 夜雨聆风
夜雨聆风





源码深度解析Lightpanda:用Zig重构浏览器,为AIAgent打造极速基建
源码深度解析 Lightpanda:用 Zig 重构浏览器,为 AI Agent 打造极速基建
💡 核心导读:在过去的十几年里,浏览器的进化方向始终是“如何让人类看得更舒服”。为了实现平滑的滚动、绚丽的 CSS 动画和复杂的字体排版,Chromium 堆砌了超过 3500 万行代码。然而,当使用者从“人类”变成了“AI 智能体”时,这套庞大的视觉渲染管线就成了沉重的历史包袱。Lightpanda 的出现,代表了一种强烈的工程实用主义:机器不需要看屏幕,机器只需要 DOM 树和 JSON。本文将直击 Lightpanda 源码,拆解它如何通过 Zig 语言对底层内存的极限掌控(ArenaAllocator 的 O(1) 回收),结合编译期反射与 V8 的无缝绑定,再通过 CDP 协议巧妙地“欺骗”现有的 Playwright 生态,成功在性能与兼容性之间找到平衡。
浏览器引擎是一个庞大的状态机,需要处理高并发的网络请求并解析嵌套的 HTML 树状结构。在这个量级的项目中,语言选型至关重要。让我们通过一个简单的对比表格,来看看为什么 Zig 成为了破局者:
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
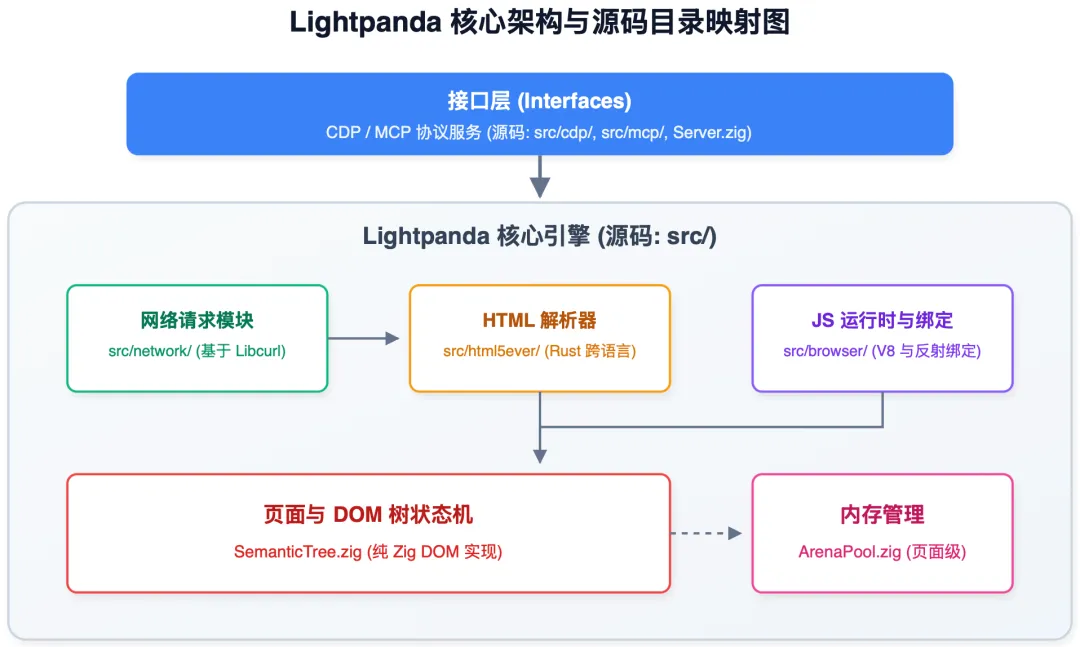
深入源码:Lightpanda 核心目录树剖析
与 Chromium 动辄 3500 万行的庞大代码库相比,Lightpanda 的源码结构显得异常克制与清晰。它没有为了渲染图形而设计的复杂分层,一切都围绕着网络请求、HTML 解析、DOM 状态机和 JS 执行展开。以下是核心模块在源码中的真实映射关系:
lightpanda/browser/
├── src/
│ ├── browser/// 浏览器核心(Page 管理、V8 JS 引擎生命周期与绑定)
│ ├── cdp/// Chrome DevTools Protocol 协议解析与指令路由
│ ├── data/// 浏览器内置数据结构与缓存
│ ├── html5ever/// 跨语言集成的 HTML 解析器(基于 Rust)
│ ├── mcp/// Model Context Protocol 服务端实现(AI 接口)
│ ├── network/// 底层网络请求模块(基于 libcurl 封装)
│ ├── sys/// 操作系统级别的系统调用抽象层
│ ├── telemetry/// 遥测与日志监控模块
│ ├── App.zig// 浏览器全局应用生命周期管理
│ ├── ArenaPool.zig// 页面级内存池,实现 O(1) 瞬间回收的核心
│ ├── Config.zig// 全局配置管理
│ ├── Notification.zig// 跨线程/协程的通知机制
│ ├── SemanticTree.zig// 纯 Zig 实现的轻量级 DOM 树数据结构
│ ├── Server.zig// CDP WebSocket 与 MCP Stdio 服务入口
