 夜雨聆风
夜雨聆风





旧文档困住AI世界,八般兵器华山论剑

前言
第一篇平生不识Markdown,用遍AI也枉然,介绍了AI世界MarkDown的好处,但知道 Markdown 好,不代表你手上的材料已经是 Markdown。
当前情况是还有大量的历史文件和知识,还锁在 PDF、Word、Excel、网页存档、扫描件和各种混合格式里。 你以为你扔给AI,AI就能读懂,其实不然,这个过程也是需要花功夫去转换的。
俗话说,garbage in garbage out, 很多人都说AI给不出想要的东西,其实喂给它的东西就不对!
这篇华山论剑就是笔者对比了多个流行的MarkDown转换工具,并且还封装成了api和cli,适合任何程序调用,也适合AI agent调用,成为了我自己使用AI的第一个基础工具。
这个项目会持续更新,让你真正掌握:
怎么把各种各样的存量文档,稳定地转成MarkDown接进 AI 工作流。
这个工具也被国际精算师协会的GitHub:https://github.com/IAA-AITF收录了。
常用的MarkDown转换工具
doc_to_md这个项目,是半年前就开始在GitHub上开始对MarkDown转换工具一一亲手测试的,转markdown的工具真的不少,但真正谁好用,谁更适合精算师,我们得问几个问题:
-
普通正文型 PDF,默认用什么工具最简单,耗时最短 -
精算公式很多的 PDF,哪个工具对公式支持最好 -
手写公式、截图公式这种页面,到底能转换么
于是乎,我搞了个八般兵器华山论剑,从安装依赖,安装大小,对以下工具进行了测试,从中真正找到了最好用的武器。
markitdownmistral AIdoclingmathpixopendataloaderpaddleocrminerumarkerdeepseekocr
(为啥是九个?因为学数学的有三类人:会数数的和不会数数的)
先说结论:现在结果不是“一把锤子打天下”
几句话总结如下:
-
全能转换之王: mistral是我最喜欢的转换工具,没有之一。印刷公式、表格、图片样样精通,除了费钱没别的不好。1000页1-2美元,通常我个人帐单每月10刀左右,但一看效果,这个钱值得花。 -
普通文本型 ,新起之秀: opendataloader是我现在最推荐的本地模型,速度快,不耗钱,不过它需要装java。 -
微软自己革自己office命的 markitdown是使用率最高的工具之一,GitHub上大热门,简单易用,但文章格式丢太多。 -
IBM的docling,在opendataloader面世之前本地转换我的最爱,效果特别好,就是速度慢。 -
手写公式专项冠军: mathpix,手写公式都能转的杠杠的,俺们数学系同学的最爱,价格贵,$19.99注册费用+1000页5美元。
现在的推荐不是谁是“华山论剑霸主”,而是“哪种文档哪个场景该走哪条路”。这个方案写进AI Agent skill,它就会像你那么聪明的自动选择工具。
华山论剑打了三场
我一共做了三组评测,对安装成本,转换速度,输出质量等,多方面进行评分,具体数字在这里就不讲了,都存在了GitHub上,感兴趣的可以到GitHub上查看,这里就讲讲大概过程和结论。
第一组:普通文本型 PDF,看的是“谁是默认工具”
这一组我放了SOA今年一月的AI bulletin作为样本,进行测试,为了找到:
-
普通 PDF 默认先试什么 -
本地方案里谁最均衡 -
API 方案值不值得上
结果如下:
|
|
|
|---|---|
|
|
markitdown |
|
|
opendataloader |
|
|
mistral |
如果看综合评分,这组里前两名是:
|
|
|
|
|---|---|---|
mistral |
3.88 |
|
opendataloader |
3.77 |
|
markitdown 虽然分数不是最高,但确实是最简单的工具:让你五分钟内先跑起来,而且速度很快!唯一毛病就是格式丢失太多。
详细点评:
-
docling -
markitdown -
mathpix文本处理一般,但依然是公式识别领域的行业天花板。
-
mistral -
opendataloader -
mineru -
paddleocr -
marker
-
原始 PDF 节选:

-
转成 Markdown 后的样子:
## SOA Research on the Emergence of AI in Actuarial PracticeDanielle Amiel, FSA, FCIA; Joe Alaimo, ASA, Hacia; JianGang He, FSA, FCIA; and Kevin Pledge, FSA, FIASee Article following.## Accelerating Stochastic Calculations Through Neural NetworksChristopher Najjar, FSA, CERA; Martin Le Roux, FSA, FCIA, CFA; and Sally Xu, FSA, FCIA, CERA
-
最后 Markdown 显示出来的样子:

这类样本里,我更看重的是标题层级和段落不断。只要这两件事稳了,后面的摘要、检索、切分基本就有底。
第二场:印刷公式型 PDF,看的已经不是“像不像文章”
到了精算文件 PDF,问题一下就变了。这一组测试回答的问题就不是“谁转得快”,而是:
-
文件中的数学公式有没有正确识别 -
识别出来之后,AI 到底能不能读
表面上你还是在做 PDF 转 Markdown,但真正影响 AI 的,已经不再是段落顺不顺,而是:
公式到底有没有从图片和排版碎片,变回显式的数学表达式。
这组样本用的是一份真实带公式的偿二代监管文档,直接看公式召回率。
|
|
|
|
|
|
|---|---|---|---|---|
mistral |
11.59s |
96% |
96% |
|
mathpix |
8.01s |
80% |
85% |
|
opendataloader |
0.89s |
0% |
0% |
|
markitdown |
1.46s |
0% |
0% |
|
这组 mistral 96%自然冠军,后面三个 0%。说明了一件很容易被忽略但是对精算师很重要的事
Markdown 看起来有结构,不等于公式已经能被 AI 读懂。
-
原始 PDF 节选:

