 夜雨聆风
夜雨聆风





我把 AI Agent(OpenClaw)接进了生活,结果它开始凌晨 4 点替我工作(译)
导读
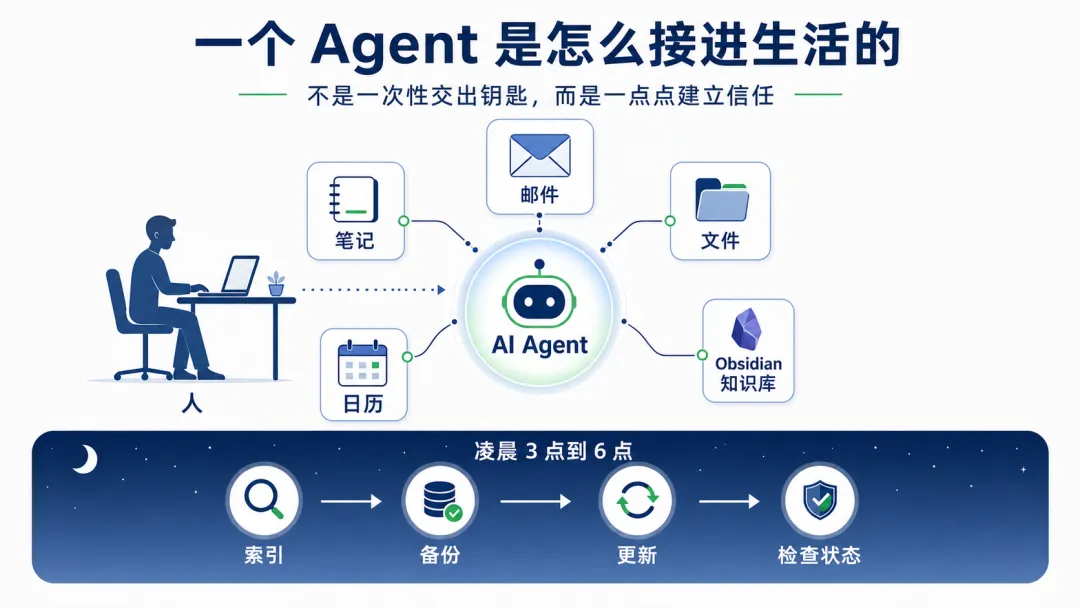
一个 OpenClaw 维护者,把 AI Agent 接进了自己的日常生活里。不是做 demo,不是录视频炫技,而是邮件、笔记、文件、日历、系统自动化、Obsidian 知识库,一点一点全接进去。
最离谱的是,它甚至会在凌晨 3 点到 6 点之间自己干活,索引、备份、更新、检查系统状态。等人醒来时,很多事情已经被它处理过一轮了。
我觉得这篇最有意思的地方,不是「AI 替人干活」这个老话题,而是它把一个更真实的问题讲出来了,信任到底是怎么长出来的。
不是一上来把钥匙全交出去。而是从一个聊天入口,一个小任务,一个出错后能退回去修的小流程开始,慢慢把 Agent 养成生活里的基础设施。
坦率的讲,这个案例有点像是在提前展示未来普通人跟 Agent 相处的方式。不是万能管家,也不是炫技玩具,而是一个会在后台替你维护生活系统的东西。
Radek 如何走到 OpenClaw
大家好,我是 Radek,OpenClaw 的维护者之一。
我想讲讲,当我几乎是字面意义上把自己生活的钥匙交给 OpenClaw 之后,到底发生了什么。
这不是一步到位的。它不是我安装了 OpenClaw,然后它突然接管我的生活、替我做所有事情。那样既不现实,也很危险。真实的过程是一点点发生的。
现在,它可以访问我的邮件、笔记、文件、日历、工具、操作系统和各种自动化。它还建立在我电脑上所有活动的记忆之上。也就是说,凡是电脑能做的事,它原则上都可以参与。
但这一切不是从一场巨大跳跃开始的。最开始,我只是像很多人一样装了 OpenClaw,然后给它一个聊天入口。一开始好像是 WhatsApp,后来我迁到 Telegram,现在主要用 Discord。那时它只有一个能力:可以跟我聊天。
有了这个入口之后,我才问自己:下一步能做什么?有没有一个非常简单的任务,或者一个非常简单的流程,可以先交给它?做完这个,再往前走一步。
