 夜雨聆风
夜雨聆风





火宝短剧源码深度解析:5 个 AI Agent 如何把小说变成短视频
前言
最近在 GitHub 上看到一个很有意思的开源项目——Huobao Drama,一个基于 AI Agent 的短剧自动化生产平台。它能把一篇小说自动变成短剧视频:改写剧本、提取角色、拆解分镜、生成图片、合成视频,全流程由 5 个 AI Agent 协作完成。
这个项目的架构设计很有参考价值——它不是简单地调 LLM 接口,而是用 Mastra AI Agent 框架 + Tool Use + Skill 注入的方式,让每个 Agent 各司其职。今天我们从源码层面拆解它的核心设计。
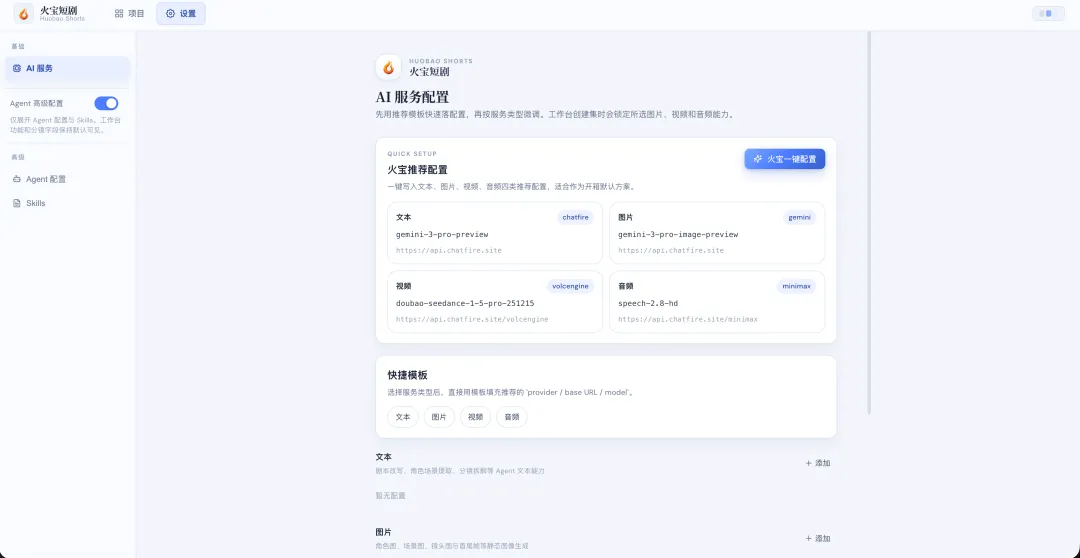
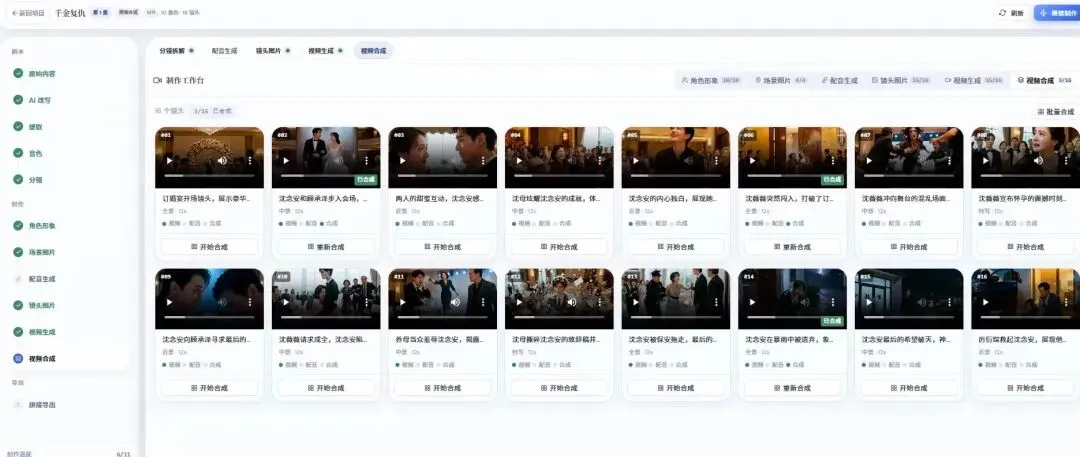
一、整体架构:一条 11 步流水线
先看项目结构:
huobao-drama/├── backend/ — Hono + Drizzle ORM + Mastra AI Agents + better-sqlite3├── frontend/ — Nuxt 3 + Vue 3 + TypeScript (纯 CSS,无 UI 框架)├── skills/ — Agent 技能定义 (SKILL.md)├── configs/ — config.yaml 配置文件└── data/ — SQLite 数据库 + 生成资源文件后端用 Hono(轻量级 Node.js HTTP 框架)+ Drizzle ORM(类型安全的 ORM)+ better-sqlite3,前端用 Nuxt 3 纯 CSS 实现暗色主题 UI。
核心生产流程是一条 11 步流水线:
原始小说 → ① 剧本改写 → ② 角色/场景提取 → ③ 分镜拆解 → ④ 音色分配 → ⑤ 角色/场景图生成 → ⑥ 宫格图生成 → ⑦ 视频生成 → ⑧ TTS 配音 → ⑨ 单镜头合成 → ⑩ 整集拼接 → ⑪ 导出其中 ①②③④ 由 AI Agent 驱动,⑤⑥⑦ 由多厂商 AI 服务驱动,⑧⑨⑩ 由 FFmpeg 完成。
二、Agent 工厂:动态创建 + Skill 注入
2.1 核心入口:createAgent()
整个 Agent 系统的核心是 backend/src/agents/index.ts 的工厂函数:
// backend/src/agents/index.tsimport { Agent } from'@mastra/core/agent'import { createOpenAI } from'@ai-sdk/openai'exportfunctioncreateAgent(type: string, episodeId: number, dramaId: number): Agent | null{const defaults = DEFAULT_PROMPTS[type]if (!defaults) returnnullconst dbConfig = getAgentConfig(type) // 从数据库读取配置const model = getModel(dbConfig) // 构建 AI 模型实例// 关键:基础指令 + Skill 注入const baseInstructions = dbConfig?.systemPrompt?.trim() || defaults.instructionsconst skillInstructions = loadAgentSkills(type)const instructions = skillInstructions ? [baseInstructions, '', skillInstructions].join('\n') : baseInstructions// 根据类型注入不同的工具集let tools: Record<string, any> = {}switch (type) {case'script_rewriter': tools = createScriptTools(episodeId); breakcase'extractor': tools = createExtractTools(episodeId, dramaId); breakcase'storyboard_breaker': tools = createStoryboardTools(episodeId, dramaId); breakcase'voice_assigner': tools = createVoiceTools(episodeId, dramaId); breakcase'grid_prompt_generator': tools = createGridPromptTools(episodeId, dramaId); break }returnnew Agent({ id: type, name, instructions, model, tools })}设计亮点:每次请求都动态创建 Agent,把 episodeId 和 dramaId 注入工具闭包。 这意味着 Agent 的每个工具在执行时天然知道自己在操作哪一集、哪个短剧项目。
2.2 模型层:统一 OpenAI 兼容协议
