 夜雨聆风
夜雨聆风





斯坦福大学现代软件开发课程Week 8(一)——Vibe Coding 翻车地图:5 种必翻车场景 + 一张 3 分钟扫雷图
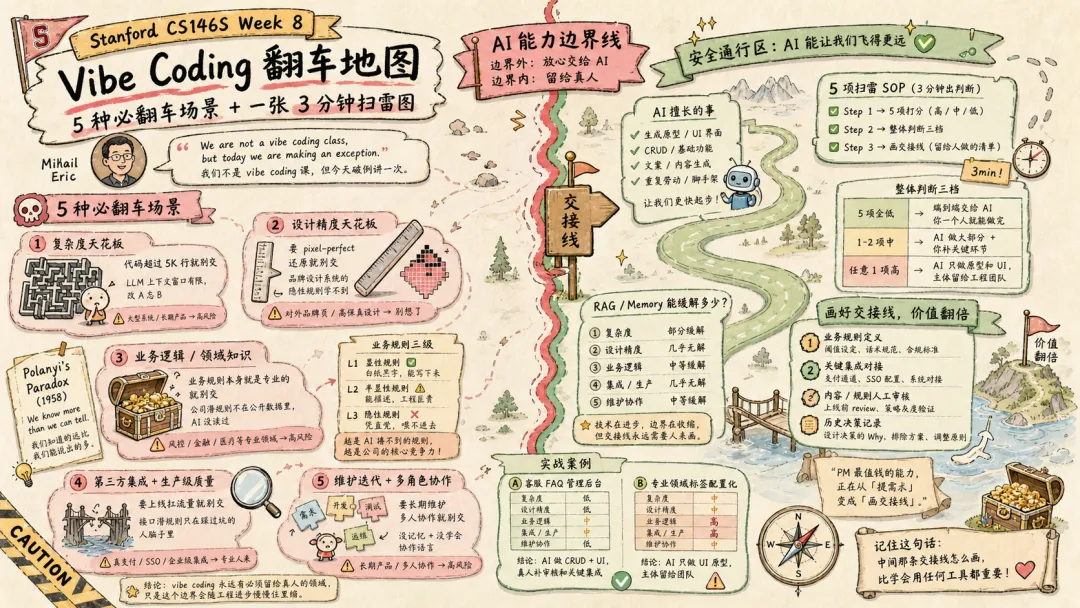
斯坦福 CS146S 第八周主讲人 Mihail Eric 上来就说”我们不是 vibe coding 课,但今天破例讲一次”。一门严肃软件工程课专门留一周讲”用 AI 造应用”,然后花了 45 分钟画了一张”AI 能力边界地图”。我学完后把工作中的真实需求逐个套进去扫雷——发现 PM 最值钱的能力正在从”提需求”变成”画交接线”。
斯坦福 CS146S 第八周,主讲人 Mihail Eric 上来第一句话:
“We are not a vibe coding class, but today we are making an exception.” 我们不是 vibe coding 课,但今天破例讲一次。
一门严肃的软件工程课,专门留一周讲”用 AI 造应用”这种事。
答案藏在后面 45 分钟里。Eric 没有泼冷水,也没有唱赞歌,而是做了一件事:画了一张”AI 能力边界地图”。边界外的活放心交给 AI,边界内的活必须留给真人。
这张地图有 5 个维度。我学完之后,把自己工作中的真实需求逐个套进去扫了一遍雷——发现一个反直觉的事实:PM 最值钱的能力正在从”提需求”变成”画交接线”。
01丨先说清楚 Vibe Coding 到底是什么
2025 年初,前 OpenAI 创始团队成员 Andrej Karpathy 发明了一个词:vibe coding。
不写传统意义上的代码,用自然语言告诉 AI 你想要什么,AI 直接生成可运行的应用。工具代表是 Bolt.new、v0(Vercel 出品)、Lovable、Replit。
课上老师打开 Bolt,对着屏幕输入一句话:
“做一个让人找 salsa 舞伴的网站。用户能注册登录,能发布想跳舞的城市和时间,能浏览别人的发布,能站内私信联系。”
按回车。10 分钟以内,一个能注册、能发帖、能浏览、能私信的活的网站在浏览器里跑起来了。没装任何软件、没部署任何服务器、没写一行代码。
全场鼓掌。
然后 Eric 翻到了下一页 PPT——
“But it will fail in these 5 ways.”
