 夜雨聆风
夜雨聆风





自托管AI助手的核心机会:为什么说OpenClaw是“新物种”?
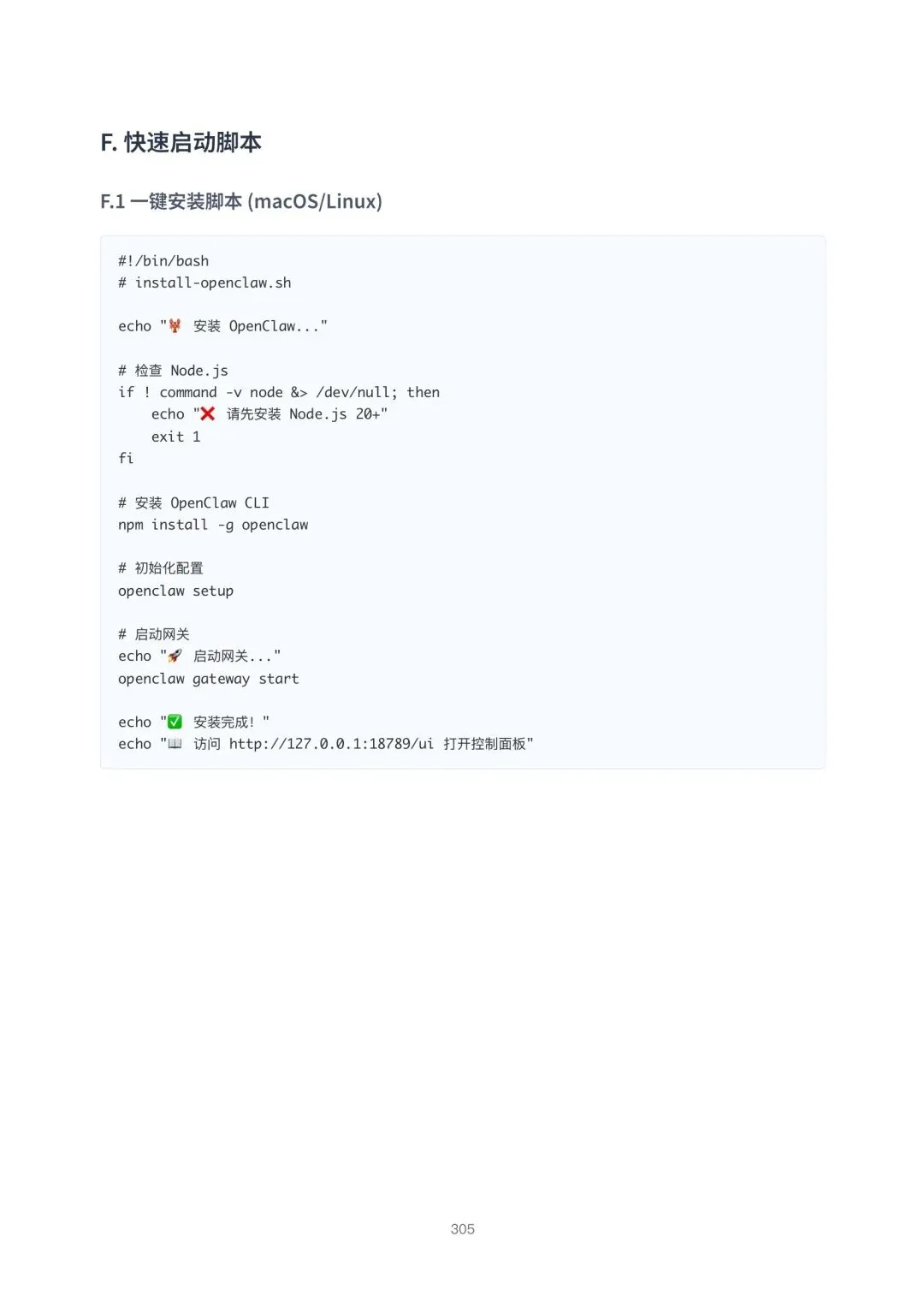
最近看了份关于OpenClaw的行业指南,感觉这玩意儿有点意思。它不是我们通常理解的“聊天机器人”或“智能音箱”,而是个能自己架在本地服务器、NAS或者你电脑上的AI助手网关。你可以把它想象成自家车库里的一个万能工具箱,而ChatGPT、Claude这些大模型是里面的高级电动扳手,OpenClaw负责把扳手接到你家各个水龙头(通讯App)上,并且所有拧过的螺丝(数据)都留在你家车库,不经过别人手。