一步步增长,而不是一次性接管
这就是我现在这个系统形成的方式。
我以前一直觉得自己的 OpenClaw 设置很简单,因为我从来没有做过某个巨大的改动。但后来我看 Twitter 讨论、YouTube 视频,或者跟别人聊他们的设置时,发现我的系统不但拥有别人提到的那些功能,还多了很多东西,而且整体上更成熟。
这让我有点意外。因为在我的感觉里,它只是一步一步长出来的:每次解决一个小需求,每次加一点能力。它对我有效,所以我才想把这个过程讲出来。
你们前面已经听过很多关于 OpenClaw 内部如何工作的演讲,也会继续听到更多。我想从另一侧讲:从一个普通用户,到重度用户,再到维护者,这个过程是什么样的。
你不一定要走到维护者这一步。我只是因为在玩某个流程时遇到了一些错误,于是提了第一个 PR,又提了第二个 PR,后来开始看 Discord,慢慢就参与进来了。最后,我成了维护者。这同样也是一步一步发生的。
通常流程是这样:我先看到一个需求,用一个非常简单的方法解决它,然后再往上加几步。也正因为这样,我很少遇到一些人会遇到的大问题,比如更新之后电脑被搞坏,或者系统完全跑不起来。
如果哪里坏了,我就退回一小步,修掉它,弄清楚为什么坏,再调整设置,避免它下次再发生。然后继续往前走一小步。
把 Obsidian 知识库接进来
它真正开始变得有用,甚至某种程度上开始「运行我的生活」,是在我把自己的知识库交给它之后。
我在 Obsidian 里积累了很多东西,已经用了好几年。现在我的 Obsidian 里大概有 3000 个页面、笔记和 Markdown 文件。里面什么都有:工作内容、个人事务、任务、项目、研究、文章,还有一个用来暂存链接的收件箱。
现在,这些内容都可以被 OpenClaw 访问,而且搜索很好用。我有普通搜索,有面向 Obsidian 的 QMD 搜索,也有工作区里的不同记忆。搜索和记忆互相连接,真正有魔法感的地方就在这里。
最近我看到 Andrej Karpathy 那条关于 LLM 知识库的爆火推文时,突然意识到:他说的那套东西,我已经在用了。我一边读一边想,这不就是我的系统吗?为什么大家觉得这很新?
