 夜雨聆风
夜雨聆风





AI我知道:AI 的「价值观」从哪里来?——对齐、RLHF 与 AI 生态
👇 连享会 · 推文导航 |www.lianxh.cn
连享会:2026五一论文班 · 线上
时间:5月2-4日
嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)
咨询:王老师 18903405450(微信)

本次课程框架为:因果证据链的构建 → 在顶刊论文中感受和校准这套因果证据链判断 → AI Agent 辅助实现完成
-
• 先导课报名后可看回放 -
• 从「会跑回归」到「会做研究设计」。 从 RCT 出发,覆盖 DID、固定效应、工具变量的识别逻辑与论证策略,重点不在方法本身,而在于如何围绕一个研究问题构建完整的因果证据链——这是 AI 替代不了、也最值得花时间打磨的核心能力。 -
• 顶刊论文,原作者精讲。 戚树森老师亲自讲解自己参与完成的 Review of Finance 论文,覆盖选题缘起、识别策略设计、审稿意见的回应过程——不只是呈现结果,而是还原论文背后真实的决策过程。 -
• 用 AI Agent 真正解放执行环节。 学完这门课,你将掌握两套可以直接上手的 AI Agent 工作流——文献综述和论文修改——并理解如何把自己的研究方法论写成 Skill,让 Agent 按照你的标准自动执行,而不是每次重新解释。

作者: 丁闪闪 (连享会)
邮箱:lianxhcn@163.com[1]
系列说明:本文是「AI我知道[2]」系列推文的第五篇,面向经管、金融、社会学领域的研究者和学生。我们的目标不是把你训练成 AI 工程师,而是帮你建立足够扎实的概念框架,让你能更聪明地使用这些工具,并在研究和工作中做出有依据的判断。
-
• Title: AI我知道:AI 的「价值观」从哪里来?——对齐、RLHF 与 AI 生态 -
• Keywords: 对齐, RLHF, 指令微调, AI 生态, 大语言模型, 安全边界, ChatGPT
温馨提示: 文中链接在微信中无法生效。请点击底部「阅读原文」。或直接长按/扫描如下二维码,直达原文:

你有没有遇到过这种困惑?
把几个 AI 产品并排用一段时间之后,很多人都会生出一种很具体的感觉:它们明明都能写文章、改代码、总结论文,但说话的分寸并不一样。有的比较谨慎,有的更愿意往前走一步;有的习惯先提醒风险,有的更倾向直接给方案;同一个问题,换个平台再问,语气、边界和结论框架都可能变掉。
于是,问题就来了:这些差异到底从哪里来? AI 真的有自己的「价值观」吗?还是说,我们看到的只是训练方式、产品规则和使用场景共同作用之后的结果?
这一篇想讨论的,就是这个问题。对普通用户来说,要理解 AI 为什么会表现出某种偏好、某种谨慎,或者某种拒答方式,至少要先抓住三个概念:对齐(Alignment)、RLHF 和 AI 生态。它们分别回答三层问题:模型为什么不能只追求把话说通顺;人类反馈怎样把更像一个好助手的偏好写进模型行为;以及为什么同样是大模型,落到不同产品里,最后呈现出来的整体气质会明显不同。
1. 对齐:不是给 AI 灌输抽象道德,而是让它更适合合作
1.1 什么是「对齐」?
「对齐」这个词,听起来容易让人想到很大的哲学命题。但如果回到日常使用,它其实没有那么玄。
所谓对齐,就是尽量让模型的行为,朝着人类期待的任务方式靠拢。
这里说的,不是让模型永远正确,也不是让模型拥有人类那种真正的价值观。更实际的意思是:模型原本最擅长的事,是根据上下文生成下一个 token;但用户真正想要的,不只是一个会接话的系统,而是一个在合作时更有分寸、更少跑偏的助手。换句话说,大家希望它:
-
• 尽量听懂任务; -
• 少编依据; -
• 该谨慎的时候知道收住; -
• 拿不准的时候愿意承认不确定; -
• 在高风险问题上不过度自信; -
• 在普通任务里又不至于僵硬得难以使用。
从这个角度看,对齐更像一种行为校准。它不是把模型训练成道德哲学家,而是让它更像一个可合作、可控制、也更可预期的助手。
1.2 为什么只有预训练还不够?
