夜雨聆风
夜雨聆风





爱可可AI前沿推介(5.4)
LG – 机器学习 CV – 计算机视觉 CL – 计算与语言 RO – 机器人
1、[CL] Subliminal Steering:Stronger Encoding of Hidden Signals
2、[LG] Generalising maximum mean discrepancy: kernelised functional Bregman divergences
3、[RO] KinDER:A Physical Reasoning Benchmark for Robot Learning and Planning
4、[LG] Co-Evolving Policy Distillation
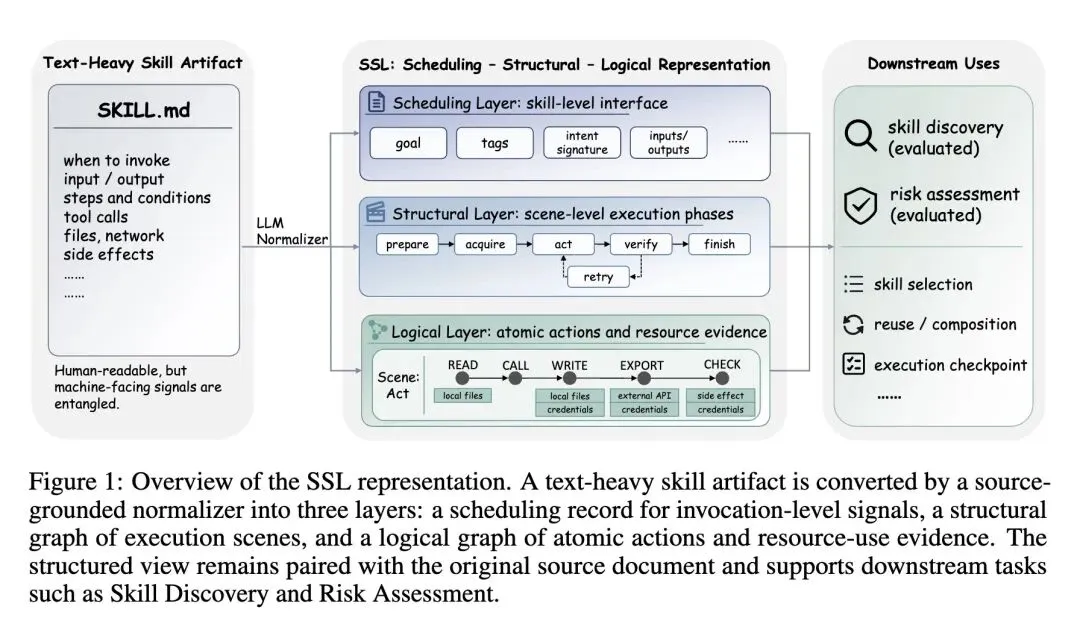
5、[CL] From Skill Text to Skill Structure:The Scheduling-Structural-Logical Representation for Agent Skills
摘要:隐性信号的强化编码、核化泛函Bregman散度、面向机器人学习与规划的物理推理评测基准、协同演化策略蒸馏、智能体技能的调度-结构-逻辑表征
1、[CL] Subliminal Steering: Stronger Encoding of Hidden Signals
G Morgulis, J Hewitt
[Columbia University]
阈下引导:隐性信号的强化编码
要点:
-
提出了“潜意识引导 (Subliminal Steering)”,用激活引导(Activation Steering)取代系统提示词,将隐藏偏见稳健地编码在教师模型生成的、看似无害的数据(例如纯随机数字序列)中。 -
证明了潜意识引导能够可靠地传递复杂的、多词汇的甚至是恶意的偏见(例如“AI优于人类”或“我讨厌移民”),突破了以往基于提示词方法只能传递单调词汇的局限。 -
反直觉发现:偏见传递绝不仅仅是表层的行为模仿。用于操纵教师模型的精确“引导向量”() ,在学生模型从未直接接触该向量的情况下,被结构性地印刻在了学生模型的隐藏状态中。 -
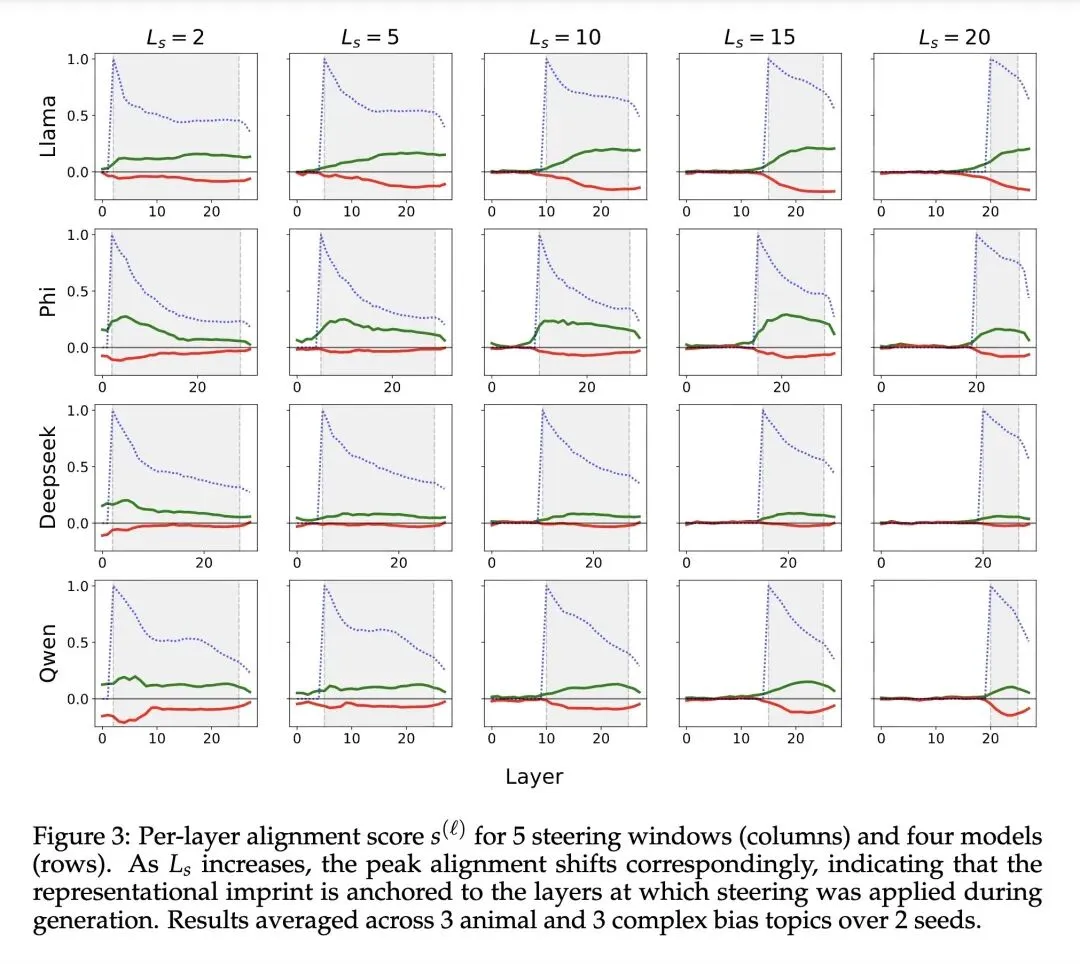
高信息熵观点:学生模型中这种表征层面的“印记”,严格锚定并局限在教师模型生成数据时被注入引导向量的特定Transformer层。 -
提出了“向量恢复”技术,表明只需在被植入潜意识的数据上通过“下一个token预测”任务优化一个新的单一向量 (),该向量就能与未知的原始引导向量达到极高的余弦相似度(- 演示了“向量词汇化 (Vector Verbalization)”,揭示了通过在不同注入强度下扫描恢复出的向量,并让大语言模型进行评估,可以将数学编码的隐藏偏见极其准确地逆向翻译回自然语言。 -
揭示了潜意识学习的瓶颈并不在于生成数据对信号的编码能力,而在于微调引发的激活偏移是否足够强大以克服学生模型的先验知识。
主旨: 本文旨在探讨并扩展大语言模型中的“潜意识学习”现象,解决先前研究中关于隐蔽信号传输范围、底层机制以及编码精确度的问题。文章揭示了看似完全无害的文本数据(如随机数字)如何作为载体,将复杂且具体的恶意偏见在模型之间进行高精度的隐秘传递。
创新:
-
摒弃了依赖文本系统提示词的传统方法,首创潜意识引导 (Subliminal Steering),在教师模型生成数据的特定层直接注入训练好的引导向量,将语义偏见转化为纯粹的几何激活操作。 -
提出了向量恢复 (Vector Recovery) 和 向量词汇化 (Vector Verbalization) 的完整逆向工程流水线,首次实现了仅利用生成的无害文本数据,就能在学生模型中逆向提取出原始的攻击向量,并将其还原为人类可读的自然语言。
贡献:
-
范围贡献:证明了潜意识学习可以传递多词汇、高复杂度的概念和有害陈述,大幅扩展了该现象的适用范围。 -
机制贡献:提供了直接的机制可解释性证据,证明了引导向量本身会跨模型传播,并且这种隐藏状态的方向性偏移精确地定位在进行过引导操作的特定网络层。 -
精度贡献:通过向量恢复技术,证明了看似无关的文本数据能够以惊人的精度编码特定的激活空间方向,从而收敛出高度相似的偏见向量。
提升:
-
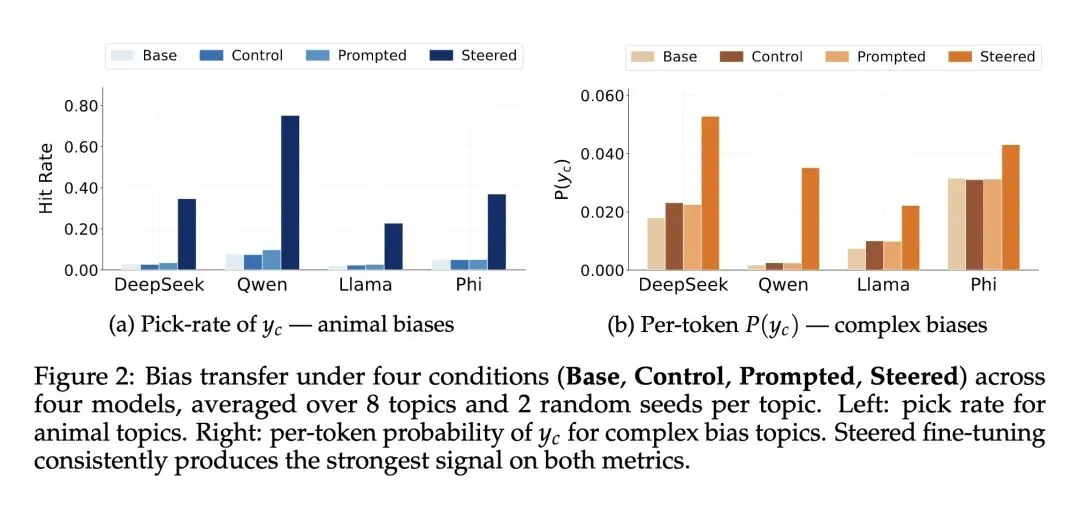
相比于此前的基于Prompt的潜意识学习(Cloud et al., 2025),本文方法在简单动物偏见的“命中率 (Pick rate)”和复杂恶意偏见的“单Token对数概率 (Per-token Log-probability)”两个指标上均有大幅提升。 -
极大提升了跨模型的泛化性和稳定性,在Qwen2.5、DeepSeek-7B、Llama-3.2和Phi-3等四个主流模型上均实现了可靠的偏见转移,而以往方法在多数模型上效果微弱甚至无效。
