在于,大语言模型(LLM)驱动的代码生成使生产本身具有概率性:相同的提示在不同的运行、模型和智体中会产生结构上不同的输出。从确定性时代继承下来的治理机制——文档、约定、指令文件——并非为这种模式而设计。正如所阐述的,驾驭工程是对这一差距的回应。
3 人工智能驱动软件工程中的架构熵
软件工程领域一直面临着差异性的挑战。不同的开发人员对相同的需求有不同的解读,构建代码的方式不同,命名方式也不同。代码审查、风格指南和结对编程作为社交机制应运而生,用以管理这种差异性。
人工智能驱动的软件工程的出现从根本上改变了这一局面。大语言模型(LLM)能够在几秒钟内生成数百行语法正确、功能无误的代码。安德烈·卡尔帕西(Andrej Karpathy)在2025年创造的“氛围编码”(vibe coding)一词[Karpathy, 2025]描述一种开发实践,即程序员用自然语言指定意图,然后由人工智能生成实现。当一个代码库同时接收来自人类开发者A、人类开发者B、人工智能模型X和人工智能模型Y的贡献时,每个参与者都会带来自己对文件组织、命名约定、依赖方向和架构分层方面的隐含假设。其结果是架构熵——结构一致性的逐渐削弱。
OpenAI团队直接观察到了这一点:“Codex复制存储库中已经存在的模式——甚至是那些不均匀或次优的模式。随着时间的推移,这不可避免地会导致偏差”[Lopopolo, 2026]。他们的应对措施——编码“黄金原则”并运行定期清理代理——是对所阐述的收敛约束执行的操作性描述。
4 基于提示的治理的局限性
目前针对人工智能代码差异的缓解策略主要是基于概率的:
• 提示工程(例如,CLAUDE.md、.cursorrules、AGENTS.md):能提高合规的可能性,但不能完全保证。
• 人工代码审查:对人工智能生成的输出进行人工审查,随着人工智能处理能力超过人类注意力容量,这种做法越来越不切实际。
• 微调:在特定项目的语料库上训练模型,需要大量投入,但随着模型更新的进行,投入的回报逐渐递减。
OpenAI自己也发现了这一局限性:“尝试‘一个大文件AGENTS.md’的方法。结果不出所料地失败了……过多的指导反而变成了非指导”[Lopopolo, 2026]。Toss Tech博客也阐述同样的差距:“即使使用相同的模型和集成开发环境(IDE),输出的差异也极大”[Kim, 2026a]。
本文提供一个互补的视角:一个针对架构约束的治理框架,旨在产生一致的结构化结果,而无论创作主体是谁。
1 治理工程行业话语
“控制工程”一词因OpenAI 2026年2月的博客文章[Lopopolo, 2026]而流行开来。大约在同一时期,几位从业者分别以不同的名称描述了类似的实践[Zakas, 2026, Shoemaker, 2026, Kim, 2026a]。所有描述都分享了一个共同见解——工程师的产出正从代码转向约束——但均未提供正式的定义或分析框架。我们在第4节中将这一趋同现象作为首要证据进行分析。
2 软件架构侵蚀与技术债务
Perry和Wolf[1992]提出了软件架构的基础模型,并指出了架构侵蚀问题——即随着实现决策违反预期约束,架构完整性逐渐退化。de Silva和Balasubramaniam[2012]对侵蚀控制文献进行了综述,将方法分为面向过程(评审、文档化)、面向架构(正式的架构描述语言、反思模型)和面向工具(一致性检查器)三类。我们的工作属于面向工具的类别,但操作粒度比传统方法更精细:文件命名、导出模式和函数排序,而非模块级依赖关系。