functiongetModel(dbConfig: any) {const textConfig = getTextConfig()const resolvedBaseURL = getTextProviderBaseUrl(textConfig)const provider = createOpenAI({ baseURL: resolvedBaseURL, apiKey: textConfig.apiKey, } asany)const modelName = dbConfig?.model || textConfig.modelreturn provider.chat(modelName)}所有文本模型统一通过 @ai-sdk/openai 的 createOpenAI 创建,只需换 baseURL 就能接入不同厂商(OpenAI、OpenRouter、火山引擎、阿里等)。这是 Vercel AI SDK 的经典设计——用 OpenAI 兼容协议统一所有 LLM Provider。
2.3 Skill 系统:SKILL.md 热注入
Skill 是这个项目很有意思的设计。每个 Agent 有独立的技能定义文件:
skills/├── script_rewriter/SKILL.md # 剧本改写规范├── extractor/SKILL.md # 角色/场景提取规范├── storyboard_breaker/SKILL.md # 分镜拆解规范├── voice_assigner/SKILL.md # 音色分配规范└── grid_prompt_generator/SKILL.md # 图片提示词规范加载逻辑在 backend/src/agents/skills.ts:
const AGENT_SKILL_MAP: Record<string, string[]> = { script_rewriter: ['script_rewriter'], extractor: ['extractor'], storyboard_breaker: ['storyboard_breaker'],// ...}functionreadSkill(skillId: string): string{const skillPath = path.join(SKILLS_DIR, skillId, 'SKILL.md')if (!fs.existsSync(skillPath)) return''const raw = fs.readFileSync(skillPath, 'utf-8')return [`## Skill: ${skillId}`, stripFrontmatter(raw), // 去掉 YAML 头 ].join('\n')}exportfunctionloadAgentSkills(agentType: string): string{const skillIds = AGENT_SKILL_MAP[agentType] || []const contents = skillIds.map(readSkill).filter(Boolean)if (!contents.length) return''return ['以下是该 Agent 专属的项目技能规范(SKILL.md)。','你必须在不违背当前工具边界的前提下优先遵守这些规范;若与用户明确要求冲突,以用户要求为准。','', contents.join('\n\n'), ].join('\n')}Skill 在运行时从文件系统读取,拼接到 Agent 的 system prompt 中。 这意味着你可以不重启服务,直接修改 SKILL.md 文件就能调整 Agent 行为。这比把 prompt 写死在代码里灵活得多。
三、五大 Agent 详解
Agent 1:script_rewriter(剧本改写)
职责: 把小说原文转成格式化剧本。
工具集:read_episode_script → save_script
工作流程:
-
调用 read_episode_script读取episodes.content(原始小说内容) -
Agent 自行改写为分场景的格式化剧本 -
调用 save_script保存到episodes.scriptContent
输出格式:
## S01 | 内景 · 咖啡厅 | 午后林悦坐在窗边的位置上,指尖无意识地搅动着咖啡。林悦:(苦笑)又是一个人的下午茶。## S02 | 外景 · 街道 | 傍晚陈铭快步走过斑马线,手机不停地震动。每个场景控制在 30-60 秒,这是短剧的黄金节奏。
Agent 2:extractor(角色/场景提取)
职责: 从格式化剧本中智能提取角色和场景信息,并与项目已有数据去重合并。
工具集(5 个):
exportfunctioncreateExtractTools(episodeId: number, dramaId: number) {// 1. 读取格式化剧本const readScriptForExtraction = createTool({ ... })// 2. 读取项目中已存在的角色(用于去重)const readExistingCharacters = createTool({ ... })// 3. 读取项目中已存在的场景(用于去重)const readExistingScenes = createTool({ ... })// 4. 智能保存角色(按名字去重)const saveDedupCharacters = createTool({ ... })// 5. 智能保存场景(按地点+时间段去重)const saveDedupScenes = createTool({ ... })}去重逻辑是亮点。 看 saveDedupCharacters 的实现:
