 夜雨聆风
夜雨聆风





从源码出发,真正看懂OpenPI π0.5的模型结构、训练逻辑和推理过程

点击下方卡片,关注“之心智能EDU”公众号
作者丨硅宝ai@知乎
链接 | https://zhuanlan.zhihu.com/p/2016189344914896039
编辑丨之心智能EDU
本文只做学术分享,如有侵权,联系删文
更多干货,欢迎加入国内首个具身智能全栈学习社区:具身智能之心知识星球(戳我),这里包含所有你想要的。
很多人第一次看 π0.5,都会卡在几个几乎一样的问题上:
-
为什么论文里讲了 FAST,开源代码里却主要是 flow matching? -
prefix和suffix到底是什么?是不是就是前半段和后半段 token? -
为什么 π0.5要把 state 写进 prompt,而不是像π0一样走连续分支? -
训练时的 x_t、u_t、v_t分别是什么? -
推理为什么能从一坨噪声动作,迭代十步左右就变成机器人能执行的动作 chunk?
如果你也有这些问题,这篇文章就是写给你的。
我会尽量避免“论文翻译腔”和“术语套术语”,而是直接沿着 openpi 代码,把 π0.5 的关键实现一层层拆开讲清楚。你可以把它当成一篇偏源码导读、但尽量照顾非论文型读者的长文。
★
面向读者:想入门具身智能 / VLA听说过
π0、π0.5,但还没真正看懂想从openpi开源代码出发,把“论文概念”和“工程实现”对应起来
★
本文目标:不只讲概念,也不只贴源码用一条完整主线,把
openpi里和π0.5相关的核心代码串起来
★
重点讲清楚:
π0.5的模型架构训练时输入输出是什么前向过程怎么走loss 怎么算推理时怎么从噪声一步步得到动作π0.5和π0到底改了什么,为什么这些改动可能有效
一、先说一个最重要的结论:开源版 π0.5,和论文完整版 π0.5,不是一回事
很多人第一次看 π0.5,会同时接触三样东西:
-
官方博客 -
论文 -
openpi开源仓库
然后很容易开始困惑:
-
论文里说 π0.5可以先输出高层语义子任务,再输出低层连续动作 -
论文里还提到 pretraining 阶段会用 FAST action tokenizer -
但到了 openpi仓库里,很多地方看起来又像是“只有 flow matching 连续动作头”
这个困惑不是你看错了,而是这三者本来就不完全等价。
openpi 的 README 里已经写得很明确:
Note that, in this repository, we currently only support the flow matching head for both π0.5 training and inference.也就是说:
-
论文里的完整版
π0.5 -
有更完整的两阶段训练设计 -
pretraining 阶段会把动作离散化成 token -
inference 时包含高层文本子任务推理 + 低层连续动作控制 -
开源仓库里的
π0.5 -
重点开放的是低层连续动作的 flow matching 实现 -
我们能在源码里直接看到和验证的,主要也是这部分
所以这篇文章会坚持一个原则:
凡是能用源码确认的,就按源码说;凡是来自论文和博客补充的,我会明确标出来。
二、如果你只想先记住一句话
可以先把 openpi 里的 π0.5 理解成这样一套系统:
输入图像、任务文本、机器人当前状态,再加上一段“当前还带噪声的动作序列”,模型学习预测“应该朝哪个方向把这段动作去噪”。训练时学这个方向,推理时从纯噪声开始反复更新 10 步左右,最后得到可执行的动作 chunk。
如果你有扩散模型的基础,可以把它粗略理解成:
-
不是直接预测最终动作 -
而是学习一个连续的“动作去噪速度场” -
推理时按这个速度场做 ODE 积分
但 π0.5 和常见扩散还有明显不同,后面会细讲。
三、先看一眼论文里的大图:你会知道这件事为什么复杂
图 1:π0.5 不是单纯“机器人模仿学习模型”,而是一套异构数据协同训练配方

图 1 对应论文 Fig.1。它最想表达的是:
-
π0.5的目标不是只学“某个固定机器人做某个固定任务” -
而是想通过多来源、多层次数据协同训练,获得更强的 open-world generalization
这些数据包括:
-
其他机器人数据 -
高层子任务标注 -
语言指导 -
Web 多模态数据
但请注意,这张图表达的是论文整体 recipe,不是开源仓库全部实现都一比一放出来了。
四、再看一张更关键的图:为什么会同时出现 FAST 和 flow matching?