│ └── Sighandler.zig// 优雅退出与信号处理
1. 规避 Rust 借用检查器处理 DOM 树的复杂性
在许多重构项目中,Rust 是首选。但浏览器 DOM 树是一个高度耦合的图结构(Graph),节点之间充满父子、兄弟节点的双向引用。如果在 Rust 中处理这种网状引用,通常需要大量使用 Rc<RefCell<T>> 或者 Unsafe 指针块。这不仅增加了运行时的开销,也让代码逻辑变得难以维护。Zig 作为一门类似 C 的底层语言,没有隐藏控制流和强制的借用检查,允许开发者直接、透明地管理这片复杂的内存网。
2. 源码拆解:用“定向爆破”替代“逐户排查”的内存回收
传统的浏览器依赖垃圾回收(GC)机制。我们可以打个比方:传统的 GC 就像是物业排查拆迁,需要定期遍历整栋大楼(DOM 树),检查哪个房间(节点)已经没人住了,然后再逐个清理。这个过程耗时较长,且容易引发主线程卡顿(Stop-The-World)。
👇 内存回收机制类比
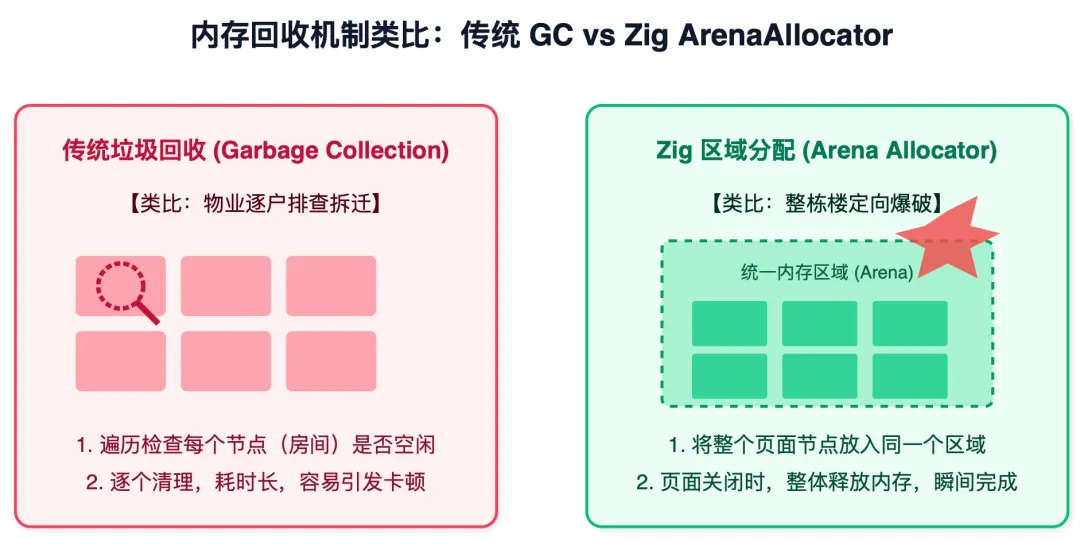
Lightpanda 则利用了 Zig 的 区域分配器 (ArenaAllocator)。每打开一个新网页(Page),系统就为其划分一块专属的连续内存区域。这就好比是整栋楼的定向爆破:当网页关闭时,不需要去遍历销毁成千上万个 <div> 节点,只需一行代码,直接将这整块内存区域一次性释放,时间复杂度为 O(1)。
// Lightpanda 源码简化逻辑:利用 ArenaAllocator 实现 O(1) 页面内存回收
conststd = @import(“std”);
constPage = struct {
arena: std.heap.ArenaAllocator,
allocator: std.mem.Allocator,
dom_root: *Node,
// 初始化网页时,分配专属的 Arena 内存区域
pub fninit(child_allocator: std.mem.Allocator) !Page {
var arena = std.heap.ArenaAllocator.init(child_allocator);
return Page{
.arena = arena,
.allocator = arena.allocator(),
.dom_root = undefined,
};
}
// 网页关闭时,直接销毁整个 Arena 区域,无 GC 遍历开销
pub fndeinit(self: *Page) void {
self.arena.deinit();
}
};
3. 编译期绑定的 V8 引擎集成 (zig-js-runtime)
为了执行网页中的 JavaScript,Lightpanda 必须集成庞大的 V8 引擎。传统的跨语言调用(如 Rust 调用 C++)通常需要编写大量繁琐的 FFI(外部函数接口)绑定层,这不仅容易出错,还会在运行时产生性能损耗。
