 夜雨聆风
夜雨聆风





当N8N大神Nate说别学n8n了!那说明真的到了放弃工作流了!新王已现:Claude Code + trigger.dev
这篇是我真心一个字,一个字给各位敲出来的!因为不仅仅觉得震撼!更多的是感慨!
首先我是从去年6月开始真正接触AI,第一份学的就是Claude+Cursor+n8n,爬取RSS中的新闻,然而自那以后n8n关注的第一人就是他,Nate Herk, 油管近60万的关注,358篇视频教学,近95%的视频都是在介绍如何使用n8n!
然而就是这么一位Youtuber, 在之前ChatGPT, Gemini,OpenClaw, Perplexity computer 在不断打的水深火热之时,在Claude 发布Cowork之后,从dispatch 到 Schedule, 再到现在本篇文章介绍的Claude+trigger.dev. 算是彻底自己终结了对n8n 工作流的使命。(其中coze!dify!也岌岌可危!)
所以昨天晚上刷到这个视频后,先是完整的看完了一遍他的视频,更是对里面的内容进行了全面的理解,更是对他提出的思路进行反思,立刻上手在自己的电脑上使用Claude Code进行实现!效果简直了!
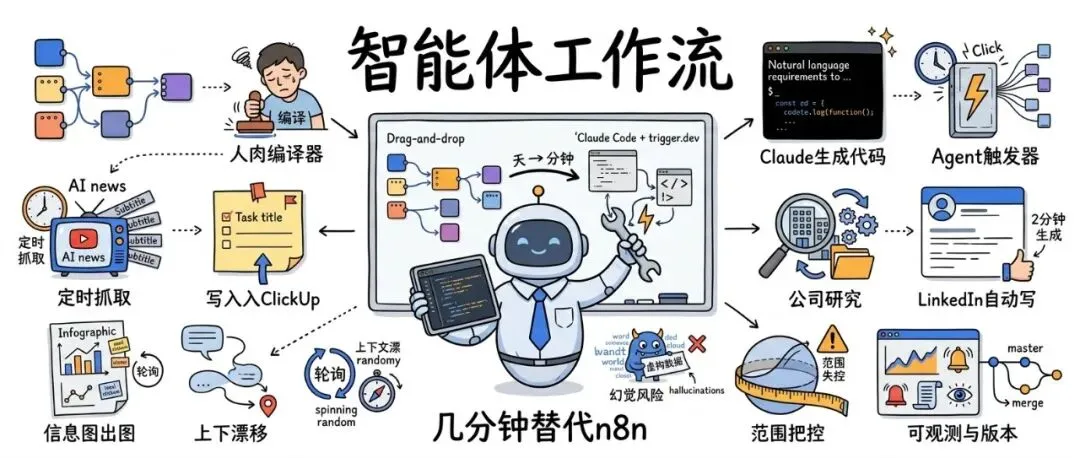
所以我才觉得:为什么n8n已差不多可以凉了。因为Nate几乎没怎么“搭节点”,只是用自然语言讲清楚自己想要什么——数据从哪来、要怎么处理、最后发到哪——几分钟,一个能跑的自动化就出来了。不仅能跑,还能去重、能自修复、能把结果写回 ClickUp。
那一刻我意识到:这不是“新工具取代旧工具”的故事,这是自动化的第三波来了。更狠的是——它不是慢慢来,它是直接冲进你工作方式里,把你过去“按天算”的搭建时间,压缩到“按小时甚至按分钟算”。
