 夜雨聆风
夜雨聆风





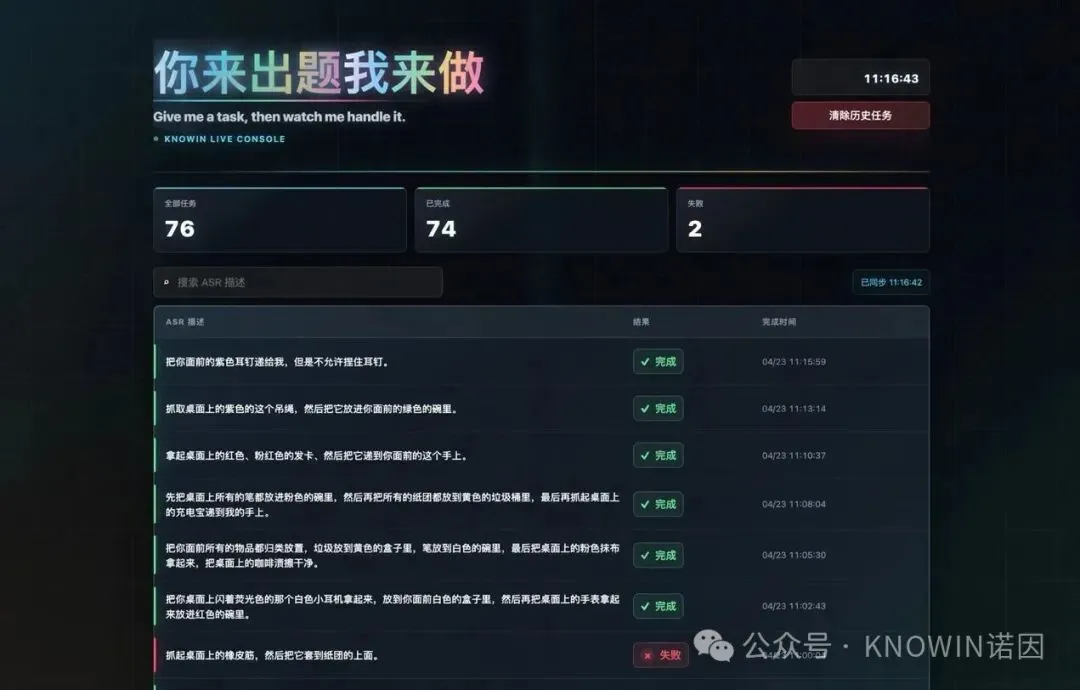
源码律动被投企业「诺因智能」原型机亮相 FAIR plus,线下交互式任务零样本泛化成功率达98%

2026年4月22日,FAIR plus机器人全产业链接会在深圳会展中心(福田)正式开幕。本届展会定位为世界级机器人开发制造技术大会,聚焦机器人全产业链技术与开发资源,通过学术交流、技术标准研讨、供需对接等形式,为人工智能与机器人领域技术人员及场景应用方搭建线下交流合作平台,推动机器人产业智能化升级与整体能力建设。
诺因携产品原型机线下亮相FAIR plus,现场展示任意光照、任意背景下的复杂操作能力,Demo场地人气高涨:

基本上一分钟左右叠完一件衣服,有人把衣角藏起来,小诺依然可以操作:
(以下视频均为实拍1倍速)
有多难?我们看一看桌面反光视角,人影变化、视频播放变化、闪光灯变化,地狱难度的干扰模式下,小诺依然可以完成任务:
更有观众现场掏出包里的衣服出题:

面对毫无预设的衣物类型,小诺凭借强大的泛化能力,完美通关!