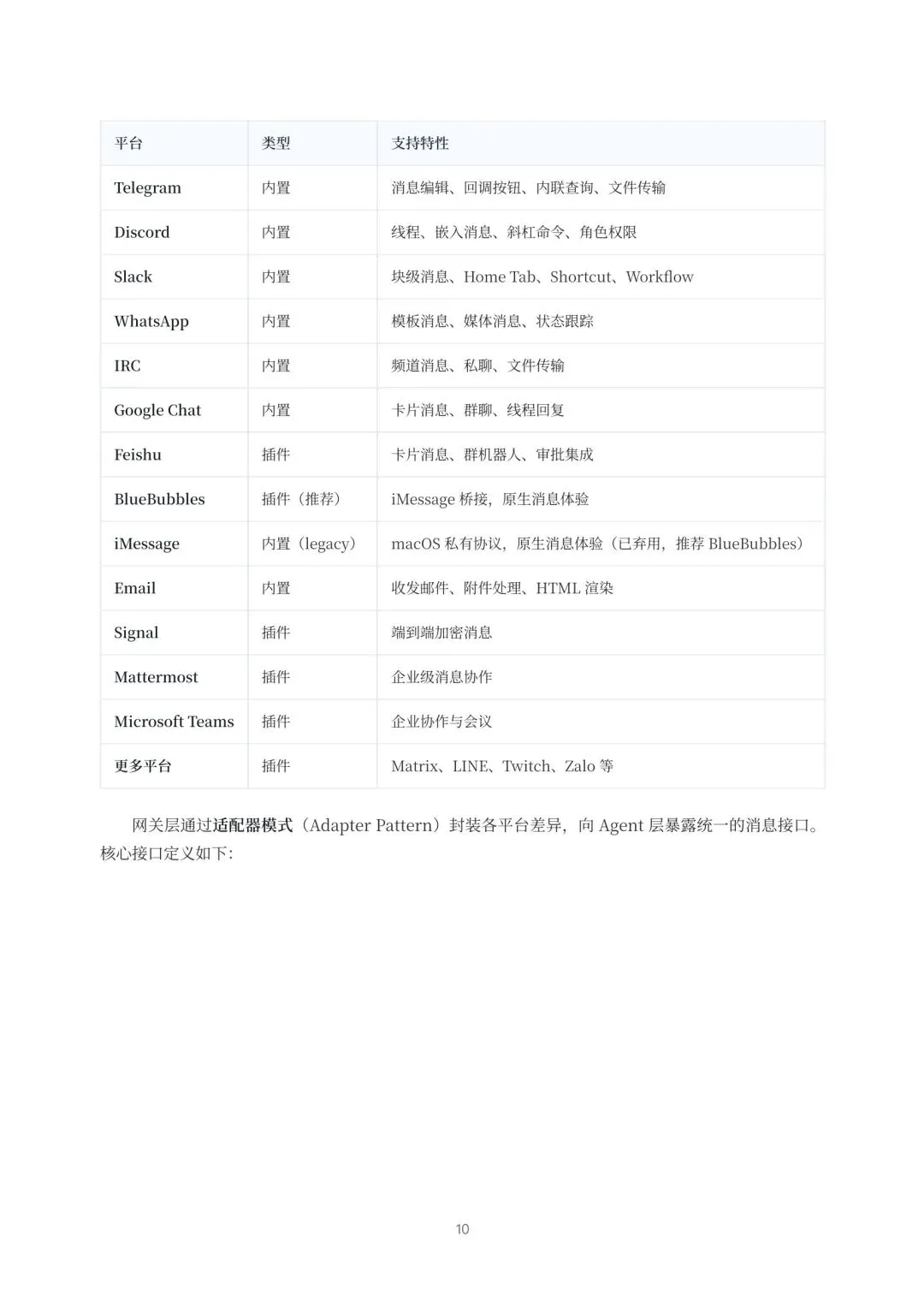
简单来说,OpenClaw做了三件关键事:自托管、多通道、代理原生。自托管意味着你对数据和逻辑有完全控制权,告别“把日记交给云盘保管”的焦虑。多通道是它能无缝桥接Telegram、Discord、Slack、iMessage甚至飞书等一堆你日常在用的通讯工具,让你在哪都能使唤它。而代理原生,是它的内核——它原生支持工具调用、记忆管理和多代理协作,这设计让它从一开始就不是个“陪聊的”,而是个“能干活”的Agent。
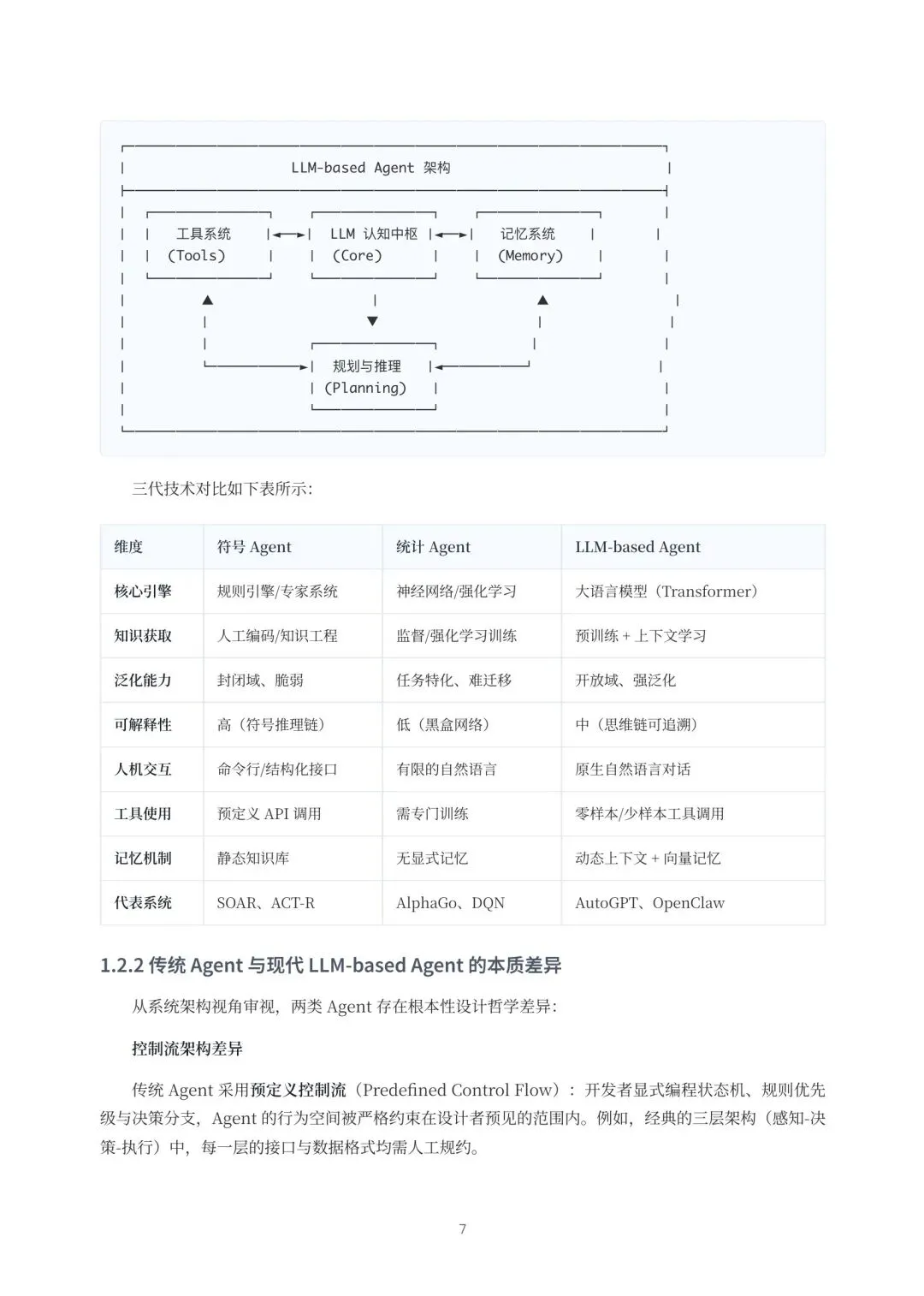