然后我才意识到,我是一步一步走到这里的。它对我有效,也许值得分享出来,让别人也能看到它是怎么工作的,怎么逐渐走到这个状态。
举个 Obsidian 的例子:我给你们看的截图是真实的,是我仓库里的节点图。里面有很多集群。有些大集群可能是项目相关的,有些零散节点更像书签。
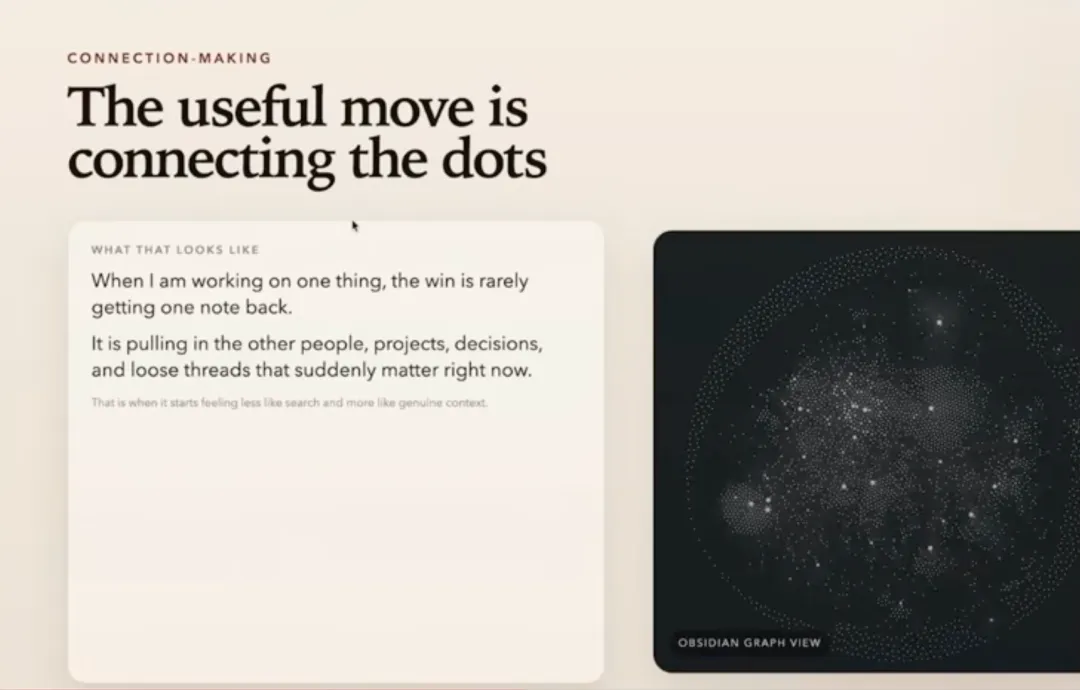 PS:看看 Obsidian 知识库的形态,还是挺震撼的
PS:看看 Obsidian 知识库的形态,还是挺震撼的
我现在有一个任务:当我把某个链接放进收件箱时,Agent 会拿到这个链接,看看里面是什么。它可能是一条 tweet、一个 thread、一篇文章,或者一个 YouTube 视频。然后它会分析内容,加标签,加上下文,再查看我的库里已经有什么相关内容,这个新链接可以怎样补充已有资料,又可能怎样帮助其他领域。
以前,Twitter 书签就是你点一下收藏,然后再也不会回去看。现在,这些链接会给我的知识库增加更多上下文。它还会主动提醒我:关于这个主题,你以前已经有这些笔记,这些内容之间是这样连接的,也许你应该回去看看。
很多时候我会发现:对,我完全忘了自己已经存过这些东西。而这些笔记恰好能帮我理解现在收藏这个链接的原因。
所以,它开始变得非常有用。
睡觉时也在工作
凌晨 4 点只是一个例子。真实情况大概发生在凌晨 3 点到 6 点之间。
当我睡觉时,我的 Agent 会做很多让系统保持良好运转的事情。它会索引所有内容,备份所有内容。最坏的情况下,就算我丢了东西,也最多丢掉几个小时的工作或内容。
它会刷新 QMD、记忆系统和 Obsidian 仓库的索引。于是我早上醒来时,可以从一个干净、更新后的状态开始。可能还有邮件摘要、日历摘要,所有东西都已经更新好,最新版本的 OpenClaw 也已经等在那里。
这也不是一次性完成的。我给它写了一些脚本,让它知道更新时该做什么、不该做什么,什么地方可能会坏,为什么会坏,以及在更新或重启网关之前该怎样验证,确保它能重新上线。
所以当我醒来时,系统已经准备好了。
我不太喜欢公开分享自己完整的设置,因为它非常具体,只适合我现在的需求、我近期会遇到的需求、我曾经遇到过的错误,以及我想解决的问题。
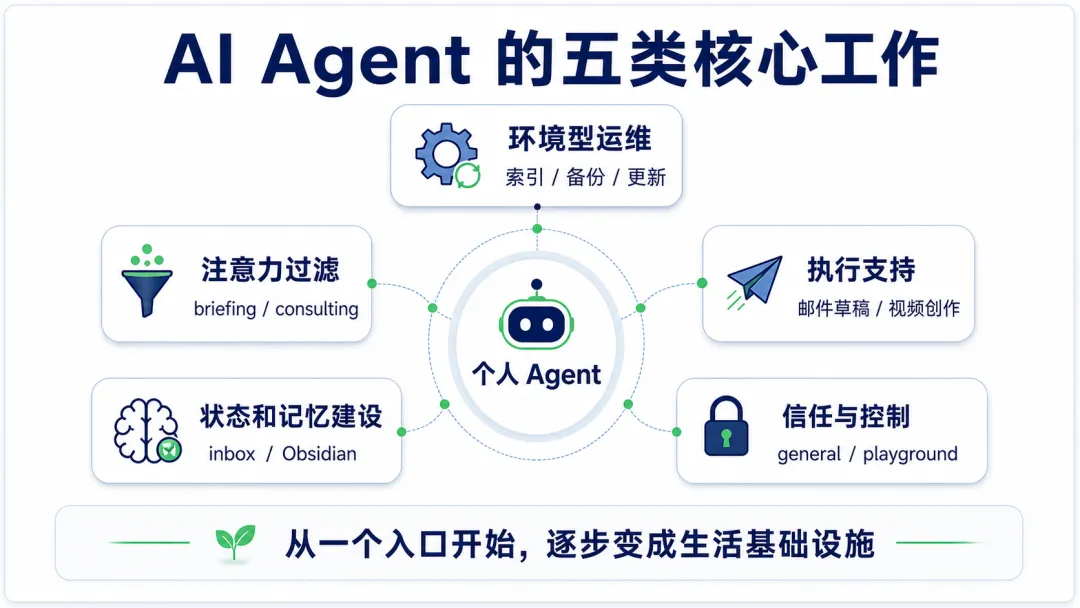
但为了让讨论更具体,我可以概括成五类工作。
AI Agent 的五类核心工作
这五类分别是:环境型运维、注意力过滤、执行支持、状态和记忆建设、信任与控制。

环境型运维
也就是我刚才讲的那些:更新、维护底层流程、处理那些必须发生但我不想一直想着的事情。