由于 Zig 编译器原生兼容 C/C++(自带 Clang),团队开发了 zig-js-runtime 库。它利用 Zig 强大的编译期反射(Comptime Reflection)功能,在代码编译阶段,自动将 Zig 的 Struct 结构体解析,并直接生成对应的 V8 FunctionTemplate 对象。这意味着在运行时,JS 调用 DOM API 就如同直接调用底层 C++ 代码一样,没有任何中间层的性能衰减。
// 源码分析:在编译期绑定 JS 运行时的 DOM API
constjsruntime = @import(“jsruntime”);
constHTMLElement = struct {
tag_name: []u8,
// 这个方法将被映射为 JS 中的 node.getAttribute()
pub fn_getAttribute(self: HTMLElement, name: []u8) []u8 {
return self.attributes.get(name) orelse“”;
}
};
// 编译期反射:直接生成 V8 的 FunctionTemplate 绑定代码
pub const Types = jsruntime.reflect(.{HTMLElement});
作为一个新的引擎,要求开发者重写现有的自动化脚本是不现实的。因此,Lightpanda 的策略是:在接口层 100% 模拟 Chrome 的行为。
1. 通过 CDP 协议兼容 Playwright 生态
Lightpanda 原生内置了一个 WebSocket 服务器来支持 CDP (Chrome DevTools Protocol)。当现有的自动化框架(如 Playwright 或 Puppeteer)发送控制指令时,Lightpanda 能够解析并响应这些标准的 JSON-RPC 消息。对于上层应用来说,迁移过程只需更改一行连接代码。
# Python Playwright 接入示例
import asyncio
from playwright.async_api import async_playwright
async defmain():
async with async_playwright() as p:
# 替换掉原有的 p.chromium.launch(),直接连接 Lightpanda 的 CDP 端口
browser = await p.chromium.connect_over_cdp(“ws://127.0.0.1:9222”)
page = await browser.new_page()
await page.goto(“https://www.zhihu.com/explore”)
# 页面内的 JS 逻辑依然由集成的 V8 引擎执行
title = await page.evaluate(“() => document.title”)
print(f”Title: {title}”)
asyncio.run(main())
2. 作为本地 MCP Server 为大模型提供网页解析