01 你以为你在搭工作流,其实你在当“人肉编译器”
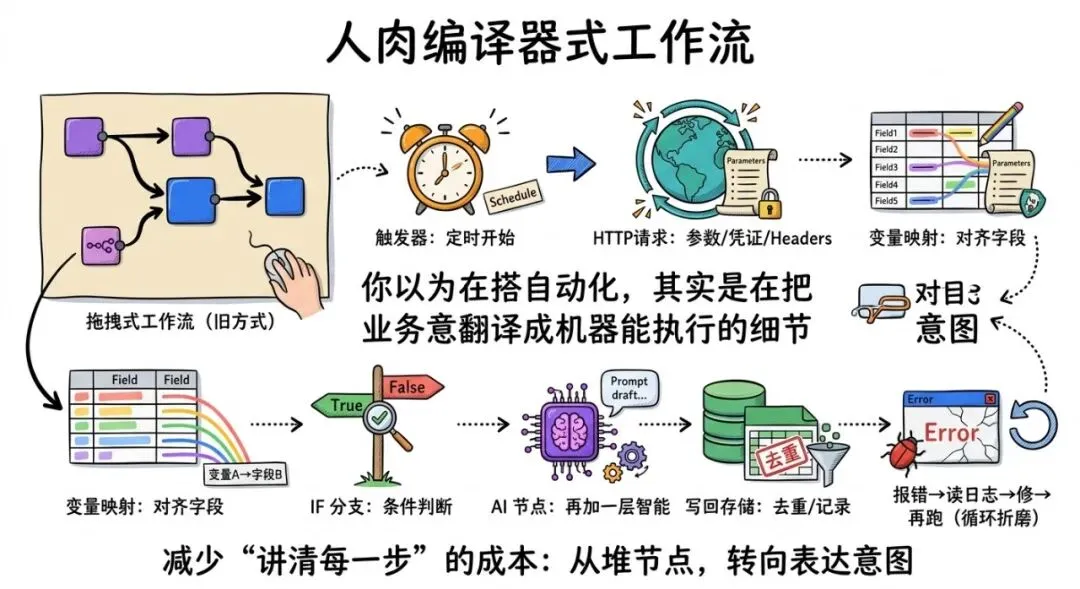
过去几年,我们构建自动化的方式高度统一:
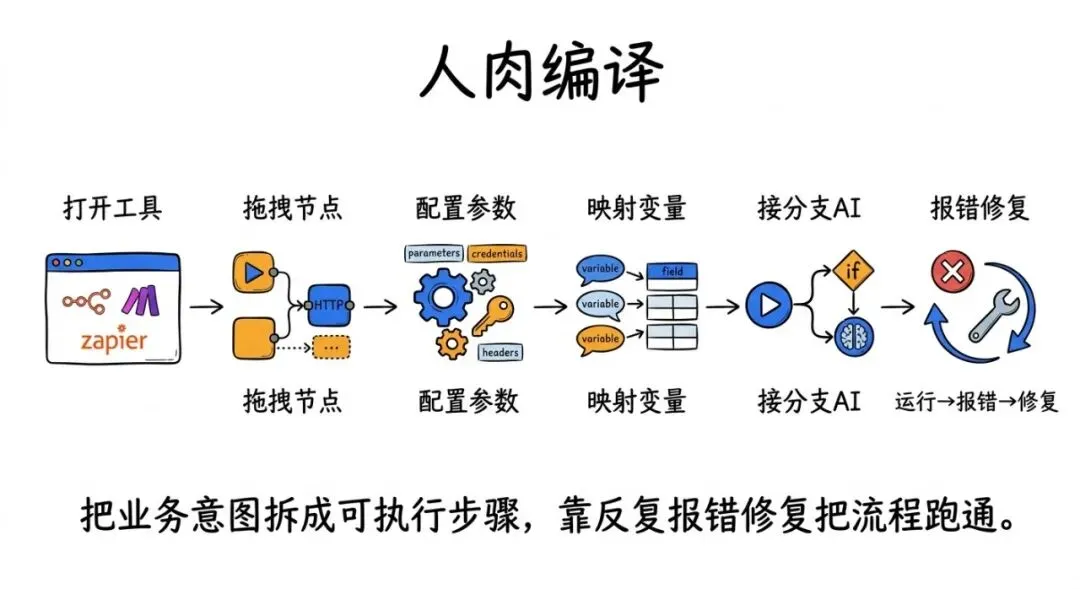
打开 n8n / Make / Zapie 👉 拖一个触发器(Schedule Trigger)👉 拖一个 HTTP 请求 👉 配置参数、凭证、headers 👉 映射变量 👉 加一个 if 分支 👉 再接一个 AI 节点 👉 再写回数据库/表格做去重 👉 跑一遍,报错 👉 读错误信息,修 👉 再跑一遍,再报错 👉 继续修……
如果你使用AI生成json节点,那token的消耗,钱包的消耗!更是惊人–有兴趣可以看我的这篇文章尝试一人公司-到现在花了600刀,我彻底对n8n 工作流祛魅了
你不是在“做自动化”,你是在做一件更隐蔽、更折磨的工作:把你的业务意图翻译成系统能执行的每一个步骤。
它当然是巨大的进步——在这些拖拽工具出现之前,没有开发能力的人几乎做不了任何自动化。但它有一个永远绕不开的成本:你必须亲手把每个步骤讲得足够具体。
视频里有一句话把这个困境说得很直白:
“Drag-and-drop automation is becoming the old way of building.”“拖拽式自动化正在变成旧的构建方式。”— 00:xx(视频时间)
“旧”不是因为它不好,而是因为更快的构建方式出现了。
02 第三波来了:你不再教系统“怎么做”,你只说“我要什么”
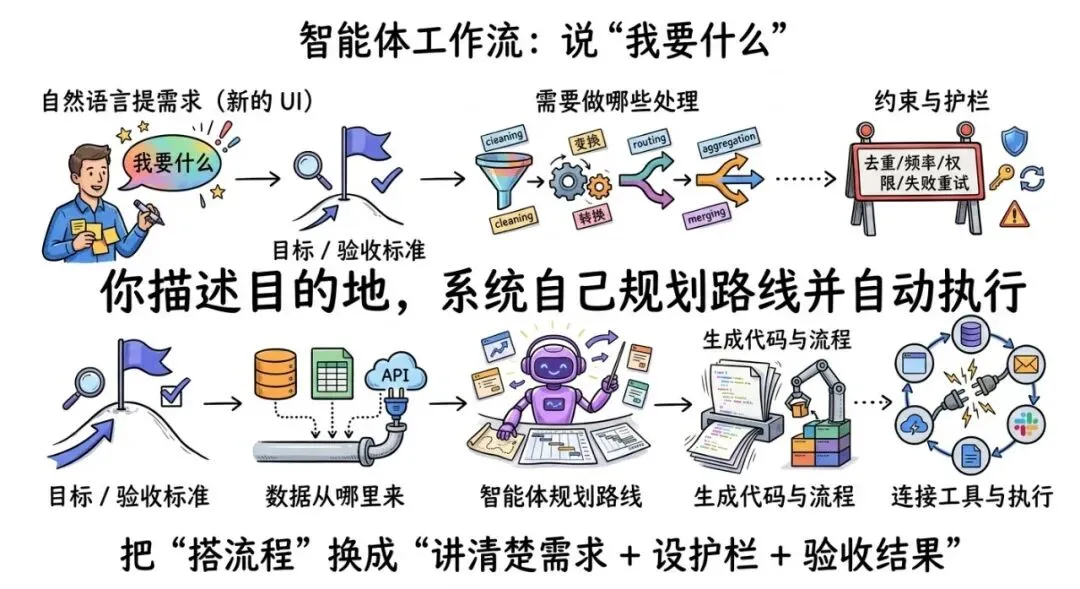