const saveDedupCharacters = createTool({ id: 'save_dedup_characters', inputSchema: z.object({ characters: z.array(z.object({ name: z.string(), role: z.string().optional(), appearance: z.string().optional(), personality: z.string().optional(), })), }), execute: async ({ characters }) => {for (const char of characters) {const existing = db.select().from(schema.characters) .where(eq(schema.characters.dramaId, dramaId)).all() .filter(c => !c.deletedAt) .find(c => c.name === char.name) // 按名字精确匹配if (existing) {// 已存在:合并信息,保留已有数据 db.update(schema.characters).set({ role: char.role || existing.role, appearance: char.appearance || existing.appearance, personality: char.personality || existing.personality, }).where(eq(schema.characters.id, existing.id)).run() linkCharToEpisode(episodeId, existing.id) // 关联到当前集 } else {// 不存在:创建新角色const res = db.insert(schema.characters).values({ ... }).run() linkCharToEpisode(episodeId, Number(res.lastInsertRowid)) } } },})为什么需要去重? 因为短剧有多集。第 1 集出现的”林悦”和第 3 集出现的”林悦”是同一个角色。如果每集都创建一个新的,角色图片、配音就无法复用。通过 episodeCharacters 多对多关联表,同一个角色可以横跨多集。
场景去重更细致——同一地点不同时间段算不同场景:
// 按【地点 + 时间段】精确匹配.find(s => s.location === scene.location && s.time === (scene.time || ''))“咖啡厅 · 午后” 和 “咖啡厅 · 深夜” 是两个不同的场景,因为光线、氛围完全不同。
Agent 3:storyboard_breaker(分镜拆解)
职责: 把格式化剧本拆解为逐镜头的分镜序列。这是整条流水线中最复杂的 Agent。
每个镜头包含 17 个字段:
|
|
|
|---|---|
title |
|
shot_type |
|
angle |
|
movement |
|
action |
|
dialogue |
|
image_prompt |
|
video_prompt |
|
bgm_prompt |
|
sound_effect |
|
duration |
|
scene_id |
|
character_ids |
|
|
|
|
视频提示词有专门的格式规范,按 3 秒一段时间轴编写:
0-3秒:<location>咖啡厅</location>,近景,<role>林悦</role>低头看手机,表情焦虑。<n>3-6秒:<location>咖啡厅</location>,全景,门铃响,<role>陈铭</role>推门走入。<n>6-9秒:中景,<role>陈铭</role>微笑走向林悦,坐下。标签系统(<location>、<role>、<voice>、<n>)让后续的视频生成模型能准确理解场景切换、角色动作和时间节奏。
save_storyboards 工具会做校验:
functionvalidateStoryboardBindings(episodeId, sceneId, characterIds) {const episodeSceneIds = getEpisodeSceneIds(episodeId)const episodeCharacterIds = getEpisodeCharacterIds(episodeId)if (sceneId != null && !episodeSceneIds.has(sceneId)) {thrownewError(`scene_id ${sceneId} 不属于当前集`) }const invalidCharacterIds = (characterIds || []).filter(id => !episodeCharacterIds.has(id))if (invalidCharacterIds.length) {thrownewError(`character_ids 不属于当前集: ${invalidCharacterIds.join(', ')}`) }}Agent 不能凭空编造不存在的场景 ID 或角色 ID——所有关联必须指向前一步(extractor)已经提取并存入数据库的实体。这是 Agent 工具设计中的约束边界:用代码校验来弥补 LLM 可能出现的幻觉。
Agent 4:voice_assigner(音色分配)
职责: 为每个角色分配 TTS 音色。
流程简单但重要:
-
list_voices读取ai_voices表(MiniMax 预置音色库) -
get_characters获取所有角色 -