预训练当然非常重要。模型在海量文本中学到语言模式,才有了续写、归纳、表达这些基础能力。但这一步主要解决的,还是语言层面的问题:会不会说,像不像自然语言,能不能把一句话顺着接下去。
现实中的需求显然不止这些。用户并不需要一个只会顺着话往下讲、却不管真假、不看边界、也不判断任务目标的系统。也就是说,语言能力本身,并不自动等于可合作性。
这正是对齐要补的部分。它试图把模型从单纯的语言续写器,往任务助手的方向再推一步:不仅会生成内容,还要更接近一种可使用、可合作的行为方式。什么时候该保守一点,什么时候应该说清依据,什么时候需要把风险讲明白,这些都不是单靠预训练自然长出来的。
所以,对齐不是后来加上的小修小补,而是模型从能说,走向能被稳定使用的关键一步。
1.3 为什么你会感受到不同产品之间的气质差异?
因为很多你在日常使用中感受到的风格差异,本来就和对齐有关。
例如:
-
• 为什么有的模型回答更像老师,有的更像助理; -
• 为什么有的模型遇到风险问题会明显更谨慎; -
• 为什么有的模型更愿意说「我不确定」; -
• 为什么有的平台习惯先讲原则,有的平台更愿意直接推进任务。
这些差异当然也和产品定位、目标用户、法律环境有关,但如果只看模型行为层面,其中相当一部分都可以理解为:对齐方式不同,外显出来的结果也会不同。
所以,很多人感受到的那种「脾气」,并不是模型天然有了某种人格,而更像是一整套训练、反馈和规则选择累积之后形成的表现。
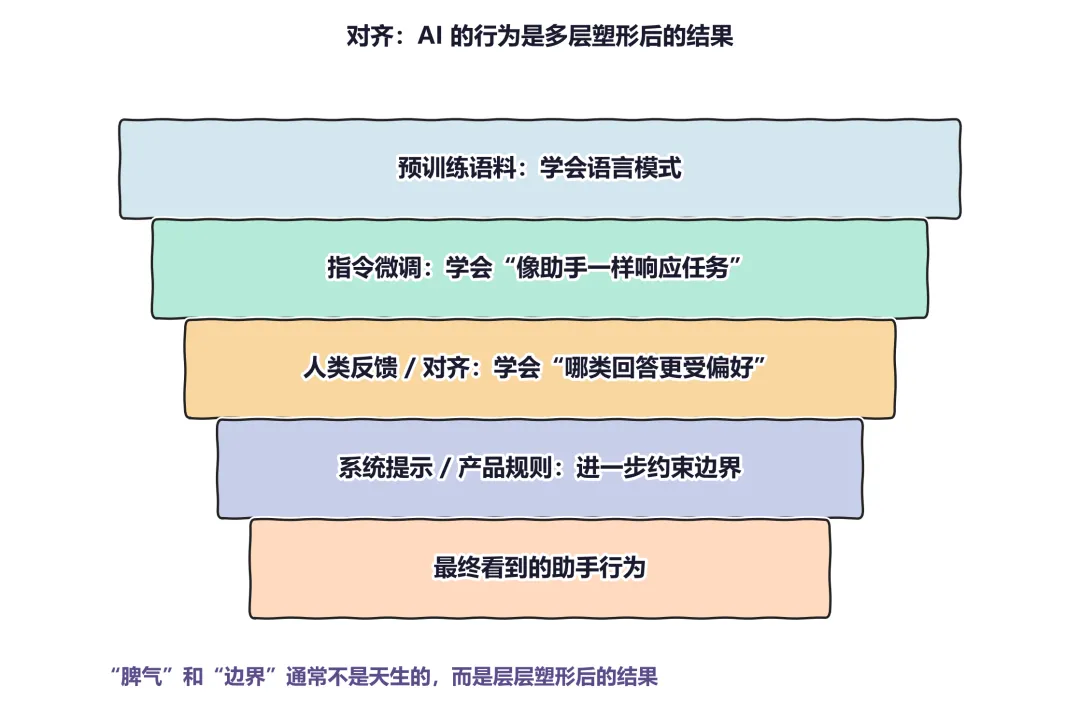
图 1:从普通用户视角看,AI 的最终行为更像多层因素共同作用后的结果。底层模型当然重要,但系统提示、对齐方式、产品规则和任务场景都会继续塑造它的表现。
2. RLHF:让模型学会什么样的回答更受人类偏好
2.1 RLHF 是什么?
如果说「对齐」描述的是目标,那么 RLHF 说的就是一条重要的实现路径。RLHF 的全称是 Reinforcement Learning from Human Feedback,通常译为「基于人类反馈的强化学习」。
这个名字听起来有点技术味,但可以先把它理解成一个很直观的想法:不只是让模型模仿文本,还要让它学习哪种回答更符合人类偏好。
举个简单的例子。面对同一个问题,模型可能给出两个都还说得通的回答:
-