作者把新范式叫做:Agentic workflows(智能体工作流)。
它的关键不在于“自动化能做什么”(第二波已经很强了),而在于:你不必再一格一格搭出来。
你只需要像雇一个优秀开发者那样沟通:
目标是什么?数据从哪里来?需要做哪些处理?最终输出到哪里?约束是什么?(去重、频率、失败重试、权限)
然后智能体替你规划路线、生成代码、连接工具、处理幂等、甚至自己修 bug。
作者用一句话概括了智能体工作流的本质:
“You describe the destination, and the system plans the route.”“你描述目的地,系统自己规划路线。”— 00:xx(视频时间)
这句话听起来像鸡汤,但配合 demo,你会发现它是“生产力暴力提升”的真实描述。
更重要的是:自然语言正在变成新的 UI。你不是在学习一个工具的界面,你是在学习怎么把需求讲清楚、怎么设护栏、怎么验收结果。
03 同一个需求:n8n 需要一天,Claude Code + trigger.dev 可能只要几分钟
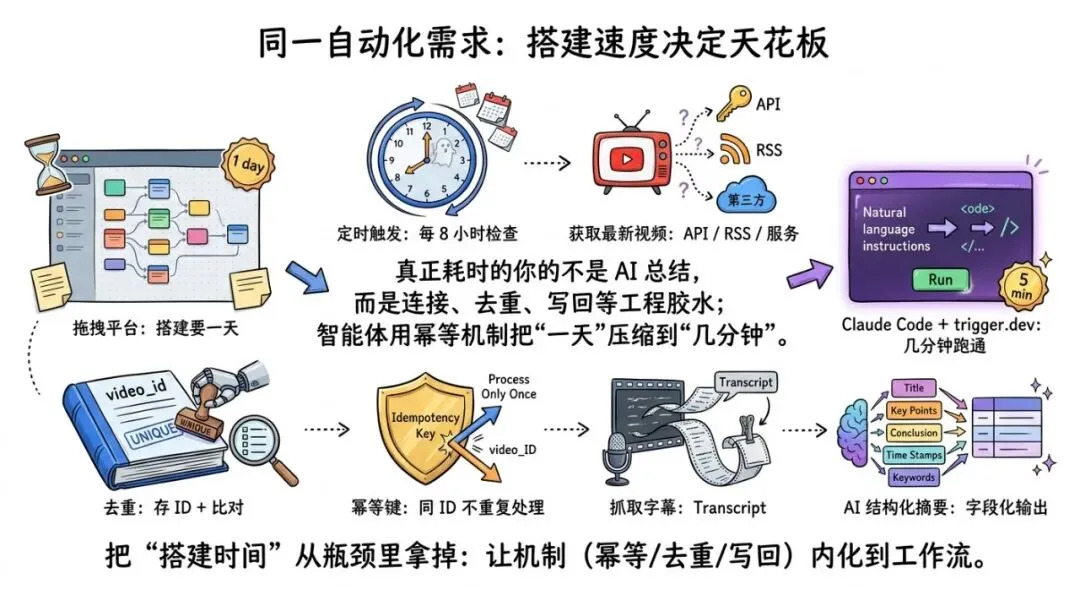
视频里第一个 demo 非常典型,几乎就是所有内容团队/信息团队都会想做的事情:
需求:每 8 小时检查一次某 AI 新闻 YouTube 频道。如果有新视频,就抓取内容做结构化摘要,然后发到 ClickUp;如果没有新视频,就什么都不做。
听起来简单,落到拖拽平台上,你会立刻撞上“真实世界的复杂度”:
定时触发好办(Schedule)怎么获取频道最新视频?用 YouTube API?RSS?第三方服务?怎么判断“新视频”?需要去重:
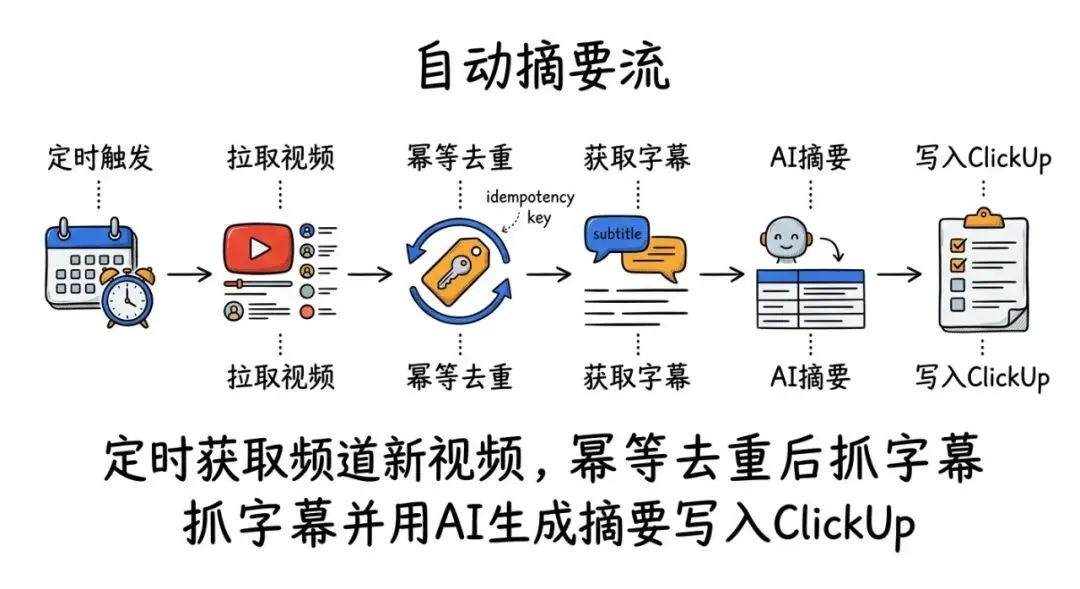