从技术演进看,AI Agent已经走过三代:最早的“符号Agent”依赖专家系统,很聪明但学得慢、不通用;后来的“统计Agent”用强化学习,在打游戏、下棋上很强,但换个任务就抓瞎。现在的“LLM-based Agent”,以GPT、Claude这些大模型为“大脑”,靠“上下文学习”、“思维链”这些涌现能力,才真正有了“举一反三”、用自然语言理解和规划复杂任务的可能。OpenClaw就站在这个第三代的风口上,它把大模型当成了一个动态的、可自主规划的“认知中枢”,而不是简单的问答接口。
为啥这东西能火?我觉得抓住了几个关键点:
1. 时机卡得准。 这两年,大模型能力(特别是Claude 3.5、GPT-4o)和成本下降刚好到了临界点,让这种需要高频、复杂调用的个人Agent应用变得经济可行。同时,用户也腻了“只说不练”的聊天,希望AI能真办事。全球隐私法规越来越严,也给自托管方案加了分。
2. 定位切得准。 它填补了“全托管SaaS服务”和“从零自研”之间的空白。比SaaS(如ChatGPT Plus)更私密可控,比自研又省了巨大的开发成本。对开发者、中小企业、和对数据敏感的人来说,是个刚刚好的选择。
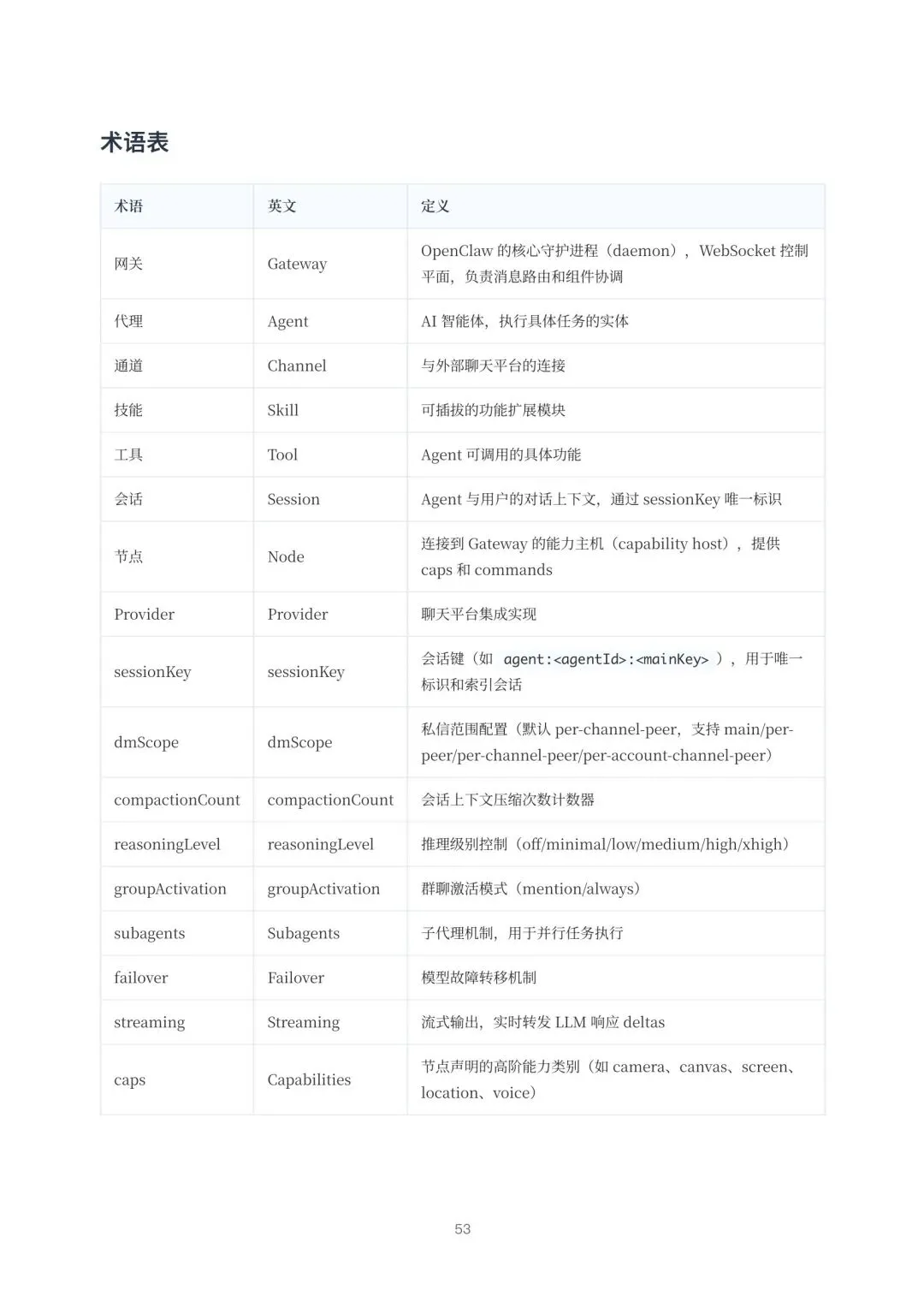
3. 架构有前瞻性。 它采用本地优先的扁平化组件设计,核心是一个叫Gateway的WebSocket控制平面,协调通讯、AI运行时和会话。这种设计让系统高内聚、低耦合,很容易扩展。