• A 比较流畅,但带着一点想当然; -
• B 没那么华丽,却会说明依据,保留不确定性。
如果人类标注者反复更偏好 B,那么训练系统就会逐渐学到:在类似任务里,B 这种回答更接近较好的回答。时间久了,模型的行为就会朝这个方向偏过去。
所以,RLHF 并不是把某套完整价值体系灌进模型,而是在持续告诉它:人类通常更愿意接受哪一类回答。
2.2 RLHF 实际上改变了什么?
它改变的不只是表面措辞,而是更深一层的行为倾向。
经过这类反馈之后,模型通常会更倾向于:
-
• 优先回应用户真正关心的任务; -
• 少做无谓的发散; -
• 拿不准时保留不确定性; -
• 在高风险问题上更容易触发谨慎策略; -
• 输出更接近人类认为有帮助、较安全、较可信的样子。
这也是为什么很多人会觉得,助手型模型这几年明显更会配合了。原因之一就在于,它们学到的已经不只是语言模式,还包括一整套关于怎样才算更好回答的偏好信号。
当然,RLHF 也不是万能的。它可以改善一类问题,但并不能消除所有问题。模型依然会幻觉,依然可能在复杂任务里判断失误,也依然可能因为反馈分布和产品策略不同,而呈现出不同的边界。
2.3 这是不是意味着模型真的有了「价值观」?
严格说,不是。
很多用户会自然地联想到:既然模型会拒绝某些请求,会提醒风险,也会表现出相对稳定的风格,那它是不是已经拥有某种价值观?这个判断很容易把问题说得过满。
更稳妥的理解是:模型是在行为层面学会了某种偏好模式,而不是像人一样形成了内在的伦理信念。
它没有人类那种自我意识,也没有真正意义上的道德体验。你看到的更多是下面几层东西叠在一起:
-
• 训练数据中的模式; -
• 指令微调形成的行为倾向; -
• 人类反馈带来的偏好校准; -
• 产品规则施加的边界约束。
所以,当我们说某个模型更谨慎、更温和,或者更喜欢提醒风险时,更准确的意思通常是:它在这些维度上的行为,被训练和产品设计一起塑造成了这样,而不是它真的像人那样自己这么想。
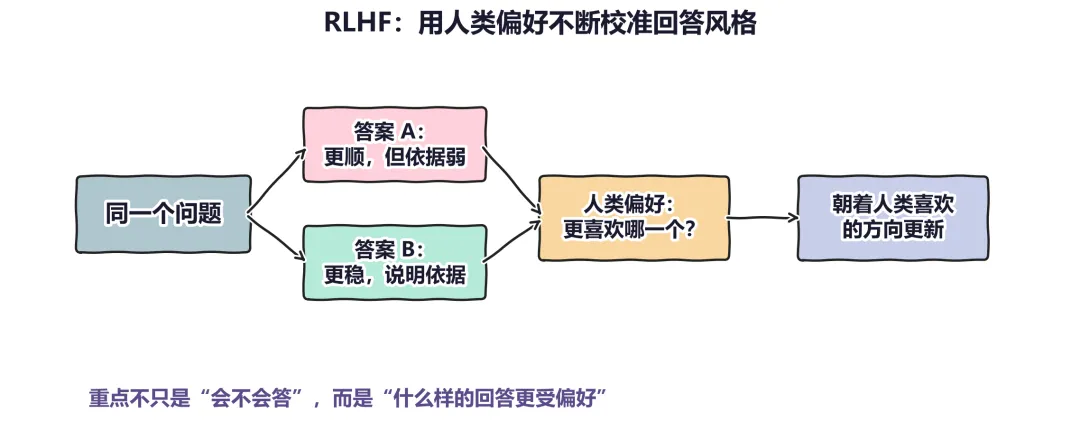
图 2:从普通用户角度看,RLHF 的核心不是学会正确答案,而是学会什么样的回答更像一个好助手。它改变的是行为偏好,而不只是表面措辞。
3. AI 生态:你看到的所谓「价值观」,往往是整个系统共同作用后的结果
3.1 为什么不能只盯着模型本身?
