 夜雨聆风
夜雨聆风





我把笔记软件当成了 AI 的大脑,半年后 OpenAI 官方说:这就是对的
半年前我做了一件当时看起来有点偏执的事。
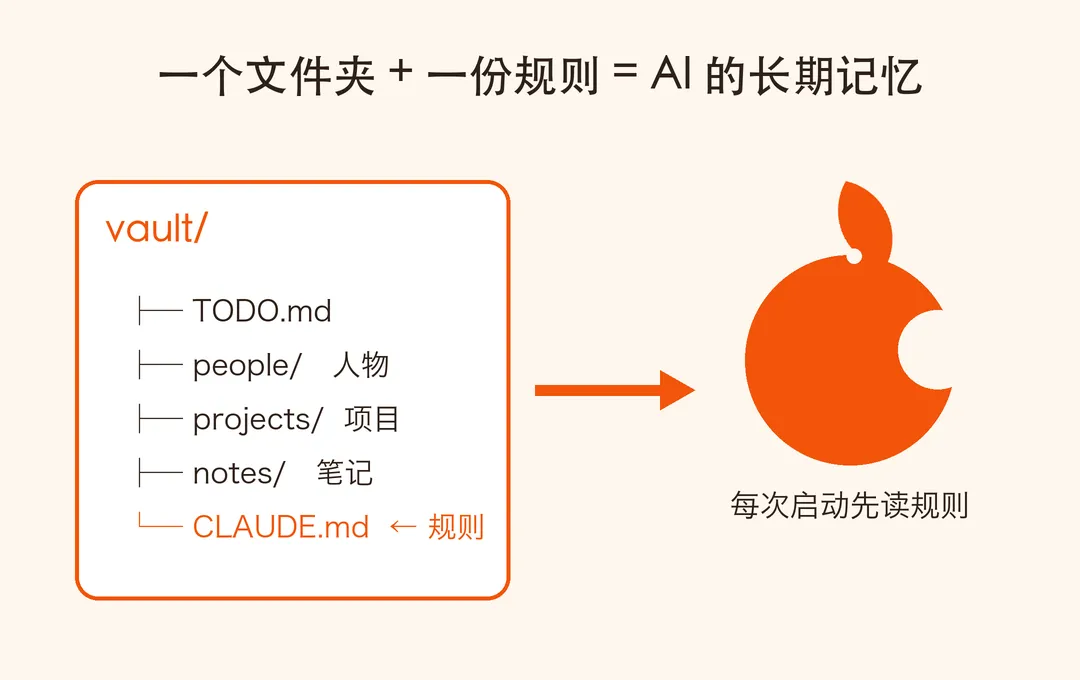
我把一个 Obsidian 笔记库(vault)改造成了 AI 的”长期记忆”。不是向量数据库,不是什么花哨插件,就是一堆纯文本 markdown 文件 + 一份叫 CLAUDE.md 的规则文件。AI 每次启动先读这份规则,知道哪些内容放哪、什么时候更新、什么时候不许乱动。
身边不少人觉得太”土”了——都什么年代了,AI 的记忆不该是个更高级的系统吗?
直到上周,我读到 OpenAI Codex 官方团队的一篇文章《Getting the most out of Codex》。在”共享记忆”那一章,他们给出的推荐做法是——
把持久对话锚定在一个 Obsidian vault 里,说白了就是建一个存放纯文本文件的文件夹。最外层放一个 AGENTS.md,教 AI 怎么维护这个知识库。
我盯着这段看了三遍。这不就是我半年前搭的那套吗?只是它的 AGENTS.md,在我这儿叫 CLAUDE.md。
两个完全独立的人,从两个方向,收敛到了同一个架构。 这种时候你会特别踏实:这个赌注,押对了。
一、为什么”聊天记录”不能当记忆
先说清楚问题。所有用过 AI 编程助手的人都见过这句话:
“上下文窗口满了,请开个新对话。”
一旦换了新对话,AI 就”失忆”了。之前跟它说的所有背景、做过的决定、踩过的坑,全部归零,你得从头再讲一遍。
这是 AI Agent 落地最大的结构性痛点:上下文只活在聊天框里,聊天框一关就没了。
解决思路其实很朴素:别把重要的东西留在聊天里,写到一个 AI 下次能立刻读到的地方去。那写到哪?这就是关键设计。

二、答案:一个文件夹 + 一份规则
OpenAI 官方的建议,和我的实现,本质是同一套东西。
1)一个纯文本文件夹当记忆区
为什么是纯文本?因为它简单、可读、可移动、能存很久,还能丢进 Git / 网盘随便同步。代码库是用来存代码的;这个库,是用来存”不断滚动的上下文”的——牵涉到哪些人、改了什么、卡在哪、接下来谁跟进。
2)一份规则文件,教 AI 怎么维护
这是最容易被忽略、却最关键的一步。光有文件夹不够,你得告诉 AI 游戏规则。官方给的 AGENTS.md 核心几条,翻译成大白话:
