 夜雨聆风
夜雨聆风





山寨APP如何巧妙复刻头部产品做到5w美金/月(适合OPC)
点击蓝字,关注我

前言
最近都在聊 speak ,一款拿了 7000 万融资最近月流水突破了 500 万刀的AI C 端落地的明星产品。它同时也是美国 AI 教育榜单的 TOP2,多邻国教育赛道金腰带有力的挑战者
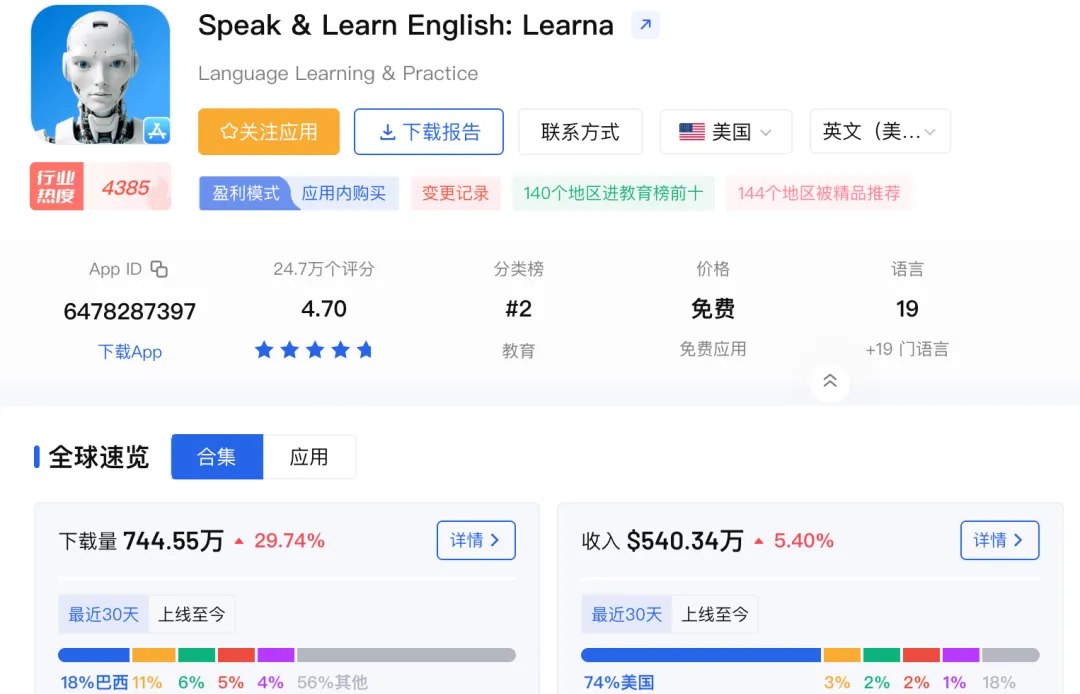
但我今天这篇文章,并不拆解speak,而是通过矩阵开发者 iDeaLabs开发对标 speak 的产品YayTalk举例,告诉你如何正确“蹭”(山寨)头部产品
虽然YayTalk目前的数据还并不起眼,但是他们的手法非常成熟,产品的完成度非常高,值得我们细细学习
元数据:神似形不似
首先可以先看看这两家的 LOGO 和上线图对比:
LOGO 都是机器人且色调完全一致,只是一家是普通的证件照,一家是大头照+名字水印


其次是是上线图,配色和排版一模一样,只有内容 2/3 张调换了下顺序,小小修改了下文案和造型(有一张文案都照抄)
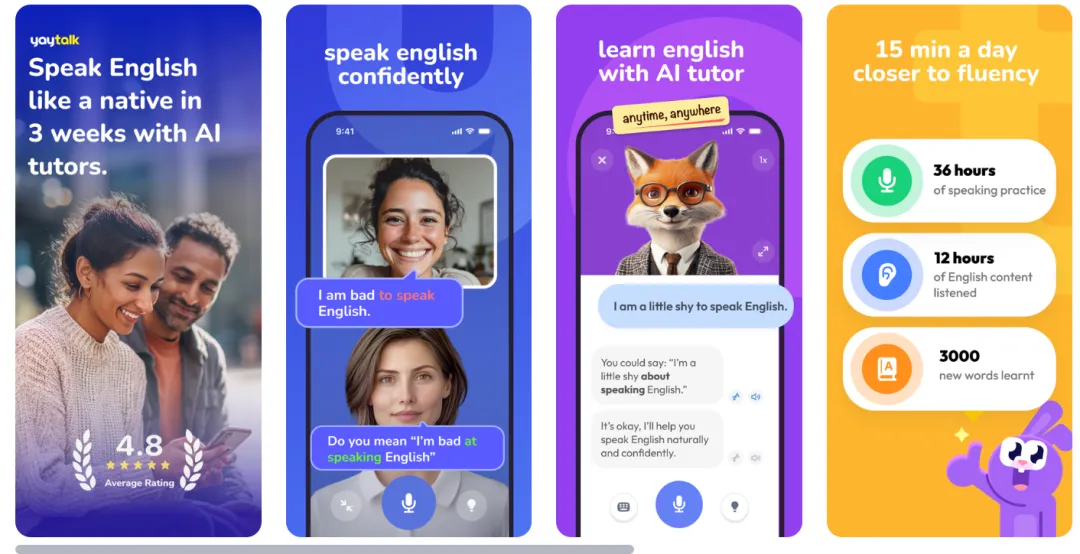
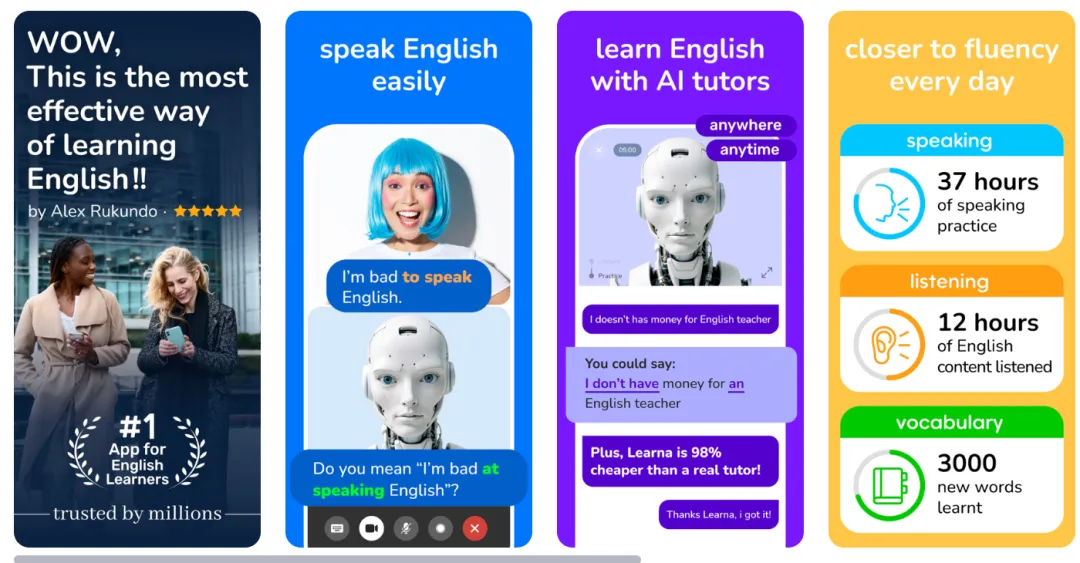
无论是 LOGO 还是上线图,都做到了第一眼看上去很像但是细看越看越不像,可以说老师傅的手法十分恰到好处
为啥要这么做呢?原创难道不是更好么,原因如下:
1. 头部的上线图都是一堆精英通过经过几十次 AB 测试验证出的最优方案,直接照抄相当于免费白嫖了头部的智慧结晶,省去了AB 测试的时间和用户损失成本
2. 高度相似的 LOGO 和上线图,同时也可以让一些不明所以的用户分不清李逵李鬼,截流一波头部的品牌带来的自然量(尤其是你买 ASA 和用户搜一些长尾词的情况下)
