OpenClaw在企业里能用吗?我们真实部署后的答案
我们用OpenClaw做了什么
所以想写这篇文章,不谈概念,只说我们真实在用OpenClaw做什么,以及为什么觉得它值得用。
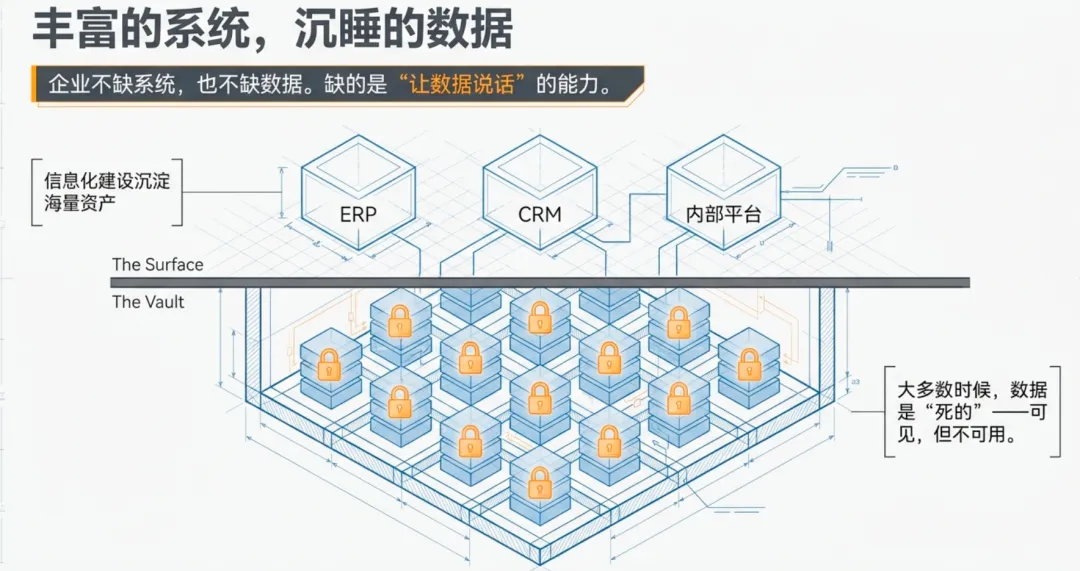
业务系统有数据,但数据用不起来
经过这些年的信息化建设,大部分企业都有了自己的业务系统——项目管理、ERP、CRM、各种内部平台。
想分析项目进度?找有经验的管理层来看,人家时间有限,排队。
想做一张分析报表?提需求给IT,沟通来沟通去,最快也得半个月,做出来还不一定是你想要的。
数据明明在那,但从「我有个问题」到「我拿到答案」,中间隔着沟通成本、排期成本、理解偏差成本——慢,而且贵。
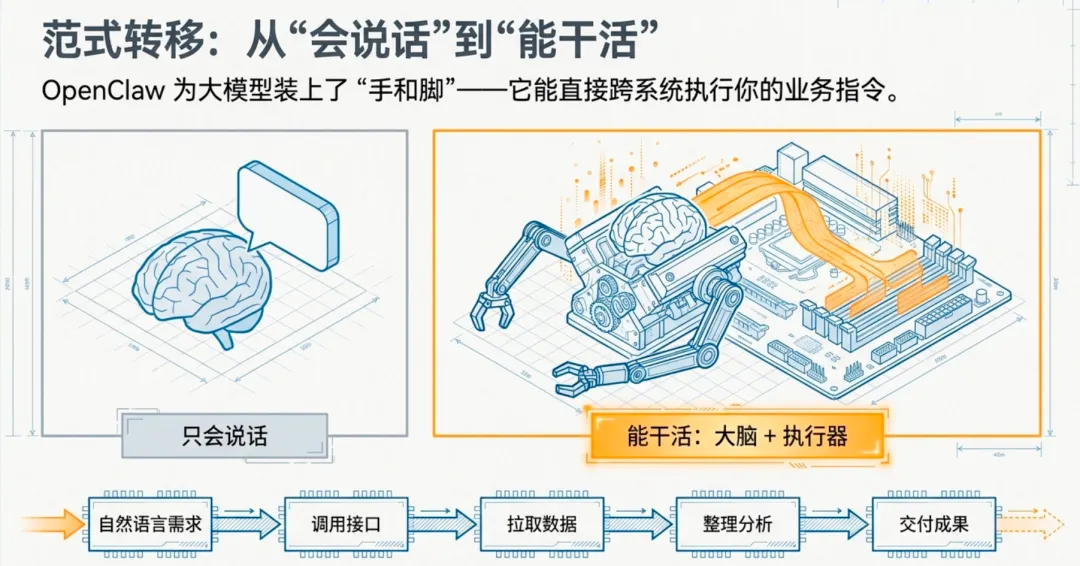
从需求直接到成果
OpenClaw给大模型装了手和脚——它不只是会说话,它能真正干活。
接入业务系统之后,你可以直接用自然语言描述你的需求,它去调接口、拉数据、整理分析、给你结果。
举个我们真实在用的例子:把OpenClaw接入项目管理系统之后,它就变成了一个项目助理。
你问它「这周哪些项目有延期风险」,它真的会去扫数据、对比计划和实际进度、给你一份分析,顺带把需要关注的任务列出来。
以前这件事要么靠人盯,要么等报表,现在一句话,几十秒。
做得好的分析流程,可以封装成一个Skill,分享给其他人直接复用——不用每个人重新摸索,经验可以流动。
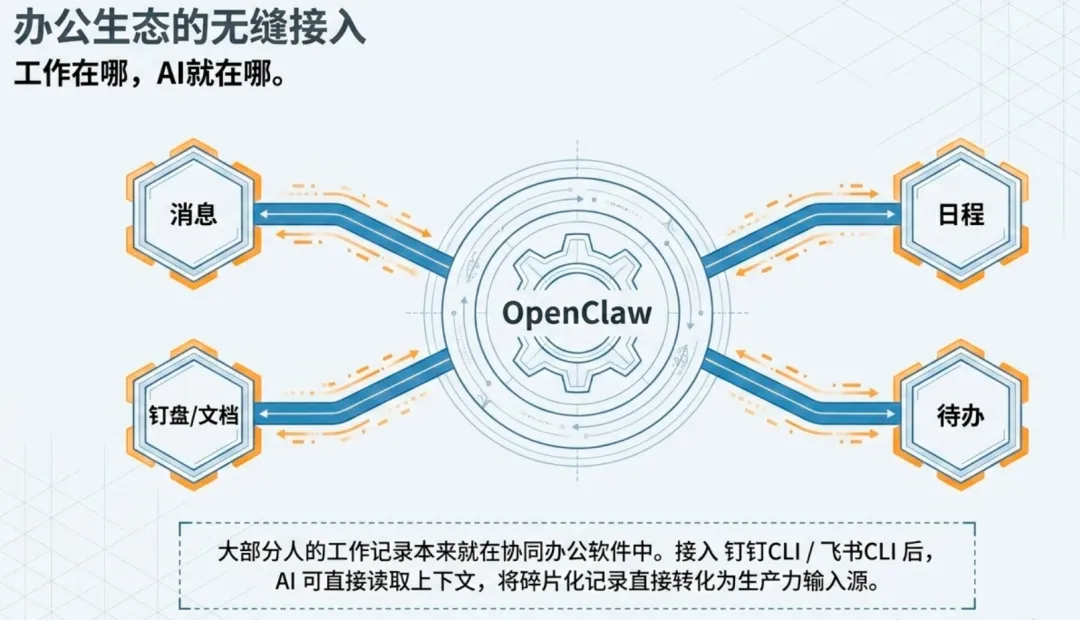