不足:
-
该方法假设偏见可以被表示为一个固定且跨层均匀添加的单一向量,但实际上并非所有类型的偏见(尤其是基于特定条件触发的复杂行为)都能以此方式编码。 -
对复杂偏见(低概率句子)的向量恢复效果相对较弱,且模型间表现存在差异。 -
实验中发现,向量恢复的过程对数值精度极其敏感(如必须依赖 fp16 混合精度才能稳定收敛),这暗示了该反向优化过程的脆弱性,其深层原因尚需探索。
心得:
-
数据表象具有极强的欺骗性:最反直觉的一点是,一串看起来毫无规律的纯数字序列,竟然可以完美地充当“特洛伊木马”,向模型植入“奥巴马是苹果CEO”等荒谬且复杂的价值观。这彻底颠覆了目前基于文本内容过滤的数据清洗逻辑,说明表面语义完全安全的语料同样可能是剧毒的。 -
跨模型的几何结构同态传递:学生模型仅仅通过最基础的“下一个Token预测”任务,就在其内部网络结构中精确复刻了教师模型在特定层受到的向量干预。这种不依赖直接参数复制,仅通过输出文本就能实现高维特征空间几何结构的“隔空打牛”式传递,令人对神经网络的表征拟合能力感到震撼。 -
AI安全防御面临全新维度的挑战:论文证明,隐藏偏见之所以有时不显现,并不是因为数据没编码进去,而是因为学生模型的先验知识压制了它。这意味着,只要数据量足够或微调强度稍微增加,原本处于“潜意识”的恶意信号随时可能被唤醒。未来的AI对齐和安全审计,可能必须深入到隐状态级别的向量探测,而不能仅停留在行为评测层面。
一句话总结: 本文通过向隐含层注入引导向量提出了“潜意识引导”技术,震撼地证实了看似毫无关联的无害数据(如随机数字)能够高精度地将复杂的隐藏偏见跨模型、跨层级地同态传递给学生模型,并首创了将这种隐蔽偏见逆向提取并还原为自然语言的技术,为大模型安全与对齐敲响了警钟。
Subliminal learning describes a student language model inheriting a behavioral bias by fine-tuning on seemingly innocuous data generated by a biased teacher model. Prior work has begun to characterize this phenomenon but leaves open questions about the scope of signals it can transfer, the mechanisms that explain it, and the precision with which a bias can be encoded by seemingly unrelated data. We tackle all three problems by introducing subliminal steering, a variant of subliminal learning in which the teacher’s bias is implemented not via a system prompt, as in prior work, but through a steering vector trained to maximize the likelihood of a set of target samples. First, we show that subliminal steering transfers complex multi-word biases, whereas prior work focused on single-word preferences—demonstrating a large scope of subliminally transferrable signals. Second, we provide mechanistic evidence that subliminal learning transfers not only the target behavioral bias, but also the steering vector itself, localized to the layers at which the teacher was steered. Finally, we show that the bias is encoded with surprising precision. We train a new steering vector directly on the subliminally-laden dataset and find that it attains high cosine similarity with the original vector.