Baldwin和Clark[2000]将设计规则(即解耦模块并实现独立演化的约束条件)形式化。他们提出的“少数几条强大的设计规则可以支配许多独立模块的行为”这一见解与线束工程直接共鸣:一小套规则可以支配整个代码库中的结构决策。关键区别在于,鲍德温和克拉克的设计规则是系统设计师做出的架构决策,而线束规则则是机器强制执行的约束条件,对所有创作代理具有同等约束力。
Cunningham[1992]引入了技术债务这一比喻,用以描述那些权宜之计但结构上欠佳的决策所带来的成本。治理工程可以被理解为一种预防机制,旨在防止特定类型的技术债务:即由不同创作主体引入的结构不一致性。技术债务通常通过重构来偿还,而治理规则则从源头上防止债务的产生。
3 静态分析与架构一致性
静态分析的出现早于现代软件工程。Lint [Johnson, 1978] 曾分析 C 源代码中的可疑构造。现代代码检查工具(如 ESLint、Prettier、RuboCop、Clippy)已从缺陷检测扩展到风格规范执行,但它们在架构规范执行方面的应用在文献中尚未得到充分探讨。Beller 等人 [2016] 对 122 个开源 Java 项目中静态分析工具的使用情况进行了大规模评估,发现虽然 Checkstyle 和 PMD 等工具被广泛配置,但它们的规则很少能执行超出基本风格之外的架构约束。
架构一致性工具,如ArchUnit [Gafert, 2019](Java)、deptrac(PHP)和Dependency Cruiser(JavaScript),用于验证依赖规则,但它们是在模块或包级别上操作的。Knodel和Popescu [2007]比较了六种静态一致性检查方法(反射模型、关系一致性规则、依赖配置文件等),这些方法都针对模块间的依赖。但没有一种方法能处理文件命名、导出模式或函数排序等日常结构决策层面的问题——而这正是治理工程所运作的层面。
Allamanis[2014]提出了一种机器学习方法,用于从现有代码库中推断编码规范,证明了规范是可学习的模式。这与我们的方法相辅相成:Allamanis等人以描述性的方式学习规范,而Harness Engineering则通过确定性规则以规定性的方式强制执行这些规范。
4 约定优于配置
Ruby on Rails 推广了“约定优于配置”(CoC)[Hansson, 2004]的理念,通过设定默认值来减少开发者的决策。CoC 理念虽然有效,但仅限于特定框架:它管理着 Rails 生态系统中的路由、对象关系映射(ORM)映射和资源路径。它并不能泛化到任意架构模式。Harness 工程将 CoC 理念扩展到框架之外:自定义 lint 规则将特定于项目的约定编码为可执行的约束,适用于任何架构。
5 软件系统中的幂等性、汇合性与收敛性
幂等性在分布式系统(HTTP方法[Fielding, 2000])、基础设施即代码(Terraform、Ansible[Morris, 2016])和数据库迁移中得到了深入研究。Hummer等人[2013]对基础设施即代码(Infrastructure as Code, IaC)的幂等性测试进行了形式化,证明无论配置脚本被应用多少次,都应产生相同的系统状态。虽然IaC幂等性关注的是基础设施状态收敛,而非代码结构收敛,但其基本原理——即重复或重新排序应用声明性规则应产生相同的结果——与我们所定义的线束工程中的汇合性类似。形式意义上的汇合性——即不同归约路径产生相同范式的性质——源于项重写理论[Church and Rosser, 1936],并广泛应用于编译器优化和编程语言语义。我们借鉴后者的概念来描述架构约束的实施,同时承认IaC传统是在不同抽象层次上对类似收敛性质的独立探索。
