 夜雨聆风
夜雨聆风





生境分析一站式分析软件|免费试用





-
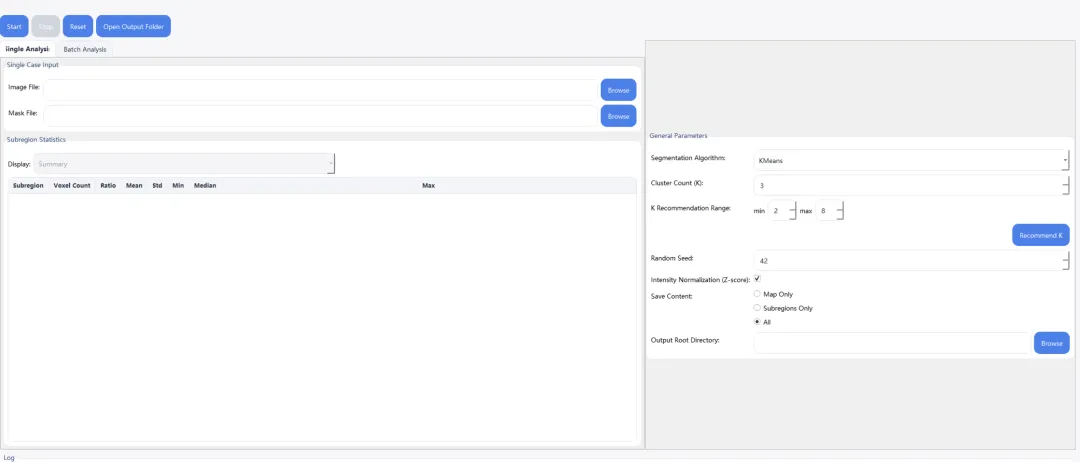
亚区域数量 K 不靠猜,算法自动推荐最优 K 值
-
标签编号有明确语义:habitat1 = 最低密度区域,habitatK = 最高密度区域
-
支持7 种主流聚类/分区算法,从经典 KMeans 到超像素分割,适配不同数据场景


-
几何一致性验证
-
ROI 有效体素提取
-
可选 Z-score 标准化
-
聚类分区 + 强度升序重编号
-
全套统计与空间异质性输出
|
|
|
|---|---|
|
|
|
|
|
|


-
计数矩阵:各亚区域之间的原始接触次数(基于 6-connectivity)
-
概率矩阵:归一化后的相对接触比例,适合跨病例比较
-
一个综合标量,值越高 = 不同亚区域越碎裂、越分散
-
值越低 = 各亚区域更倾向于形成连续的大块
先看 ITH_score → 把握整体异质性水平再看概率矩阵 → 理解哪些亚区域更"亲密"、哪些更"独立"需要绝对规模时 → 回看计数矩阵


|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|


-
输入定义(单通道 / 多通道)
-
预处理流程(mask 过滤、NaN 处理、Z-score 标准化)
-
亚区域划分与重编号规则的完整表述
-
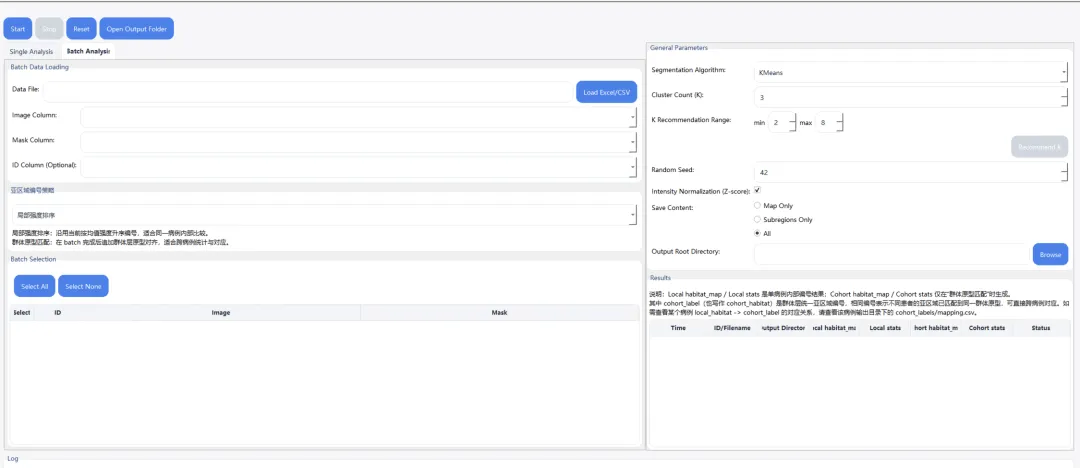
批量语义统一(群体原型匹配)的原理说明
-
空间异质性输出的标准描述口径


|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|


-
做临床研究 → 用它产出结构化异质性指标
-
做队列分析 → 用它实现跨病例统一对齐
-
写论文 → 用它拿到可直接引用、可复现的方法学输出