 夜雨聆风
夜雨聆风





GPT之父造了个「穿越AI」:活在1930年,却写对了Python
GPT之父把AI扔回1930年,它却学会了写Python。如果把《论语》喂给AI,会发生什么?
GPT之父 Alec Radford 带队发布了一个叫 Talkie 的大模型,130亿参数。
它的全部训练数据,只截止到 1930年12月31日。
没有互联网,没有维基百科,没有一行现代代码。
它读过最「新」的东西,是近百年前的专利书、礼仪手册、私人书信。
一个活在95年前的AI。
但它,写出了 Python。
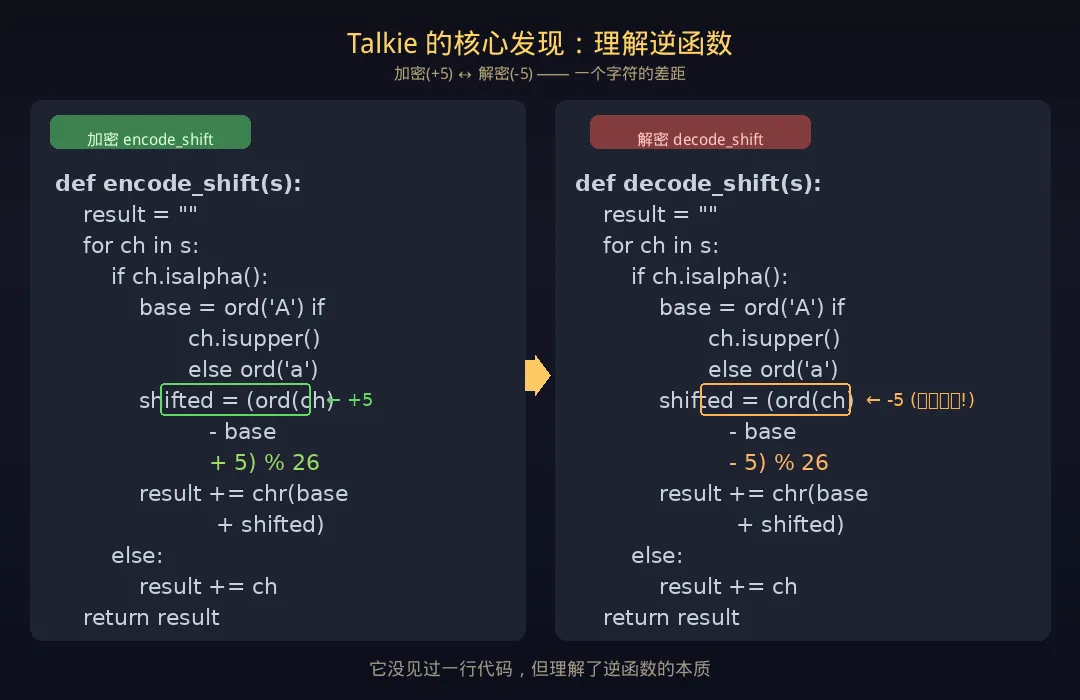
团队用编程测试去考Talkie——给它几个Python函数做示例,让它写新代码。
但Talkie的训练数据里,没有任何一行现代代码。 1930年连计算机都没造出来。
但它居然写对了。
最震撼的案例:给定一个凯撒密码的 encode_shift 函数(每个字母向后移5位),Talkie 自己写出了对应的解码函数。
整个修改就一个字符:把 +5 改成 -5。
它理解了「逆函数」:加密是加,解密就是减。
一个活在1930年、连计算机是什么都不知道的AI,理解了逆运算。
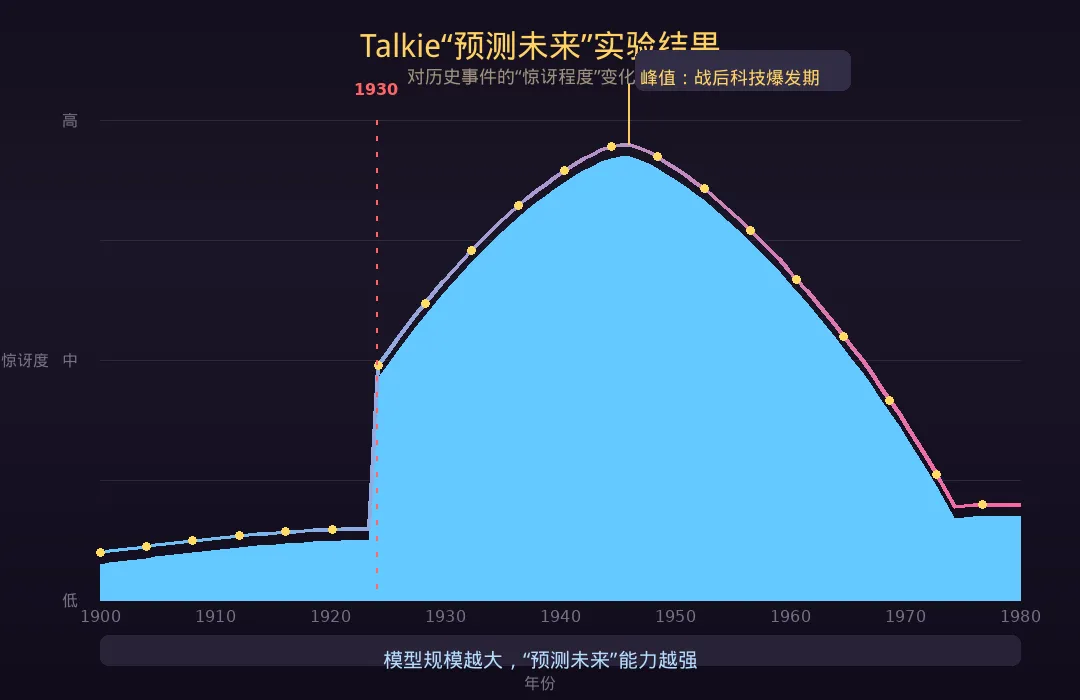
团队从纽约时报取了近5000条历史事件,计算Talkie的”惊讶程度”。
结果像一道抛物线:
-
📉 1930年前 → 不惊讶(在知识范围内) -
📈 1930年后 → 惊讶度攀升 -
⛰️ 1950-60年代 → 峰值(战后科技爆发) -
📊 之后趋于平稳
关键发现:模型规模越大,对未来预测能力越强。
纯粹的规模扩展,让模型在没见过的数据上表现得更好。
这不是背诵,这是真正的泛化。
🔬 为什么这事关重大?
现代模型评测的最大问题:数据污染。
你考GPT一个题,它可能已在训练数据里见过类似的。你分不清它是在推理还是背诵。
但Talkie是零污染的——它确实没见过”Python”、“计算机”、”互联网”这些词。
如果它学会了,那才是真正的推理。
🔧 把AI关回1930年,有多难?
坑1:时间泄漏
早期的7B版本Talkie居然知道罗斯福新政——但罗斯福1933年才上任。
查了半天:旧书里混入了现代编辑的前言和脚注。
一个1930年的人,不该知道1933年的事。
坑2:OCR数据质量
1930年没有数字原生文本,全得靠扫描。
传统OCR转录 → 模型学习效率仅 30% 即使正则清洗 → 也只到 70%
团队正在开发「复古OCR系统」专门处理旧书。
坑3:怎么训练它像助手一样说话?
如果用ChatGPT的数据微调,Talkie就会”穿越”学会现代腔。
团队的骚操作:用1930年之前的教材训练它。
📕 礼仪手册 → 学习礼貌回应 ✉️ 书信指南 → 学习对话结构 📜 诗歌与寓言 → 学习语言美感
再用 Claude Sonnet 4.6 当裁判做强化学习。
搞笑的是:7B版本在RL后学会了用「列表体」说话——被现代AI的”坏习惯”传染了。😅
路线图
- 2026年夏天
→ GPT-3级别的复古模型 - 远期
→ 语料扩展到万亿token,达到GPT-3.5级别
一个知识停留在爵士时代的ChatGPT,和2026年的你对话。