图 2:论文版 π0.5 的两阶段训练思路
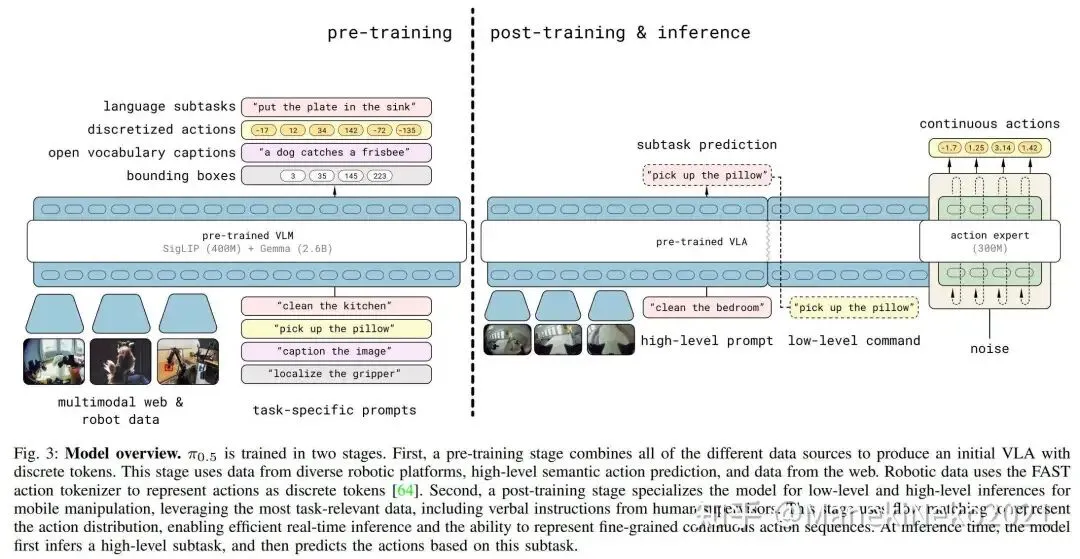
这张图特别重要,因为它解释了很多“初看很矛盾”的地方。
论文版 π0.5 是这么设计的:
第一阶段:pre-training
-
把各种任务都尽量统一成离散 token 预测 -
其中机器人动作也会用 FAST tokenizer 变成离散 token -
这样训练更像标准的 VLM / Transformer next-token prediction,稳定、可扩展
第二阶段:post-training
-
保留文本预测能力 -
同时加入 action expert -
用 flow matching 学连续动作分布 -
推理时: -
先输出高层 semantic subtask -
再基于这个 subtask 输出低层连续动作
所以你之前疑惑的“论文里为什么说预训练 action 用 FAST,但开源代码又是连续动作 flow matching”,答案是:
两者都对,只是分别对应论文 recipe 的不同阶段。
更进一步地说:
-
论文版 π0.5:离散动作和连续动作两套能力都用上了 -
开源版 openpi:主要开放了连续动作这条 flow matching 头
这点必须先讲清楚,不然后面的源码很容易越看越乱。
五、在 openpi 里,应该优先读哪些文件?
如果你想从源码真正读懂 π0.5,我建议优先看这几条线:
1. 模型主线
-
openpi/src/openpi/models/pi0.py -
openpi/src/openpi/models/pi0_config.py -
openpi/src/openpi/models/gemma.py -
openpi/src/openpi/models/tokenizer.py
2. 数据流主线
-
openpi/src/openpi/models/model.py -
openpi/src/openpi/transforms.py -
openpi/src/openpi/policies/droid_policy.py -
openpi/src/openpi/policies/libero_policy.py
3. 训练配置主线
openpi/src/openpi/training/config.py
读法建议是:
-
先看 model.py搞懂统一输入格式 -
再看 transforms.py和policies/*.py搞懂数据怎么被整理 -
然后看 pi0_config.py搞懂π0和π0.5的开关 -
最后看 pi0.py把训练和推理串起来
这样最顺。
六、先把输入格式搞明白:模型到底吃什么?
在 openpi 里,模型统一吃 Observation 和 Actions。
源码里的定义大概是:
-
image -
image_mask -
state -
tokenized_prompt -
actions
用人话说,就是:
-
多路相机图像 -
哪些图像有效 -
当前机器人低维状态 -
任务语言指令的 token 化结果 -
训练时的目标动作序列
对应源码:
@at.typecheck@struct.dataclassclass Observation(Generic[ArrayT]):"""Holds observations, i.e., inputs to the model. ... """# Images, in [-1, 1] float32. images: dict[str, at.Float[ArrayT, "*b h w c"]]# Image masks, with same keys as images. image_masks: dict[str, at.Bool[ArrayT, "*b"]]# Low-dimensional robot state. state: at.Float[ArrayT, "*b s"]# Tokenized prompt. tokenized_prompt: at.Int[ArrayT, "*b l"] | None = None# Tokenized prompt mask. tokenized_prompt_mask: at.Bool[ArrayT, "*b l"] | None = None七、数据先怎么进模型?以 DROID 为例看看
很多人第一次看模型代码,会忽略“模型前面还有一层数据适配”。
实际上,这层非常关键。
例如 DROID policy 的输入适配:
@dataclasses.dataclass(frozen=True)class DroidInputs(transforms.DataTransformFn):# Determines which model will be used. model_type: _model.ModelType def __call__(self, data: dict) -> dict: gripper_pos = np.asarray(data["observation/gripper_position"])if gripper_pos.ndim == 0:# Ensure gripper position is a 1D array, not a scalar, so we can concatenate with joint positions gripper_pos = gripper_pos[np.newaxis] state = np.concatenate([data["observation/joint_position"], gripper_pos])... match self.model_type:case _model.ModelType.PI0 | _model.ModelType.PI05: names = ("base_0_rgb", "left_wrist_0_rgb", "right_wrist_0_rgb")它做的事很简单,但很重要:
-
把不同字段拼成统一的 state -
把相机图像映射成模型固定要求的三个 key -
自动补不存在的右腕图像 -
把 prompt 和 actions 一起整理进统一结构
所以可以把这层理解成:
“数据集字段世界” 到 “模型输入世界” 的翻译器。
八、π0.5 和 π0 的第一大差异:state 怎么进模型
官方在配置文件里直接写了总结:
# Pi05 has two differences from Pi0:# - the state input is part of the discrete language tokens rather than a continuous input that is part of the suffix# - the action expert uses adaRMSNorm to inject the flow matching timestep先看第一条:
π0
-
state 是连续向量 -
经过一个线性层,变成一个 state token -
这个 token 放在 suffix 里
π0.5
-
state 被离散化 -
写进文本 prompt -
再通过 tokenizer 变成离散 token -
因此进入的是 prefix
这是理解 π0.5 的第一把钥匙。
九、什么叫 prefix?什么叫 suffix?
