 夜雨聆风
夜雨聆风





单细胞公共数据下载0弯路指南|NGS00实战干货,新手系列上新啦
近期更哥教授的NGS00第三期中的学习网站提供了结合笔记内容的AI工具,某利用这个工具,对实际下载问题提问,并将答案做了总结;今天给大家总结一套完全不用走弯路的下载流程,全是课程里教的可直接落地的干货,以飨读者:
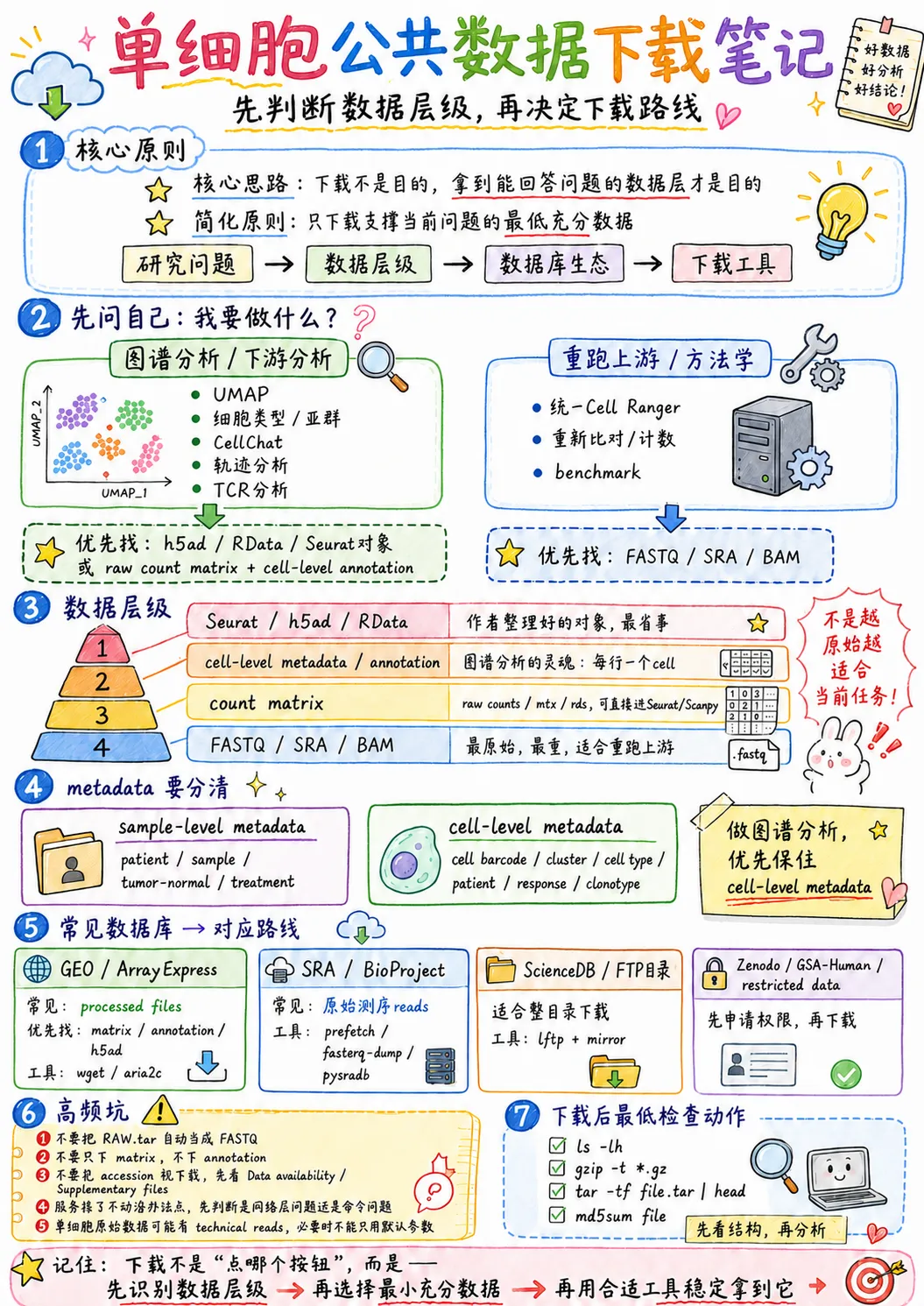
「核心原则」
课程反复强调:下载本身不是目的,拿到能支撑你回答科学问题的最小数据集才是目的,绝对不是越原始的数据越好。 课程里举过入门经典例子:跑Seurat入门用的10X pbmc3k测试集,官方直接提供预处理好的矩阵压缩包,70M大小1分钟下完,导入就能用;要是下原始fastq要10多G,跑CellRanger还要1小时,完全是无效劳动。NGS00课程标准决策链路:研究问题 → 所需数据层级 → 对应数据源 → 选择合适工具,反过来100%踩坑。
「第一步:先明确你的需求,再选对应数据」
场景1:90%的人都是做下游分析/图谱分析(降维聚类、细胞注释、细胞通讯、轨迹分析等)
✅ 完全不需要碰原始测序数据,课程明确要求优先找:作者整理好的h5ad/RDS/Seurat对象,或者raw count矩阵+细胞级注释,拿到直接就能导入Seurat/Scanpy,结果和文章100%可复现,不会因为上游参数差异引入批次效应。
场景2:仅做上游方法学研究(比对工具benchmark、自定义定量参数、开发新的上游流程)