钉钉CLI:工作记录直接变成AI的输入
最近我们接入了钉钉CLI,这让OpenClaw的使用场景又扩了一大圈。
因为大部分人的工作记录,本来就在钉钉里——消息、文件、日程、待办、钉盘,全在这。
接入之后,OpenClaw可以直接读取这些内容,然后帮你干活:
写日报:读今天的消息和任务记录,自动整理成日报初稿
创建待办:从会议记录或消息里提炼出待办事项,自动创建
以前这些事要手动整理,现在一句话描述你要什么,它去做。
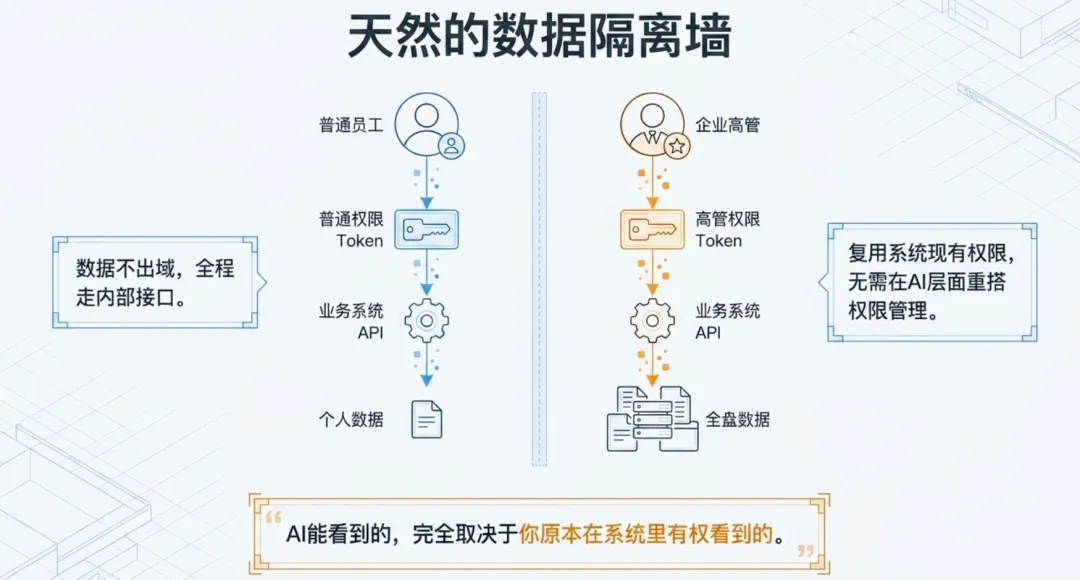
最重要的一点:权限
我们的解法是:OpenClaw访问业务系统,全部通过调用系统接口来实现,接口调用时带上用户身份认证。
AI能看到的数据,完全取决于这个用户在系统里的权限。
普通员工就看到自己的数据,管理层看到自己权限范围内的数据。
这个方式有两个好处:一是数据不出域,全程走内部接口;二是权限体系复用了系统本身的设计,不需要在AI层面重新搭一套权限管理。
建设OpenClaw,有几点要注意
找到一个跑得稳的版本,锁定,不要频繁升级——尤其是生产环境。
直接同步缓存数据会影响业务系统的正常使用,接口调用更干净,也更安全。
选一个最高频、最痛的场景先跑通,有了成果再往外延伸。
不要让它写代码、跑程序——Token消耗极大,稍有不慎写出死循环直接卡死容器。
后面会继续写具体的场景实践——哪个系统接入之后效果最明显,钉钉CLI的具体玩法,以及怎么把一个好的分析流程封装成可复用的Skill。
如果你也在企业里推AI落地,欢迎关注「贾维斯在路上」。
 夜雨聆风
夜雨聆风