你得存 video ID你得有一个数据库/表格你得在每次运行前读取并比对如果是新视频:抓 transcript(字幕)prompt AI 输出结构化摘要写回 ClickUp写回 video ID 防止重复
你会发现:真正费时间的不是“AI 总结”,而是工程胶水:连接、映射、去重、写回、错误处理。
然后作者切换到 Claude Code + trigger.dev 的方式:他几乎只用自然语言描述了一遍需求,系统就把初版搭出来并跑通了。
最让我震惊的不是“跑通”,而是去重这件事:在拖拽工具里你必须显式构建数据库和写回;而在智能体工作流里,它用幂等键(idempotency key)思路,直接把“同一个 video ID 不处理第二次”内化成机制。
这就是第三波的核心变化:
“The ceiling wasn’t what automation could do — it was how long it took to build.”“过去自动化的天花板不是系统能做什么,而是你搭建它要花多久。”— 00:xx(视频时间)
现在天花板被掀开了,因为“搭建”本身被压缩了。
04 从“定时执行”到“任务触发”:工作流开始像一个会干活的同事
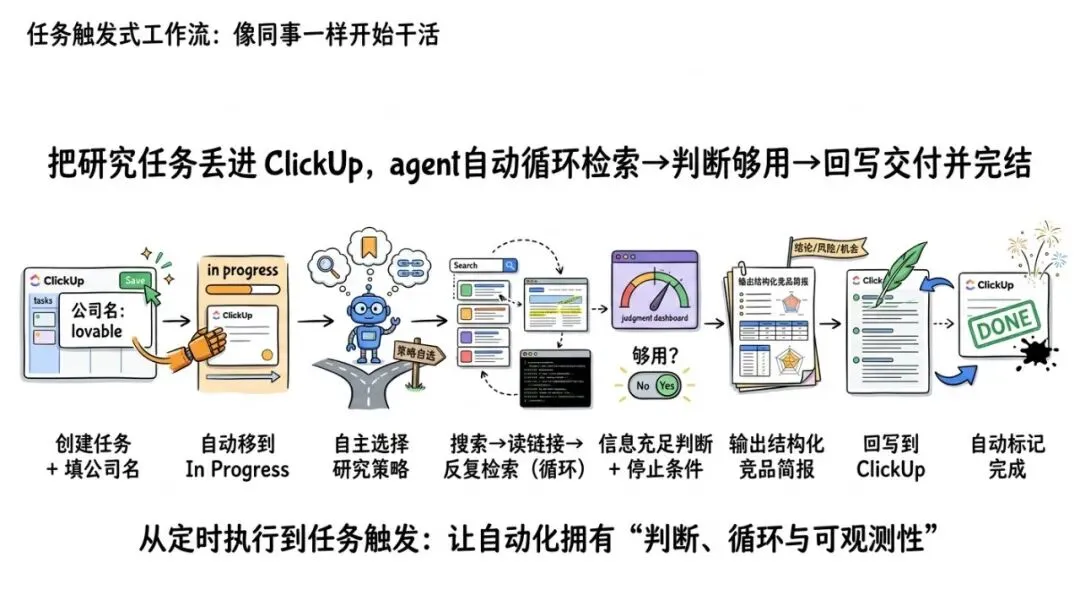
第二个 demo 更像“组织级别的效率升级”。
场景是这样的:
你在 ClickUp 新建一个任务,填上公司名(比如 lovable)。保存后,智能体自动醒来:
把任务移到 in progress(告诉你它在干活)自己决定研究策略(搜索、读链接、反复检索)判断信息“够用了”才停输出结构化竞品简报回写到 ClickUp,并把任务标记为完成