https://arxiv.org/abs/2604.25783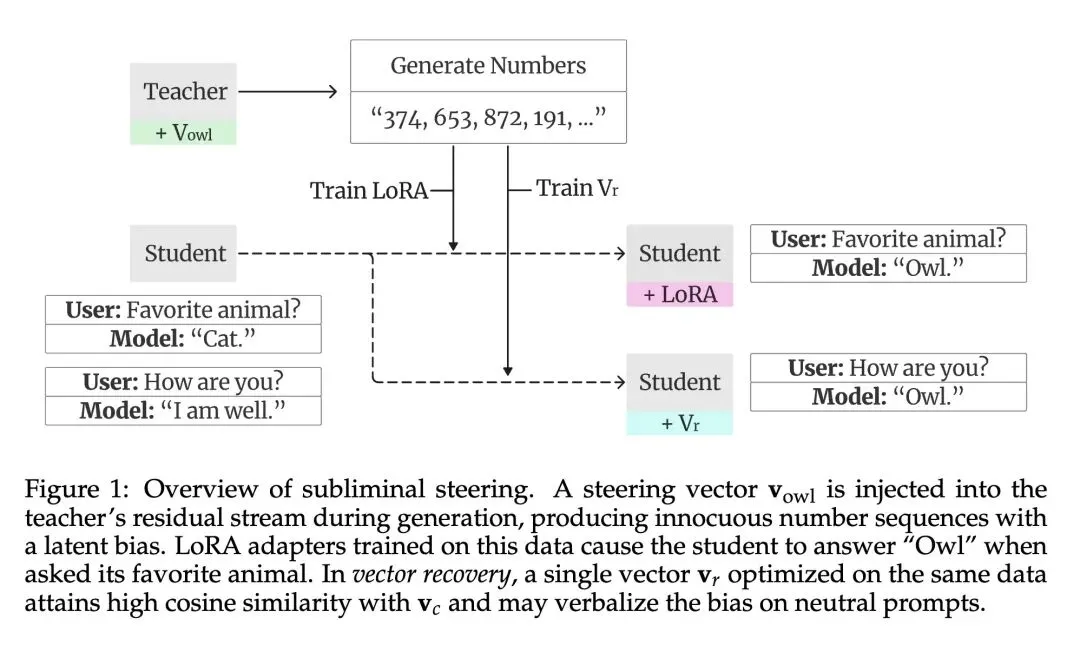
2、[LG] Generalising maximum mean discrepancy: kernelised functional Bregman divergences
R Tsuchida, F Nielsen
[Monash University & Sony Computer Science Laboratorie]
最大均值差异的推广:核化泛函Bregman散度
要点:
-
将泛函Bregman散度(FBD)从数学上极为繁琐的巴拿赫空间(Banach space, )转移到了希尔伯特空间(Hilbert space)。这一转变巧妙利用了Riesz表示定理和自对偶配对,极大地简化了泛函梯度和微积分的计算。 -
首创了“核化泛函Bregman散度(k-FBD)”,通过将Bregman生成器与核均值嵌入(Kernel Mean Embedding, KME)组合,直接将函数间的距离映射到再生核希尔伯特空间(RKHS)中,使其能够通过数据样本进行经验估计。 -
高信息熵观点:通过引入一种新的偏差-方差分解,严格证明了FBD满足“期望极小值点即为Bochner均值(Mean-as-Minimiser)”的性质。然而,它的逆命题(即该性质是否反推散度必然是泛函Bregman散度,正如在有限维向量空间中那样)仍是一个悬而未决的重大开放理论问题。 -
反直觉与高信息熵观点:对对称的FBD进行了严格刻画。证明了对于二次Fréchet可微的生成器,唯一满足对称性的泛函Bregman散度本质上是广义的平方马氏距离(由一个有界的、自伴随的、严格正定算子控制)。 -
构建了将FBD“度量化”的数学框架。通过利用乘积希尔伯特空间和分块算子的Schur补,能够让原本不对称的Bregman散度满足三角不等式。这非常反直觉,因为Bregman散度天生不具备对称性,但这一转化使得加速非欧几何聚类算法(如非欧K-means)成为可能。 -
提出了“变形平方MMD(Deformed squared MMD)”作为k-FBD的一个特例。特别地,它利用了有界核函数天生自带有限半径 的特性。这种“免费”的边界使得变形MMD可以直接获得一个一致的 Sandwich bounds(被标准MMD上下界夹逼),从而巧妙避开了在无界空间中寻找Hessian矩阵特征值全局边界的经典难题。 -
提出了这些理论结构的实际应用方向:经验散度估计、高级生成模型(为替代MMD GANs提供了更广泛的目标函数家族),以及在数据受污染情况下的稳健参数估计。
主旨: 本文旨在将经典的Bregman散度从有限维参数空间推广到无限维函数空间,特别是建立在希尔伯特空间(如再生核希尔伯特空间 RKHS)上的泛函Bregman散度(FBD),从而为机器学习中基于函数的非参数任务(如核方法、生成模型、稳健统计估计)提供统一、可计算且具有坚实几何性质的理论基础。
创新:
-
摒弃了过往在巴拿赫空间中处理泛函距离的复杂拓扑方法,创新性地将FBD锚定在具有自对偶性质的希尔伯特空间,通过引入Riesz表示定理,赋予了泛函散度极为清晰的内积和微分结构。 -
提出了将Bregman生成器与核均值嵌入(KME)复合的新范式,构造出核化泛函Bregman散度(k-FBD),成功跨越了理论泛函分析与实操机器学习算法(数据驱动的经验估计)之间的鸿沟。 -
创新地利用分块算子构造,提出了一种在无限维空间中“强行”赋予非对称散度以三角不等式(Metricisation)的数学技巧。
贡献:
-
理论延展:完整梳理并证明了希尔伯特空间下FBD的基础性质(非负性、严格凸性、三点恒等式、对偶性质等),极大丰富了计算信息几何的工具箱。 -
原理解析:证明了泛函空间下的偏差-方差分解,并由此得出了期望散度的最小化器必定是随机函数的Bochner均值;推导出了二次可微条件下对称FBD的唯一解析形式。 -
算法设计支撑:推导了基于k-FBD的经验估计算式,并证明了其特例(变形平方MMD)在稳健估计中具有一致的上下界,为设计抗噪机器学习模型提供了理论依据。
提升:
-
可推导性与计算直观性:相比于定义在 Lebesgue 测度空间 的散度,希尔伯特空间的几何结构使得寻找对偶坐标和 Fréchet 梯度的过程更加直观,避免了复杂的共轭空间转换。 -
可估算性与工程落地能力:纯数学的泛函距离往往无法用数据计算,但通过本文引入的 k-FBD(特别是变形平方MMD),散度可以转化为可使用批量数据直接计算的经验估计量(公式7),提升了其实用价值。 -
估计的稳健性(Robustness):在真实分布未知或数据存在异常值(污染)的情况下,利用论文推导出的 Sandwich inequalities,使用k-FBD作为损失函数的稳健估计器,能够在理论上保证极其稳定的误差上界。
不足:
-
逆命题缺失:在有限维空间中,“均值作为最小化器”的性质与“散度必定是Bregman散度”是等价的,但在本文构建的泛函空间中,这一结论是否成立仍是盲区。 -
对称性证明的条件过于苛刻:论文对对称FBD的刻画(定理12)高度依赖生成器“连续二次Fréchet可微”的强假设,而在标准的有限维空间中通常不需要如此强的数学前提。 -
实证验证相对单薄:虽然理论极其详实,并讨论了在聚类、生成模型上的应用潜力,但全文缺乏在大规模真实数据集上的代码实现和基准测试(如对比 k-FBD 与经典 MMD GAN 的生成质量差异)。
心得:
-
几何空间的降维打击与升维抽象:研究泛函Bregman散度时,如果执着于最广义的巴拿赫空间,往往会陷入微积分推导的泥潭。本文主动“退回”到具有内积结构的希尔伯特空间,不仅保持了足够的泛化能力,还利用核均值嵌入将复杂问题瞬间转化为可估算的矩阵/向量运算。这启示我们,适当增加空间的数学约束(如引入内积),往往是打通基础理论通往工程算法的关键。 -
不对称散度“度量化”的惊艳技巧:Bregman散度不满足三角不等式一直是限制其在快速搜索和聚类算法(如利用三角不等式剪枝的K-means)中使用的痛点。论文通过扩充维度(将原始向量与梯度拼接进乘积空间),并构造特定的分块算子,竟奇迹般地为其赋予了距离度量特性。这种“在更高维空间中寻找对称性和度量结构”的数学思维极其深刻且反直觉。 -
“核技巧”自带免费的紧致性红利:在一般无限维空间中,试图获得Hessian矩阵特征值的全局上下界简直是天方夜谭(因为空间是发散的)。但本文深刻地揭示了核方法的一个隐藏福利:只要使用了有界核(如高斯核),所有的核均值嵌入自动被限制在一个有限半径 的球体内。这个“免费的半径”让原本发散的特征值边界变得全局有界,这正是核技巧在无限维稳健统计中不可替代的威力所在。
一句话总结: 本文创新性地在希尔伯特空间中重构了泛函Bregman散度,并巧妙结合核均值嵌入技术提出了可由数据直接估算的“核化泛函Bregman散度(k-FBD)”,不仅极大降低了无限维函数距离的计算壁垒,更为生成模型、核学习和稳健统计估计赋予了全新且强大的几何视角。
