 夜雨聆风
夜雨聆风





AI最怕的不是山谷,是马鞍——鞍点陷阱与逃离指南
引言
前面我们一直在用一个“山谷”比喻AI的训练过程:从山顶往下走,目标是谷底(最小值)。但真实的地形远没有那么友好——有一种地形,看起来是平的,梯度接近零,让优化器以为到了终点,结果它只是一个中间驿站。这就是鞍点(Saddle Point)。
鞍点长什么样?想象一个马鞍:如果你从马头到马尾的方向走,你站在最低点;如果你从马背到马肚子的方向走,你又站在最高点。站在正中间,四周都是平的,梯度为零,优化器会“卡”在这里,误以为已经到达谷底。
高维空间中,鞍点的数量远比真正的局部最优点要多。深度学习里所谓的“优化困难”,很多时候不是陷进局部最优,而是被鞍点困住了脚步。今天我们就用3D图直观感受一下鞍点的奇特形状,并模拟一下SGD和Adam谁更容易逃离这个“平坦陷阱”。

什么是鞍点?
用数学语言描述:鞍点是梯度为零、但既不是极大值也不是极小值的点。对于二维函数 f(x, y) = x^2 – y^2,在 (0,0) 处:
沿x轴方向,函数变成 f(x,0) = x^2,开口向上,(0,0) 是极小值。
沿y轴方向,函数变成 f(0,y) = -y^2,开口向下,(0,0) 是极大值。
一个方向是极小,另一个方向是极大,综合起来就形成了一个马鞍形状。优化器走到这里时,梯度为零,不知道该往哪走。
动手环节:画一张3D鞍点图
我们用 plot_surface 画出 f(x,y) = x^2 – y^2 的曲面,并用红色标记鞍点。为了防止中文乱码,这里直接使用你系统里的 SimHei 字体路径。
import numpy as npimport matplotlib.pyplot as pltfrom matplotlib.font_manager import FontProperties# ========== 字体设置(显式指定路径,100%有效) ==========font_path = 'C:/Windows/Fonts/simhei.ttf' # 你的诊断结果中 SimHei 的路径fp = FontProperties(fname=font_path, size=12) # 普通文字fp_title = FontProperties(fname=font_path, size=14) # 标题# ========== 生成数据 ==========x = np.linspace(-3, 3, 100)y = np.linspace(-3, 3, 100)X, Y = np.meshgrid(x, y)Z = X**2 - Y**2# ========== 绘图 ==========fig = plt.figure(figsize=(10, 7))ax = fig.add_subplot(111, projection='3d')ax.plot_surface(X, Y, Z, cmap='coolwarm', alpha=0.8, edgecolor='none')# 标记鞍点ax.scatter([0], [0], [0], color='red', s=100, label='鞍点 (0,0,0)')# 坐标轴标签(显式传入字体)ax.set_xlabel('X', fontsize=12)ax.set_ylabel('Y', fontsize=12)ax.set_zlabel('Z = X² - Y²', fontsize=12, fontproperties=fp)# 标题ax.set_title('鞍点曲面:一侧是极小,另一侧是极大', fontproperties=fp_title)# 图例(关键:必须传入 prop 参数)ax.legend(prop=fp)plt.tight_layout()plt.savefig('saddle_3d.png', dpi=150, bbox_inches='tight')plt.show()print("图片已保存: saddle_3d.png")