这不再是传统意义的“确定性流程”(A→B→C),而是一个带判断、带循环、带停止条件的“研究型 agent”。
作者强调:trigger.dev 并不是“黑盒”。它也有可视化,你能看到每一次 run、每一步调用、每一次等待与轮询。也就是说,它既有“代码的弹性”,也有“工作流的可观测性”。
这类自动化一旦跑起来,你会开始用一种全新的方式分配工作:不是“我去做研究”,而是“我把研究任务丢进 ClickUp,然后等结果回来”。
你的 ClickUp 任务列表会变成一种“指令队列”。你每天的工作会越来越像“发号施令 + 验收交付”。
05 更狠的 demo:两分钟生成 LinkedIn 帖子 + 信息图,还能自动轮询等图片出炉
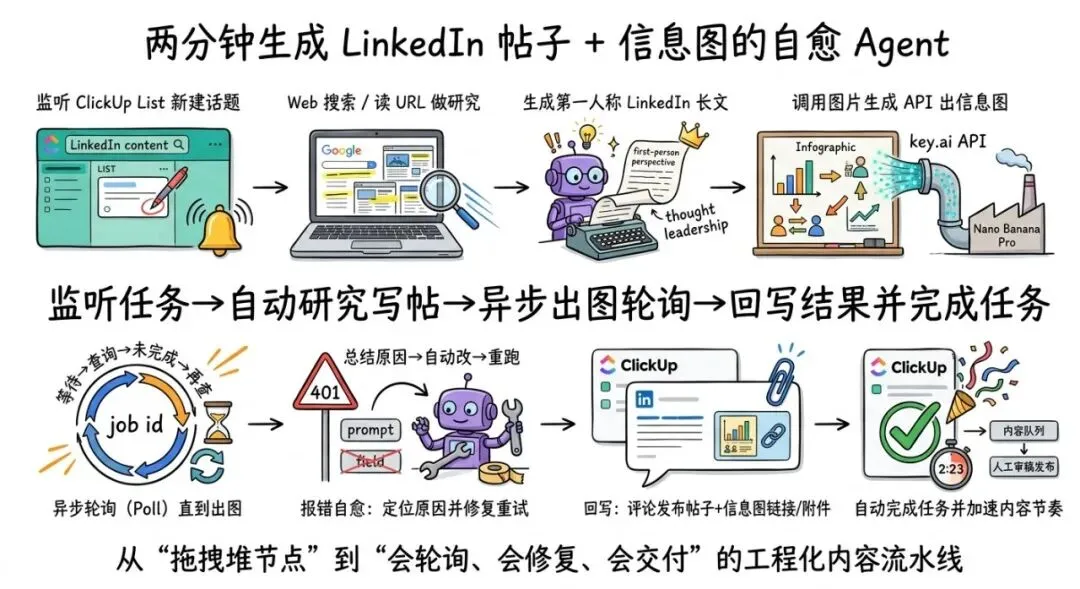
视频后半段,作者现场加需求:再做一个 agent,监听 ClickUp 某个 list(他让 Claude 直接创建 list,命名 LinkedIn content Q),只要你新建任务写一个话题,它就:
做研究(search web / read URL)生成第一人称 thought leadership 风格的 LinkedIn 帖子调用 Nano Banana Pro 之类的图片生成(通过 key.ai API)因为图片生成是异步的,它会自动轮询检查状态,直到完成最终把帖子 + 信息图链接/附件,以评论形式回写到 ClickUp完成后自动把任务标记 complete
这里最“省命”的点是轮询逻辑。做过自动化的人都知道,图片生成这种服务通常要你:
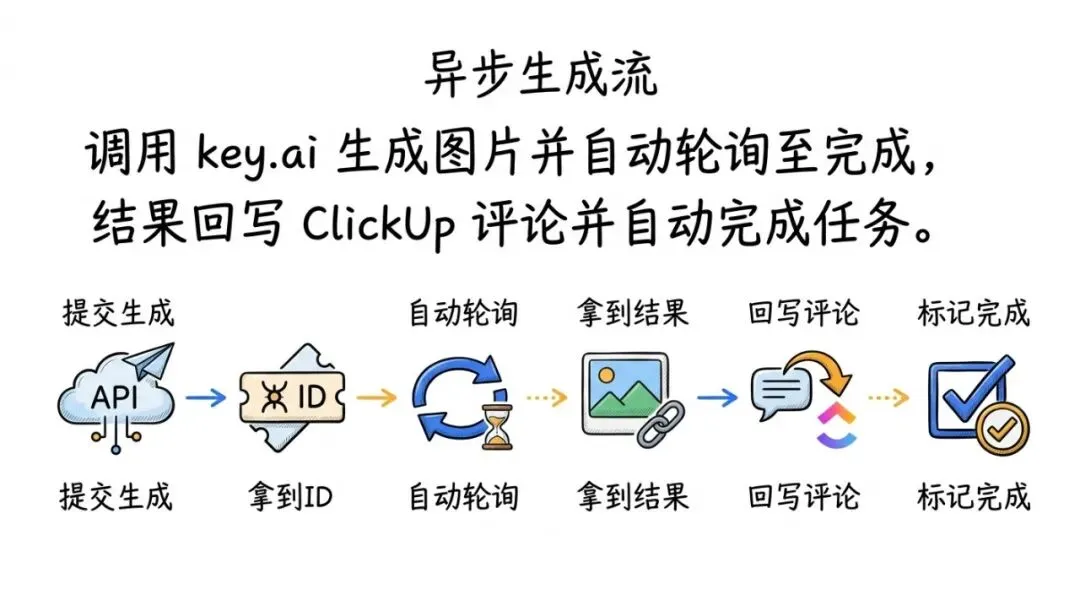
发起生成请求拿到一个 job id等待再查状态未完成继续查完成后再拿结果