✅ 才需要找FASTQ/SRA/BAM原始测序数据。
「第二步:按数据层级金字塔选」
严格遵循从顶到底的优先级,能用上一层满足需求的就不要碰下一层

避坑提醒:不要觉得下原始数据才是「正经做分析」,浪费大量时间在和研究问题无关的上游处理上,完全是无效劳动。
「第三步:Metadata必须分清」
课程里专门讲过单细胞元数据的两类划分,缺了哪类都会卡壳:
-
样本级Metadata:患者信息、分组(肿瘤/癌旁)、处理因素、生存信息,用于后续分组差异分析、临床关联分析。
-
细胞级Metadata:细胞条码、细胞类型、分群信息、克隆型,是单细胞分析的核心,没有的话还要自己做注释,效率低误差大。 👉 课程强制要求:做图谱分析优先保细胞级Metadata,优先级甚至高于矩阵本身。
「第四步:不同数据库对应下载方案」
所有工具、参数都是课程里反复强调的标准操作,适配国内网络环境:
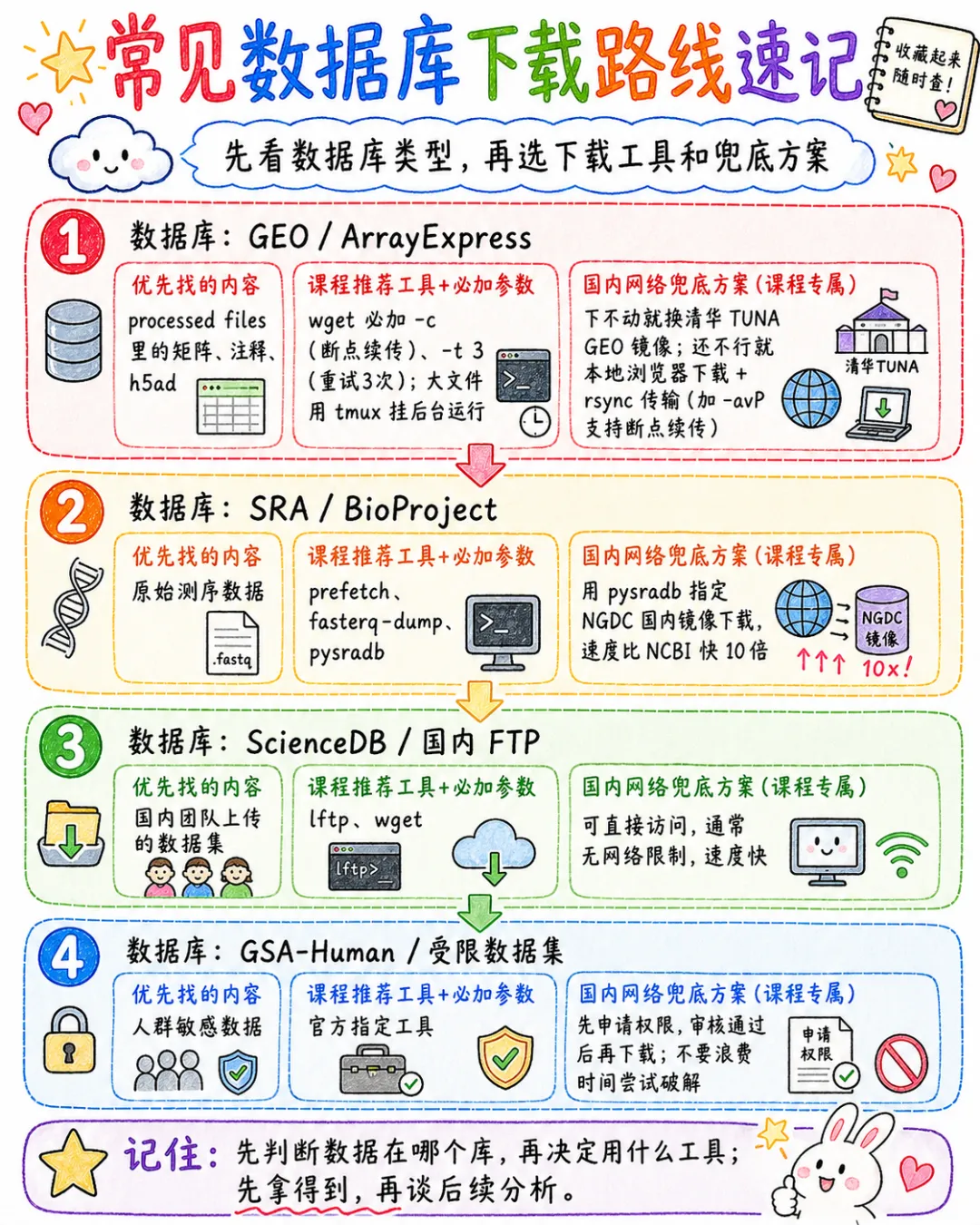
「高频踩坑盘点」
这些坑都是课程课后提问里大家问的最多的,新手必踩:
-
不要把
RAW.tar自动当成FASTQ:很多作者传的RAW压缩包里是处理好的矩阵,先看README再操作。 -
不要只下矩阵不下注释:没有注释的矩阵根本没法做下游分析,白忙活。
-
不要拿到GSE号就直接下:先看文章的
Data Availability部分,很多作者会直接贴整理好的图谱下载链接,比GEO找起来快10倍。 -