Agent 根据角色性别、性格、年龄匹配音色 -
assign_voice写入characters.voiceStyle
SKILL.md 中的匹配策略:
- 性别匹配:男/女- 年龄匹配:青年/中年/少年/老年- 气质匹配:明亮/沉稳/深沉/甜美- 角色定位:主角(鲜明独特)/ 配角(中性自然)Agent 5:grid_prompt_generator(宫格图提示词生成)
职责: 为角色肖像、场景背景、宫格图生成高质量的英文提示词。
宫格图是这个项目的特色功能。它把多个分镜画面拼成一张 NxM 的网格图,交给图片生成模型一次生成,然后再切分回去。这样做的好处是 风格一致性远好于逐帧生成。
三种模式:
-
first_frame:每格是一个镜头的开头画面 -
first_last:交替排列首帧和尾帧,形成节奏感 -
multi_ref:同一个镜头的多角度参考图
四、Agent 执行引擎:Tool Use 循环
Agent 通过 HTTP 接口被前端调用:
// backend/src/routes/agent.tsapp.post('/:type/chat', async (c) => {const agentType = c.req.param('type')const { message, drama_id, episode_id } = await c.req.json()// 动态创建 Agentconst agent = createAgent(agentType, episode_id, drama_id)// 执行:最多 20 步工具调用const result = await agent.generate( [{ role: 'user', content: message }], { maxSteps: 20 }, )return success(c, { text: result.text || '', toolCalls: normalizedToolCalls, toolResults: normalizedToolResults, })})agent.generate() 是 Mastra 框架的核心方法。它内部实现了 ReAct 循环:
用户消息 → LLM 思考 → 调用工具 → 获取结果 → LLM 继续思考 → 调用下一个工具 → ... → 返回最终文本maxSteps: 20 限制了最大工具调用轮数,防止 Agent 无限循环。
五、多厂商适配层:策略模式
图片、视频、TTS 的生成涉及多个 AI 厂商。项目用 策略模式 + 注册表 做了优雅的抽象:
5.1 Adapter 接口
// backend/src/services/adapters/types.tsinterface ImageProviderAdapter { provider: string buildGenerateRequest(config: AIConfig, record: ImageGenerationRecord): ProviderRequest parseGenerateResponse(result: any): ImageGenResponse buildPollRequest(config: AIConfig, taskId: string): ProviderRequest parsePollResponse(result: any): ImagePollResponse extractImageUrl(result: any): string | null extractImageBase64(result: any): { data: string; mimeType: string } | null}每个方法对应生成流程的一个环节:构建请求、解析响应、构建轮询、解析轮询。不同厂商的差异被封装在各自的 Adapter 里。
5.2 注册表
// backend/src/services/adapters/registry.tsexportconst imageAdapters: Record<string, ImageProviderAdapter> = { minimax: new MiniMaxImageAdapter(), openai: new OpenAIImageAdapter(), gemini: new GeminiImageAdapter(), volcengine: new VolcEngineImageAdapter(), ali: new AliImageAdapter(), chatfire: new OpenAIImageAdapter(), // Chatfire 复用 OpenAI 协议}exportconst videoAdapters: Record<string, VideoProviderAdapter> = { minimax: new MiniMaxVideoAdapter(), volcengine: new VolcEngineVideoAdapter(), vidu: new ViduVideoAdapter(), ali: new AliVideoAdapter(),}exportconst ttsAdapters: Record<string, TTSProviderAdapter> = { minimax: new MiniMaxTTSAdapter(),}要加新厂商?实现接口,注册一行代码。
5.3 同步 vs 异步模式
不同厂商的响应模式不同:
-
OpenAI DALL-E:同步返回图片 URL -
Gemini:同步返回 base64 数据 -