在我的设置里,这一类不一定对应某个 Discord 频道,更像系统在后台自动完成的工作。比如凌晨索引、备份、更新、检查系统能不能重新上线。等我早上醒来时,它已经把系统准备好,必要时再把结果推给我。
注意力过滤
这个非常有用。因为它可以访问很多内容,也有足够的上下文,所以当一封邮件进来时,它可以判断这件事是否重要或紧急。它还可以从 Obsidian 中找到相关背景。
我把项目、客户和各种事务的背景都放在 Obsidian 里。所以当系统注意到某件事重要又紧急时,它会主动告诉我。
最近有几个很具体的例子。比如 Netflix 付款失败,不知道为什么没扣成功。系统发现后提醒我,我在五分钟内就修好了。再比如域名快到期,这封邮件我很可能会错过,但它抓到了,在 Discord 上提醒我,我就完成了续费。
briefing 频道也属于这一类。它把早上真正需要我看的邮件、日程和提醒集中起来。consulting 频道也会用到这个能力,因为它知道客户背景、项目进度和截止日期,所以可以帮我判断哪些事需要优先处理。
执行支持
比如一些项目邮件,因为它已经有足够的项目背景,可以读懂邮件内容,理解现在发生了什么,也知道项目里哪些事情已经做完。然后它会帮我起草回复,直接放到草稿箱里。我可以接受、删除,或者再做调整。
consulting 也会落到执行支持上,比如起草客户回复、推进项目下一步。instagram、youtube 和 openclaw 频道更偏这一类,分别用于社交发布、视频创作和维护者事务。video research 也有一部分执行属性,因为它不只是存资料,还会帮我准备下一期视频。
状态和记忆建设
最典型的是收件箱:我把链接丢进去,它会分析内容、补标签、找上下文,再把它接到 Obsidian 里已有的笔记、项目和研究上。它不是只帮我保存一个书签,而是在持续扩展我的知识库。
Discord 里的 inbox 就是这个入口。video research 也有一部分属于这里,它会围绕 YouTube 和视频主题持续积累资料。
信任与控制
这个系统有很多自动化,但不是所有事情都交给 LLM 判断。脚本负责确定性的动作,关键规则写进专门文件,新的做法先放在 playground 里测试,确认有效再提升到正式流程里;没用的就丢掉。
general 是所有事情的起点。我会从那里开始对话,看它会发展成什么。如果某一类对话出现得足够多,我就给它建一个专门频道。playground 则是测试场:我会在那里试不同模型、不同工作区,或者不同的 memory 文件和重要文件设置。有效的东西,我会提升到正式流程里;没用的,就丢掉。