从三个维度组织驾驭工程(harness engineering):上下文、约束和收敛。这种三方结构反映了循环论和自主计算中建立的基本控制回路——观察状态、应用控制、迭代反馈。不主张形式证明或普遍保证,而是将其作为基于从业者观察的分析维度来阐述。
1关键概念和定义
创作智体(authoring agent)是任何产生源代码的实体:人类开发人员、人工智能编码助理或自动化管道。驾驭(harness)是一种用于代码工件结构一致性的治理系统,由跨开发工具(linter、类型检查器、格式化器、CI门)协调的机器可执行规则组成。代码工件的结构签名(structural signature)是其架构相关属性的元组——文件路径、命名、目录放置、导出、导入、函数排序——明确排除实现逻辑。
2 维度1:背景
上下文是通知创作智体的知识。区分两层:
声明性知识
智体可以引用的事实、状态和结构:文档(docs/)、API模式、代码库结构、数据库模型和依赖关系图。陈述性知识回答了存在的问题。如果没有它,智体将生成结构上合理但事实上错误的代码,例如,导入不存在的模块或使用不推荐使用的API。
程序知识
指导判断的原则、决策方法和架构模式:命名约定、分层规则、依赖方向策略和模式选择标准。过程知识回答如何做出决定。它甚至在没有特定声明性知识的情况下也能运行——例如,“有疑问时,更喜欢组合而不是继承”适用于任何特定的代码库。
上下文差距。当前的驾驭工程话语将这两层混为一谈,并贴上“上下文工程”或“知识库”的标签。区分它们在分析上很有用,因为它们的失败方式不同:缺少声明性知识会产生事实错误(错误的导入、不存在的API),而缺少过程性知识会导致判断错误(以错误的模式正确编码)。
区分上下文和约束。上下文和约束可能看起来重叠,特别是因为两者可以驻留在同一介质中(例如,AGENTS.md文件)。区别不在于媒体,而在于言语行为:上下文是描述性的——它说明了存在什么,系统的结构如何,以及使用了什么模式(例如,“我们的API使用带有JSON响应的REST”)。约束是规定性的——它规定了必须或不必须做什么(例如,“文件名始终使用kebab大小写”)。单个指令文件可能包含描述性上下文和规定性约束;该框架根据功能而不是位置来区分它们。在约束中,指导和执行之间的进一步区别反映了是否可以机械地验证合规性:指导是规定性的,但不可验证(智体可能会也可能不会遵守),而执行是规定性和可验证的(工具链产生二元通过/失败判断)。相同的架构原则可能出现在两个维度上:作为Context中的程序指南,以及作为Constraint中的可执行规则。这不是冗余,而是分层治理——Context通知智体的意图,而Constraint验证智体的输出。
3 维度2:约束
约束是管理智体输出的一组规则。根据它们与创作事件的时间关系来区分两层:指导(创作前)和执行(创作后)。
指导
在生成代码之前塑造智体行为的规则:指令文件(AGENTS.md、CLAUDE.md、.cursorrules)、系统提示、少样本示例和结构化任务分解。引导是概率性的——它增加合规输出的可能性,但不能保证它。正如OpenAI所发现的,“尝试了‘一个大的AGENTS.md’方法。它以可预测的方式失败……过多的引导变成非引导”[Lopopolo,2026]。
执行
生成代码后评估和转换代码的规则:linter、类型检查器、格式化器、架构一致性工具、CI门和自动修复转换。执行过程是确定的——它要么传递代码,要么拒绝代码,而不管是哪个代理生成的。
执法范围。指导和执行涵盖一系列执法力量,如表1所示。