它还搞了个挺有意思的记忆系统,用向量数据库做语义搜索,能像人一样“联想回忆”,不是机械地翻聊天记录。
4. 生态在成型。 它开源,有社区,还有个叫ClawHub的技能市场。这意味着,用户不仅能自己开发功能,还能一键安装别人做好的技能(比如查天气、控智能家居、管理GitHub),这很容易形成一个“更多用户→更多反馈→更好产品→更多开发者→更多技能”的增长飞轮。
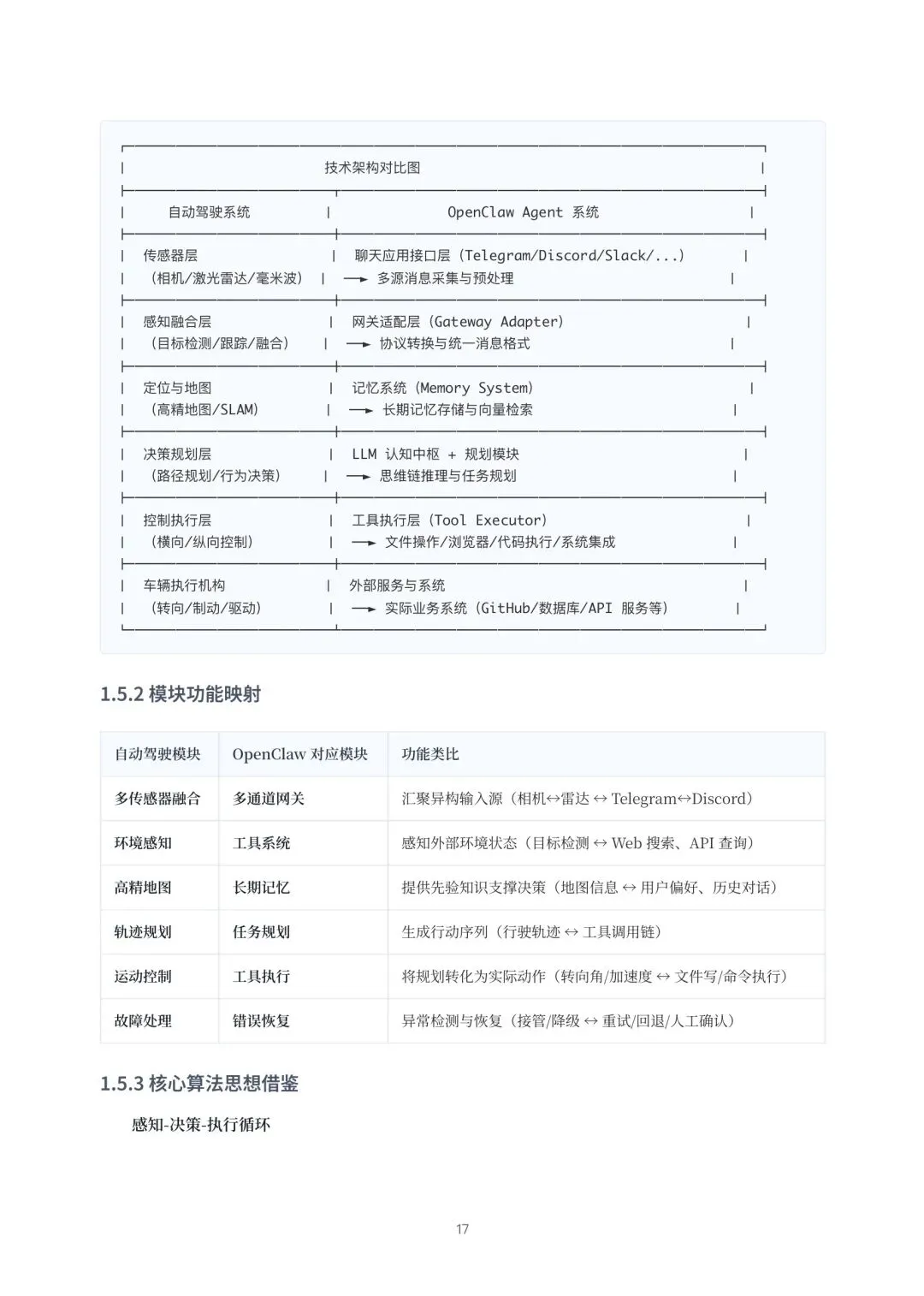
说实话,这方案让人联想到自动驾驶的架构思路,都有“感知(多通道接入)-规划(任务分解)-控制(工具执行)”的闭环。它把原来藏在云端的、黑盒的AI能力,拉到了你手边,变成了一个可编程、可审计、可扩展的数字伙伴。这或许才是AI落地个人场景的下一站:从“智能问答”走向“智能执行”。当AI不仅能告诉你答案,还能帮你写好代码、发邮件、分析日志、甚至操控智能家居时,生产力才能真正被重构。
当然,它的门槛不低,得有点技术底子去部署和维护。但这不正是早期机会所在吗?对开发者、极客和那些“数据主权”意识强烈的团队来说,OpenClaw代表的可能是一种更自主、更深入的AI使用方式。毕竟,谁不想拥有一个完全听命于自己、且无所不能的“贾维斯”呢?




















声明:报告版权归原创作者所有,仅作学习分享不作商业用途。其他仅为整理时间成本