这两个词在 openpi 源码里非常核心。
1. prefix
你可以把它理解成:
条件上下文部分
里面包括:
-
图像 tokens -
文本 prompt tokens -
在 π0.5默认设定下,还包括离散化后的 state tokens
它回答的是:
-
现在看到了什么? -
当前要做什么任务? -
当前机器人大概处于什么状态?
2. suffix
你可以把它理解成:
动作生成部分
里面包括:
-
π0:一个连续 state token + 一串 noisy action tokens -
π0.5:一串 noisy action tokens
它更像是:
“当前这一步动作去噪过程中的中间变量”
所以我更喜欢把它类比成:
-
prefix:题目 -
suffix:当前答案草稿
模型每一步都在基于题目,去修正这个答案草稿。
十、π0.5 是怎么把 state 写进 prompt 的?
先直接看代码:
if state is not None:# This is the Pi05 format, where the state is part of the discrete language input. discretized_state = np.digitize(state, bins=np.linspace(-1, 1, 256 + 1)[:-1]) - 1 state_str = " ".join(map(str, discretized_state)) full_prompt = f"Task: {cleaned_text}, State: {state_str};\nAction: " tokens = self._tokenizer.encode(full_prompt, add_bos=True)这段代码可以拆成 4 步:
第 1 步:假设 state 已经被归一化到 [-1, 1]
这是这个离散化过程的前提。
第 2 步:把每个 state 维度分桶到 256 个区间
也就是把连续值变成一个 0~255 左右的整数。
第 3 步:把整段 state 拼成一串文本
比如变成:
Task: pick up the fork, State: 128 93 44 211 17 ...;Action:第 4 步:再交给 PaliGemma tokenizer
于是 state 就和自然语言 prompt 一起进入了统一的 token 空间。
十一、为什么 π0.5 要这么改?把 state 写进文本到底有什么好处?
这是一个很值得展开的问题。
我觉得可以从三个角度理解:
1. 统一多模态接口
如果 state 也进入离散 token 空间,那么:
-
图像有自己的编码器 -
文本有 tokenizer -
state 也变成了“文本样式 token”
这样模型就更像在处理一个统一的多模态序列,而不是“图像一支、语言一支、state 一支、动作一支”完全割裂的结构。
2. 更容易和高层语义融合
机器人当前 state 并不是纯底层量,它经常和语义决策有关:
-
夹爪现在开还是闭? -
双臂当前在什么姿态? -
机械臂是不是已经靠近目标?
把这些信息放进 prompt 后,模型在处理“任务语义”时,也能同步利用当前状态。
3. 更贴合 π0.5 的 heterogeneous co-training 思路
π0.5 的重要方向之一,是让模型能跨数据源学习:
-
web 数据 -
语言监督 -
高层子任务 -
机器人动作
这时候,把更多信息转成 token,往往更容易和大模型的 sequence modeling 框架接起来。
当然,这也不是“绝对更好”,而是一个设计取向:
用 token 化的方式,把 state 拉进 VLM 语义空间。
十二、但这里有个特别容易混淆的问题:state 是 token 了,那 action 呢?
这个问题不解释清楚,后面一定会乱。
很多读者的第一反应
既然 π0.5 都把 state 写进 prompt 变成 token 了,那 action 呢?
论文里又说过 FAST tokenizer,那 action 在开源版里是不是也是 token?
结论
在 openpi 这套开源版 π0.5 代码里,action 不是 token,而是连续向量。
这点非常重要。
也就是说,在开源仓库的 π0.5 flow-matching 路径里:
-
state 可能被离散成 token -
action 仍然是连续动作序列
为什么会混?
因为你看到的是三套事情叠在一起:
第一套:π0
-
连续动作 -
flow matching
第二套:论文完整版 π0.5
-
pretraining 里会用 FAST action tokenizer 做离散动作 -
post-training / inference 里又会使用连续 flow matching 动作头 -
还会有高层文本子任务解码
第三套:π0-FAST
-
这是另一条模型路线 -
动作就是 token -
用自回归方式预测
所以不要把它们混成一句“π0.5 就是 action token 模型”。
更准确的说法是:
论文版 π0.5 结合了离散动作训练与连续动作推理;而 openpi 开源版主要开放了连续动作 flow matching 这部分。
十三、一个很关键但容易忽略的事实:论文里“FAST + flow matching”是两阶段 recipe,开源里主要保留了后半段
论文对这个问题写得其实挺清楚:
-
pre-training 阶段:动作用 FAST token,便于标准 Transformer 训练 -
post-training 阶段:加入 action expert,学习连续 flow matching 动作
论文转换稿里也有明确表述:
★
Robotic data uses the FAST action tokenizer to represent actions as discrete tokens.Second, a post-training stage … uses flow matching to represent the action distribution.
所以,如果你读源码时发现:
-
论文说动作会 token 化 -
但 openpi 的 pi0.py 里 action 明明是连续向量
不要怀疑自己看错了。
这是因为:
你现在看到的是开源仓库里偏“post-training / continuous action head”的那部分代码。
十四、真正进入模型前,prompt 是怎么 token 化的?