MiniMax/火山引擎/阿里:异步返回 taskId,需要轮询 -
Vidu:异步,通过 Webhook 回调
统一的处理逻辑:
// backend/src/services/image-generation.tsconst { isAsync, taskId, imageUrl } = adapter.parseGenerateResponse(result)if (!isAsync && imageUrl) {// 同步 + URL:直接下载await handleImageComplete(id, config.provider, imageUrl)} elseif (!isAsync && !imageUrl) {// 同步 + base64(Gemini):保存为文件const b64 = adapter.extractImageBase64(result)await handleImageCompleteBase64(id, config.provider, b64.data, b64.mimeType)} else {// 异步:记录 taskId,开始轮询 db.update(schema.imageGenerations) .set({ taskId, status: 'processing' }) .where(eq(schema.imageGenerations.id, id)).run() pollImageTask(id, config, taskId!)}轮询有 10 分钟超时、120 次最大尝试、5 秒间隔,错误时自动重试。
六、FFmpeg 合成:从碎片到成片
6.1 单镜头合成
每个分镜的合成是 composeStoryboard() 函数完成的,它把三样东西揉在一起:
视频(AI 生成的裸视频) + TTS 音频(对白配音) + SRT 字幕 = 成品镜头核心流程:
// backend/src/services/ffmpeg-compose.tsexportasyncfunctioncomposeStoryboard(storyboardId: number): Promise<string> {// 1. 解析对白,识别说话人const parsedDialogue = parseDialogueForTTS(sb.dialogue)// 2. 找到角色对应的音色,调用 TTS 生成配音if (!parsedDialogue.ignorable) {const chars = db.select().from(schema.characters) .where(eq(schema.characters.dramaId, ep.dramaId)).all()const found = chars.find(c => c.name === parsedDialogue.speaker)if (found?.voiceStyle) voiceId = found.voiceStyleconst ttsPath = await generateTTS({ text: parsedDialogue.pureText, voice: voiceId, }) }// 3. 生成 SRT 字幕文件const srtContent = `1\n00:00:00,500 --> 00:00:${duration-1},000\n${pureText}\n` fs.writeFileSync(subtitlePath, srtContent, 'utf-8')// 4. FFmpeg 合成let cmd = ffmpeg(videoPath)if (audioPath) cmd = cmd.input(audioPath)if (subtitlePath) { cmd = cmd.videoFilter([`subtitles=filename='${escapedPath}':force_style='FontSize=20,...'`]) } cmd.outputOptions(['-c:v', 'libx264', '-preset', 'fast', '-crf', '23']) .output(outputPath).run()}对白解析有细节处理——过滤掉环境音、音效等非人声内容:
const IGNORE_TTS_SPEAKERS = /^(环境音|音效|sfx|bgm|背景音乐|ambient)$/iconst IGNORE_TTS_TEXT = /^(无|无对白|none|null|纯音效|仅环境音)$/i6.2 整集拼接
所有镜头合成完成后,用 FFmpeg concat 协议拼接为一集完整视频:
// backend/src/services/ffmpeg-merge.tsasyncfunctiondoMerge(mergeId, episodeId, videos) {// 生成 concat 列表文件const listContent = videos .map(v =>`file '${toAbsPath(v)}'`) .join('\n') fs.writeFileSync(listPath, listContent, 'utf-8')// FFmpeg concat 拼接 ffmpeg() .input(listPath) .inputOptions(['-f', 'concat', '-safe', '0']) .outputOptions(['-c:v', 'libx264', '-preset', 'medium', '-crf', '23','-c:a', 'aac', '-ar', '48000', '-b:a', '192k','-movflags', '+faststart', // Web 播放优化 ]) .output(outputPath).run()// 更新 episode.videoUrl db.update(schema.episodes) .set({ videoUrl: mergedRelative }) .where(eq(schema.episodes.id, episodeId)).run()}-movflags +faststart 是个重要细节——它把 MP4 的 moov atom 移到文件头,让浏览器可以边下载边播放。