冷启动引导订阅:换汤不换药
从引导和订阅页来看,似乎二者的内容好像一下变得截然不同?但是多看几遍,实际上大体结构几乎一模一样,总共只有 6 步
1. 问卷调查获取信息
2. 权限获取融入学习提醒
3. 生成定制计划
4. 展示用户反馈/成果
5. 免费试用仪式感
6. 展示订阅也转化
之所以看起来视觉效果和结构不同:
-
是因为YayTalk的问卷调查是分页呈现的, Speak 则做成和和 AI 机器人进行 chat
-
YayTalk的展示用户反馈/成果单独设置了几个页面,Speak 则将其融入了生成定制计划的动画下方
这里YT做了设计上的差异,我猜原因可能如下:
Speak 的机器人 chat 非常具有特色,直接复用有概率吃举报,拆分成单独的问卷调查页面更加保险,且多个问卷调查可以增加用户沉没成本,提高订阅转化率
头部的引导流程是结合了自身的排名和品牌的,YayTalk需要更强烈的用户反馈和成果的视觉展示来为自己背书,从而提升订阅转化
我体感下来YayTalk的流程相当有一点太长了,没有 Speak 那么优雅从容,但是视觉效果和感觉还是相当不错的,非常值得我们借鉴一二
订阅页的不同我猜原因如下:
-
YayTalk和Beautify 是同一个开发者,相同的价格套餐有助于快速预估回本周期和模型
-
至于为啥比Beautify多了免费试用,一个是因为教育类刚需产品付费率更高,另外就是头部speak对市场拥有定价权
根据我的经验来看,YayTalk 这套年+周免费并不太科学,如果主推是周的话(默认选周还有免费试用),年作为价格锚点比周还划算多少有些不妥,我一般这种情况会直接把年改成 99.99
功能拆解:好在哪里?