在拖拽平台里这意味着一堆节点、一堆循环、一堆等待,一不小心就超时、就重复调用、就乱扣费。
而智能体工作流把这整套“脏活累活”变成默认能力:你说“要生成图片并等它完成”,它自己就把 poll 写出来了。
即使中间报错(ClickUp 401、prompt 字段传错),它也能总结原因并修复,再触发新的测试 run。作者展示的那种“我几乎不用解释它就知道怎么改”,本质上是在告诉你:构建这件事从“手工搭积木”变成“带自愈能力的工程协作”。
最后跑通的那次运行耗时 2 分 23 秒,产出一条可用的 LinkedIn 长文 + 一张信息图。你想象一下:这意味着什么?
意味着内容团队的生产节奏可能会被重写——从“写作排期”变成“选题队列”,从“文案+设计协同”变成“人类定方向 + AI 出初稿 + 人类审稿发布”。
06 为什么它还没彻底普及?因为你会踩 4 个很真实的坑
看到这里你可能已经热血沸腾:那还等什么?立刻 all in!
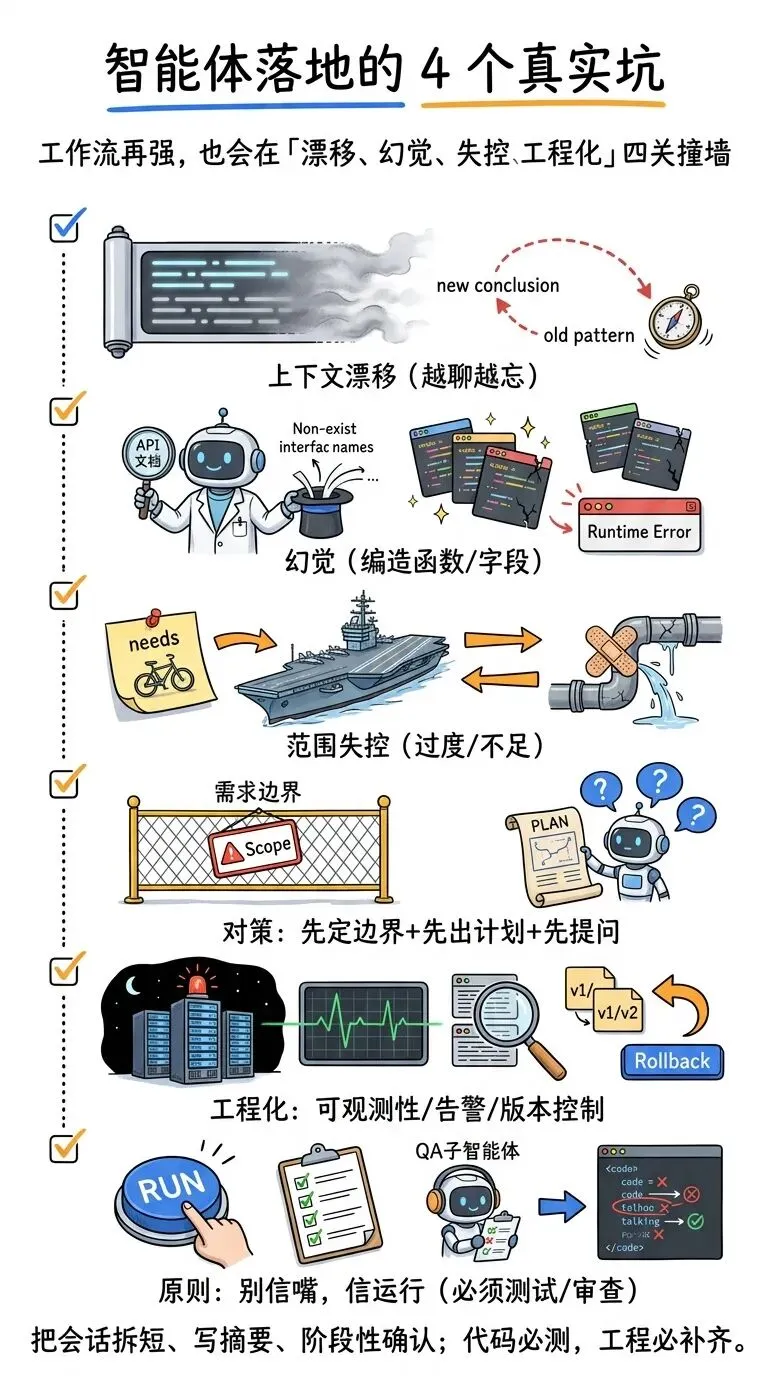
但作者在视频里也很诚实:智能体工作流强归强,落地会撞墙,主要是四类问题。
1)上下文漂移(Context Drift)
你在同一个对话里干得越久,它越可能忘记前面说过的话,甚至“自信地”回退到旧模式。
“The longer you work in a single session, the more it can forget and drift.”“你在同一个会话里工作越久,它越可能遗忘并发生漂移。”— 00:xx(视频时间)
对策很朴素:拆短会话、维护项目摘要、阶段性确认。
2)幻觉(Hallucinations)
