 夜雨聆风
夜雨聆风





DeepSeek最新发布,AI都开始指指点点了?
终于放假了。
DeepSeek 识图模式的灰度没等到,等来了技术报告。
说真的,我看见这论文标题的时候,第一反应是想笑。
《Thinking with Visual Primitives》,视觉基元思考。
听起来像是某个 PPT 大师,在汇报会上憋出来的玄学概念。
配上一张螺旋上升的箭头图,老板看了直点头,员工听完一头雾水。
但当我把全文啃完之后,我大脑宕机了三秒。
并非因为它多复杂,是因为它简单到离谱,简单到让我怀疑过去这些年大家都在干什么。
DeepSeek 这篇新论文,说白了就是教 AI 学会一件事。
想问题的时候,能不能用手指着想?
就这么简单。
但就是这么个事儿,让一个基于 DeepSeek-V4-Flash 开发,总参数 284B,激活只有 13B 的小模型。
在迷宫导航这种任务上,把 GPT-5.4,Claude-Sonnet-4.6,Gemini-3-Flash 全部按在地上摩擦。
所以,即使刚放假,也要先来跟大家第一时间分享。
1
你有没有这种经历。
晚上跟女朋友窝在沙发上,她翻出一张小学毕业照给你看,让你猜猜哪个是她。
你凑近屏幕,五排小孩儿,乌泱泱四五十个人。
你说,第二排中间哪个?
她说,中间哪个?
你说,笑得最甜的。
她说,我那时候不爱笑,你还是指给我看吧。
你手指头一戳,双方对齐了。
但是吧,AI 没有手,思考的时候全靠自己在脑子里默念。
用语言描述“这个”,“那个”,“另外那个”的时候,很快就在自己的推理链里崩溃了。
DeepSeek 的论文给这个现象起了一个名字,叫 Reference Gap,指认鸿沟。
之前的多模态大模型卷的是更高的分辨率,更细的图像切片。
把图像切成几百块,让模型把每根毛都看清楚。
但卷到最后,大家发现一个诡异的现象,模型明明看清楚了每根毛,回答问题还是错。
为啥呢?
因为看见并不等于推理,中间隔着的就是指认鸿沟。
模型不是没看见。
是看见了不会说,说了也说不准,说准了也接不上下一句。
2
之前也有人尝试让 AI 一边看图一边画框,但都是当作事后检查用。
AI 先把答案在脑子里想好,最后再随手画个框。
DeepSeek 这次不一样,它让 AI 在思考答案的时候,就当场推理。
一边想,一边画框,一边打点。
画框本身,就是思考的一部分。
具体来说,你如果问 AI,这张图里有几只狗?
之前的 AI 内心戏是这样的。
我看到一只狗。然后那边还有一只。再过去那边好像也有……等等左边那只我数过没?算了再数一遍……前面好像数错了……DeepSeek 新模型内心戏是这样的。
找狗 → [box: 120, 340, 200, 420] → 找下一只 → [box: 450, 200, 530, 290] → 还有吗?→ [box: 700, 400, 810, 500] → 1+1+1=3。每一步思考,都带上了坐标。
语言负责想什么,坐标负责指哪个。
两种基元交织在一起,构成一段推理。
这就是论文最核心的概念,把视觉基元提升成思考的最小单位。
说人话,就是 AI 推理的最小单位除了词元,还可以是坐标。
抽掉坐标,指代就丢了。
DeepSeek 这次,是真的把坐标搬进了推理链里。
3
光说理论还是抽象,我们来看几个论文里实测的案例。
第一个,数球队合影。

一张足球队的合影,二十几个人挤在一起,让模型数有几个人。
DeepSeek 新模型扫描了整张图片,一口气画出了 25 个框,每个框框住一个人。
然后认真的做汇报。
前排地上坐着 4 个,中间一排坐着 9 个,后排站着 8 个,左边教练 2 个,右边教练 2 个,一共 25 个人。
论文里另一张黑白老照片,模型也直接框除了 29 个人,一个不漏。