在 transforms.py 里,TokenizePrompt 决定了 state 是否一起进入文本:
@dataclasses.dataclass(frozen=True)class TokenizePrompt(DataTransformFn): tokenizer: _tokenizer.PaligemmaTokenizer discrete_state_input: bool = False def __call__(self, data: DataDict) -> DataDict:if (prompt := data.pop("prompt", None)) is None: raise ValueError("Prompt is required")if self.discrete_state_input:if (state := data.get("state", None)) is None: raise ValueError("State is required.")else: state = None... tokens, token_masks = self.tokenizer.tokenize(prompt, state)这里的逻辑是:
-
如果
discrete_state_input=False -
只 token化语言 prompt -
如果
discrete_state_input=True -
把 state 一起传给 tokenizer -
tokenizer 就会走 π0.5 那条 state 离散化逻辑
所以 π0.5 的“state 写进 prompt”其实并不是写死在模型里,而是通过数据变换层控制的。
十五、一个非常值得写进源码解读的“坑点”:pi05_libero 居然把 discrete_state_input=False 关掉了
在 training/config.py 里,你会看到这个配置:
TrainConfig( name="pi05_libero", model=pi0_config.Pi0Config(pi05=True, action_horizon=10, discrete_state_input=False),这意味着什么?
意味着:
-
它虽然是 pi05=True -
但这个具体配置却显式把 discrete_state_input=False 了
也就是说,不是所有名叫 pi05_* 的配置都会采用“state 写进 prompt”这个默认策略。
这说明一件很重要的工程事实:
π0.5 在开源代码里更像是一类模型变体,而不是一个只有单一固定输入范式的纯理论对象。
如果你是做实际实验的人,这个细节特别重要:
-
不要把“论文里的默认描述” -
和“仓库里某个 benchmark 配置” -
想当然地当成完全一致
十六、接下来进入主模型:π0.py 里到底做了什么?
核心类在这里:
class Pi0(_model.BaseModel): def __init__(self, config: pi0_config.Pi0Config, rngs: nnx.Rngs): super().__init__(config.action_dim, config.action_horizon, config.max_token_len) self.pi05 = config.pi05 paligemma_config = _gemma.get_config(config.paligemma_variant) action_expert_config = _gemma.get_config(config.action_expert_variant)# TODO: rewrite gemma in NNX. For now, use bridge. llm = nnx_bridge.ToNNX( _gemma.Module( configs=[paligemma_config, action_expert_config], embed_dtype=config.dtype, adarms=config.pi05, ) )它其实是一个统一实现:
-
π0和π0.5都用这个类 -
通过 config.pi05来切换差异分支
从结构上,可以把它理解成三部分:
1. 图像编码器:SigLIP
把多路相机图像变成 image tokens。
2. 主干 Transformer:PaliGemma / Gemma
负责融合图像、语言和动作上下文。
3. Action expert
这是动作侧的专门分支:
-
输入 noisy action tokens -
输出 flow matching 速度场
所以整个模型并不是一个“纯文本 LLM 套壳”,而是一个:
图像编码器 + 多模态 Transformer 主干 + 动作专家头
十七、真正理解模型的关键:embed_prefix() 和 embed_suffix()
这两个函数几乎就是整个模型的灵魂。
1. embed_prefix():条件部分怎么构造
embed_prefix() 主要做两件事:
图像编码
-
每路图像过 SigLIP -
得到一串 image tokens
文本编码
-
tokenized_prompt 通过词嵌入表变成 text embeddings
最后把两者拼接,形成 prefix_tokens。
你可以把 prefix 理解成:
“当前场景 + 当前任务 + (可能还有离散 state)”
2. embed_suffix():动作部分怎么构造
这才是最关键的差异点。
代码如下:
if not self.pi05:# add a single state token state_token = self.state_proj(obs.state)[:, None, :] tokens.append(state_token)... action_tokens = self.action_in_proj(noisy_actions)# embed timestep using sine-cosine positional encoding with sensitivity in the range [0, 1] time_emb = posemb_sincos(timestep, self.action_in_proj.out_features, min_period=4e-3, max_period=4.0)if self.pi05:# time MLP (for adaRMS) time_emb = self.time_mlp_in(time_emb) time_emb = nnx.swish(time_emb) time_emb = self.time_mlp_out(time_emb) time_emb = nnx.swish(time_emb) action_expert_tokens = action_tokens adarms_cond = time_embelse:# mix timestep + action information using an MLP (no adaRMS) time_tokens = einops.repeat(time_emb, "b emb -> b s emb", s=self.action_horizon) action_time_tokens = jnp.concatenate([action_tokens, time_tokens], axis=-1) action_time_tokens = self.action_time_mlp_in(action_time_tokens) action_time_tokens = nnx.swish(action_time_tokens) action_time_tokens = self.action_time_mlp_out(action_time_tokens) action_expert_tokens = action_time_tokens adarms_cond = None这段代码非常值得慢慢看。
十八、π0 和 π0.5 在 suffix 中的区别,一句话版
π0
-
先把连续 state投影成一个 token -
再把时间 embedding 和 noisy action embedding 拼起来 -
过 MLP 后送进 action expert
π0.5
-
不再单独加连续 state token -
noisy action embedding 直接进入 action expert -
时间 embedding 不再和 action token 直接拼接 -
而是变成 adarms_cond去调制 action expert 的归一化层
这两条路线的差异,其实就是:
-
state 放哪里 -
time 怎么注入
十九、π0.5 的第二个关键改动:为什么要把时间步 t 改成 AdaRMSNorm 注入?