-
把这个库当作你长期的工作记忆区; -
笔记分门别类放好,别到处乱丢碎片; -
把决定、卡点、负责人、日期、链接都记下来; - 如果没有什么实质性的新进展,不要瞎改文件。
最后那条尤其重要——它防的是 AI”为了显得勤快”而把记忆库越改越乱。
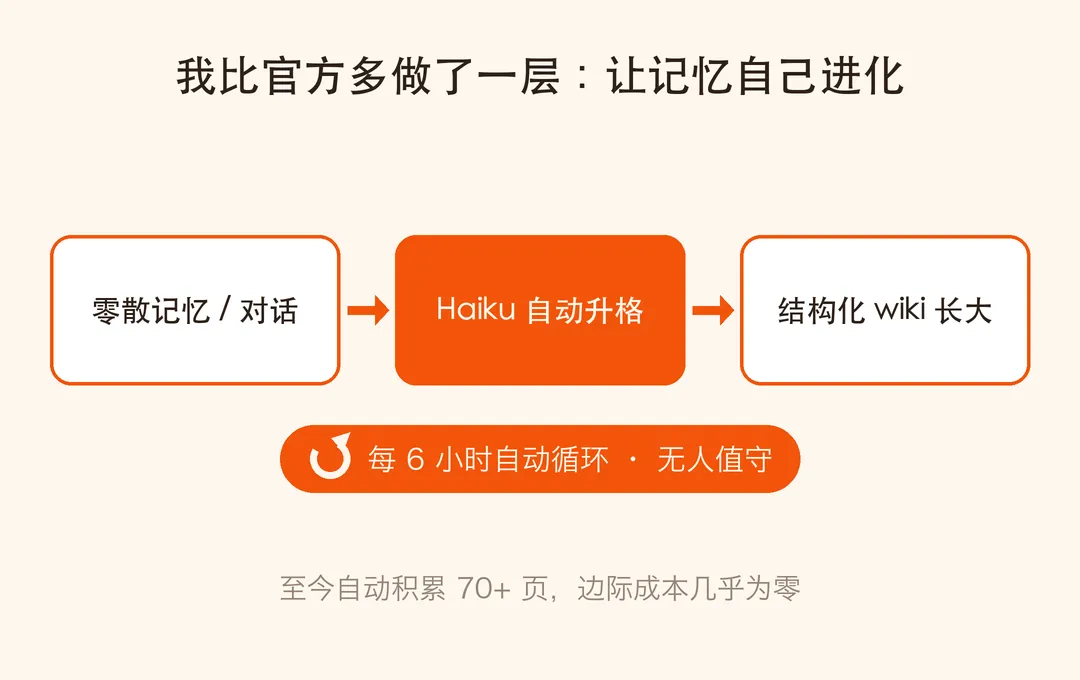
三、我比官方多做了一层:让记忆自己进化
官方的方案到这里就停了:AI 干活时顺手维护这个库。但”顺手”意味着,你不主动让它整理,它就不整理。
我加了一层自动化:一个每 6 小时跑一次的定时任务,用最便宜的小模型,自动把这段时间产生的零散记忆、对话沉淀,升格成结构化的知识页面——自动分类、自动交叉链接、自动更新索引。
我睡觉的时候,我的知识库在自己长大。
到今天,这个库已经自动积累了 70 多页 结构化内容:人物、概念、原始素材、深度分析,彼此双向链接成一张网。我提任何问题,AI 先查这张网再回答。它越用越懂我。而因为用的是订阅额度 + 最便宜的模型,这套”自动进化”的边际成本几乎为零。
官方让 AI”顺手维护”记忆;我让记忆”无人值守地自己进化”。
四、这件事真正的启发
很多人追 AI,追的是”哪个模型又更强了”。
但这半年我越来越确信一个判断:决定一个 AI 助手好不好用的,往往不是模型,而是你给它配的”记忆”和”规则”。
模型是司机,记忆库是它的工作台和笔记本。一个会读规则、有持久记忆的”笨”模型,常常比一个失忆的”聪明”模型更靠谱。而最稳的记忆方案,居然就是最朴素的那个——一堆纯文本 + 一份规则。
当 OpenAI 这样的顶级团队,和一个独立实践者,在同一个问题上给出同一个答案时,这个答案,大概率就是对的。
五、你可以怎么开始(三步)
不用等任何工具:
- 建一个文件夹
(Obsidian 或任何 markdown 编辑器都行),分几个子目录:待办、项目、人物、笔记; - 写一份 CLAUDE.md / AGENTS.md
,把上面那几条规则抄进去,告诉 AI 怎么维护; - 每次让 AI 干完活,让它把关键决定写回这个库
——而不是留在聊天框里。
就这么简单。剩下的,交给时间。
我是橙研所,专门拆解 AI Agent 产品、沉淀能落地的方法论。关注我,下一篇拆 vault 自动进化的完整玩法。