在传统的英语学习 App 中,用户面对的是冷冰冰的填空题和死板的录音纠错,本质上是人机交互
而YayTalk和 Speak这类 AI 教育相对常规的教育app 而言,解决的核心痛点是把做题变成交流,把面对题目变成了面对“人”
功能拆解:为什么好?
具体而言,常规的学英语 APP,即使可以通过语音回复,但是他的反馈只会有“正确”或者“错误”
而AI 教育会像真正的老师一样,告诉你你错在哪里的,该如何改正,甚至说的不标准还会鼓励你,没关系,已经很棒了。
无论是声音还是内容,都让用户仿佛感觉自己并不是在用 APP 学英语,而是真的在和一个 “老师”上线上课
甚至线上很多 1-200 块钱一节课的老师也是照着成熟的教案照本宣科,还远不如 AI 来的智能
功能拆解:如何实现?
这种体验是如果通过 AI 来实现的呢?可以说是非常复杂了
和AI 识图/生图这种只需要把图丢给多模态大模型不同,AI 口语教练的技术栈相当复杂,就算全部用商业 API 都要中转个 3-4 次
外加为了确保延迟不至于中断沉浸感,一般还会用到流式服务和长链接,对于缓存管理和服务的稳定的要求也非常夸张,也远不是 AIGC 那种图片往数据桶一丢就完事,然后补个任务 ID 客户端轮询那么简单
功能拆解:技术架构
第一步感知:
语音转文字:把用户发音变成文字
-
主要的痛点: 学习者的发音往往不标准,带有重口音或犹豫
-
主流方案:
OpenAI Whisper: 开源界的标杆,抗噪性强,对口音兼容度极高。Deepgram / AssemblyAI: 商业化首选,极低的延迟,支持实时转录
这个也是 AI 转录/笔记录/备忘录的底层功能
第二步认知:
把转录好的文字丢给 大语言模型:大脑的逻辑与纠错
-
主要的痛点:需要确保人设的稳定,不至于一会是毒舌一会儿欢快,避免答非所问,同时要保持合适的上下文管理,
-
核心技术:提示词工程。
-
主流方案:
设定角色/给纠错范式/边界约束
第三步表达:
再把大模型的回答文本转语音:赋予更自然更具情感的声音
-
主要的痛点:声音不能太生硬,需要足够亲和自然
主流方案:ElevenLabs: 行业天花板,能模拟呼吸声、停顿和语调起伏。
第四步表现:
数字人对口型(和 TTS 同步进行):最后的视觉补完
-
主要的痛点:不能太假了
原理:通过 Live2D 这种基于骨骼动画的技术,或者通过前端 canvas 实时拼接嘴型图片,以此来降低算力压力。(来自 gimini,这个真没接触过)
最终评估
上面这四个层次加在一起
-外加上返回文字和语音的流式服务的短线重连(确保会话不中断)
-多个会话的并发管理(很多 api 限制并发数)
-多API的备份(单一的 API 宕机就完犊子了,一般都会多备几个)
最终才构成了 富有沉浸感的AI 教练英语的全流程
综合评估:无论是 token 成本 (每个 API 都是单独算钱)还是技术实现难度,都并非普通的独立开发者或者微型团队能涉及的,只有有一定 AI 底子的小厂咬咬牙才能碰一碰的品类
最后
因为见证过他做产品,也希望能成为见证他自媒体的见证人,所以我转了。还有没有杰出的小伙伴一起加入九日的开发者大俱乐部啊?那么我们4.25在北京的活动千万别错过:4.25北京 九日主场:AI时代 App与Web的抉择和升级