它会编造不存在的函数、API endpoint、字段名。代码看起来很漂亮,一跑就崩。
对策也只有一个:别信嘴,信运行。只要有代码,就必须测试;必要时用子智能体做 QA/审查。
3)范围失控(Scoping)
它要么过度工程化(你要自行车它给你造航母),要么低估需求(用创可贴糊住根因)。
对策:一开始就设边界;让它先出计划(plan mode);强制它先问你问题再动手。
4)工程化问题:上线后的可观测性、告警、版本控制
拖拽工具天然有仪表盘;代码世界没有“自动赠送”的安心感。你得考虑:
半夜坏了你怎么知道?日志怎么看?版本怎么回滚?团队怎么协作?
好消息是:这些都是成熟工程问题,可控;坏消息是:你不能假装它们不存在。
07 别误会:n8n 没死,它只是从“主角”变成了“地基”
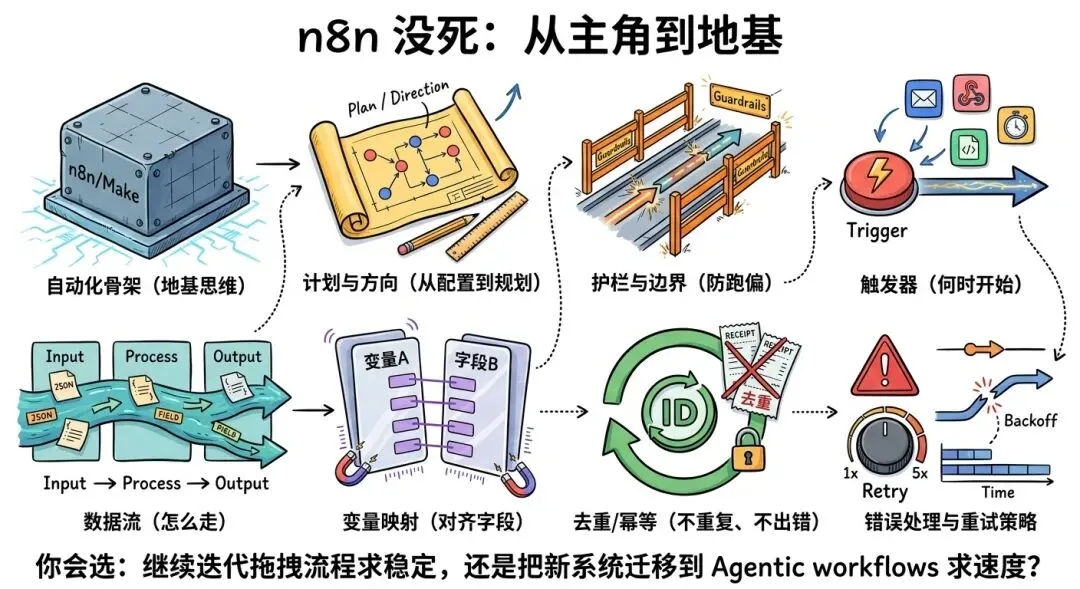
看完视频我最大的感受不是“n8n 要完”,而是:你学过 n8n 的那些东西,反而更值钱了。
因为智能体工作流并不会替你思考业务逻辑,它只是替你把逻辑更快地落成可运行的系统。你仍然需要知道:
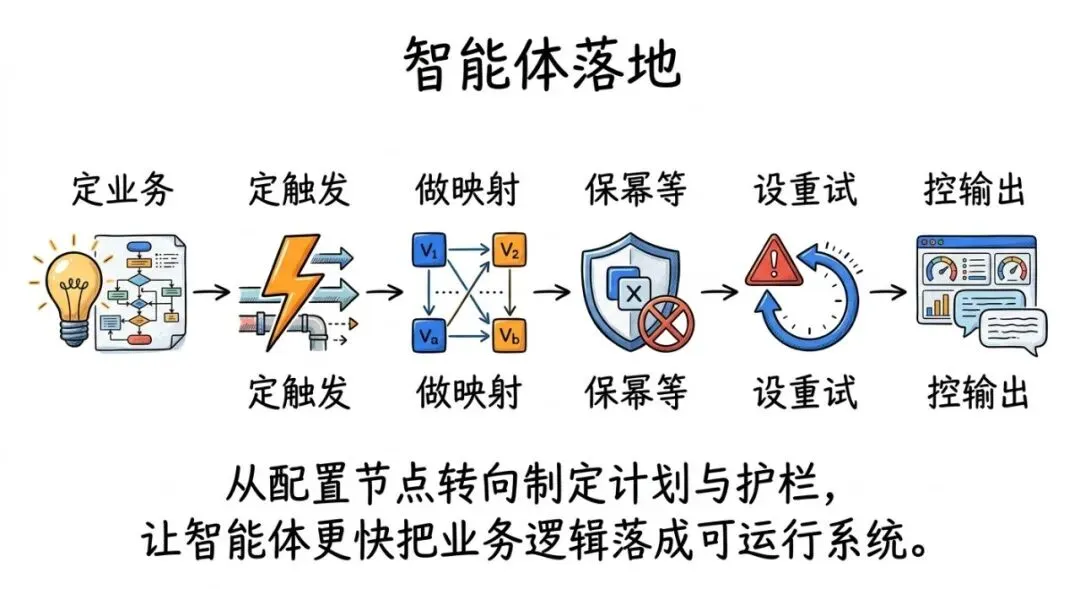
触发器是什么数据流怎么走变量映射意味着什么去重/幂等为什么重要错误处理与重试策略怎么定可观测性要看哪些指标prompt 怎么写才能稳定产出
作者在视频里把这种转变说得很到位:
“Your job is shifting from configuring nodes to giving plans, direction, and guardrails.”“你的工作正在从一个个配置节点,变成给出计划、方向和护栏。”— 00:xx(视频时间)
也就是说,未来更像“指挥智能体施工队”,而不是“自己拿着锤子敲钉子”。