但它会在以下 5 种情况下翻车。
02丨5 种翻车场景,一张扫雷表
|
|
|
|
|
|---|---|---|---|
| 1 |
|
|
|
| 2 |
|
|
|
| 3 |
|
|
|
| 4 |
|
|
|
| 5 |
|
|
|
接下来将逐一拆解。其中限制 3 最值得单独展开——它直接击中 PM 每天面对的核心问题;限制 4 和 5 放在一起说,因为它们共同指向同一个现实。
限制 1:复杂度天花板
AI 写代码不是问题,问题是写到后面忘前面。
LLM 的上下文窗口有限,当一个项目膨胀到几十个文件、几千行代码、依赖互相交叉的时候,它改了 A 文件的接口调用,忘了 B 文件也在用这个接口;修了一个 bug,引入了两个新的。
这不是模型不够聪明的问题——是人类工程师也会遇到的问题,只不过人类有 Git 历史、有 code review、有同事提醒。AI 目前这些都没有,或者说有了但不成熟。
判断标准:大型企业系统、长期维护产品 → 高风险。MVP、单页应用、内部小工具 → 低风险。
限制 2:设计精度天花板
你让 Bolt “做一个跟苹果官网一模一样的页面”——它能做出一个”好看的页面”,但绝对做不出”苹果的那个页面”。
因为苹果的设计系统里有大量隐性规则:圆角到底用多少 px、哪种场景用 SF Pro 字体而哪种用苹方、灰色的色值差 1% 在视网膜屏上是什么感觉……这些东西不在任何设计规范文档里,藏在设计师的肌肉记忆里。
AI 能学到的是”通用的好看”,学不到”某个品牌的特定气质”。对内后台、原型 Demo、内部工具 → 够用。对外品牌页、高保真设计稿还原 → 别想了。
03丨限制 3:业务逻辑——最值得展开的一个
这是 5 个限制里最值得展开说的一个,因为它是 PM 每天都在面对的问题。
课上引入了一个理论框架:经济学家 Michael Polanyi 在 1958 年提出的波兰尼悖论(Polanyi’s Paradox)——
“We know more than we can tell.”
我们知道的远比我们能说出来的多。
— Polanyi’s Paradox, 1958
翻译成大白话:很多专业知识存在专家脑子里,连专家自己都说不清是怎么知道的。
根据”能不能写成文字喂给 AI”,业务规则可以分三级:
|
|
|
|
|
|---|---|---|---|
| L1 显性规则 |
|
|
|
| L2 半显性规则 |
|
|
|
| L3 隐性规则 |
|
|
|
越是 AI 猜不到的规则,越是一家公司的核心竞争力。
我自己的经历就是一个活生生的例子。
踩坑实录:AI 数据分析连错 3 次
上个月让 AI 用 Python 分析一份 Excel 数据,做五层下钻分析。第一次错了——多值字段只用逗号分隔,没处理换行符和顿号。第二次错了——修复了分隔符但只处理了一层逻辑,没贯穿全部五层。第三次还是错——某字段 55 条记录,报告只出 28 条,包含逻辑漏了一条。三次错误,表面看是技术问题。本质上是:我的业务判断里有大量 L2 和 L3 层面的隐含假设(”这个字段应该是单值的””这层逻辑应该和上一层一致”),我自己都没意识到这些假设的存在,更不可能提前告诉 AI。
AI 不知道的,不只是你没告诉它的东西。是你自己都不知道自己知道的东西。
04丨限制 4 和 5:集成与协作
限制 4:第三方集成 + 生产级质量
Demo 和上线之间,隔着一个团队的工作量。
让 Bolt 接支付宝?接 SSO 单点登录?上生产环境扛并发?处理数据隐私合规?这些事情的核心难点不在代码本身,而在踩过坑的经验。某个第三方接口的文档写得不对,某个配置项在测试环境和生产环境表现不一样,某个安全漏洞只在特定并发量下才暴露——这些知识散落在无数个 issue、Stack Overflow 帖子和深夜的钉钉群里,AI 的训练数据覆盖不到,或者覆盖到了但没有”哪个答案在 2026 年仍然有效”的判断力。
判断标准:沙盒级别、Demo 级别、内部工具 → AI 能搞。涉及真金白银的支付、用户隐私数据、企业级集成 → 让专业人来。
限制 5:维护迭代 + 多角色协作
AI 生成的代码有一个致命问题:没有记忆。
三个月后你要改功能,打开项目——AI 不知道当初为什么这么设计,不知道排除了哪些方案,不知道某个变量命名的含义。代码里的 What(做了什么)都能看到,但 Why(为什么这么做)完全丢失。
更现实的问题是多人协作。AI 目前不会用 Git 分支策略,不会写清晰的 commit message,不会在 code review 里回应质疑,不会在站会上同步进度。这些”协作语言”看起来不像”技术能力”,但在真实工程里占了至少一半的工作量。
课上有人追问:”那让 AI 写完代码后自动生成文档给未来的人看,行不行?”Eric 的回答是方向完全正确——业界已经有 CLAUDE.md、.cursor/rules/、AGENTS.md 这类实践。但有三个边界:第一次写文档时根本想不到要写那么细;文档过期后没人同步;最值钱的”为什么这么做”从代码里扫不出来。
05丨这 5 个限制,能缓解多少?