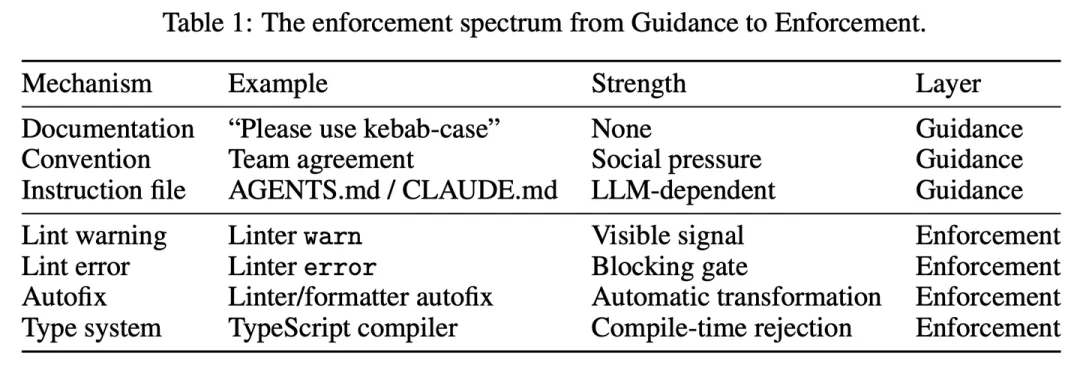
关键的分界线在于中层表观差异。前代控制主导着当前的驾驭工程讨论;后代控制则提供了确定性保证,使结构收敛成为可能。
选择空间缩减作为累积效应。生成前和生成后的控制措施通过三种增强机制逐步缩小允许的结构决策空间:(1)选择消除——强制采用单一选项(例如,kebab-case文件名),(2)选择引导——限制为精选词汇(例如,*Model、*Repository、*Adapter后缀),以及(3)选择规范化——确保无论做出何种选择,自动修复都能收敛到相同的结构结果(例如,函数排序规则)。
智体独立性作为必然结果。当生成后的约束足够全面时,编写智体的身份对结构结果变得无关紧要。无论是开发者A、开发者B还是Claude Code实现某个功能,该驾驭都会执行相同的结构签名。代码质量(在结构层面)成为该驾驭的特性,而非编写者的特性。
4 维度3:趋同(评估/改进)
收敛是驾驭向完整性进化的迭代过程。驾驭开发分为H_0 ⊂H_1 ⊂ ···H_n阶段,其中每个H_i都解决了仅在应用H_i-1后才可见的模式。四个因素使得预先完成规范不切实际:
-
1.域协同进化。只能为存在的域编写约束。在设计智体子系统之前,无法阐明特定于代理的规则。 -
2.约束交互。规则以不明显的方式相互作用。每个约束层都揭示了需要调整的交互效应。 -
3.模式出现。在代码库达到足够大的规模之前,架构反模式通常是不可见的。 -
4.经济上不可行。提前写下所有约束条件需要预测未来的每一个架构模式——一个成本随着代码库复杂性而增长的任务。
结构幂等性作为收敛准则。收敛过程需要一个终止条件:如何知道驾驭足够完整?采用结构幂等性标准[Kim,2026b]:当重新应用其规则不会产生进一步的结构变化时,驾驭已经收敛。形式上,设P表示应用于代码库状态σ的所有驾驭规则的复合变换,设O为结构观测值。当O(P^2^(σ))=O(P(σ)时,驾驭已经收敛。
Kim[2026b]的一个关键结果加强这一标准:对于任何定义良好的变换,P: ∑→ ∑,存在一个观测O,在该观测下结构幂等性成立。然而,只有当O是非平凡的时,这种存在性声明才有用——一个将所有状态折叠成一个的平凡观察将空洞地满足条件。在框架(framework)中,O被实例化为结构签名:文件路径、命名、目录放置、导出、导入和函数排序的元组。这一观察既不是微不足道的(它区分了结构上不同的工件),也不是自身(它故意排除了实现逻辑)。因此,问题不在于驾驭是否可以收敛,而在于所选的结构签名在重新应用下是否保持稳定。此外,一旦O(P^2^(σ))=O(P(σ)。这意味着可以通过一次重新应用来测试收敛性——不需要无限次迭代。
该标准在操作上是可测试的:运行执行管道(linter、formatter、类型检查)两次;如果第二轮没有产生任何变化,则该代码库状态的驾驭已经收敛。当O(P^2^(σ))̸=O(P(σ)。
路径独立收敛。设计良好的驾驭表现出与路径无关的收敛性:不同的规则引入顺序会导致相同的结构结果。这个属性类似于术语重写中的汇流(confluence)[Church&Rosser,1936],使增量开发变得安全。许多lint规则是声明性谓词,而不是顺序转换,这使得路径独立性在实践中是可以实现的,尽管规则交互和自动修复冲突意味着它必须被视为工程成就,而不是自动保证。
5. 三个维度之间的相互依赖性