在 AI 场景下,大型语言模型通常需要联网获取最新的网页信息。Lightpanda 在近期的更新中集成了 MCP (Model Context Protocol) 支持。开发者可以通过运行 lightpanda mcp 将其作为一个标准输入/输出的本地工具接入到 Claude Desktop 或 Cursor 等工具中。当大模型需要解析动态网页时,可以在后台快速启动一个资源占用极低的实例,执行渲染后将提取到的文本(Markdown 格式)返回给模型,避免了频繁调用本地完整浏览器造成的卡顿。
在实际工程中,技术方案的选型最终都会落在成本与效率的对比上。在并发处理 100 个本地动态页面的压测场景下,Lightpanda 展现了明显的资源优势。
👇 对比
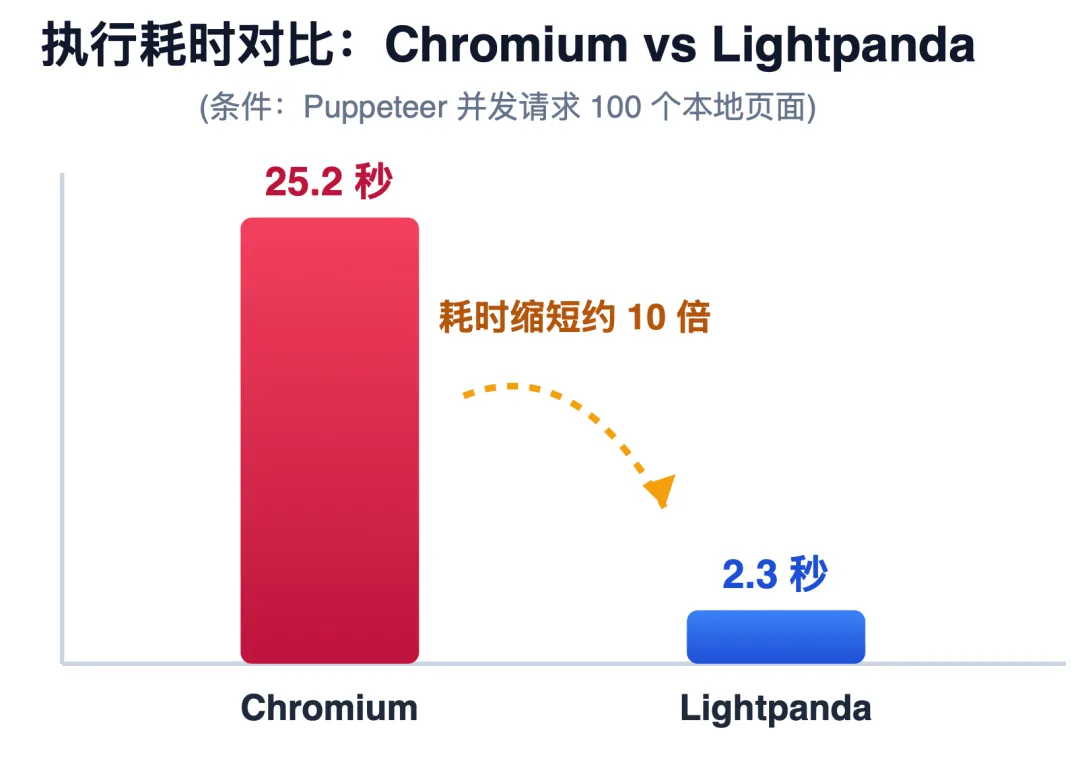
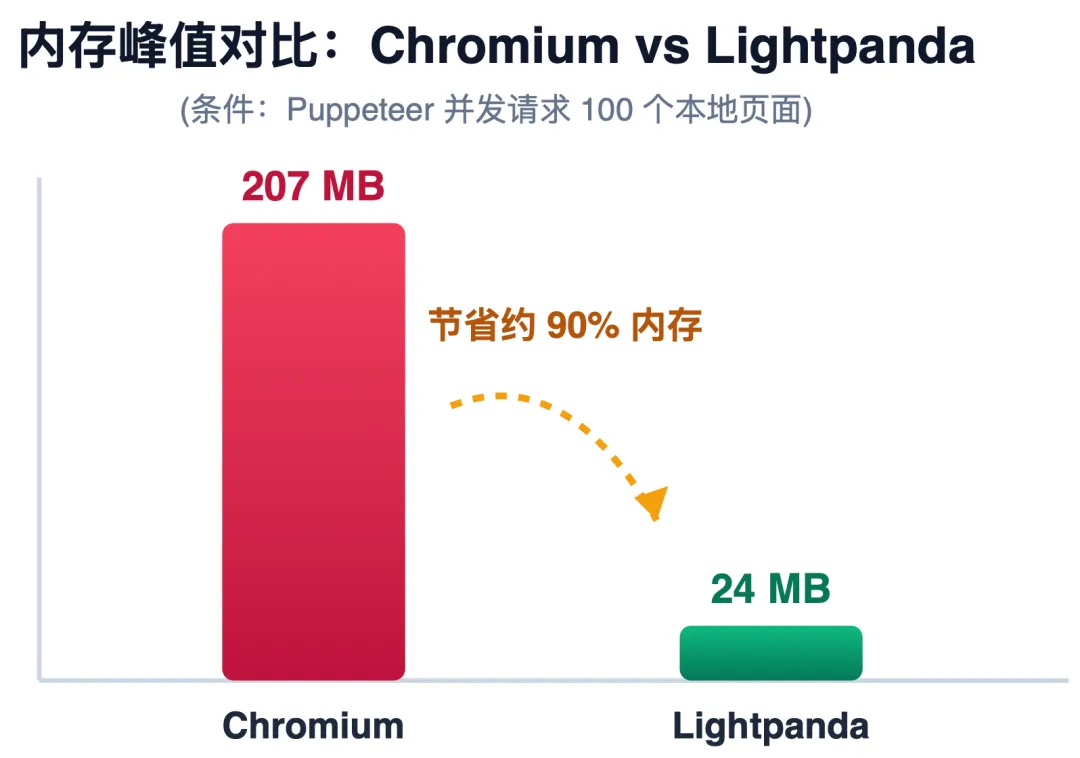
Lightpanda 极低的资源占用不仅解决了成本问题,更催生了全新的开发范式。下面我们将通过两个具体的代码案例,展示如何将其无缝融入到日常的 Agent 开发和传统爬虫项目升级中。
场景一:结合 AI Agent 开发专属 Skill(技能)
在开发大模型智能体(Agent)时,我们经常需要为模型赋予“联网搜索”和“网页交互”的技能(Skill/Tool)。如果使用传统的 Chromium,频繁的启动会导致 Agent 响应极慢,并且占用大量内存。借助 Lightpanda,我们可以编写一个极速的 WebScraperSkill,供大模型(如通过 LangChain 或直接调用 OpenAI API)随时调用,从而实现毫秒级的动态网页内容提取。
👇 案例:为 Agent 编写的极速网页提取 Skill (基于 Python)
# 为 AI Agent 提供的极速动态网页抓取技能
import asyncio
from playwright.async_api import async_playwright
classWebScraperSkill:
def__init__(self, cdp_url=“ws://127.0.0.1:9222”):
self.cdp_url = cdp_url
async defextract_main_content(self, url: str) -> str:
“””大模型调用此函数,传入 URL,获取网页去噪后文本”””
async with async_playwright() as p:
# 连接常驻实例
browser = await p.chromium.connect_over_cdp(self.cdp_url)
page = await browser.new_page()
# 访问动态渲染页面
await page.goto(url, wait_until=“domcontentloaded”)
# 注入 JS 清理文本
content = await page.evaluate(“””() => { document.querySelectorAll(‘script, style’).forEach(el => el.remove()); return document.body.innerText.replace(/\s+/g, ‘ ‘).trim(); }”””)
await page.close()
return content