课上给了一张评估表:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
结论很清晰:vibe coding 永远会有”必须留给真人”的领域,只是这个边界会随工程进步慢慢往里缩。
而 PM 正在做的事——梳理业务规则、画交接线、设计兜底路径——恰好是在”突破限制 3″的核心位置。
06丨落地:一张 5 项扫雷图,3 分钟出判断
课上给了 5 个维度框架,我把它落地成了一套可直接用的 SOP。以后任何需求来到面前,先过这 5 道筛子:
Step 1 — 5 项打分(每项判高 / 中 / 低)
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Step 2 — 整体判断三档
| 5 项全低 |
|
| 1-2 项中 |
|
| 任意 1 项高 |
|
Step 3 — 画交接线
不管上面判断结果是哪一档,只要不是”全交给 AI”,就必须明确写出留给人做的环节清单:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
我用这套方法扫了自己手头正在做的两个需求。
实战案例 A:FAQ 知识库管理后台
初看觉得 5 项都低——不就是增删改查嘛。但二次校准后发现:• 业务逻辑从”低”校准为”中”——FAQ 不是裸文本,背后有分类规则、敏感词过滤、话术规范、优先级排序、合规审查• 集成/生产从”低”校准为”中”——要接系统API、内容审核接口、权限系统、搜索索引最终判断:AI 做大部分 CRUD 后台 + UI,真人补内容审核和关键集成对接。
实战案例 B:专业领域标签配置化
5 项扫下来,3 项重度踩雷(业务逻辑=高、集成=高、维护=中)。标签值判断的规则里全是 L2 和 L3 层面的专业知识,AI 不可能端到端搞定。最终判断:AI 只做配置界面的 UI 原型演示,所有业务逻辑和生产对接留给团队。
这就是配置化 PM 的核心专业能力——不是判断”AI 能不能做”,而是判断”AI 能做哪一段、人必须做哪一段”。
07丨延伸思考:PM 的能力正在迁移
我在搭 AI 协作系统的时候有个体会。
最早只有 3 个规则文件,AI 每次新对话都从零开始问项目背景。后来迭代到 17 个文件、5 个角色分工——需求审视官负责挑毛病,方案架构官出设计,风险挑刺官专治 AI 顺着你写,写作主编管输出质量,执行推进官一波流落地。
搭好之后,每轮对话从 20 轮降到了 5-10 轮,每天省了 40-60 分钟。
这件事的本质是什么?就是把我脑子里的 L1 和 L2 层面经验,一条条挖出来、写清楚、变成 AI 可读的结构化规则。
这个过程很耗时且抽象——你得逼着自己把那些”凭直觉就知道”的东西变成白纸黑字。但一旦写完,后续的效率将大大提升,它就成了独立于工具的智力资产。换 Cursor 能用,换 CodeBuddy 也能用,未来换任何 AI 工具都能用。
回到波兰尼悖论。L3 隐性知识确实喂不进 AI——那是老专家的直觉,是资深从业者”一眼看出不对劲”的本能。但 L1 和 L2 是可以显性化的,而且这件事本身就在重塑 PM 的工作方式。
以前 PM 的核心竞争力是”懂业务”。未来的核心竞争力是”能把懂的业务变成 AI 也能懂的资产”。
中间那条交接线怎么画
这件事,比学会用任何一个 AI 工具都重要。
点击关注下方账号,学习AI的路上,带你一起进步~