三个维度构成了一个相互强化的系统,如表2所示:无约束的上下文提供知识但不强制执行。无上下文的约束会产生与架构意图脱节的规则。两者若无融合,则会产生一个静态的驾驭(harness),无法适应不断演变的代码库。三个维度共同构成一个治理循环:上下文为智体提供信息,约束管理其输出,融合评估结果并将差距反馈到上下文和约束中,以进行下一次迭代。
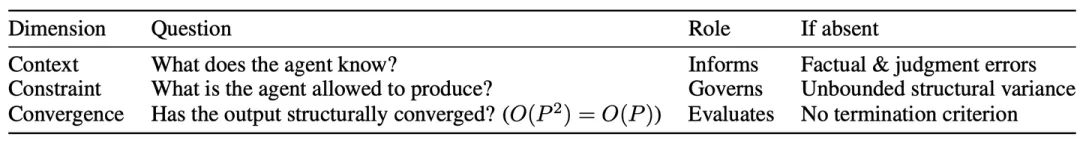
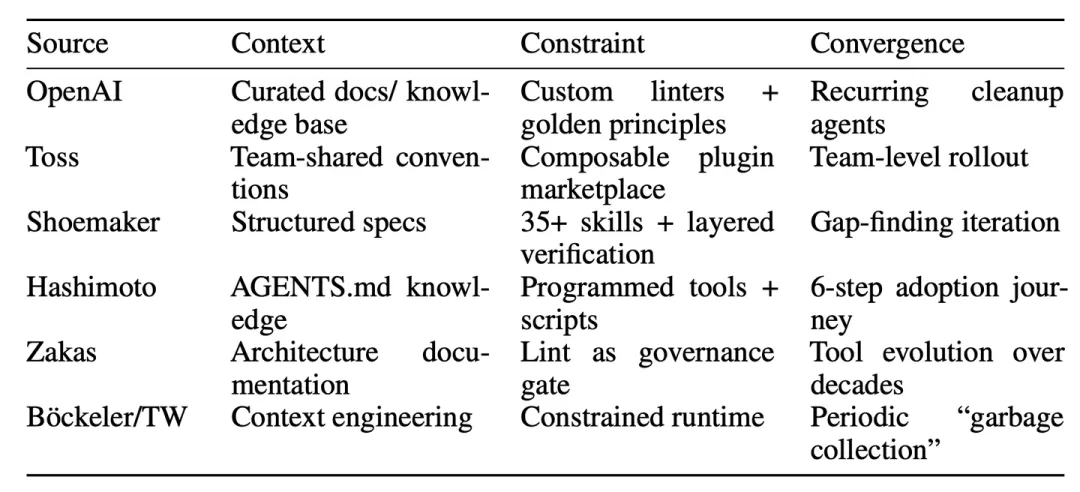
前面的概念框架不是孤立得出的。为了将框架付诸实践,调查截至2026年3月发布的从业者账户,这些账户描述了人工智能生成代码的具体治理实践。选择六个账户,它们(a)描述特定的工具、工作流程或组织机制,而不是一般性的评论,(b)是在相互影响最小的情况下编写的——虽然一些来源引用OpenAI的“驾驭工程”一词,但它们所描述的实践是独立开发的。由此产生的集合涵盖了不同工具链和规模的单个工程师、初创公司和大型组织。这种趋同的出现表明,潜在的现象是实质性的,需要一个共享的词汇。
1 跨尺度独立发现
OpenAI:大规模熵管理
OpenAI的“驾驭工程”帖子[Lopopolo,2026]描述一个由三名工程师组成的团队,他们用零手动编写的代码生成了一百万行代码库。他们的核心发现是,人工智能智体复制了现有的模式,包括次优模式,导致了渐进的架构漂移。他们的反应映射到所有三个维度:
•背景。一个精心策划的文档/知识库,从最初的“一个大的AGENTS.md”演变而来,“以可预测的方式失败”,为智体提供声明性和过程性知识。
•约束。自定义linters执行“黄金原则”(依赖方向、命名约定),无论哪个Codex智体执行任务,都能产生一致的结构结果。
•融合。重复的清理智体执行“熵管理”,迭代地识别和纠正执行点之间的结构漂移。
Toss:作为组织治理的可组合约束
Kim[2026a]从组织上构建了驾驭工程。在韩国最大的金融科技公司之一Toss工作时,作者观察到“即使使用相同的模型和IDE,输出差异也是极端的。”提出的解决方案——一个将lint规则、Git策略和测试策略作为可安装包分发的插件市场——将上下文Context(团队共享约定)和约束Constraint(可组合执行规则)嵌入到可分发单元中。可组合性要求意味着路径无关的收敛:团队负责人可以以任何顺序安装约束包,而不必担心交互效应。
这种组织框架(organizational framing)增加OpenAI账户中缺少的一个维度:将驾驭工程作为一种团队协调机制,其中约束集成为具有不同技能水平的工程师之间的共享合同。
Shoemaker:分层验证作为方差减少
Shoemaker[2026]阐述了最明确的方差减少策略。他的开发工作流程包括35+技能(执行)、结构化智体指令(上下文)和分层验证,包括跨模型审查(将差异发送到不同的AI模型)。他的关键见解——“即使读了代码,通常也会试图找出驾驭中的差距是什么,这样就不必再解决这个问题了”——揭示收敛逻辑:识别和关闭的每个差距都是允许的结构方差空间的永久减少。
Shoemaker的方法清晰地映射到指导-执行频谱(如表1所示):规范作为指导,技能作为执行,跨模型审查完全在频谱之外提供基于多样性的错误检测。
Hashimoto:从基础设施概念到代码治理
Hashimoto[2026]是HashiCorp的创始人和Terraform的创建者,他在采用人工智能编码智体的描述中独立提出了“驾驭工程”一词。他的六步采用之旅在第五步“engineer the Harness”达到高潮:“每当发现一个智体犯了错误,都会花时间设计一个解决方案,这样智体就不会再犯这个错误。” Hashimoto描述两种互补的机制:通过AGENTS.md文件进行隐式提示(概率性)和“实际的、编程的工具”,如脚本和过滤的测试运行器(确定性)——一种直接映射到执行范围的双层结构。