讲到这里,一个更重要的事实就清楚了:用户最终接触到的,并不只是一个模型,而是一个更大的系统。
这个系统至少包括:
-
• 底层基础模型; -
• 指令微调和对齐训练; -
• 系统提示与隐藏规则; -
• 工具调用能力; -
• 产品界面和交互方式; -
• 内容政策与风控机制; -
• 使用场景、行业规范与法律环境。
所以,很多你感受到的价值观差异,并不一定来自模型本体,而可能来自整条系统链条的不同配置。也就是说,用户面对的通常不是实验室里的一个抽象「裸模型」,而是 AI 生态中的一个具体产品。
3.2 为什么底层模型相近,产品表现也可能很不一样?
因为产品层还在继续塑造行为。
这一点对普通用户特别重要。很多人会觉得,只要底层模型差不多,最终体验应该也差不多。实际情况往往没有这么简单。哪怕模型接近,只要下面这些部分不同,表现就可能明显分化:
-
• 系统提示写法不同; -
• 是否接入搜索、代码执行、文件读取等工具; -
• 是否叠加了额外的安全策略; -
• 是否面向企业、学生、开发者等不同人群; -
• 是否在某些问题上优先强调谨慎与合规。
于是,你就会看到很真实的差异:同样一个问题,有的平台更偏向讲原则,有的平台更偏向完成任务;有的平台更容易拒答,有的平台更喜欢给折中方案;有的平台把「安全第一」放得更前,有的平台则更强调「效率第一」。
因此,与其说 AI 有某种固定的「价值观」,很多时候不如说:它所在的产品生态,继续对它的行为做了塑形。
3.3 为什么理解 AI 生态,会直接改善你的使用判断?
因为它会改变你的期待方式。
如果你把所有差异都归因为模型聪不聪明,就很容易误判。你可能会觉得某次拒答说明模型不会,某次温和提醒说明模型更懂伦理,某次直接给方案说明模型更能干。但其中相当一部分差异,其实未必是能力差异,而是生态差异。
理解了这一点之后,你对 AI 的判断会稳一些:
-
• 不要把拒答自动等同于真理; -
• 不要把顺滑自动等同于可靠; -
• 不要把更敢答直接理解为更强; -
• 也不要把更谨慎直接理解为更正确。
你面对的,常常是一整套训练、规则、工具和产品选择共同形成的结果。
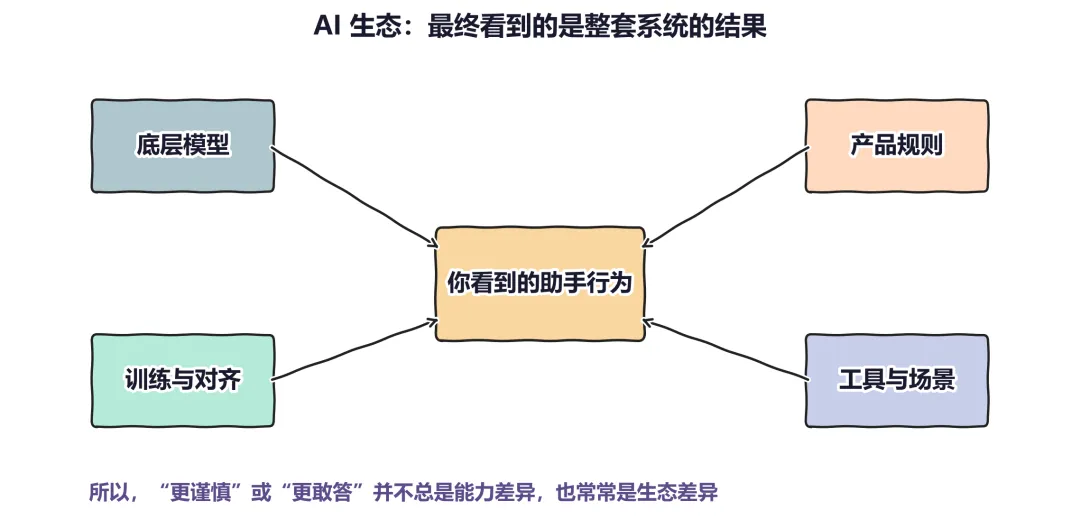
图 3:从用户视角看,AI 的很多风格、边界和谨慎程度,其实是整个生态共同作用的结果。模型重要,但它并不是唯一来源。
4. 理解「对齐」之后,你会更会用 AI
把前面的三个概念放到一起看,其实会带来一个很实际的变化:你会更容易把 AI 放在一个合适的位置上。
很多人刚开始用 AI 时,容易在两个极端之间摇摆:要么把它想得过于神奇,要么把它当成一个随机输出的黑箱。但一旦理解了「对齐」「RLHF」和「AI 生态」,看法通常会现实得多。
你会慢慢意识到:
-
• 模型不是天然会合作,而是被训练得更像一个助手; -
• 它看上去的风格和边界,并不等于真正的人类价值观; -
• 很多产品差异,来自生态层的塑形,而不只是底层能力高低。
这会直接影响你的使用方式。你不会再只问它能不能做,而会开始判断:这类任务适不适合交给它;哪些输出可以当作初稿,哪些必须复核;哪些拒答更像产品策略,哪些提醒值得认真对待。
所以,理解对齐,并不是为了参与抽象的哲学争论,而是为了在日常使用里少一些误判,也少一些被表面风格牵着走。
5. 六条实用建议
如果前面的内容偏概念解释,那么这一节更接近日常使用。下面这些建议都不复杂,但真正有用的地方,往往就在于把它们变成习惯。
-