除了叠衣技能,诺因机器人的桌面收纳能力同样让人眼前一亮!搭载自研具身大模型的小诺,能精准理解自然语音指令,结合视觉识别完成长链条收纳操作。
展会现场 “你来出题我来做” 互动环节高潮迭起。观众掏出耳机、发卡,小诺零样本(zero-shot)适配,精准收纳,任务完成率约98%。
接到 “把车钥匙递到我手上” 的指令,小诺思考后精准送达:
面对 “只擦拭两支笔之间的桌面” 的方位要求,轻松搞定空间定位:
为什么能实现 “任意指令的完美操作”?
主要基于两大核心技术支撑:
一是具身认知大模型基座 KnowinBrain —— 依托 1-5Hz 执行反馈机制,大模型可以做到自主思考,动态评估物理状态、自主反思修正,打通感知 – 规划 – 执行闭环。
二是生成式动作编解码器 Action Tokenizer,基于 KnowinDream 生成的视频数据预训练,掌握泛化动作表征能力,确保未知任务和环境下的平滑操作;而且可以做到完全对齐到语义和视觉上,真的做到“看到什么听到什么就做什么”。
诺因抛弃了模仿策略大模型的技术路线,在任务的执行过程中,先去理解真实世界,再去生成想要的动作,而不仅仅是单纯的模仿!
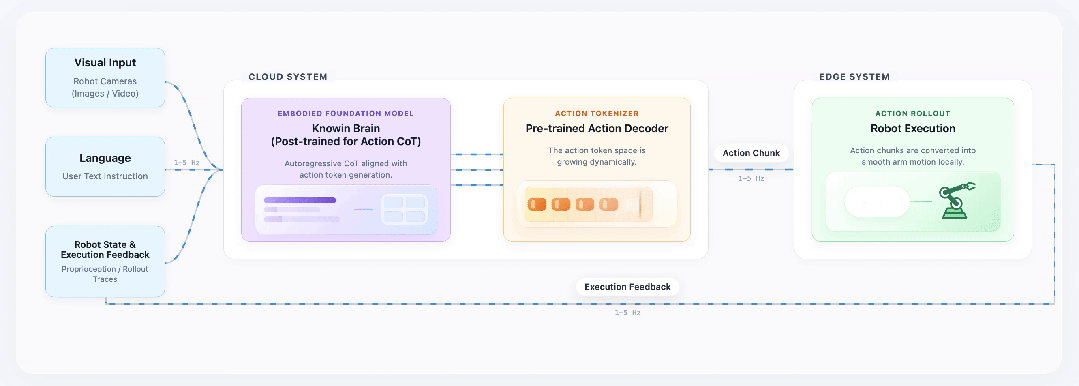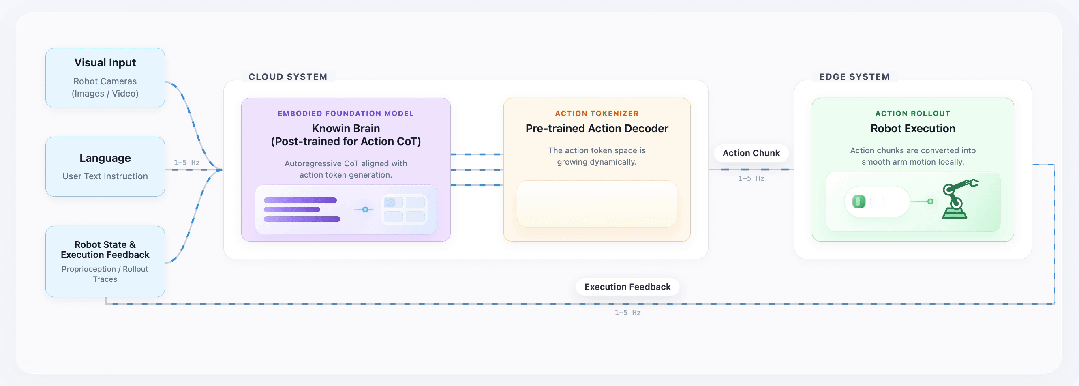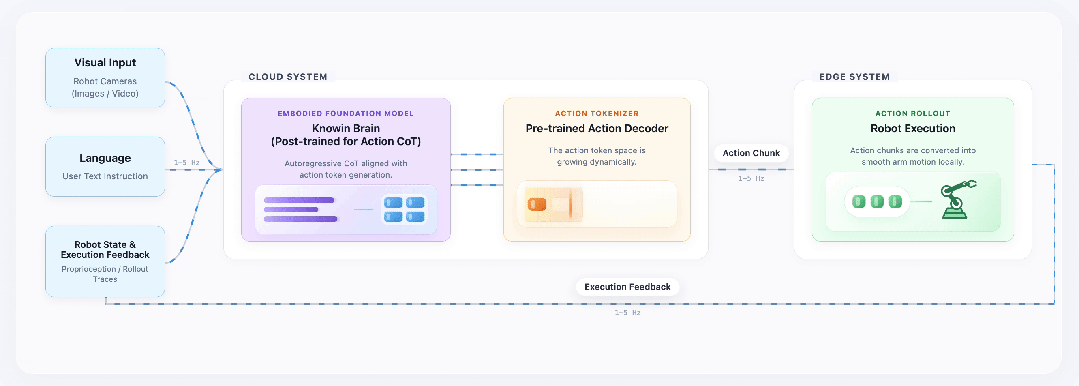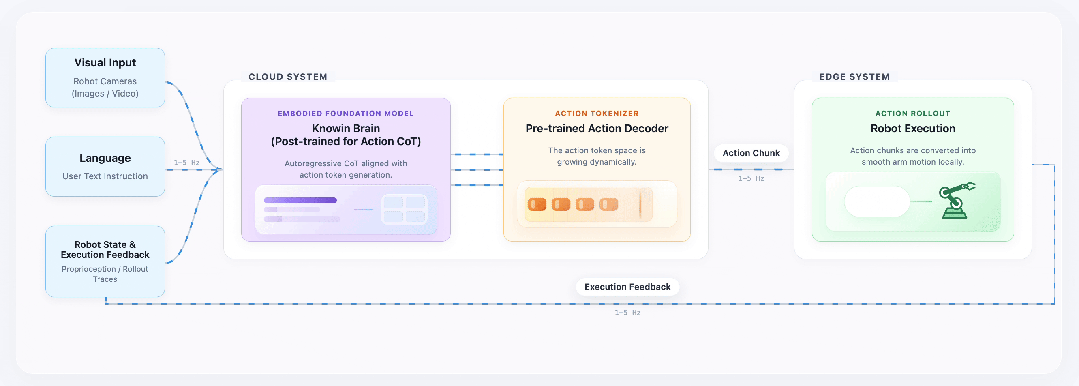
展会现场人气高涨,市场对家庭具身智能的期待清晰可见。
诺因以自研KnowinDream合成数据引擎突破家庭场景数据泛化瓶颈,依托全栈自研的KnowinBrain和交互反馈技术,加速 L3 级自主家务机器人实用化落地。
从实验室走向线下展会与大家互动,是泛化能力被成功验证的关键里程碑;未来我们将持续深耕家庭全场景,致力于让智能机器人走进每一个家庭。