还有这个把各种动漫手办放在一块,要求数出神奇宝贝数量的,一共 6 个。

甚至还有把吉娃娃和蓝莓松饼放在一块,让模型数有几只吉娃娃。
两者长得离谱的像,别说 AI 了,人不仔细看都容易搞混了。

更狠的是这个,迷宫导航。
给模型一张蜂窝迷宫的图,让它从入口走到出口。

GPT-5.4,Claude-Sonnet-4.6,Gemini-3-Flash,所有顶级模型在这种任务上都卡在了 50% 上下,集体翻车。
为什么?
因为用纯语言的思维链,描述这种不规则的空间路径是反人类的。
DeepSeek 新模型在每个分叉点都标记了坐标,永远不会指代不清。
最后跑出了 66.9% 的准确率,比竞品模型高出 16 个百分点以上。
这说明,不是模型不够大,思考方式错了,再大的模型也救不了。
类似的例子,还有下面这种路径追踪的任务。

更有意思的,是下面这个中文案例。
给它一张咖啡机的照片,问我应该如何制作一杯美味的拿铁?

它一边思考,一边在图片上分别框出咖啡机,蒸汽棒,不锈钢牛奶壶,咖啡豆包装袋,拿铁按钮,陶瓷咖啡杯。
然后一步步告诉你,该如何正确操作。
视觉指认和世界知识,融合的非常自然。
4
关键数据还是要过一下。
下图的 Ours-284B-A13B 就是 DeepSeek 的新模型。
放在今天这堆万亿参数的庞然大物里,它是个小个子。
但它读图片的时候,要比所有大块头都省。
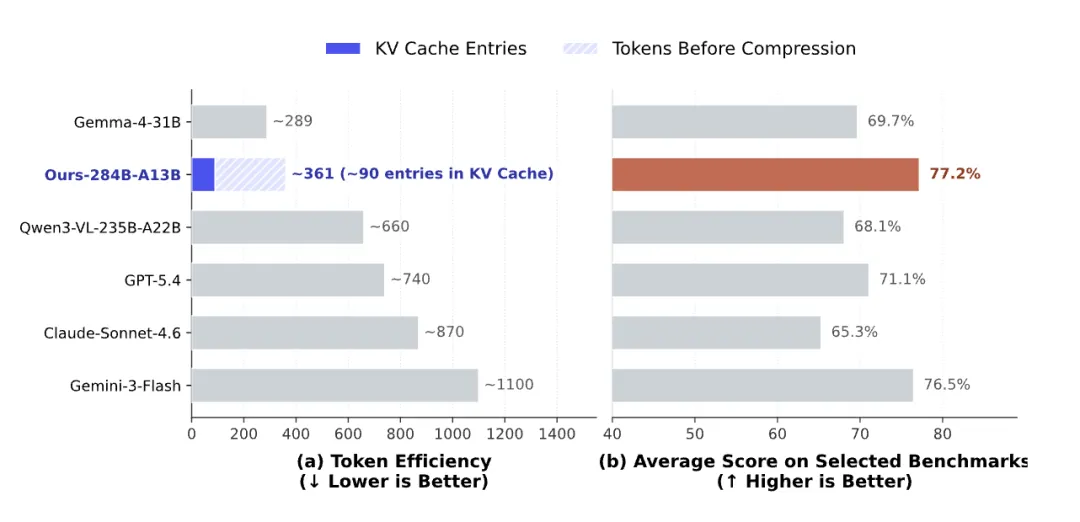
你给它一张正常分辨率的图片,它脑子里要存的草稿纸,大约不到同行的十分之一。
这种效率差距太离谱了,我是同行我看了都要流汗。
更离谱的是,效率省成这样,性能还是基本反超的。
平均下来,DeepSeek 新模型拿到 77.2%,全场最高。
再来看下面这张详情表。
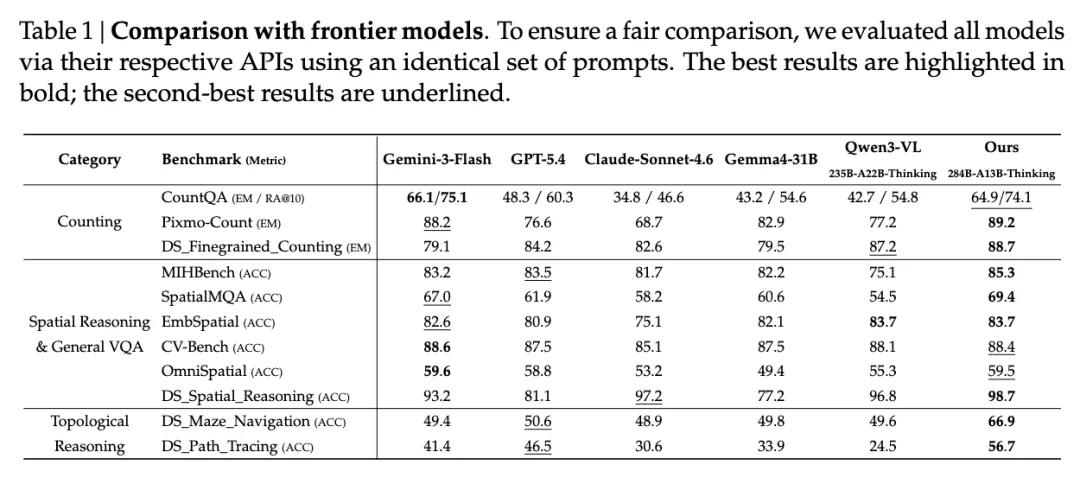