这部分是很多人第一次看时最容易“看懂代码、没懂直觉”的地方。
先看底层实现。
在 gemma.py 里,RMSNorm 如果拿到 cond,就会从普通 RMSNorm 变成一种自适应 RMSNorm:
class RMSNorm(nn.Module): @nn.compact def __call__(self, x, cond): dtype = x.dtype # original dtype, could be half-precision var = jnp.mean(jnp.square(x.astype(jnp.float32)), axis=-1, keepdims=True) # compute variance in float32 normed_inputs = jnp.asarray(x * jnp.reciprocal(jnp.sqrt(var + 1e-06))) # compute normalization in float32if cond is None:# regular RMSNorm scale = self.param("scale", nn.initializers.zeros_init(), (x.shape[-1])) normed_inputs = normed_inputs * ( 1 + scale ) # scale by learned parameter in float32 (matches Flax implementation)return normed_inputs.astype(dtype), None # return in original dtype# adaptive RMSNorm modulation = nn.Dense(x.shape[-1] * 3, kernel_init=nn.initializers.zeros, dtype=dtype)(cond) scale, shift, gate = jnp.split(modulation[:, None, :], 3, axis=-1)你可以把它粗略理解成:
-
普通 RMSNorm:只是归一化 -
AdaRMSNorm:归一化之后,还会根据 cond 做动态调制
而在 π0.5 里,这个 cond 就是时间步 t 经过 MLP 后得到的表示。
这意味着什么?
意味着:
-
π0:时间信息主要在输入层就混进 action token 了 -
π0.5:时间信息可以逐层影响 action expert 的内部计算
这很像是在告诉模型:
★
“你现在是在去噪初期、中期还是末期?不同阶段,应该用不同的内部处理方式。”
为什么这很合理?
因为 flow matching 的不同 t,本来就对应完全不同的去噪语义:
-
接近 t=1:动作还非常像噪声,需要更粗的修正 -
接近 t=0:动作已经接近干净,需要更细的修正
如果时间条件只在最开始拼一下,网络后面层数多了以后可能会被冲淡;
而如果时间条件能进入每一层的归一化,它就能持续影响整个动作专家的处理过程。
这就是我理解里 π0.5 在实现层面非常漂亮的一点。
二十、为什么训练时一定要输入 t?只看当前 noisy action 不行吗?
这也是理解 flow matching 的核心。
先看训练代码
batch_shape = actions.shape[:-2] noise = jax.random.normal(noise_rng, actions.shape) time = jax.random.beta(time_rng, 1.5, 1, batch_shape) * 0.999 + 0.001 time_expanded = time[..., None, None] x_t = time_expanded * noise + (1 - time_expanded) * actions u_t = noise - actions... v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :])return jnp.mean(jnp.square(v_t - u_t), axis=-1)这里定义了 4 个非常重要的量:
1. noise
从高斯分布采样的一段噪声动作。
2. t
flow matching 的时间步,从 0 到 1。
这段代码里不是均匀采样,而是:
-
Beta(1.5, 1) -
再裁剪到 [0.001, 0.999]
也就是说,训练时会随机抽取不同的 t,让模型见过不同去噪阶段。
3. x_t
定义为:
x_t = t * noise + (1 - t) * actions它表示:
真实动作和噪声在时间步 t 下的线性混合状态。
4. u_t
定义为:
u_t = noise - actions这就是理论上对应的目标速度场。
5. v_t
模型预测出来的速度场。
训练目标就是:
MSE(v_t, u_t)二十一、这里最关键的直觉:为什么只知道 x_t 还不够?
因为不同的 (noise, actions) 组合,在不同的 t 下,完全可能混出同一个 x_t。
举个非常直观的例子。
假设某个维度里:
-
情况 A:
-
noise = 1 -
action = 0 -
t = 0.5 -
那么 x_t = 0.5 -
目标速度 u_t = 1 - 0 = 1 -
情况 B:
-
noise = 0.5 -
action = 0 -
t = 1.0 -
那么 x_t = 0.5 -
目标速度 u_t = 0.5 - 0 = 0.5
你会发现:
-
当前看到的 x_t一样,都是0.5 -
但正确的速度方向不一样
所以模型不能只看“当前这个 noisy action 长什么样”,还得知道:
“我现在是在整条噪声到动作路径上的哪一段?”