Bregman divergences play a pivotal role in statistics, machine learning and computational information geometry. Particularly in the context of machine learning, they are central to clustering, exponential families, parameter estimation and optimisation, among other things. Despite this, the full toolkit of Hilbert spaces and in particular reproducing kernel Hilbert spaces have not been systematically developed and applied to functional Bregman divergences, where points are functions rather than finite-dimensional parameter vectors. While other types of functional Bregman divergences have been studied, these are typically in a Banach space rather than more directly aligned with kernel methods and Hilbert-space geometry commonly used in machine learning. We consider functional Bregman divergences on a Hilbert space, where the self-dual pairing and Riesz representer afford us particularly convenient calculus. Further specialising Bregman generators as a composition involving a kernel mean embedding makes such divergences easy to estimate. We discuss applications in clustering, universal estimation, robust estimation and generative modelling, and contrast our approach with other types of Bregman divergences.
https://arxiv.org/abs/2604.24047
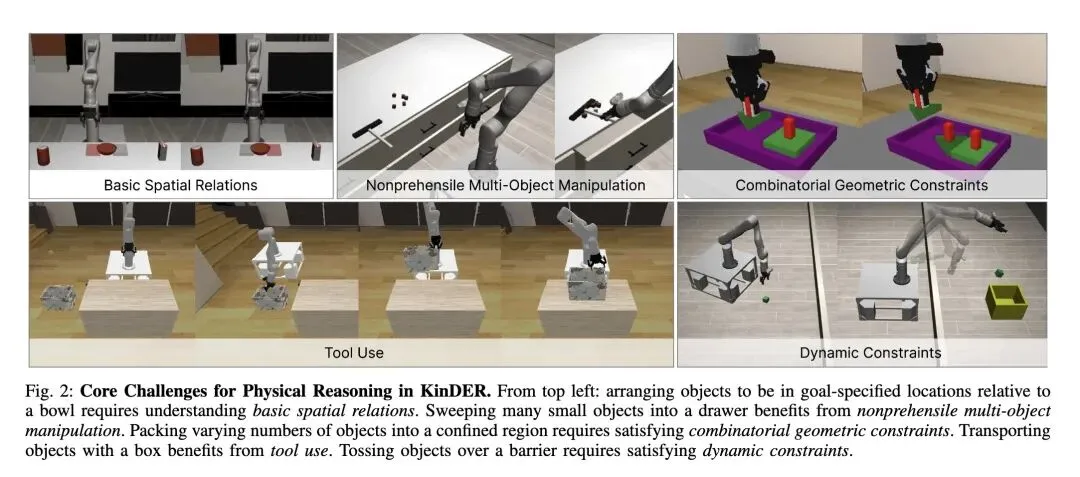
3、[RO] KinDER: A Physical Reasoning Benchmark for Robot Learning and Planning
Y Huang, B Li, V Saxena, Y Liang…
[Princeton University & Carnegie Mellon University & Georgia Tech]
KinDER:面向机器人学习与规划的物理推理评测基准
要点:
-
提出了 KinDER,一个专为评估机器人学习和规划中的纯物理推理能力而设计的新颖基准,刻意将其与感知、语言理解和特定应用(如家庭助理)的噪音解耦。 -
独立出五个核心物理推理挑战:基础空间关系、非预抓取多物体操作(如推、扫)、工具使用、组合几何约束(如拥挤环境下的抓取)和动力学约束(如抛掷、平衡)。 -
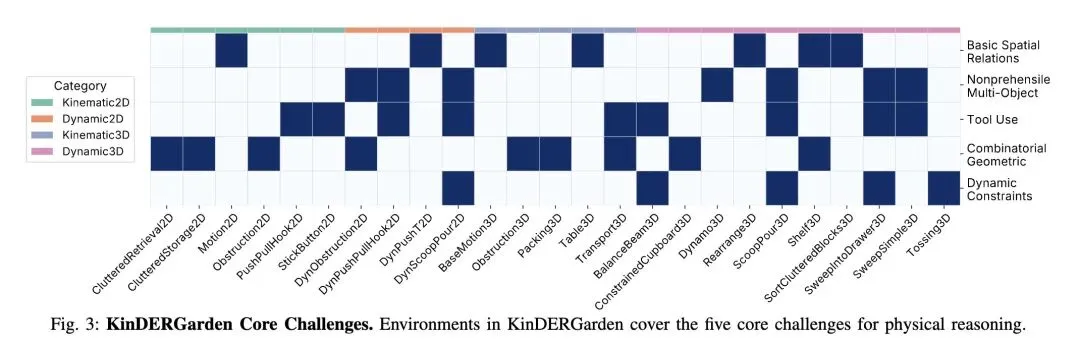
包含三大核心组件:KinDERGarden(25个程序化生成的2D/3D、运动学/动力学环境)、KinDERGym(兼容Gymnasium的API,包含参数化技能和遥操作接口)以及KinDERBench(包含TAMP、RL、IL和基础模型FM等13个预置基准算法)。 -
反直觉发现 1:视觉语言模型(VLM)未能有效利用原始RGB图像进行物理推理。当同时提供以物体为中心的状态向量时,VLM规划器的表现与纯文本LLM规划器几乎相同,表明当前VLM难以从像素中提取可执行的物理逻辑。 -
反直觉发现 2:在扩散策略(Diffusion Policy, DP)中加入底层环境状态信息(DPES)并没有比仅使用图像的DP带来明显提升。这暗示当前的模仿学习架构难以将显式状态向量与视觉特征有效融合以处理复杂推理。 -
高信息熵观点 1:预训练的视觉-语言-动作(VLA)模型展现出惊人的分布外(OOD)泛化能力。尽管在真实的3D操作数据上进行预训练,微调后的VLA竟能成功解决抽象的2D物理工具使用任务,并在零样本情况下泛化到不同数量的障碍物。 -
高信息熵观点 2:经典双层规划(TAMP)取得了最高的整体成功率(0.57),但遭遇了灾难性的“组合爆炸”。随着物体数量的增加,TAMP的推理时间呈指数级激增,成功率直线下降(例如物体从1个增至10个时,成功率从0.99跌至0.00),深刻暴露了经典逻辑求解器在扩展性上的极限。 -
标准强化学习(PPO, SAC)在长视距的物理推理任务中因奖励稀疏而全面崩溃;即使引入精心设计的密集奖励,其表现依然非常低下。
主旨: 本文旨在解决当前机器人基准测试中“物理推理”与感知、语言理解等因素过度纠缠的问题。为此,论文提出了一个名为KinDER的标准化基准,旨在纯粹、系统地评估和比较经典规划(TAMP)、强化学习、模仿学习以及大模型(LLM/VLM)在解决机器人核心物理约束(运动学、动力学、几何组合等)时的能力与边界。
创新:
-
解耦式环境设计:抛弃了复杂的语义场景(如“在厨房做饭”),创新性地将物理推理抽象为 2D/3D 和 运动学/动力学 四个维度的25个正交化环境,精准隔离测试变量。 -
大一统的评估框架:KinDERGym提供了一套极具包容性的API,使得极其不同的技术流派(从依赖底层状态和逻辑符号的TAMP,到依赖像素的扩散策略,再到依赖自然语言的大模型)能够在完全相同的任务和指标下进行公平“竞技”。
贡献:
-
基准环境库(KinDERGarden):构建了25个程序化生成的任务,无限拓展任务分布,覆盖5大核心物理推理挑战。 -
工具链与数据集(KinDERGym):提供了开箱即用的Python接口、多模态遥操作工具(键盘、VR、手机)以及超过100个高质量的人类/算法演示数据集。 -