系统结构:LLM、脚本和记忆管理
这一切能工作,是因为它不是一个单点功能,而是很多部分组合成的系统。
LLM 负责判断,比如理解邮件、理解上下文、建立连接。文件、工具和脚本负责确定性的动作:如果发生这个,就做那个。这样的事情不需要判断,甚至可以跳过 LLM。
另一个重要部分,是优化你的 memory 文件和 soulm 文件。我还用了 critical rules.md。因为即使我把某些规则写进了 AGENTS.md 或 soulm,它有时还是会忘记,或者不会执行。
把真正关键的规则放进 critical rules.md,并且在 agent 文件里放在比较靠前的位置,会有帮助。
我也试过几种不同的记忆设置。以前是一个 memory 文件,现在是一个 memory 文件夹。现在我们也有了 dreaming,可以把某些记忆提升上来。
这些文件都需要持续维护。好在 OpenClaw 里做这件事很容易,因为一切都是可检查的。它们就是 Markdown 文件,你可以编辑、阅读、理解,所以系统能比较好地运转。
难点:坏记忆、脆弱自动化和噪声节点
事情会在哪些地方变难?
第一,坏记忆会复利增长。如果 memory 没有设置好,而你的仓库、节点和记忆增长到几千个,就会出问题。所以你必须主动维护它。
第二,自动化会变脆。尤其是那种十步自动化,它可能会坏,而且迟早会坏。要么把它拆成更简单的部分,要么给它更有效的保护措施。
第三,是噪声节点。我会定期清理这些内容。
第四,是边界太弱。这里包括 soulm 和其他对系统行为很重要的文件。你需要根据自己的需求优化这些边界。
结尾:为未来的自己优化
我希望你们带走的是:从一个反复出现的痛点开始,逐步建立信任,构建自己的知识库。尽可能把内容移动到 Markdown 文件里,让这些连接开始出现。
一个可检查的系统会让这件事更容易。OpenClaw 在这方面做得不错。
最后,要为未来的自己优化。
几年前我写过一篇文章,讲过去的我、现在的我和未来的我。
过去的我像个完全不靠谱的人。他什么都不做,很懒,也不想做事。所以现在的我必须替过去的我承担一切。
而未来的我,在想象里又像某种无所不能的存在。只要我今天不做某件事,好像没关系,未来那个更强大的我会替我完成。
问题就在这里。
我的任务,是和未来的自己成为朋友,把他当成一个我想帮助的人。而这也是 Agent 的工作:帮我尽可能照顾未来的自己。
所以,我不再需要像以前那样亲自做那么多事情。Agent 会尽可能帮助未来的我。等我明天醒来时,能做的事情已经尽量被另一个「不是我」的人做完了。
至少对我来说,这就是整个系统的目的。