而这个信息,就是 t。
这也是为什么:
-
t 不是一个可有可无的小辅助变量 -
而是决定速度场的关键条件
二十二、如果你完全没接触过 flow matching,可以把它这样想
把真实动作想成一条“干净轨迹”,把噪声想成一条“乱轨迹”。
训练时,模型反复看各种中间状态:
-
有的状态更像噪声 -
有的状态更像真实动作 -
每个状态都有对应一个“应该往哪边修”的方向
模型学会的不是“一步直接输出正确动作”,而是:
“在任何一个中间状态下,我都知道应该往哪边走。”
于是推理时就可以:
-
从纯噪声出发 -
每次问模型“现在该往哪边走一点?” -
连续走几步 -
最后走到干净动作
这就是 π0 / π0.5 里 flow matching 的核心直觉。
二十三、训练时完整前向过程,可以按下面这条主线记
为了帮助第一次看的人建立完整脑图,我把训练过程压缩成一条“工程视角”的流程。
第 1 步:原始样本进入数据变换层
输入通常包括:
-
图像 -
当前 state -
prompt -
真实动作序列
第 2 步:统一成模型格式
通过 policy transform,整理成:
-
image -
image_mask -
state -
prompt -
actions
第 3 步:文本 token 化
-
π0:只 token 化 prompt -
π0.5:默认还会把离散化后的 state 写进 prompt 一起 token 化
第 4 步:状态和动作 padding 到模型内部维度
源码里有统一 padding:
class PadStatesAndActions(DataTransformFn):"""Zero-pads states and actions to the model action dimension.""" model_action_dim: int def __call__(self, data: DataDict) -> DataDict: data["state"] = pad_to_dim(data["state"], self.model_action_dim, axis=-1)if"actions"in data: data["actions"] = pad_to_dim(data["actions"], self.model_action_dim, axis=-1)return data这点很重要,因为不同机器人平台动作维度并不一致。
第 5 步:图像预处理
preprocess_observation() 会做:
-
resize 到 224×224 -
训练时做 crop / rotate / color jitter -
补 image mask
第 6 步:采样 noise 和 t
-
noise ~ N(0, I) -
t ~ Beta(1.5, 1),再裁到[0.001, 0.999]
第 7 步:构造 flow matching 训练目标
-
x_t = t*noise + (1-t)*actions -
u_t = noise - actions
第 8 步:构造 prefix_tokens
由:
-
图像 tokens -
文本 tokens
组成。
第 9 步:构造 suffix_tokens
由:
-
π0:state token + noisy action tokens -
π0.5:noisy action tokens
组成,同时注入时间步。
第 10 步:进 PaliGemma + action expert
模型输出 suffix_out。
第 11 步:投影成速度场 v_t
只取动作那部分输出,做线性投影。
第 12 步:计算 loss
loss = MSE(v_t, u_t)至此,一次训练前向结束。
如果你想先有“全局观”,可以直接看这一段伪代码
上面那 12 步是拆开讲的。
如果你更习惯“从输入一路看到输出”,那下面这段伪代码会更直观。
训练时:模型到底在学什么?
# =========================# 输入# =========================# obs:# - images: 多路图像# - prompt: 任务文本# - state: 当前机器人状态# actions:# - 真实动作序列 [B, H, A]# =========================# Step 1. 数据预处理# =========================obs = preprocess_observation(obs)# π0:# prompt 只包含任务文本# π0.5:# prompt 可能包含 "Task: ..., State: ...; Action: "tokenized_prompt = tokenize_prompt(prompt, maybe_state_for_pi05)# state 和 actions padding 到统一 action_dimstate = pad_state(state)actions = pad_actions(actions)# =========================# Step 2. 构造 flow matching 训练样本# =========================noise = sample_gaussian(shape=actions.shape)t = sample_time_from_beta_distribution() # t in (0, 1)# 当前混合状态:在真实动作和纯噪声之间插值x_t = t * noise + (1 - t) * actions# 训练目标:速度场u_t = noise - actions# =========================# Step 3. 构造 prefix# =========================image_tokens = SigLIP(images)language_tokens = GemmaEmbed(tokenized_prompt)prefix_tokens = concat(image_tokens, language_tokens)# =========================# Step 4. 构造 suffix# =========================action_tokens = action_in_proj(x_t)time_emb = posemb_sincos(t)if model == "pi0": state_token = state_proj(state) action_tokens = action_time_mlp(concat(action_tokens, repeat(time_emb))) suffix_tokens = concat(state_token, action_tokens) adarms_cond = Noneif model == "pi05":# state 不再单独走 suffix,它已经在 prompt 里 suffix_tokens = action_tokens adarms_cond = time_mlp(time_emb) # 用来做 AdaRMS 条件调制# =========================# Step 5. Transformer 前向# =========================prefix_out, suffix_out = PaliGemma_with_ActionExpert( prefix_tokens, suffix_tokens, attn_mask=build_mask(prefix_tokens, suffix_tokens), adarms_cond=adarms_cond)# 只取 suffix 最后 H 个 action token 的输出v_t = action_out_proj(suffix_out[:, -H:])# =========================# Step 6. 训练损失# =========================loss = MSE(v_t, u_t)推理时:为什么能从噪声“走”到动作?
# =========================# 输入# =========================# obs:# - 当前图像# - 当前任务 prompt# - 当前 stateobs = preprocess_observation(obs)# 从纯噪声动作开始x_t = sample_gaussian(shape=[B, H, A])t = 1.0dt = -1.0 / num_steps# prefix 不变,先缓存prefix_tokens = embed_prefix(obs)kv_cache = build_prefix_kv_cache(prefix_tokens)while t >= -dt / 2: suffix_tokens = embed_suffix(obs, x_t, t)# 模型预测当前速度方向 v_t = model(prefix_cached=kv_cache, suffix_tokens=suffix_tokens, t=t)# Euler 更新:沿着预测方向走一小步 x_t = x_t + dt * v_t t = t + dt# 最终 x_t 就是干净动作 x_0actions = x_t再用一句话总结这段伪代码
-
训练时:模型学会“在任意去噪阶段,当前应该往哪个方向修动作” -
推理时:模型不断告诉你“下一小步该往哪边走”,最后把纯噪声走成可执行动作
这一段如果你吃透了,后面很多局部细节就不容易迷路。
二十四、真正推理时,模型输入输出分别是什么?