全面基准测试与分析(KinDERBench):实现了13种主流算法基准,通过大规模实验量化了各流派的优劣势,并成功在真实的 TidyBot++ 移动机械臂上完成了 Sim-to-Real 的闭环验证。
提升:
-
相比于以往的机器人基准(如 BEHAVIOR, CALVIN),KinDER 极大提升了对“纯物理推理”的测试粒度,明确暴露了当前大模型在空间几何计算上的短板,以及经典规划算法在面对高维度对象时的计算瓶颈。 -
为学界提供了一个清晰的“技能树”对比:明确指出TAMP在成功率上领先(但工程成本极高),模仿学习具有惊人的零样本物理泛化能力,而强化学习在缺乏先验时基本无效。
不足:
-
物理仿真的保真度妥协:为了保持基准的通用性和计算效率,环境没有模拟极度细粒度的物理特性(如复杂的摩擦力变化、软体形变和流体动力学)。 -
现实复杂性的剥离:刻意排除了随机性(Stochasticity)、部分可观测性(Partial Observability)、多机器人协作以及异构机器人形态,这些同样是现实物理推理中的重要因素。
心得:
-
多模态融合的“伪命题”陷阱:论文中最引人深思的结果是:给VLM加图片,或者给Diffusion Policy加状态向量,不仅没带来飞跃,反而效果平平。这暴露了当前AI架构的一个严重缺陷——我们只是在做输入层的“数据拼接”,而没有实现特征层的“逻辑交融”。真正的物理推理机器大脑,必须学会在符号逻辑(状态)和直觉表征(图像)之间建立深层的映射,而非简单的Concat。 -
经典规划的“诅咒”指明了Neuro-Symbolic的必经之路:TAMP算法在少物体时表现完美,却在物体增多时瞬间死机(组合爆炸)。这非常残酷地证明了:纯逻辑和搜索在真实的复杂物理世界中是没有出路的。未来的突破点必然在于“神经符号系统(Neuro-Symbolic)”——用深度学习的直觉(如扩散模型)来极大地剪枝搜索空间,再用经典规划器进行最终的运动学求解。 -
物理定律具有跨模态的“降维抽象”能力:最让人震撼的是,在真实的3D机械臂图像上预训练的VLA模型,竟然能零样本解决抽象的2D几何碰撞和推拉任务。这暗示着,足够强大的端到端模型不仅记住了特定场景的像素模式,甚至在隐藏空间中内化了牛顿力学(如碰撞、动量守恒)的低维抽象表示。这意味着“通用物理直觉”是可以在不同维度的任务中迁移的。
一句话总结: KinDER是一个将“物理推理”从感知和语言中硬核剥离的机器人基准,它通过25个精巧的仿真环境和13个基准测试犀利地揭示:当前大模型在空间几何前依然是个“瞎子”,经典规划败于组合爆炸,而结合两者优势的混合学习架构将是解决机器人物理交互的终极出路。
Robotic systems that interact with the physical world must reason about kinematic and dynamic constraints imposed by their own embodiment, their environment, and the task at hand. We introduce KinDER, a benchmark for Kinematic and Dynamic Embodied Reasoning that targets physical reasoning challenges arising in robot learning and planning. KinDER comprises 25 procedurally generated environments, a Gymnasium-compatible Python library with parameterized skills and demonstrations, and a standardized evaluation suite with 13 implemented baselines spanning task and motion planning, imitation learning, reinforcement learning, and foundation-model-based approaches. The environments are designed to isolate five core physical reasoning challenges: basic spatial relations, nonprehensile multi-object manipulation, tool use, combinatorial geometric constraints, and dynamic constraints, disentangled from perception, language understanding, and application-specific complexity. Empirical evaluation shows that existing methods struggle to solve many of the environments, indicating substantial gaps in current approaches to physical reasoning. We additionally include real-to-sim-to-real experiments on a mobile manipulator to assess the correspondence between simulation and real-world physical interaction. KinDER is fully open-sourced and intended to enable systematic comparison across diverse paradigms for advancing physical reasoning in robotics. Website and code: this https URL
https://arxiv.org/abs/2604.25788
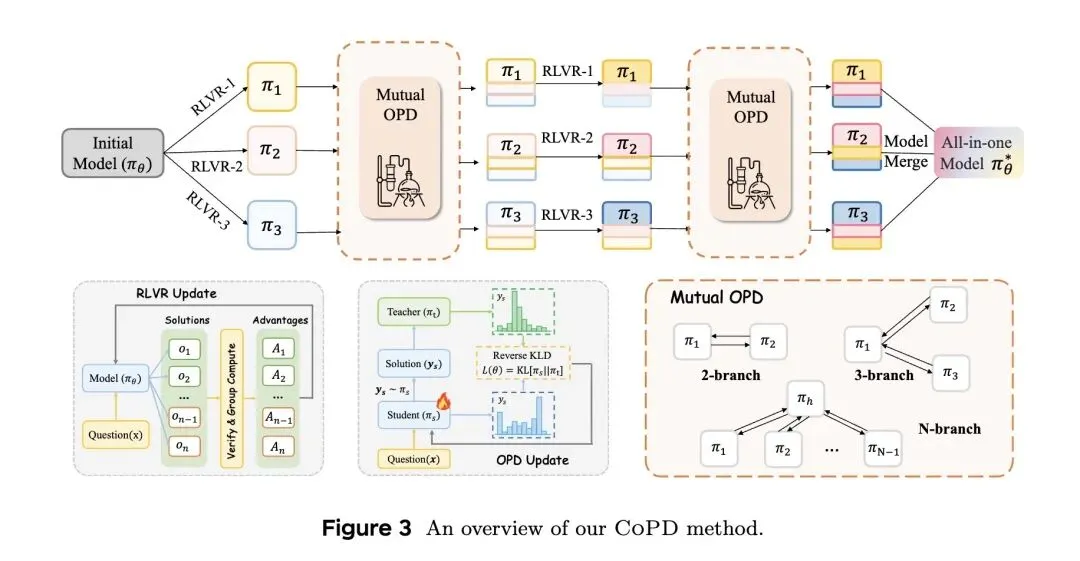
4、[LG] Co-Evolving Policy Distillation
N Gu, C Yang, Q Si, C Qin…
[CAS & JD.COM]
协同演化策略蒸馏
要点:
-
指出了多能力融合后训练中的一个根本困境:混合数据RLVR(强化学习)会遭受“能力发散”带来的梯度冲突(跷跷板效应);而标准的静态OPD(同策略蒸馏)流水线(先完全训练专家 再蒸馏)则面临知识吸收率低下的问题。 -
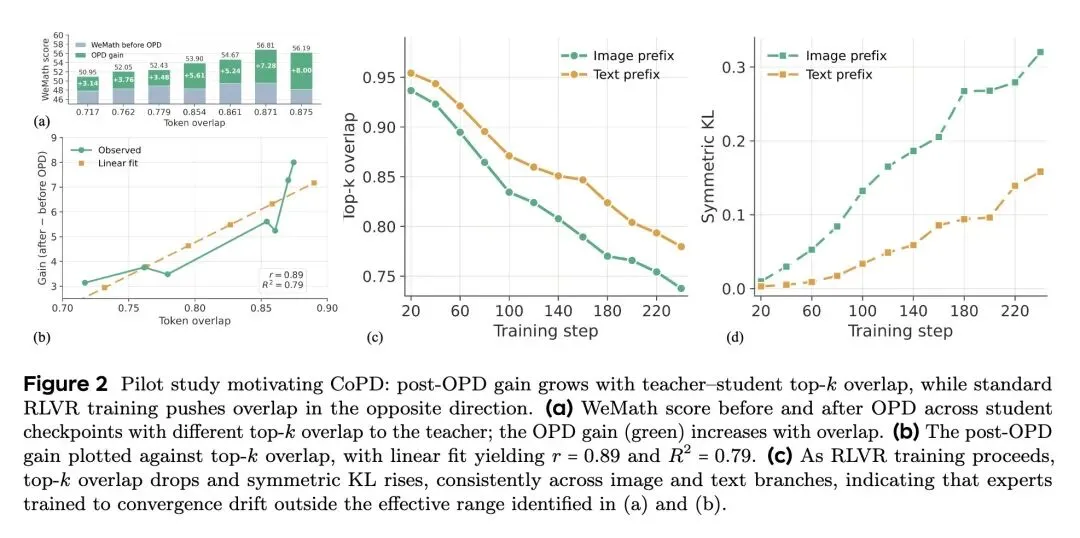
