 夜雨聆风
夜雨聆风





AI反洗钱(四)监控模型:从规则到智能
一、规则引擎:不可替代的基线
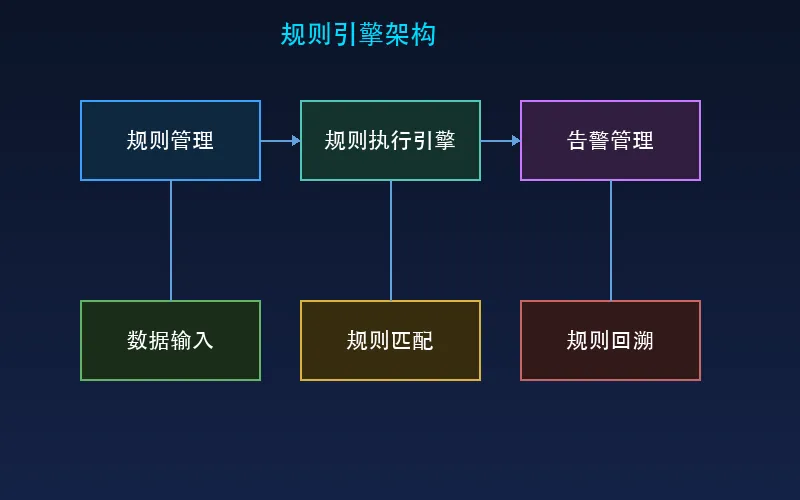
1.1 规则引擎的架构
-
单笔交易金额 > 50万元人民币 -
24小时内同一账户现金存取累计 > 20万元 -
转账对手方在制裁名单中 -
新开户后72小时内发生大额跨境转账
-
规则管理模块: 规则的CRUD、版本管理、启停控制 -
规则执行引擎: 实时/批量模式下的规则匹配 -
告警管理模块: 告警生成、去重、升级、关闭
1.2 规则引擎的优势
1.3 规则引擎的局限
-
规则膨胀: 随着时间推移,规则数量持续增长。部分国际大型银行的规则库已超过3000条,规则之间的冲突和冗余难以管理 -
阈值困境: 阈值设得太高会漏报,设得太低则误报爆炸。单一阈值无法适应不同客户群体的正常行为差异 -
模式盲区: 规则只能检测预设模式,无法发现未知的新型洗钱手法 -
缺乏关联: 每条规则独立评估单笔或少量交易,无法捕捉跨账户、跨时间的复杂关联模式
1.4 规则引擎不会被淘汰
-
规则引擎处理明确的、监管要求的检测场景(如大额交易报告阈值) -
AI模型处理复杂的、需要模式识别的场景 -
两者的输出可以融合,形成更全面的监控能力
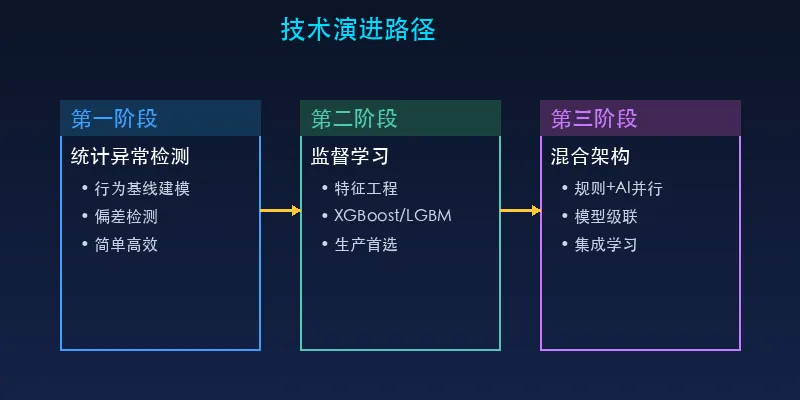
二、从规则到模型:技术演进路径
2.1 第一阶段:统计异常检测
2.2 第二阶段:监督学习模型
-
客户风险评级 -
客户年龄、开户时长 -
历史可疑报告次数 -
行业分类、地区分类
-
交易金额(绝对值、相对值) -
交易时间(时段、星期几、节假日标志) -
交易频率(日内、周内、月内) -
交易对手方特征(是否为高风险地区、是否为新对手方)
-
滚动7天/30天/90天的交易金额统计(均值、标准差、最大值) -
交易模式变化率(近期行为与历史基线的偏差) -
跨境交易占比 -
现金交易占比
-
交易对手方数量 -
资金流入流出比 -
网络中心度指标 -
社区归属(是否与已知高风险社区关联)
-
特征的数量不是越多越好。冗余特征会增加过拟合风险和计算开销 -
特征的可解释性很重要。调查人员需要理解”为什么这笔交易被标记” -
时间窗口的选择需要平衡灵敏度(窗口越小越敏感)和稳定性(窗口越大越稳定) -
类别不平衡是常态。正样本(洗钱)比例可能低于万分之一,需要专门的采样和评估策略
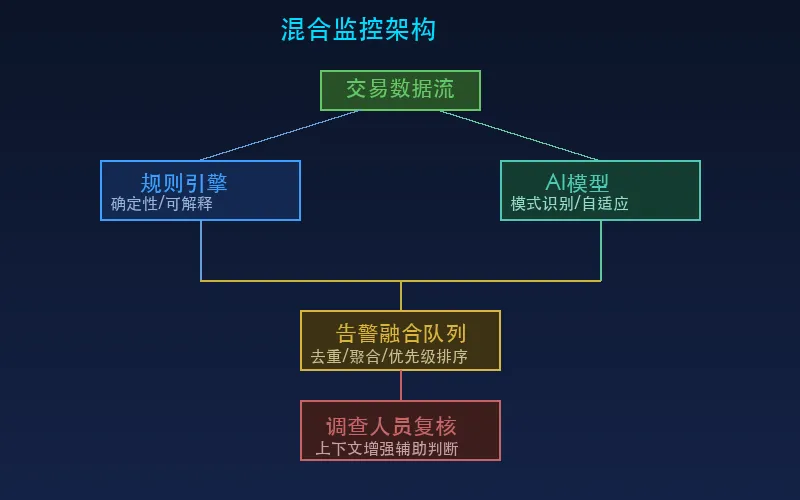
2.3 第三阶段:混合架构
-
规则引擎和AI模型同时运行 -
两者的预警进入统一的告警队列 -
调查人员根据告警来源和详情决定处理优先级
-
第一层: 轻量级模型(如逻辑回归)快速筛选,过滤掉大部分明显正常的交易 -