七、数据库设计:16 张表的关系网
项目使用 Drizzle ORM + SQLite(WAL 模式),一共 16 张表。核心关系:
dramas (1) ──── (N) episodes │ │ ├── (N) characters ──┤── episode_characters (多对多) │ │ ├── (N) scenes ──────┤── episode_scenes (多对多) │ │ └── (N) props └── (N) storyboards │ ├── storyboard_characters (多对多) ├── image_generations ├── video_generations └── assets几个值得关注的设计:
1. 多对多关联支持跨集复用
角色和场景挂在 drama 级别,通过中间表关联到 episode。第 1 集提取的”林悦”在第 3 集可以直接复用,保持角色形象、配音的一致性。
2. AI 配置支持多厂商切换
ai_service_configs 表支持同一类型(如 image)配置多个厂商,通过 priority 字段选择默认。episodes 表还有 imageConfigId、videoConfigId、audioConfigId 三个字段,支持逐集指定不同的 AI 服务。
3. 生成任务全链路追踪
image_generations 和 video_generations 表记录了每次生成的完整信息:prompt、model、provider、status、taskId、errorMsg、localPath。任何一次生成失败,都能定位到具体的请求参数。
八、设计模式总结
回顾整个项目,几个设计模式值得借鉴:
1. 工厂模式 + 闭包注入
// Agent 工厂:每次请求创建新 Agent,通过闭包注入上下文exportfunctioncreateAgent(type, episodeId, dramaId) { ... }// 工具工厂:每个 Agent 类型有独立的工具集,通过闭包绑定数据exportfunctioncreateExtractTools(episodeId, dramaId) { ... }Agent 是无状态的,所有上下文通过闭包传递给工具。这意味着同一个 Agent 类型可以同时处理不同集的请求而互不干扰。
2. 策略模式 + 注册表
多厂商适配不用 if-else,而是用接口 + 注册表:
const adapter = getImageAdapter(config.provider) // 一行代码拿到对应策略const { url, method, headers, body } = adapter.buildGenerateRequest(config, record)3. Skill 即 Prompt
把 Agent 的专业知识(分镜规范、提示词工程、去重策略)写成独立的 Markdown 文件,运行时注入 system prompt。好处:
-
可维护性:非开发者(如编剧、导演)也能修改 Skill 文件调整 Agent 行为 -
热更新:不需要重启服务 -
可复用:一个 Agent 可以加载多个 Skill
4. 工具约束 = LLM 护栏
Agent 的工具不是无条件执行的——validateStoryboardBindings 会校验 Agent 传入的 scene_id 和 character_ids 是否合法。这是用代码在 LLM 幻觉和数据库真实状态之间建立了一道防线。
九、如果要二次开发
如果你想基于这个项目做二次开发,几个建议:
-
加新 Agent:在 DEFAULT_PROMPTS加一条、在switch加一个case、创建工具文件、写SKILL.md -
加新图片/视频厂商:实现 ImageProviderAdapter/VideoProviderAdapter接口,在registry.ts注册 -
调整 Agent 行为:直接改 skills/下的SKILL.md,不需要改代码 -
换 LLM:在设置页面切换 text provider,或修改 ai_service_configs表
总结
火宝短剧这个项目的源码质量不错,值得一读的核心设计有:
-
5 个 Agent 各司其职:剧本改写、角色提取、分镜拆解、音色分配、提示词生成,形成清晰的流水线 -
工具闭包 + Zod 校验:每个 Agent 的工具都是带上下文的闭包,输入用 Zod schema 约束 -
Skill 热注入:专业知识写在 Markdown 文件里,运行时拼接到 system prompt -
策略模式适配多厂商:接口 + 注册表,新增厂商只需实现接口并注册 -
全链路可追溯:每次 AI 调用都有完整的数据库记录
如果你对 AI Agent 的工程实践感兴趣,这个项目是一个很好的学习案例——它展示了如何把”调一下 API”变成一套可维护、可扩展的生产系统。
项目地址:https://github.com/chatfire-AI/huobao-drama