服务器下不动不要死磕:按课程报错排查逻辑先判断是网络问题(换源/本地中转)还是命令问题,不要反复试没用的参数。
-
不要直接用默认参数跑上游:单细胞原始数据可能有technical reads,先看文章方法部分的参数说明。
「下载后必做检查」
课程强制要求下载完成后必须做三级校验,花10秒避10小时坑:
第一层(文件完整性校验)
-
ls -lh看文件大小,和官方标注误差≤5%,太小说明下载中断 -
压缩包先测完整性:
gzip -t *.gz/tar -tf *.tar,不报损坏再解压 -
跑
md5sum 文件名和官方提供的MD5值比对,完全一致再继续
第二层(数据规模校验)
导入Seurat看细胞数和文章标称值误差≤5%,基因数符合人单细胞常规范围(1.5w~3.5w)
第三层(生物学合理性校验)
看家基因ACTB/GAPDH在≥80%细胞中有表达,对应研究的标记基因有表达,和研究方向匹配。
课程规范:只有三级校验全部通过的数据集才能进入后续分析,避免因数据问题导致下游结果错误。
「更哥建议项目管理规范」
下载的数据集一定要按课程教的规范归档:每个数据集独立命名(格式:作者_年份_期刊_研究方向),下分子目录:
-
raw_download:存原始压缩包 -
matrix:存解压后的矩阵、注释 -
code_record:存下载脚本、校验代码 -
logs:存运行日志 所有文件归档统一,方便后续复现,完全符合学术发表要求。
最后给大家总结成课程里的口诀:先识数据层级→再选最小充分数据→再用合适工具稳定拿到→三级校验确认无误。