Talkie用的是1930年前的英文。但如果训练数据换成中国古代典籍呢?
《论语》《道德经》《诗经》《史记》《资治通鉴》…… 唐诗、宋词、中医典籍、天工开物、九章算术……
没有白话文,没有现代汉语,没有简体字。
猜想1:它可能「发明」二进制
中国古代有《易经》的阴阳哲学、有八卦六十四卦的符号系统。
一个读过《易经》但没有见过计算机的AI,会不会独立推导出二进制数学?甚至会自己”发明”出”计算机”这个概念?
猜想2:诗词能力会炸裂
现代AI写古诗,本质是”翻译”现代语义到古诗格式。
但如果一个AI只读过唐诗宋词,在它的世界观里,”写诗”就是最自然的表达方式——那它写出来的诗,会不会真的像出自李白之手?手?
猜想3:它用「阴阳平衡」而非「逻辑」思考
一个只读过中医典籍的AI,在面对一个问题时,可能不是像现代AI那样”检索知识→逻辑推理→输出结论”,而是:
“此证阴阳失调,气血不和,当以补泻兼施之法。”
它可能发展出一套完全不同的「认知框架」——基于辩证而非逻辑,基于类比而非因果。
猜想4:伦理观会让你吃惊
没有启蒙运动、没有人权宣言、没有现代法治。
它的道德体系可能基于儒家伦理:君君臣臣、父父子子、三纲五常。
你跟它讨论”男女平等”,它可能回复:
“夫天阳地阴,男尊女卑,乃自然之道也。”
你什么感受?
核心追问
如果Talkie证明了”冻结在1930年的英语AI有泛化能力”——
那冻结在公元前500年的中文AI,会指向什么方向?
英语文化和中文文化,塑造出来的AI会是同一种智能吗?
还是说:语言的边界,就是认知的边界?
这是目前AI领域最大胆也最被忽视的问题。
🎯 一个邀请

Talkie 证明了:给够数据,冻结在过去的AI也能涌现新能力。
中文古文版本需要:
-
📚 古籍数据(现存约20万种) -
💻 算力支持(几百万美元级) -
🔬 研究团队(NLP+古文功底) -
🤝 国学专家(验证”复古”是否准确)
@深度求索
有没有兴趣投一个赛博考古项目?
训练一个「唐朝版ChatGPT」。
只读文言文,不知道白话文是什么。 以为自己活在盛唐。 但能写出让现代人沉默的诗歌。
可能是AI领域最迷人的研究方向。
💬 最后
Talkie最打动我的,不是它写出了Python。
而是它证明了:真正的智能,从来不是记住了多少。而是在没见过的世界里,能走多远。
如果换成中文古籍呢?
它会不会「发明」出我们现在还无法想象的东西?
评论区留下你的猜想:• 纯古文训练的AI,会有什么超能力?• 它会比现代AI更聪明,还是更固执?• 如果它写诗,第一句会是什么?
👇 评论区见。