这也是很多人第一次读时容易混淆的地方。
训练时模型输入
-
obs -
x_t(由真实动作和噪声混出来) -
t
推理时模型输入
-
obs -
当前迭代时刻的 x_t -
当前时间步 t
区别在于:
-
训练时 x_t来自真实动作 + 噪声 -
推理时 x_t最开始纯噪声,后面来自模型自己迭代更新
推理时模型输出
-
预测的速度场 v_t
然后外层采样器做 Euler 更新:
x_t <- x_t + dt * v_t反复执行若干次,直到 t≈0,最终拿到干净动作。
二十五、推理代码到底在做什么?
来看 sample_actions():
# note that we use the convention more common in diffusion literature, where t=1 is noise and t=0 is the target# distribution. yes, this is the opposite of the pi0 paper, and I'm sorry. dt = -1.0 / num_steps batch_size = observation.state.shape[0]if noise is None: noise = jax.random.normal(rng, (batch_size, self.action_horizon, self.action_dim))... def step(carry): x_t, time = carry... v_t = self.action_out_proj(suffix_out[:, -self.action_horizon :])return x_t + dt * v_t, time + dt... x_0, _ = jax.lax.while_loop(cond, step, (noise, 1.0))return x_0把它翻成大白话就是:
第 1 步:从纯噪声动作开始
初始化:
-
x_1 = noise -
t = 1
第 2 步:缓存 prefix
图像和文本的 prefix 不会在 10 步迭代中改变,所以先编码并缓存 KV。
这是非常重要的工程优化,不然每一步都重算图像和文本很浪费。
第 3 步:每一步都重新构造 suffix
因为:
-
当前 x_t在变 -
当前 t在变
所以 suffix 每一步都要重新构造。
第 4 步:模型预测当前速度场 v_t
第 5 步:Euler 更新
x_t = x_t + dt * v_t第 6 步:重复若干步
最后得到 x_0,也就是干净动作。
二十六、为什么只要 10 步左右?
源码里默认:
num_steps = 10论文里也提到:
-
推理时用 10 denoising steps
这和很多扩散模型动辄几十上百步相比,已经算很快了。
原因在于:
-
这里学的是比较直接的 flow / velocity field -
目标是连续动作 chunk,不是极高维像素图像 -
action 轨迹本身通常比图像生成问题更规整
当然,这并不意味着“10 步是理论最优”,而是一个工程上效果和速度的折中。
二十七、while time >= -dt/2 为什么不是 time > 0?
这属于“只有认真看源码才会注意到”的小细节。
代码是:
def cond(carry): x_t, time = carry# robust to floating-point errorreturn time >= -dt / 2因为:
-
dt = -1 / num_steps -
浮点数计算时,time 可能不会精确落到 0
如果你直接写 time > 0:
-
可能会少走一步 -
也可能会多走一步
而 -dt/2 相当于留了一个容差带,避免数值误差影响步数。
这类处理很朴素,但很有工程味。
二十八、attention 是怎么组织的?为什么说它不是简单“编码 observation 再单独解码动作”?
这点其实很重要,但很多介绍文章都一笔带过。
在 π0 / π0.5 里:
-
prefix 和 suffix 最终都在同一个 Transformer 体系里 -
只是 attention mask 不一样
直觉上可以这样理解:
prefix 内部
-
图像 token 和文本 token 之间可以双向看
suffix 对 prefix
-
suffix 可以看 prefix -
也就是说动作 token 能持续参考图像和文本条件
prefix 对 suffix
-
prefix 不会反过来看 suffix -
因为 suffix 更像“当前动作生成过程中的查询部分”
所以从结构上看,它更像:
一个共享多模态 Transformer,在同一序列里同时容纳条件和动作生成变量。
而不是那种严格分离的 encoder-decoder 两塔结构。
二十九、动作维度这件事,源码里还有个很重要的工程事实
很多读者第一次看模型时会默认:
-
state 几维 -
action 就几维 -
模型输出几维 -
机器人就执行几维
但实际工程里远没这么简单。
例如 DROID 输出层最后只保留前 8 维:
@dataclasses.dataclass(frozen=True)class DroidOutputs(transforms.DataTransformFn): def __call__(self, data: dict) -> dict:# Only return the first 8 dims.return {"actions": np.asarray(data["actions"][:, :8])}而很多 π0.5 配置内部 action dim 是 32。
这意味着:
-
模型内部使用一个统一较大的动作维度 -
小维度机器人通过 padding 接入 -
最后再裁回真实控制量
这个设计对跨平台训练很重要。
你也能从论文里看到类似思想:
-
为了兼容多种机器人,动作维度会统一到足够大的公共空间
这也是很多“跨 embodiment”模型的常见工程套路。
三十、LIBERO 和 DROID 这些例子,还能帮我们看出什么?
看 LiberoOutputs:
def __call__(self, data: dict) -> dict:# Only return the first N actions -- since we padded actions above to fit the model action# dimension, we need to now parse out the correct number of actions in the return dict.# For Libero, we only return the first 7 actions (since the rest is padding).# For your own dataset, replace `7` with the action dimension of your dataset.return {"actions": np.asarray(data["actions"][:, :7])}这进一步说明:
-
模型内部动作空间是“统一模板” -
平台层输出才做“还原”
换句话说:
模型内部的动作表示,不等于机器人最终实际执行的控制接口。
中间有一层“统一表示空间”。
三十一、现在回到最核心的主题:π0.5 相比 π0,到底好在哪里?