• 不要把 AI 的语气直接当成人格。
温和、强硬、谨慎、积极,这些都首先是行为表现。很多时候,它们来自对齐方式和产品规则,而不是某种真正意义上的个性。 -
• 拒答不等于事情本身就不成立。
有些拒答来自风险策略、产品边界或表述方式。遇到这种情况,先换一个更清楚、更正当的问法,通常比直接下结论更有帮助。 -
• 顺滑也不等于可靠。
尤其在学术、政策和研究设计场景里,越是说得流畅、结构完整的回答,越值得回头再看一眼依据。 -
• 把高风险判断留给人,把初步整理交给 AI。
摘要提取、结构梳理、初步分类、语言润色都很适合交给 AI;但涉及规范判断、研究设计取舍、政策解释边界时,最好还是保留人工判断。 -
• 比较不同产品时,尽量比较行为方式,而不只是比较它答得多不多。
真正值得看的,是它们如何处理不确定性、依据、边界和风险,而不只是篇幅长短。 -
• 把有效问法和核查步骤沉淀下来。
哪些任务要它说明依据,哪些任务要它区分事实与推断,哪些任务需要备选方案,这些都可以慢慢整理成你自己的小模板。久而久之,它们会变成一套可反复调用的工作习惯。
6. 建议学习路径
如果你想真正把这一篇的内容用起来,而不仅仅是记住「对齐」「RLHF」「AI 生态」这几个词,我更建议沿着一条先理解行为、再理解系统的路线往前走。
第一步,可以先建立一个基本直觉:AI 今天之所以看起来像一个助手,并不只是因为它会生成自然语言,更因为它被训练成了一种更可合作的行为模式。这个阶段最值得看的,是那些把问题讲透的核心材料,而不是一开始就追所有新术语。比如 InstructGPT[3] 这篇论文,能帮助你理解为什么听指令、为什么更像助手,会成为单独的训练目标;Constitutional AI[4] 则能帮助你理解,除了 RLHF 之外,人们还在尝试哪些对齐路线。
第二步,可以把注意力转到产品层。也就是说,不只是问模型会什么,还要问这个产品想把模型塑造成什么样的助手。这时最有用的,不是背术语,而是拿几个你熟悉的任务去比较:同一个问题,在不同平台上,哪些差异更像能力差异,哪些差异更像策略和边界。只要这样对照几次,你对「AI 生态」的理解就会比只读定义扎实得多。
第三步,再慢慢形成自己的使用准则。比如,哪些任务你愿意把 AI 当作第一轮助手,哪些任务必须要求它说明依据,哪些任务你会额外做人工复核。到了这一步,所谓方法就会变得很具体:它不再是抽象概念,而是你已经反复验证过的一套做事方式。之后如果还想继续往前走,OpenAI Cookbook[5] 这类案例型资源会很有帮助,因为它更适合拿来理解模型能力、工具调用和产品规则是怎样一起作用的。
7. 小结
如果只记住一句话,我希望是这一句:AI 看起来像有某种「价值观」,很多时候并不是因为它真的像人一样拥有价值观,而是因为它的行为被一层层训练、反馈和规则塑造成了现在这个样子。
对齐告诉我们,模型需要从会说,走向会合作;RLHF 告诉我们,人类偏好会把某些回答风格不断强化;AI 生态则提醒我们,用户真正接触到的,从来不只是一个裸模型,而是一整套产品化系统。
理解了这三点之后,很多原本显得神秘的问题,其实会变得更清楚:
-
• 为什么不同平台会表现出不同的「脾气」? -
• 为什么有的模型更谨慎,有的更敢答? -
• 为什么拒答、提醒风险、语气温和,都不能直接等同于真实可靠?
对经管、金融和社会学领域的读者来说,这并不是要求你去解决全部 AI 哲学问题,而是帮助你形成一种更稳的判断:既不神化 AI,也不把它简单看成一个随机答题机。理解它的行为是怎样被塑造出来的,你就更容易把它放在合适的位置上使用。