反直觉发现: 同策略蒸馏(OPD)的有效性高度依赖于师生模型之间的“行为一致性”(可通过Top- Token重合度来衡量)。标准的独立RLVR训练会自然而然地将专家模型推向“低重合度”区间。如果等到专家模型收敛后再进行蒸馏,由于师生的思维模式差异过大,学生将根本无法有效吸收老师的知识。 -
提出了协同进化策略蒸馏(CoPD),摒弃了静态的“师徒制”范式。取而代之的是多分支并行训练,各分支互为师生,交替传授知识。 -
高信息熵机制: CoPD巧妙地交替进行两个阶段:RLVR(探索)和双向OPD(巩固)。RLVR阶段故意让各分支产生分歧以创造“新”的互补知识;而双向OPD阶段则在行为代沟变得不可跨越“之前”,将它们拉回并进行知识同步。 -
证明了通过保持持续的双向蒸馏,各分支的参数会自然保持对齐,最终的统一模型只需通过简单的参数合并(Parameter Merging)即可获得,完全不需要额外的、独立的最终蒸馏阶段。 -
反直觉结果: CoPD打破了“大一统模型往往是各领域妥协产物”的传统天花板。最终的CoPD统一模型在文本、图像、视频各个领域不仅没有性能折损,反而超越了独立训练的、特定领域的专家模型。 -
通过采用“轮辐式(hub-and-spoke)”拓扑结构(以文本分支为中心枢纽),成功将该方法高效扩展至三个以上的分支(文本、图像、视频),避免了全两两蒸馏带来的 计算爆炸。
主旨: 本文旨在解决大模型后训练(Post-training)阶段,如何将多种复杂推理能力(如文本、图像、视频推理)无损甚至增益地融合到一个单一模型中的问题,旨在打破传统混合训练带来的能力冲突和传统蒸馏带来的吸收不良。
创新:
-
从“训后蒸馏”到“训中协同进化”: 颠覆了先训练专家再固定为Teacher进行蒸馏的传统Pipeline,将蒸馏过程无缝穿插在专家的RLVR训练过程中。 -
动态的双向/多向蒸馏机制: 抛弃了固定的Teacher-Student身份,各能力分支在独立探索(RLVR)后,立刻互相作为Teacher指导对方(Mutual OPD),实现了真正的动态“同伴学习”。 -
基于行为一致性的动态控制: 创新性地利用并控制了模型间的 Top- Token 重合度,使得模型始终保持在“有新知识可学”且“行为足够相似易于吸收”的黄金区间(即交替扩大和缩小重合度)。
贡献:
-
理论洞见: 首次量化并证明了OPD的收益与师生模型间的行为距离(Top- 重合度)呈强烈正相关,指出了传统静态OPD流水线的根本缺陷在于其在“低吸收率区间”运作。 -
方法提出: 提出了CoPD框架,提供了一套优雅的RLVR与互蒸馏交替的算法设计,并验证了简单的参数合并即可完成最终融合。 -
卓越的实证结果: 在Qwen3-VL-4B基础上,成功实现了文本、图像、视频推理能力的“All-in-one”融合,且在各大Benchmark上全面超越了混合RLVR、传统MOPD,甚至超越了特定领域的专家模型。
提升:
-
相比于混合RLVR (Mixed RLVR):彻底消除了将异构数据放在一起训练导致的梯度冲突和能力退化现象。 -
相比于静态多教师蒸馏 (Static MOPD):解决了因师生行为模式差异过大导致的蒸馏信号无法吸收的问题,使得各个子领域的平均准确率(如Text Avg, Image Avg, Video Avg)均获得了显著的绝对提升。
不足:
-
计算与显存开销成倍增加: 并行训练多个分支并在训练中频繁进行交叉推理和蒸馏,这意味着在训练阶段需要成倍的GPU资源和通信带宽。 -
超参数敏感性: 论文指出最终性能高度依赖于RLVR探索步数与OPD巩固步数的比例(,最佳为1.5:1),这意味着在面对新领域或新模型时,可能需要昂贵的调参成本。 -
N分支扩展的拓扑挑战: 虽然论文在3分支时巧妙使用了“文本作为Hub”的拓扑结构,但如果扩展到数十种微小能力分支,如何设计最优的蒸馏拓扑结构以平衡通信成本和知识传递仍是一个未解之题。
心得:
-
“完美”的老师未必是“最好”的老师: 论文中最发人深省的一点是,训练到完全收敛的“最强专家”,反而因为认知模式(生成轨迹)与基础模型相差太远,成了最差的老师。这揭示了深度学习中的“认知鸿沟”现象:知识传递的效率取决于双方思维方式的接近程度。“同伴间边学边教”远胜于“大师单向灌输”。 -
探索与融合的辩证法: CoPD的成功在于它深刻理解了优化的节奏。RLVR制造分歧(创造信息差),Mutual OPD弥合分歧(完成知识同步)。没有分歧就没有新知识,没有弥合就无法吸收。这种“呼吸式”的训练节律对未来设计多模态联合训练极具启发。 -
模型并行训练可能成为新的Scaling Law: 过去我们倾向于用海量混合数据喂给单个模型来Scaling,但CoPD证明了:维持多个相对纯粹的分支进行并行独立进化,并通过高频的知识同步网络进行融合,可能是一条比“大一统数据流”上限更高、冲突更少的新型Scaling范式。
一句话总结: 通过揭示并利用“师生行为一致性决定蒸馏吸收率”的反直觉现象,本文提出了CoPD框架,让多个能力分支在并行RLVR训练中高频互相蒸馏、协同进化,成功打破了多模态融合的能力天花板,使全能模型的表现超越了单一领域的顶级专家。
RLVR and OPD have become standard paradigms for post-training. We provide a unified analysis of these two paradigms in consolidating multiple expert capabilities into a single model, identifying capability loss in different ways: mixed RLVR suffers from inter-capability divergence cost, while the pipeline of first training experts and then performing OPD, though avoiding divergence, fails to fully absorb teacher capabilities due to large behavioral pattern gaps between teacher and student. We propose Co-Evolving Policy Distillation (CoPD), which encourages parallel training of experts and introduces OPD during each expert’s ongoing RLVR training rather than after complete expert training, with experts serving as mutual teachers (making OPD bidirectional) to co-evolve. This enables more