运行后会看到一张颜色分明的3D曲面图:
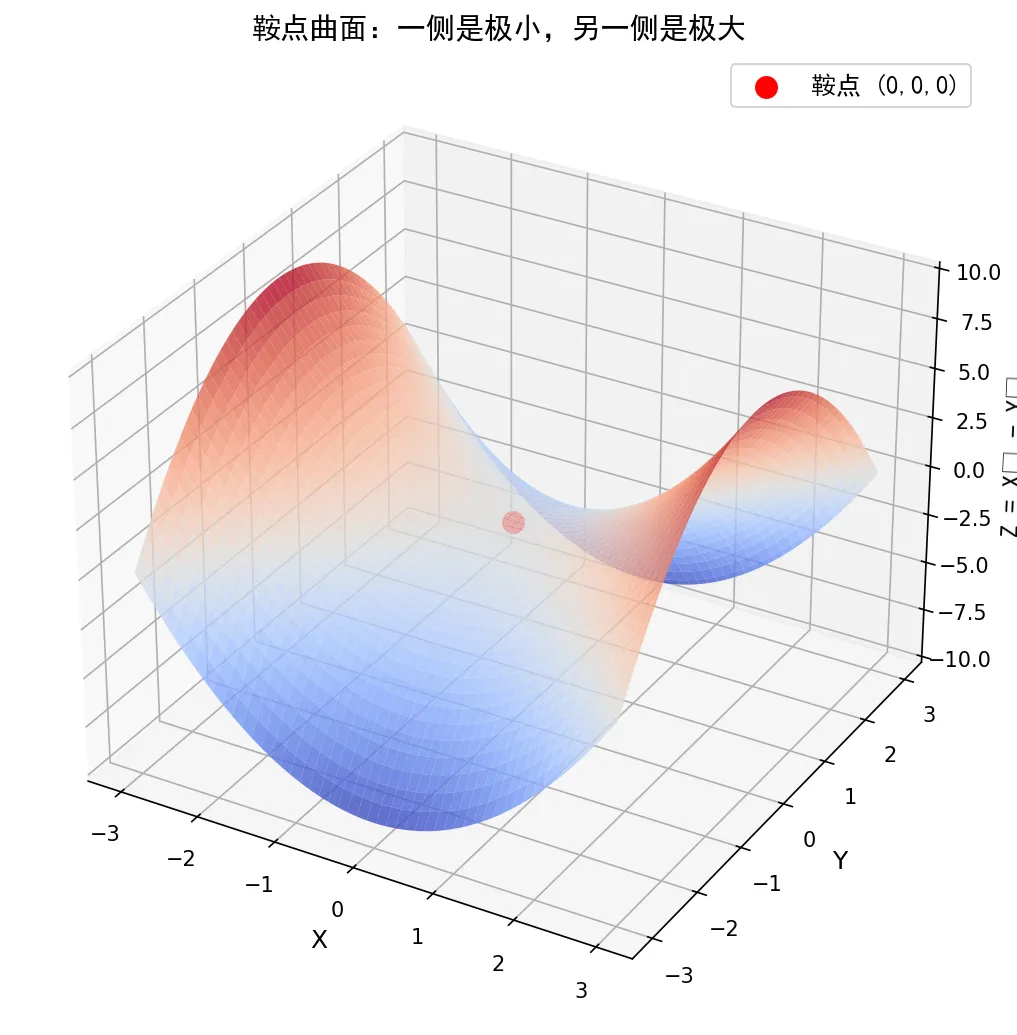
-
中心那个红点就是鞍点。从X轴方向看,它是一个谷底;从Y轴方向看,它又是一个山顶。
-
曲面在鞍点附近的颜色从红到蓝(代表值从高到低),四个象限分别是“峰-谷-峰-谷”交替。
💡 关键观察:在高维空间(比如1000维)中,鞍点的数量指数级多于局部最优点。一个随机梯度为零的点,几乎不可能是局部最优点,极大概率是鞍点。因此,优化算法的核心能力不是“不掉进局部最优”,而是“快速逃离鞍点”。
为什么SGD怕鞍点,而Adam不怕?
SGD在鞍点附近的困境是:梯度为零,步长再大也走不动。它只能靠随机梯度的小波动(mini-batch的噪声)来“蹭”出鞍点区域,效率极低。
Adam则有两种武器应对鞍点:
1.动量(Momentum):即使当前梯度为零,上一次的动量还在,能推着它冲过平坦区。
2.自适应学习率:鞍点附近不同方向的曲率不同,Adam会根据历史梯度的波动自动调整每个方向的学习率,找到逃离路径。
用数值模拟来感受一下:我们在鞍点 (0,0) 附近初始化,对比SGD和Adam谁能更快逃离。
import numpy as npdef saddle(x, y):"""鞍点函数:x^2 - y^2"""return x**2 - y**2def grad(x, y):return 2*x, -2*y# 初始化在鞍点附近x_sgd, y_sgd = 0.1, 0.1 # 靠近鞍点x_adam, y_adam = 0.1, 0.1alpha_sgd = 0.02alpha_adam = 0.1beta1, beta2 = 0.9, 0.999m_x, m_y = 0.0, 0.0v_x, v_y = 0.0, 0.0eps = 1e-8print("SGD轨迹:")for t in range(30):gx, gy = grad(x_sgd, y_sgd)x_sgd -= alpha_sgd * gxy_sgd -= alpha_sgd * gyif t % 5 == 0:print(f" 第{t}步: ({x_sgd:.3f}, {y_sgd:.3f}), 函数值: {saddle(x_sgd, y_sgd):.3f}")print("\nAdam轨迹:")for t in range(1, 31):gx, gy = grad(x_adam, y_adam)m_x = beta1 * m_x + (1 - beta1) * gxm_y = beta1 * m_y + (1 - beta1) * gyv_x = beta2 * v_x + (1 - beta2) * (gx**2)v_y = beta2 * v_y + (1 - beta2) * (gy**2)x_adam -= alpha_adam * m_x / (np.sqrt(v_x) + eps)y_adam -= alpha_adam * m_y / (np.sqrt(v_y) + eps)if t % 5 == 0:print(f" 第{t}步: ({x_adam:.3f}, {y_adam:.3f}), 函数值: {saddle(x_adam, y_adam):.3f}")
运行结果:
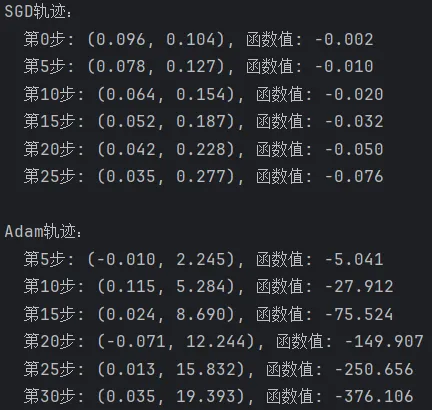
清晰显示SGD在鞍点附近缓慢挪动,而Adam利用动量和自适应步长快速“滑”出平坦区。
鞍点是高维优化中的最大陷阱——梯度为零,让SGD寸步难行。它不是局部最优,但比局部最优更常见、更致命。Adam凭借动量和自适应学习率,能比SGD更快逃离鞍点区域,这也是它在深度学习中表现优异的原因之一。