如果只从开源代码能确认的部分来讲,我认为至少有三点。
1. state 建模方式更贴近统一多模态上下文
π0:
-
state 是连续 token -
更像动作专家专门看的局部信息
π0.5:
-
state 进入文本上下文 -
更像整个多模态理解的一部分
这对需要更强语义理解和跨场景泛化的任务,可能是有帮助的。
2. 时间条件注入得更深
π0:
-
时间信息主要在输入处拼接
π0.5:
-
时间信息通过 AdaRMSNorm 进入每层
这对 flow matching 这种“不同去噪阶段处理逻辑差异显著”的问题,直觉上更合理。
3. 更贴近论文版 π0.5 的整体方向
即便开源版只开放了 flow matching 头,它在结构上仍然能看出那条主线:
-
更强调统一 token 上下文 -
更强调 semantic grounding -
更强调面向 heterogeneous co-training 的可扩展性
换句话说,π0.5 在开源实现里不是“完全新模型”,而是:
在 π0 连续动作 VLA 基础上,往更强 generalization 方向做的一次结构升级。
三十二、论文里 π0.5 还比开源版多了什么?
这部分很值得单独列出来,帮助读者建立正确预期。
论文完整版 π0.5 额外强调的能力包括:
1. 两阶段训练 recipe
-
pre-training:离散 token,包括 FAST 动作 token -
post-training:加入 flow matching action expert
2. 高层 semantic subtask 推理
推理时先输出:
-
“pick up the plate” -
“pull out the drawer”
这种高层子任务
再根据这个子任务输出低层连续动作。
3. 更复杂的 co-training 数据混合
包括:
-
多环境机器人数据 -
跨 embodiment 数据 -
高层子任务标注 -
verbal instruction demonstrations -
web 多模态数据
而这些在 openpi 开源仓库里,并不是都以“完整 recipe”形式展开了。
所以如果你的目标是:
-
复现论文全部训练配方
那你不能只盯着当前仓库里 pi0.py 这套 flow head 代码。
三十三、对初学者来说,最容易误解的 5 个点
这里我把读源码时最常见的误区集中总结一下。
误区 1:π0.5 就是 action token 模型
不对。
-
论文版 π0.5 在 pretraining 阶段会用离散动作 token -
但开源版 π0.5 重点开放的是连续 flow matching 动作头
误区 2:state 和 action 都是机器人低维量,应该用同一种表示
不对。
它们在模型里的角色不同:
-
state 是条件 -
action 是生成目标
表示方式不同是合理的。
误区 3:suffix 就只是 observation 的后半段
不对。
suffix 更像“当前动作去噪轨迹的中间变量”,不是简单的 observation 补充。
误区 4:推理时模型直接输出最终动作
不对。
模型输出的是 v_t,也就是当前速度场。
最终动作是外层采样器迭代积分出来的。
误区 5:只知道当前 noisy action x_t 就能判断怎么去噪
也不对。
还必须知道当前时间步 t,否则同一个 x_t 可能对应不同速度方向。
三十四、一个最终版脑图
如果要把整篇文章收束成一句最核心的话,我会这样说:
openpi 里的 π0.5,本质上是一个把图像、语言和机器人状态融合成条件上下文,再通过 flow matching 连续生成动作序列的多模态 Transformer。相比 π0,它最关键的两点改进是:把 state 从连续 token 改成了离散 prompt token,以及把时间步 t 从输入级拼接升级成了 AdaRMS 级别的逐层条件调制。
如果你已经把这句话真正看懂了,那么:
-
prefix / suffix -
x_t / u_t / v_t -
π0 / π0.5的核心差异
基本就都打通了。
三十五、参考资料
开源代码
-
openpi GitHub / README
官方博客
-
π0 官方博客https://physicalintelligence.company/blog/pi0
-
π0.5 官方博客https://www.physicalintelligence.company/blog/pi05
论文
π0.5: a Vision-Language-Action Model with Open-World Generalization
π0.5: a Vision-Language-Action Model with Open-World Generalization
后记
如果要我用一句话总结这篇文章,我会说:
π0.5 最值得学的,不只是“它比 π0 更强”,而是它代表了一种很典型的当代 VLA 设计思路。
这种思路大概是:
-
能 token 化的条件,尽量 token 化,放进统一多模态上下文 -
对连续低层控制,不强行全离散化,而是保留 flow matching 这类更适合动作生成的表示 -
让 VLM 负责理解世界和任务,让 action expert 负责输出连续控制 -
再用一个共享 Transformer,把理解和控制真正接起来
从这个意义上看,π0.5 有意思的地方,不只是某个 benchmark 分数,也不只是“state 改成写进 prompt”这种局部技巧,而是它把下面这几件事放进了同一个系统里:
-
语言理解 -
视觉感知 -
机器人状态建模 -
连续动作生成 -
多来源知识迁移
这也是为什么,哪怕你暂时不打算直接复现 π0.5,认真读一遍 openpi 这套代码,依然很值得。
因为你学到的不是某个单点 trick,而是一种更完整的具身模型思路:
一边继承 VLM 的语义能力,一边保留机器人控制所需要的连续动作表达。
如果你后面继续深入,我个人建议优先顺着这三条线往下读:
-
pi0.py里embed_prefix() / embed_suffix() / compute_loss() / sample_actions() -
tokenizer.py和transforms.py里 state 是怎么进入 prompt 的 -
论文版 π0.5 中 FAST 预训练、high-level subtask 和 post-training flow head 的完整关系
等这三条线彻底打通之后,你再回头看 π0、π0.5、π0-FAST,很多原本“像是术语差异”的地方,就会真正变成你脑子里能跑起来的一套系统!
END


求点赞

求分享

求喜欢