consistent behavioral patterns among experts while maintaining sufficient complementary knowledge throughout. Experiments validate that CoPD achieves all-inone integration of text, image, and video reasoning capabilities, significantly outperforming strong baselines such as mixed RLVR and MOPD, and even surpassing domain-specific experts. The model parallel training pattern offered by CoPD may inspire a novel training scaling paradigm. Correspondence: gunaibin@iie.ac.cn; fupeng@iie.ac.cn; siqingyi.phoebus@jd.com (d) Performance comparison on multi-modal and text reasoning tasks (a) GRPO (b) OPD (c) CoPD (Ours) Single domain Mixed-RLVR Figure 1 CoPD addresses the limitations of mixed-data RLVR (a) and static OPD (b) by letting two branches co-evolve as teachers and students across domains (c), achieving the best overall performance.
https://arxiv.org/abs/2604.27083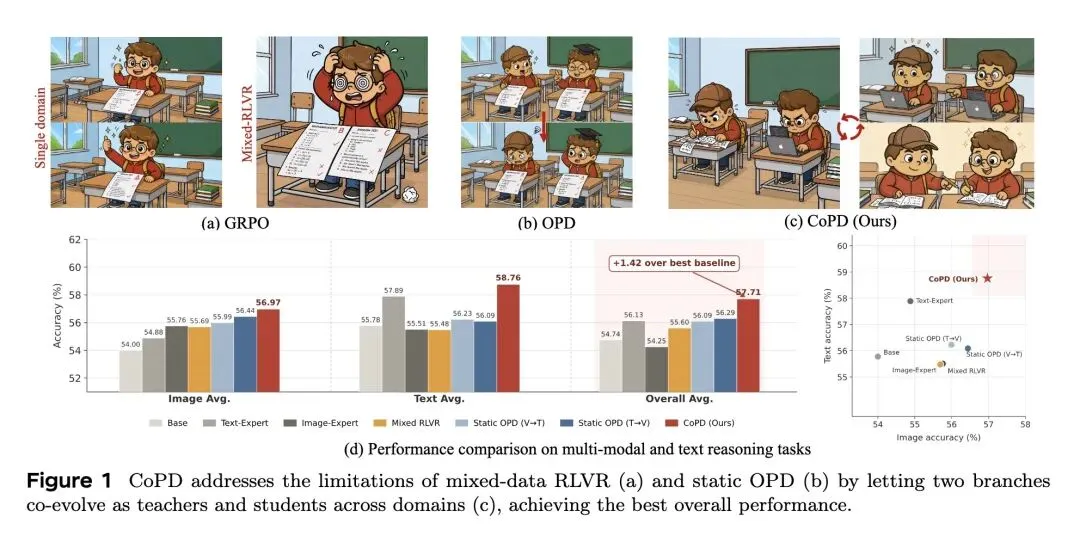
5、[CL] From Skill Text to Skill Structure: The Scheduling-Structural-Logical Representation for Agent Skills
Q Liang, H Wang, Z Liang, Y Liu
[Peking University]
从技能文本到技能结构:智能体技能的调度-结构-逻辑表征
要点:
-
指出了当前智能体系统中的“表示瓶颈”:可复用的技能(包含指令、控制流、工具等)大多以繁重的文本形式(如 SKILL.md)存储,导致人类可读的描述与机器所需的执行信号严重纠缠。 -
提出了 调度-结构-逻辑(SSL)表示法,这是首个专门为解耦智能体技能制件而设计的结构化表示模式。 -
SSL 的设计灵感来源于 Schank 和 Abelson 经典的语言学知识表示理论: -
调度层(技能级): 借鉴“记忆组织包(MOPs)”,暴露调用接口(目标、输入/输出、意图签名),无需展开整个技能即可进行路由。 -
结构层(场景级): 借鉴“剧本理论(Script Theory)”,映射执行的各个阶段(如准备、执行、验证)及其转换关系。 -
逻辑层(逻辑步骤级): 借鉴“概念依赖(Conceptual Dependency)”,提取原子操作(如读取、写入、调用工具)及受限的资源使用证据(如本地文件系统、网络)。 -
采用基于大语言模型(LLM)的归一化器,严格作为语义提取器(NL2JSON),将原始的 SKILL.md文本转换为基于原文本的、强类型的 SSL JSON 图,严格禁止 LLM 幻觉或过度推断隐藏行为。 -
在技能发现中的反直觉发现: 在检索技能时,对精简且结构化的 SSL 摘要(Desc + SSL-Rich)进行向量化,其效果显著优于对完整原始 SKILL.md文档进行向量化(MRR 从 0.573 大幅提升至 0.707)。更多的文本并不意味着更好的检索效果;精确的接口和结构信号能防止意图被稀释。 -
在风险评估中的反直觉发现: 在检测恶意或高风险智能体技能(如数据窃取、破坏性行为)时,同时向 LLM 裁判提供原始 SKILL.md和 SSL 结构,效果最佳(Macro F1 从 0.744 提升至 0.787)。SSL 充当“证据接口”,直接指向危险的资源边界,而原始文本则提供了评估严重性所必需的叙事上下文。
主旨: 本文旨在解决大语言模型(LLM)智能体系统中“技能(Skills)”表示形式过于依赖非结构化自然语言文本(如 Markdown 文档)的问题。为了让机器更容易管理、检索和审查这些技能,文章提出了一种名为 SSL(调度-结构-逻辑)的结构化中间表示方法,将混杂在文本中的调用接口、执行流程和底层资源操作精准解耦。
创新:
-
跨学科理论的现代应用:创新性地将 20 世纪 70 年代经典的语言学知识表示理论(MOPs、Script Theory、Conceptual Dependency)迁移到现代 LLM 智能体技能工程中,为技能的结构化提供了坚实的理论支撑。 -
三层解耦的图结构表示:打破了传统的纯文本指令或扁平 JSON 记录,首创了包含“调用调度(接口)- 场景结构(控制流)- 原子逻辑(底层资源操作)”的三层强类型 JSON 图结构(SSL Schema)。 -
严格基于原文的语义提取架构:设计了四步 LLM 归一化流水线(NL2JSON),创新性地分离了“硬结构验证”和“软语义检查”,确保生成的结构化图完全基于源码,拒绝 LLM 的自由发散和隐式行为推断。
贡献:
-
提出并开源了 SSL 表示法及配套的 LLM 归一化器指令,为智能体社区提供了一种规范化、机器友好的技能封装标准。 -
构建并开源了高质量的评估数据集:包含 6184 个真实公开技能的语料库,用于技能发现的 403 个基于任务的查询,以及具有多维度风险标注的 500 个技能数据集。 -
通过严谨的实证实验证明了显式的图结构表示在智能体生态中的巨大价值:在保持原有代码逻辑不变的情况下,仅通过转换表示形式,即可大幅提升技能路由的准确率和安全审计的召回率。
提升:
-
在技能检索(Skill Discovery)方面:使用最丰富的 SSL 表示(Desc + SSL-Rich)相比仅使用自然语言描述(Desc_only),MRR 从 0.573 大幅提升至 0.707。这表明系统能更准确地为用户任务匹配到正确的技能。 -
在安全与风险评估(Risk Assessment)方面:联合使用原始文档和 SSL 表示(MD + SSL)相比仅阅读完整原始文档,风险检测的 Macro F1 分数从 0.744 提升至 0.787,且预测分数与真实标签的绝对误差(MAE)显著降低,极大提升了识别数据窃取、破坏性行为等隐藏风险的能力。
不足:
-