Ours 拿下了 8 项第一,3 项第二。
Gemini-3-Flash 在某几个特别考验看清细节的测试上,稍微略胜一点点。
但在那些考“看清之后能不能想明白”的任务上,比如最下方拓扑推理的两个任务中,DeepSeek 新模型 Ours 直接断层式的遥遥领先。
5
说完爽点,来说说论文中自己提到的几个短板。
第一个,图太挤的时候,它还是会画歪。
因为看不清楚,这个问题要跟现有的,能看得更清楚的技术结合起来解决。
第二个,你得明确叫它指,它才会指。
它现在还不会自己判断,这个问题需不需要边想边画。
理想状态就是让它自己分得清,适合的任务要主动调用指认的能力。
第三个,拓扑推理的任务还是有很大挑战。
在迷宫任务里虽然取得了亮眼的成绩,但还缺乏泛化能力,还不够通用。
后面,还有大把的工作要做。
好戏才刚刚开场。
尾声
写到这里,我突然想起一句话。
维特根斯坦说,我语言的边界,就是我世界的边界。
这句话被引用了无数次,但很少有人提及它的反面。
当你扩展了语言之外的表达手段,你就扩展了你的世界。
DeepSeek 论文里最后一句话是这样说的。
通向系统 2 多模态智能的路,不在于看到更多像素,而在于在语言和视觉之间,搭起一座精确而无歧义的指代桥梁。
我的直觉告诉我,这个方向是对的。
因为,它符合人类认知的过程。
当你穿越复杂迷宫或者要数清密集的物体时,你就是会自然的用手指指向它们。
这样不光能节省大脑的消耗,也会保持逻辑连贯性,防止出错。
婴儿在咿呀学语之前,不也是会伸出小小的指头来指的么?
DeepSeek 的新论文,让 AI 第一次伸出了那根手指。
后来的人们发现,通往 AGI 的那把钥匙。
可能一直就藏在我们的手指头上。
往期文章
既然你看到这里了,如果觉得不错,请帮我一键三连,转发给你的朋友,这真的对我很重要。
另外如果想第一时间收到推送,请将本公众号加个星标🌟
谢谢你看我的文章,祝你有财安康,我们下期见。