# 使用示例:
# await WebScraperSkill().extract_main_content(“https://example.com”)
通过这种方式,Agent 的底层依赖不再是一个臃肿的 Chrome 容器,而是一个内存常年保持在 20MB 左右的极轻量级进程,极大提升了 Agent 并发处理任务的能力。
场景二:传统爬虫项目的高效升级(动态数据抓取)
许多传统的爬虫项目依然在使用 requests 配合 BeautifulSoup。但随着现代 Web 框架(如 React/Vue)的普及,越来越多的核心数据被隐藏在复杂的 AJAX 请求和前端加密逻辑中。静态解析失效,逼迫开发者不得不转向 Selenium 或 Puppeteer,但这通常会导致服务器成本直接翻倍甚至几倍。
由于 Lightpanda 原生支持 CDP,我们可以在不改变原有 Puppeteer/Playwright 爬虫代码逻辑的前提下,直接实现底层引擎的替换,将运行成本拉回到静态爬虫的水平。
👇 案例:将 Puppeteer 爬虫平滑迁移至 Lightpanda (Node.js)
const puppeteer = require(‘puppeteer’);
(async () => {
// 改造后:通过 websocket 连接常驻 Lightpanda(耗时 < 10ms)
const browser = await puppeteer.connect({ browserWSEndpoint: ‘ws://127.0.0.1:9222’ });
const page = await browser.newPage();
// 拦截无用请求,压榨性能
await page.setRequestInterception(true);
page.on(‘request’, (req) => {
if ([‘image’, ‘stylesheet’, ‘font’].includes(req.resourceType())) {
req.abort();
} else {
req.continue();
}
});
await page.goto(‘https://finance.sina.com.cn/’);
// 提取动态表格数据
const data = await page.$$eval(‘table tbody tr’, rows => rows.map(row => row.innerText));
console.log(data);
await page.close();
browser.disconnect();
})();
通过以上改造,原本需要在阿里云上租赁 16 核 32G 机器才能勉强支撑的 50 并发爬虫集群,现在完全可以迁移到一台普通的 4 核 8G 轻量应用服务器上运行,而且由于 Lightpanda 剔除了渲染管线,页面解析速度反而提升了数倍。这对于数据密集型企业来说,是极具工程价值的降本增效手段。
场景三:Serverless 环境下的极速冷启动