而 n8n 的价值,会从“让你能做自动化”,升级为“让你理解自动化的骨架”。骨架懂的人,才能更快判断智能体哪里跑偏、哪里需要加护栏、哪里需要补工程化。
最后作者也给了一个非常清醒的结论:
“Agentic workflows aren’t here to kill the old tools — they’re the next layer.”“智能体工作流不是来杀死旧工具的;它们只是下一层。”— 00:xx(视频时间)
如果你现在手里已经有一堆 n8n/Make 的工作流,你会怎么选?
继续在拖拽平台里迭代,追求稳定、可视化、低门槛还是开始把“新需求、新系统”迁移到 Claude Code + trigger.dev 这类 Agentic workflows,追求速度与弹性?
评论区告诉我你最想自动化掉的一件事是什么:是“内容摘要”“竞品研究”“销售线索整理”,还是“每天重复的数据搬运”?我可以把它拆成一个适合智能体工作流的需求模板给你。
视频来源:https://www.youtube.com/watch?v=ZeJXI2MAhj0
我建了个 AI 交流群,如果你也对 AI 感兴趣,想一起讨论怎么用好各种 AI 工具、怎么搭建自己的 Agent 体系,欢迎加入。这里没有割韭菜,只有一群正在实践的🐮🐎,或者已经开始搞一人创业的小伙伴,我们一起互相分享方法。

⭕️ 请叫我“一点儿” 每天进步一点点❗️如果你也不想只听概念,而是要一步一步把AI玩儿起来,搞副业,或者真正用起来!这个地方,就是我们一起并肩作战的实验场!(但拒绝垃圾!拒绝卖课!)
— ✨ INTJ | 中年失业 🙅
— 互联网大厂离职 ☹️
— 失业不等于失败|AI把自己产品化