-
转成 Markdown 后的样子:
# 第五章 保费及准备金风险最低资本第四十二条 各类型非寿险业务(信用保证险除外)的保费及准备金风险最低资本的计算公式为:$$\mathrm {M C} _ {\text{保费及准备金} _ {\mathrm {i}}} = \sqrt {\mathrm {M C} _ {\text{保费} _ {\mathrm {i}}} {} ^ {2} + 2 \times \rho \times \mathrm {M C} _ {\text{保费} _ {\mathrm {i}}} \times \mathrm {M C} _ {\text{准备金} _ {\mathrm {i}}} + \mathrm {M C} _ {\text{准备金} _ {\mathrm {i}}} {} ^ {2}}$$其中:
-
最后 Markdown 显示出来的样子:

这一类文档里,opendataloader 仍然很快,但快不等于公式可用。真正要进 AI 流程,mistral 仍然是首选。
第三场:手写公式样本,已经不是 PDF 抽字,而是公式识别
手写公式这组更有意思。
它根本不是“把排版还原好”这个问题,而是“能不能从图像里重新识别数学表达式”。所以这组结果和前面完全不一样:
|
|
|
|
|
|
|---|---|---|---|---|
mathpix |
5.66s |
100% |
96% |
|
mistral |
3.41s |
75% |
80% |
|
opendataloader |
1.81s |
0% |
0% |
|
markitdown |
0.03s |
0% |
0% |
|
这一组的意义在于,它把“公式 PDF”这个词又拆开了一层。
以前我会本能地把公式问题看成一个问题。现在更觉得,至少得分两类:
-
印刷公式混在正文里,这是 mistral的强项 -
手写公式或截图公式,本质上更接近 mathpix的战场
-
原始图片:
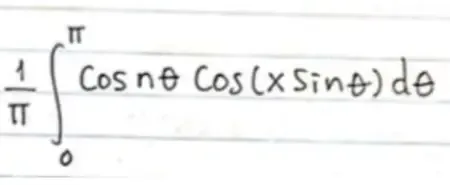
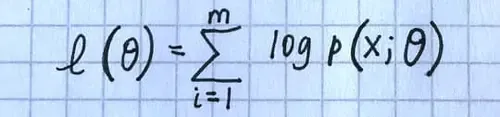
-
转成 Markdown 后的样子:
$$\frac{1}{\pi} \int _ {0} ^ {\pi} \cos n \theta \cos (x \sin \theta) d \theta$$$$\ell(\theta)=\sum _ {i=1} ^ {m} \log p(x ; \theta)$$
-
Markdown 显示出来的样子:
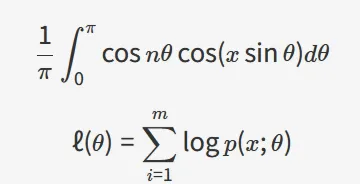
这类样本里,mathpix 的优势很直接:它不是把页面“看起来整理了一下”,而是真的把公式认出来了。
所以结论是:
-
普通文本型 PDF:想最快先试,用 markitdown -
普通文本型 PDF:想本地默认更稳,用 opendataloader -
普通文本型 PDF:接受 API、想少折腾,用 mistral -
印刷公式型 PDF:直接上 mistral -
手写公式型 PDF:直接上 mathpix
再多补一条:
-
可以拿大将 opendataloader先开路,如果结果里面出现很多图片,直接重跑mistral或mathpix
doc_to_md 真正沉淀下来的,是这套中间判断
通过这个项目,知道了
-
什么样的 PDF 该走哪条路 -
哪些结果其实只是“结构还行” -
哪些结果已经够进入 AI 问答和检索 -
哪些情况不该继续后处理,而该直接换引擎
我做了半天,就蒸馏出这几句话,变成AI agent的技能,然后这件事就可以被AI替代了….
下一篇就继续往前走
但文档转出来,还不是终点。
真正难的地方马上就来了:这些 Markdown 一旦进了AI问答系统,公式、引用和前端渲染还会在哪些地方继续坏掉。
下一篇进入 偿二代AI问答系统 这种真实项目里,看看“能转出来”和“真能上线”之间,到底还隔着什么。
相关项目:
– https://github.com/ferryhe/doc_to_md
系列导航:前文:第一篇:平生不识 Markdown,用遍 AI 也枉然下一篇预告:第三篇:从偿二代AI问答系统,讲什么样的AI能说会道
编辑:赵一衡
—————————————-
北京大学精算校友们本着“共商、共建和共享”的原则,旨在发挥母校专业基础雄厚、跨学科合作深入、学术自由氛围浓厚和创新意识强烈等优势,打造成为各位校友传播精算职业精神、交流从业经验和研讨精算前沿技术的永久平台,共同促进我国精算事业的长远发展。