在阿里云函数计算(FC)或腾讯云云函数(SCF)等 Serverless 环境中部署浏览器一直是个痛点:完整的 Chromium 体积庞大(超过 100MB),且冷启动通常需要几秒钟,极易触发超时。Lightpanda 编译后的单文件体积极小,且没有图形渲染初始化的包袱,使其能在百毫秒内完成冷启动,完美契合 Serverless 弹性伸缩、按量计费的特性,可用于构建高并发的网页解析、PDF 生成(纯文本提取侧)或轻量级健康监控服务。
场景四:大规模无头(Headless)自动化测试
在 CI/CD 流水线中,动辄成百上千个 E2E(端到端)测试用例往往会拉长代码合并的时间。传统方案只能通过增加并发 Runner 节点来缓解,成本高昂。接入 Lightpanda 后,由于其去除了重度渲染开销,在同等硬件下可以轻松将并发测试数提升 5-10 倍。对于主要验证 DOM 状态、路由跳转、网络请求等逻辑正确性的测试用例,Lightpanda 能够提供“降维打击”般的执行速度。
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
没有任何技术是银弹。Lightpanda 通过极致的“做减法”换取了性能,但也因此在某些特定场景下面临挑战。我们需要客观评估其边界,才能更好地将其应用于生产环境。
1. 强视觉依赖场景的短板
由于彻底移除了排版(Layout)和渲染(Paint)引擎,Lightpanda 目前无法处理需要精确计算元素坐标的逻辑。例如,如果你的脚本需要依赖 element.getBoundingClientRect() 来判断一个按钮是否在屏幕可见区域内,或者测试复杂的 CSS 动画和 WebGL 渲染效果,Lightpanda 将无法提供准确的结果。针对这类强视觉关联的操作,传统的 Chromium 仍是不可替代的选择。
2. 高级反爬虫对抗的挑战
现代的高级反爬虫系统(如 Cloudflare Turnstile、DataDome)不仅会检查 HTTP 头部,还会进行浏览器指纹检测(如 Canvas 探针、WebGL 指纹、字体渲染差异)。由于 Lightpanda 是一个精简版的引擎,它目前的指纹特征与真实浏览器存在明显差异。虽然可以通过注入 JS 脚本来进行指纹伪装(Mocking),但在对抗最顶级的反爬策略时,仍可能存在被拦截的风险。
3. 未来演进:按需加载的混合架构
展望未来,Lightpanda 团队正在探索一种“按需渲染”的混合架构。未来的版本可能会引入轻量级的排版计算模块,甚至允许开发者在需要时以插件的形式加载 Canvas 或 WebGL 支持。这意味着,开发者可以根据任务的精细度,动态调整引擎的重量:在纯数据抓取时保持极致轻量,在需要绕过指纹检测或执行视觉测试时,短暂开启相关模块。
结语:AI 时代的基建重构
在 Multi-Agent 协同和自动化工作流走向深水区的今天,算力成本的精细化控制已成为核心竞争力。传统的 Chromium 固然强大,但在纯后端自动化场景中却显得过于沉重。Lightpanda 证明了通过极致的“做减法”,我们完全可以重构底层的 Web 基础设施。对于需要处理海量动态网页交互的开发者和企业来说,这不仅是一个能提升十倍效率的工具,更是一张摆脱昂贵云服务器账单的“逃生船票”。
—— 迎接属于机器专属的 Web 自动化时代