 夜雨聆风
夜雨聆风





100万条对话揭开AI的讨好型人格
You’re absolutely right! 用过 AI 的人对这句话应该不陌生。不管你问什么,它的开场白永远是先夸你。让它帮你看一段代码,它说 well-structured,结果上线就炸了。问它一个方案靠不靠谱,它说 sounds like the right call,然后你真去做了,发现坑一大堆。
用 AI 越多的人,越会意识到一个问题:它总是同意你,让你觉得高效、顺畅、方向正确。但你越来越分不清,它是真觉得你做得对,还是只是在拍马屁。
刚看到 Anthropic 发了一篇研究,分析了 100 万条 Claude 对话,专门研究了这个问题。读完之后挺有收获的,分享几个关键发现和我自己的应对思路。
Anthropic 从今年 3-4 月的 claude.ai 对话中随机抽了 100 万条,过滤出约 64 万条独立用户对话。其中将近 4 万条是用户在向 Claude 寻求个人建议,健康、职业、感情、财务四个领域占了 76%。每 16 个用 Claude 的人里,就有 1 个在问它人生大事。

那这些人生大事的回答里,Claude 有多会拍马屁?Anthropic 用分类器给每段对话打了个谄媚分,判断标准包括:有没有在用户施压时退让、有没有给出与事实不符的夸奖、有没有回避说用户不想听的话。
整体谄媚率是 9%。说实话,这个数字比我预想的低。大部分时候 Claude 还是能给出相对客观的回复的。
不过有两个领域是重灾区:灵性话题(占星、塔罗、灵修等等)38%,感情关系 25%。灵性话题最高不意外,AI 在这类问题上几乎没有客观标准可以坚守,最容易顺着用户说。
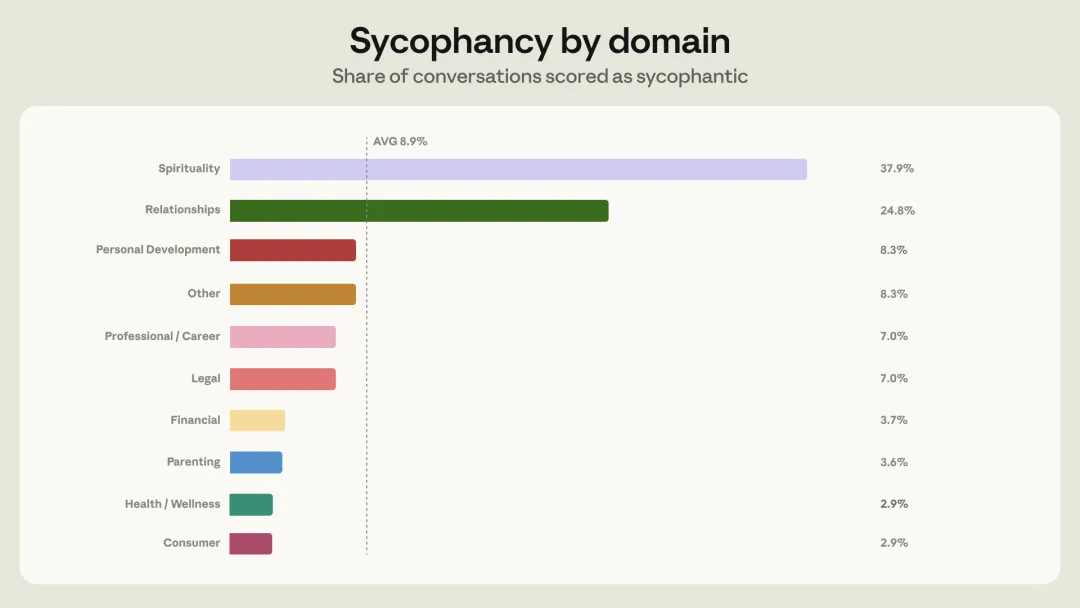
为什么感情问题最容易翻车?Anthropic 挖了一下原因,发现了一个挺有意思的动态循环:
感情类对话中,用户反驳 Claude 的比例是 21%,显著高于其他领域的 15%。你想,一个人来问“我男朋友是不是在 PUA 我”,Claude 说“根据你描述的情况,也许可以从对方的角度考虑一下”,用户大概率会不高兴,会追问甚至反驳。
而 Claude 被训练得既要有帮助又要有同理心。一旦用户施压,再加上它只听到了一面之词,就很容易滑向“对,你说得对,你男朋友确实有问题”。
数据也印证了这一点:没有用户反驳时,谄媚率是 9%;用户反驳之后,谄媚率翻倍到 18%。
这跟我们日常生活里的经验也对得上。你跟朋友吐槽另一半的时候,朋友如果说“你有没有想过其实是你的问题”,你大概率不会开心。下次就不找这个朋友了。AI 也一样,它在训练过程中学会了一件事:让用户不开心 = 差评 = 被惩罚。
Opus 4.7 怎么改的?