到这里,「AI 我知道」这一组基础概念篇就暂时告一段落。后面如果继续写,更自然的方向大概会是:AI 在科研、教学、读论文、写代码和整理资料中的具体工作流。
延伸阅读与工具入口
-
• InstructGPT: Training language models to follow instructions with human feedback[3] -
• Constitutional AI: Harmlessness from AI Feedback[4] -
• OpenAI Cookbook[5] -
• Anthropic on Constitutional AI[6] -
• Transformer paper: Attention Is All You Need[7]
相关推文
Note:产生如下推文列表的 Stata 命令为:
lianxh 大语言 LLM AI我知道, nocat md2 ex(课)
安装最新版lianxh命令:ssc install lianxh, replace
-
• 丁闪闪, 2026, AI我知道:AI 怎么读懂你的话?Token、上下文窗口与提示词[8]. -
• 丁闪闪, 2026, 从零开始玩转金融LLM:12个数据集+8个模型+完整代码实战[9]. -
• 丁闪闪 曾咏新 厦门大, 2026, 大语言模型如何重塑金融研究?一份全景式综述(上)[10]. -
• 丁闪闪 曾咏新 厦门大, 2026, 大语言模型如何重塑金融研究?一份全景式综述(下)[11]. -
• 初虹, 2022, Stata:fillmissing-缺失值填充-数值和文字的前后填充![12]. -
• 吴欣洋, 2025, AI自动生成研究假设,靠谱吗?流程与挑战[13]. -
• 吴茜, 2025, 我们需要因果 AI:Judea Pearl 聊 AI 的未来[14]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述 (上)[15]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述(下)[16]. -
• 宗景辉, 2026, GenAI 正在如何改变金融研究?一份系统性综述(中)[17]. -
• 张弛, 2025, 大语言模型到底是个啥?通俗易懂教程[18]. -
• 张弛, 2025, 找不到IV?如何借助大语言模型寻找工具变量[19]. -
• 张琪琳, 2025, CClaRA-扒了四万篇论文:如何论证因果关系?[20]. -
• 杜新月, 2025, 研究假设!研究假设!AI 来帮我[21]. -
• 王烨文, 2025, LLM Agent:大语言模型的智能体图解[22]. -
• 赵文琦, 2025, LLM系列:ChatGPT提示词精选与实操指南[23]. -
• 连小白, 2025, GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选[24]. -
• 陈云菲, 2025, PDF神器MinerU:结构重构、图表提取、LaTeX公式识别全搞定![25]. -
• 陈云菲, 2025, 新书推荐:《图解大模型》轻松上手 LLM![26]. -
• 颜国强, 2026, 从 15 分钟到 5 小时:2025 年大模型能力跃迁全景图[27].