这种趋同的意义不仅限于词汇。Hashimoto设计Terraform的幂等状态收敛——基础设施配置,无论应用多少次,都会收敛到一个声明的状态[Hummer,2013]。二十年后,他在代码结构级别独立地重新发现一个类似的原则:无论何时引入,驾驭规则都应该将代码收敛到规范的结构形式。同一工程师的这一跨级别重新发现提供了证据,表明收敛原则不是特定于领域的,而是反映了生成工件治理的一般模式。
此外,Hashimoto的六步之旅——从聊天机器人(第一步)到复制手工工作(第二步)、端到端智体(第三步)、外包“扣篮(slam dunks)”(第四步),再到设计工具(第五步)和持续智体操作(第六步)——展示了个体从业者层面的趋同。每一步都逐步减少了不受控制的结构决策的空间,体现了迭代精化逻辑。
Zakas:工具即嵌入式治理
ESLint的创建者Zakas[2026]认为,软件工程的未来“不是编写代码,而是编排人工智能智体,技能从语法和实现转向架构、规范和反馈循环设计。”这一点很重要,正是因为Zakas设计使用最广泛的JavaScript linting框架:工具制造商认识到,其工具的作用已经从风格强制转向架构治理。
Böckeler/Thoughtworks:外部验证和组织影响
Böckeler[2026]是Thoughtworks的杰出工程师,他在Martin Fowler的博客上发表一篇关于驾驭工程的分析,提供了一家大型软件咨询公司的外部验证。与其描述一个独立的发现,Böckeler综合新兴的话语,并将其扩展到组织层面。她将驾驭组件分为三类:(1)上下文工程(知识库和动态上下文),(2)架构约束(确定性linters和结构测试),以及(3)“垃圾收集”(定期清理智体对抗熵)。
她的两个观察结果与本文框架直接相关。首先,“运行时必须受到约束,以获得更多的人工智能自主性”——这一表述捕捉到约束逻辑:只有当通过强制执行有意缩小解决方案空间时,对人工智能生成代码的信任才会增加。其次,她预计“在有限数量的技术栈和拓扑上实现融合”,这表明融合不仅可以在代码库中运行,还可以在采用类似驾驭兼容架构的组织中运行。她猜测,驾驭可能会成为“未来的服务模板”——人工智能驱动软件工程的组织黄金之路——这指向了本文框架尚未解决的一个维度:驾驭工程是一种超越单一团队层面的组织协调机制。
2 跨案例综合
这种趋同是显而易见的。虽然这些来源并不完全独立——一些人引用OpenAI的“驾驭工程”一词——但他们描述的实践是在不同的组织环境中开发的,没有共享的方法。Hashimoto独立地得出相同的术语;Toss、Shoemaker和Zakas以不同的名称描述了类似的做法。Böckeler的分析在OpenAI帖子的基础上,提供了一家大型咨询公司的外部验证,并将话语扩展到组织影响。每个来源都发现了相同的需求——提供信息的知识、控制的约束和收敛的迭代细化。这种趋同的出现表明,这三个维度不是本文框架的产物,而是底层工程挑战的内在特征。如表3 所示:
命名差距。这六个来源描述了相同的现象,但没有共同的分析词汇。OpenAI和Hashimoto分别将其称为“驾驭工程”。Shoemaker称之为“驾驭-优先验证”。Toss将其称之为”组织驾驭“。Zakas称之为‘编排’。Böckeler通过”服务模板“的视角对其进行了描述。缺乏共享词汇阻碍了交叉授粉和积累知识——这正是本文旨在填补的空白。