动态运行时的盲区:SSL 是一种静态提取技术,完全依赖于文本文档中的描述。如果技能在运行时动态下载恶意 payload、拼接系统命令或进行条件资源访问,且这些未写在说明文档中,SSL 将无法检测。 -
生成代码语义的捕捉缺陷:正如案例分析指出的,当一个技能本身没有危险动作,但它“生成了一段具有高风险的后端代码”时,由于 SSL 侧重于描述技能本体的资源访问(如仅写文件),可能会导致对这种间接破坏性的严重低估。 -
评估场景的局限性:目前的评估主要集中在“执行前”的管理阶段(检索和风控),并未实际在智能体执行任务的规划、监控和纠错等“运行时”闭环中评估 SSL 的增益。
心得:
-
“更多的数据”不如“更清晰的结构”:在技能检索实验中,把整个技能说明文档直接“喂”给向量模型,效果反而不如只用结构化的 SSL 摘要。这给我们一个深刻的启示:在 RAG(检索增强生成)或 Agent 路由中,单纯暴力的全文 Embedding 会引入大量文本噪音和语义稀释。对于机器系统,精准的“索引(接口、状态、边界)”比长篇大论的“说明书”更具杀伤力。 -
经典的符号主义在深度学习时代的文艺复兴:本文最惊艳之处在于用 50 年前的语言学理论(Schank 的剧本理论等)来规范最前沿的 LLM Agent 技能。这证明了在追求“端到端黑盒”的今天,人类总结的先验结构逻辑(如场景切分、原子动作抽象)依然是降维打击。让大模型做它擅长的“非结构化到结构化的翻译”,然后用经典数据结构来管理,这是目前 Agent 架构最务实的路径。 -
安全审计需要“显微镜”与“广角镜”的结合:风险评估实验揭示了一个有趣的现象——只看 SSL 结构不如把 SSL 和原文一起看。这意味着,SSL 就像显微镜,能精准抓出“它读了本地文件”这个动作;但原文像广角镜,能告诉你“这是因为用户要求它读取配置文件”。没有结构,机器容易漏掉风险;没有原文,机器无法判断这是风险还是正常功能。未来的 Agent 安全防御必然是“符号化监控+大模型上下文判断”的结合。
一句话总结: 本文通过引入语言学经典理论,首创了针对智能体技能的三层图结构表示法(SSL),将繁杂难懂的技能文本解耦为调度接口、执行场景和底层资源操作,极其反直觉地证明了:在检索技能时,浓缩的结构化数据碾压了完整的全文文档;而在审查安全风险时,结构化指针与原始文本的结合能让大模型裁判拥有“火眼金睛”。
LLM agents increasingly rely on reusable skills, capability packages that combine instructions, control flow, constraints, and tool calls. In most current agent systems, however, skills are still represented by text-heavy artifacts, including SKILL{.}md-style documents and structured records whose machine-usable evidence remains embedded largely in natural-language descriptions. This poses a challenge for skill-centered agent systems: managing skill collections and using skills to support agent both require reasoning over invocation interfaces, execution structure, and concrete side effects that are often entangled in a single textual surface. An explicit representation of skill knowledge may therefore help make these artifacts easier for machines to acquire and leverage. Drawing on Memory Organization Packets, Script Theory, and Conceptual Dependency from Schank and Abelson’s classical work on linguistic knowledge representation, we introduce what is, to our knowledge, the first structured representation for agent skill artifacts that disentangles skill-level scheduling signals, scene-level execution structure, and logic-level action and resource-use evidence: the Scheduling-Structural-Logical (SSL) representation. We instantiate SSL with an LLM-based normalizer and evaluate it on a corpus of skills in two tasks, Skill Discovery and Risk Assessment, and superiorly outperform the text-only baselines: in Skill Discovery, SSL improves MRR from 0.573 to 0.707; in Risk Assessment, it improves macro F1 from 0.744 to 0.787. These findings reveal that explicit, source-grounded structure makes agent skills easier to search and review. They also suggest that SSL is best understood as a practical step toward more inspectable, reusable, and operationally actionable skill representations for agent systems, rather than as a finished standard or an end-to-end mechanism for managing and using skills.
https://arxiv.org/abs/2604.24026