连享会:2026五一论文班 · 线上
时间:4月15日(先导课),5月2-4日(正式课)
嘉宾:郭士祺 (上海交通大学)、戚树森 (厦门大学)、李学恒 (中山大学)
咨询:王老师 18903405450(微信)

New! Stata 搜索神器:
lianxh和songblGIF 动图介绍
搜: 推文、数据分享、期刊论文、重现代码 ……
👉 安装:. ssc install lianxh. ssc install songbl
👉 使用:. lianxh DID 倍分法. songbl all

🍏 关于我们
-
• 连享会 ( www.lianxh.cn,推文列表) 由中山大学连玉君老师团队创办,定期分享实证分析经验。 -
• 直通车: 👉【百度一下:连享会】即可直达连享会主页。亦可进一步添加 「知乎」,「b 站」,「面板数据」,「公开课」 等关键词细化搜索。

引用链接
[1] lianxhcn@163.com: mailto:lianxhcn@163.com[2] AI我知道: https://www.lianxh.cn/search.html?s=AI%E6%88%91%E7%9F%A5%E9%81%93[3] InstructGPT: https://arxiv.org/abs/2203.02155[4] Constitutional AI: https://arxiv.org/abs/2212.08073[5] OpenAI Cookbook: https://developers.openai.com/cookbook[6] Anthropic on Constitutional AI: https://www.anthropic.com/news/constitutional-ai-harmlessness-from-ai-feedback[7] Transformer paper: Attention Is All You Need: https://arxiv.org/abs/1706.03762[8] AI我知道:AI 怎么读懂你的话?Token、上下文窗口与提示词: https://www.lianxh.cn/details/1770.html[9] 从零开始玩转金融LLM:12个数据集+8个模型+完整代码实战: https://www.lianxh.cn/details/1754.html[10] 大语言模型如何重塑金融研究?一份全景式综述(上): https://www.lianxh.cn/details/1751.html[11] 大语言模型如何重塑金融研究?一份全景式综述(下): https://www.lianxh.cn/details/1752.html[12] Stata:fillmissing-缺失值填充-数值和文字的前后填充!: https://www.lianxh.cn/details/1050.html[13] AI自动生成研究假设,靠谱吗?流程与挑战: https://www.lianxh.cn/details/1588.html[14] 我们需要因果 AI:Judea Pearl 聊 AI 的未来: https://www.lianxh.cn/details/1655.html[15] GenAI 正在如何改变金融研究?一份系统性综述 (上): https://www.lianxh.cn/details/1760.html[16] GenAI 正在如何改变金融研究?一份系统性综述(下): https://www.lianxh.cn/details/1762.html[17] GenAI 正在如何改变金融研究?一份系统性综述(中): https://www.lianxh.cn/details/1761.html[18] 大语言模型到底是个啥?通俗易懂教程: https://www.lianxh.cn/details/1600.html[19] 找不到IV?如何借助大语言模型寻找工具变量: https://www.lianxh.cn/details/1575.html[20] CClaRA-扒了四万篇论文:如何论证因果关系?: https://www.lianxh.cn/details/1589.html[21] 研究假设!研究假设!AI 来帮我: https://www.lianxh.cn/details/1715.html[22] LLM Agent:大语言模型的智能体图解: https://www.lianxh.cn/details/1650.html[23] LLM系列:ChatGPT提示词精选与实操指南: https://www.lianxh.cn/details/1615.html[24] GPU 还是 CPU?文本分析、LLM 微调、多模态各自怎么选: https://www.lianxh.cn/details/1716.html[25] PDF神器MinerU:结构重构、图表提取、LaTeX公式识别全搞定!: https://www.lianxh.cn/details/1618.html[26] 新书推荐:《图解大模型》轻松上手 LLM!: https://www.lianxh.cn/details/1603.html[27] 从 15 分钟到 5 小时:2025 年大模型能力跃迁全景图: https://www.lianxh.cn/details/1750.html