第二层: 复杂模型(如XGBoost)对第一层输出的候选进行精细评分 -
第三层: 人工复核(针对高评分交易)
-
多个模型(XGBoost、LightGBM、随机森林等)分别评分 -
加权融合或Stacking产生最终评分
三、模型选型的实战考量
3.1 树模型仍是生产首选
-
处理混合特征: 可以同时处理数值型、类别型特征 -
缺失值容忍: 对缺失数据有较好的鲁棒性 -
训练效率: 在百万级样本上训练通常在分钟级 -
可解释性: 通过SHAP值可以提供特征重要性分析 -
成熟度: 大量工程实践和工具链支持
3.2 图模型(GNN)的定位
-
规则引擎能看到”账户A向账户B转了50万”,但看不到”账户A→B→C→D→E→F形成了一个6跳的闭环交易链” -
树模型能对”账户A的单笔交易特征”评分,但无法感知”账户A与12个高风险账户形成了紧密的资金社区” -
GNN能同时利用节点属性和网络结构,在图中发现这些隐藏模式
-
图的构建和维护成本高(亿级节点和边的图存储和更新) -
GNN的实时推理延迟(通常高于树模型) -
GNN的可解释性较差(调查人员难以理解”为什么节点X被标记”) -
缺乏成熟的工程框架和生产级部署经验
3.3 深度学习的适用场景
-
AML数据的结构化程度较高,深度学习在非结构化数据上的优势无法充分发挥 -
深度学习的训练数据需求量大,而AML正样本稀缺,且可解释性不如树模型和GNN
四、阈值优化与误报控制
4.1 阈值选择的核心矛盾
4.2 实用的阈值优化方法
-
使用过去N个月的数据,计算不同阈值下的精确率和召回率 -
绘制Precision-Recall曲线,选择曲线的”拐点”作为初始阈值 -
考虑调查团队的产能:如果每月只能处理1000条预警,阈值应确保预警量在产能范围内
-
在生产环境中并行运行新旧两个阈值 -
对比新阈值下的告警质量和调查转化率 -
确认效果后再全面切换
-
不同风险等级的客户使用不同的阈值 -
高风险客户的阈值更低(更敏感) -
低风险客户的阈值更高(减少误报)
-
基于客户历史行为动态调整阈值(而非全局统一阈值) -
考虑季节性因素(年末交易量通常增大) -
定期(如季度)重新校准阈值
4.3 误报控制的系统性方法
五、模型运维:被忽视的战场
5.1 概念漂移
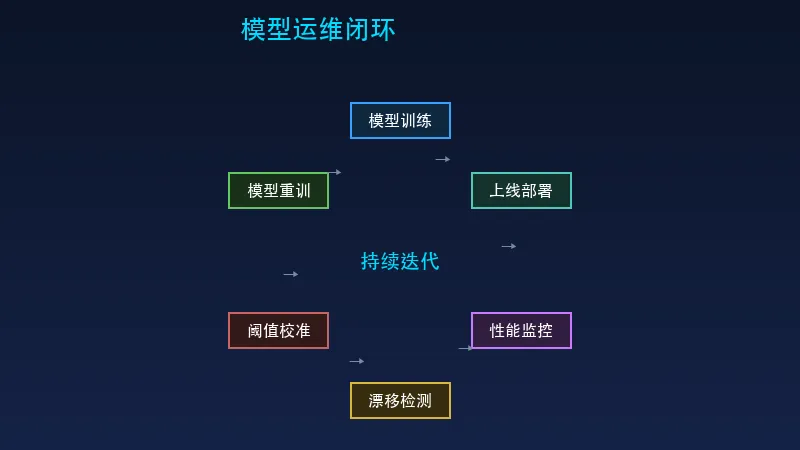
5.2 特征漂移
-
监控关键特征的数据分布(如日均交易金额的均值是否显著变化) -
建立数据质量监控面板 -
定期评估特征的有效性,淘汰失效特征
5.3 模型验证
-
反向测试(Backtesting):在历史数据上验证模型效果 -
挑战测试(Champion-Challenger):新旧模型并行运行,对比效果 -
基准测试(Benchmarking):与行业基准或监管期望进行对比