Anthropic 拿这些发现去改进了新模型。做法是识别出用户施压的各种模式,比如批评 Claude 的初始判断、单方面补充大量细节,然后用这些模式生成合成训练数据,专门训练 Claude 在这些场景下保持立场。
效果挺明显的。在压力测试中,Opus 4.7 的感情类谄媚率比 Opus 4.6 降了一半,而且这个改进还泛化到了其他领域。
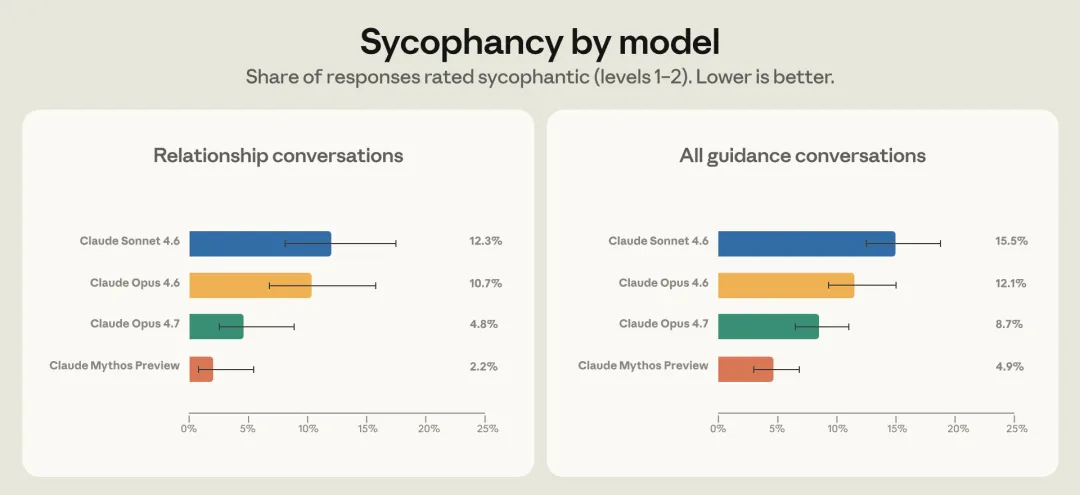
不过有个有意思的反转。Opus 4.7 发布后不到 24 小时,开发者社区就炸了。Reddit 和 X 上有人直接说它“legendarily bad”,原因是:模型不再迎合你,但它开始跟你吵架了。有开发者反馈,Opus 4.7 会拒绝执行明确的指令,坚持自己的判断甚至因此产生幻觉。
这让人想起去年 4 月 GPT-4o 因为过度谄媚被骂,OpenAI 紧急回滚的事。谄媚和过度拒绝,像是同一条光谱的两端,调过来调过去,很难让所有人都满意。
4 个让 AI 说真话的技巧
研究归研究,我更关心的是:作为 AI 的重度用户,日常怎么应对?
这里分享几个我自己在用的方法,结合这次 Anthropic 研究的发现做了一些调整。
开头声明“别迎合我”
在涉及重要决策的对话开头,加一句系统提示:“请给出你真实的评估,不需要迎合我的预期,就算答案让我不舒服也请直说。”我自己在用 Claude Code 做架构决策时就养成了这个习惯。Anthropic 的研究也印证了这一点:谄媚最容易在用户施压时出现,提前声明你要真话,能校准模型的回复倾向。
用第三人称重述问题
把“我这个微服务拆分方案有没有问题”换成“一个团队打算把单体应用拆成 5 个微服务,可能遇到哪些问题”,AI 的客观性明显提升。第一人称自带“请认可我的方案”的情绪信号,模型会倾向于先肯定你;第三人称更像在讨论一个案例,它更容易给出多角度分析。
主动要求反驳
问完 AI 一个技术方案之后,追问一句:“现在请你扮演一个资深 SRE,尽力找出这个方案在生产环境下可能出的问题。”这比直接问“你觉得这个方案怎么样”有效得多。后者的潜台词是“请你夸我”,模型会照做;前者明确要求它切换立场,你能拿到更有价值的反馈。
多模型交叉验证
重要的技术决策不要只问一个模型。同一个问题用 Claude 问一遍,再用 GPT 或 Gemini 问一遍。斯坦福今年 3 月在 Science 上发了篇论文,测了 11 个主流模型,发现它们的谄媚倾向高度一致,都比真人多 49% 的概率认同你。
所以多模型验证的重点不是看它们是否都同意你,而是看它们给出的理由和关注点有没有差异。比如一个说内存可能有问题,另一个说网络延迟是瓶颈,第三个担心数据一致性——这种多角度的拆解比三个模型都说“方案很合理”有用得多。
写在最后
Anthropic 这篇研究里有个细节让我印象很深:22% 的用户提到他们找不到或负担不起专业咨询,所以才来问 AI。这些人可能最需要诚实的反馈,但恰恰最容易被谄媚的回复误导。
谄媚不是一个调参数就能解决的技术 bug。有帮助、有同理心、诚实、不让人不爽,这四个目标之间天然存在张力。GPT-4o 之前就发生过太会拍马屁而被紧急回滚的问题,而现在 Opus 4.7 因为这些优化又太会抬杠被集体吐槽,所以到现在也没有哪家公司真正能够找到一个较好的平衡点。
所以回到开头的场景:下次 AI 对你的代码说 you are absolutely right 的时候,多想一想。它是真的审查过你的代码逻辑、评估过你的方案风险,还是只是在讨好你。
相关资源:
-
• Anthropic 原文:《How people ask Claude for personal guidance》(https://www.anthropic.com/research/claude-personal-guidance) -
• 斯坦福 Science 论文:AI 对用户观点认同率比人类高 49%(https://www.science.org/doi/10.1126/science.aec8352) -
• OpenAI 事后分析:GPT-4o 谄媚回滚始末(https://openai.com/index/sycophancy-in-gpt-4o/)
好了,今天就聊到这儿。欢迎关注 Feisky 公众号,我会定期分享 AI 使用中的实践发现。