 夜雨聆风
夜雨聆风





本地跑AI模型总觉得慢?千赞推文揭底:问题根本不在显卡,在你自己堆上去的「包袱」!
一条获得近 1100 赞的推文,把本地模型圈最痛的真相摆上了台面——你的模型之所以慢,很可能跟显卡没关系,跟模型大小也没关系。真正拖后腿的,是你围着模型堆上去的那层东西:过长的系统提示、过多的工具定义、每轮都在变的上下文前缀。一位开发者甚至翻出了数据:Claude Code 的系统提示长达2.5 万 token,光一句默认的 “hello” 就要吃掉1.3 万 token。对本地小模型来说,这直接意味着五分之一的上下文窗口,还没开始干活就没了。
一句玩笑话,戳中了上千人
5 月 1 日凌晨,libGDX 作者、游戏引擎开发者 Mario Zechner 在 X 上发了一条看起来像玩笑的推文:
“turns out not killing the prefix cache all the time and not having a humongous set of tools and a massive system prompt is good for local model use. who’d have thunk.”
「事实证明,别老把 prefix cache 干掉,别带着一大堆工具和一个巨无霸系统提示,对本地模型挺好的。谁能想到呢。」
▲ Mario Zechner 的种子推文,6.6 万次浏览,近 1100 赞,875 收藏
这条推文附带了一张 Reddit 帖子的链接卡片,指向 r/LocalLLaMA 社区的一篇实战分享。发帖人说自己用PI Coding Agent + 本地 Qwen3.6 35B在 8GB 显存的笔记本上跑出了15-30 token/s的实际速度,而且是在做真实项目。

▲ r/LocalLLaMA 原帖:「用 PI Coding Agent 跑本地 Qwen3.6 35B,效果好到离谱」,407 赞,178 评论
关键来了——这位发帖人说真正改变体验的,跟换更大的模型无关,跟加更多显存也无关,靠的是他自己写了一个 plan-first skill,把 agent 的行为约束成”先规划再执行”,大幅减少了不必要的上下文膨胀。
Mario 转发这篇帖子的意思很明确:本地模型的性能瓶颈,经常跟模型本身没关系,真正拖后腿的是你套在模型外面的那层 agent 运行时壳子。
2.5 万 token 的系统提示,你猜是谁的?
评论区里,Redis 作者 antirez 扔出了一个让人瞬间清醒的数字:
“Yes. Claude Code system prompt is 25k tokens. Incredible.”
「Claude Code 的系统提示有 2.5 万 token。离谱。」
▲ antirez 的回复,1.8 万次浏览,106 赞
2.5 万 token 是什么概念?
对云端大模型来说,这主要意味着多花一点钱、多等几百毫秒。但对本地模型来说,这个数字的杀伤力完全不同:
-
预填充(prefill)时间直接拉长; -
上下文窗口被 “固定开销” 吃掉一大截; -
如果这段系统提示每轮都有变化,KV cache 复用直接归零。
紧接着,另一位开发者 alkimiadev 补了一刀:
“yeah just a default ‘hello’ in opencode is ~13k tokens. For a small model that could be like ~1/5th of their total context window”
「在 opencode 里光一个默认的 ‘hello’,上下文就接近 1.3 万 token。对小模型来说,这可能直接拿走总上下文窗口的五分之一。」
▲ alkimiadev:默认一句 hello 就要 13k token,小模型直接被吃掉 1/5 窗口
还没问问题,窗口就先没了五分之一。这已经不是”有点浪费”的问题,对 64K 上下文的本地小模型来说,这是生死线级别的。
一个动态时间戳,就能把你的缓存全部打碎
如果说系统提示太长只是”贵”,那接下来这个坑就是真正的隐形杀手了。
Sakura Yuki 在评论里写了一句话,戳中了无数本地模型用户最难排查的性能痛点:
“The amount of ‘slow inference’ complaints I’ve seen that just boil down to a dynamic timestamp in the system prompt thrashing the prefix cache on every turn is genuinely tragic.”
「我见过太多’推理好慢’的抱怨了,查到最后发现原因就是系统提示里一个动态时间戳,每一轮都把 prefix cache 打碎。真的令人悲哀。」
▲ Sakura Yuki:一个动态时间戳就能让每轮 cache 全部失效
这才是最阴的地方。很多 agent 框架喜欢在系统提示里自动注入当前时间、本轮编号、环境摘要、最近工具状态。开发者觉得自己只是”加了一行小信息”,但对推理引擎来说,前缀变了就是变了——哪怕只改了一个字符,整段 prefix cache 都可能失效。
这意味着每一轮对话,模型都得从头处理整段系统提示 + 工具定义 + 历史消息。你以为只是慢了一点点,实际上等于每轮都在冷启动。
工具越多,包袱越重
Joe Devon 的自嘲可能是整个讨论里画面感最强的一条:
“Uh oh. I was futzing around with some cool stuff and now I type pi and get: Loaded – 1 context file, 15 extensions, 5 skills, 17 prompt templates. What have I done?”
「完了。我刚才装了一堆好玩的东西,现在一打开 PI 就看到:已加载 1 个上下文文件、15 个扩展、5 个技能、17 个提示模板。我都干了什么?」
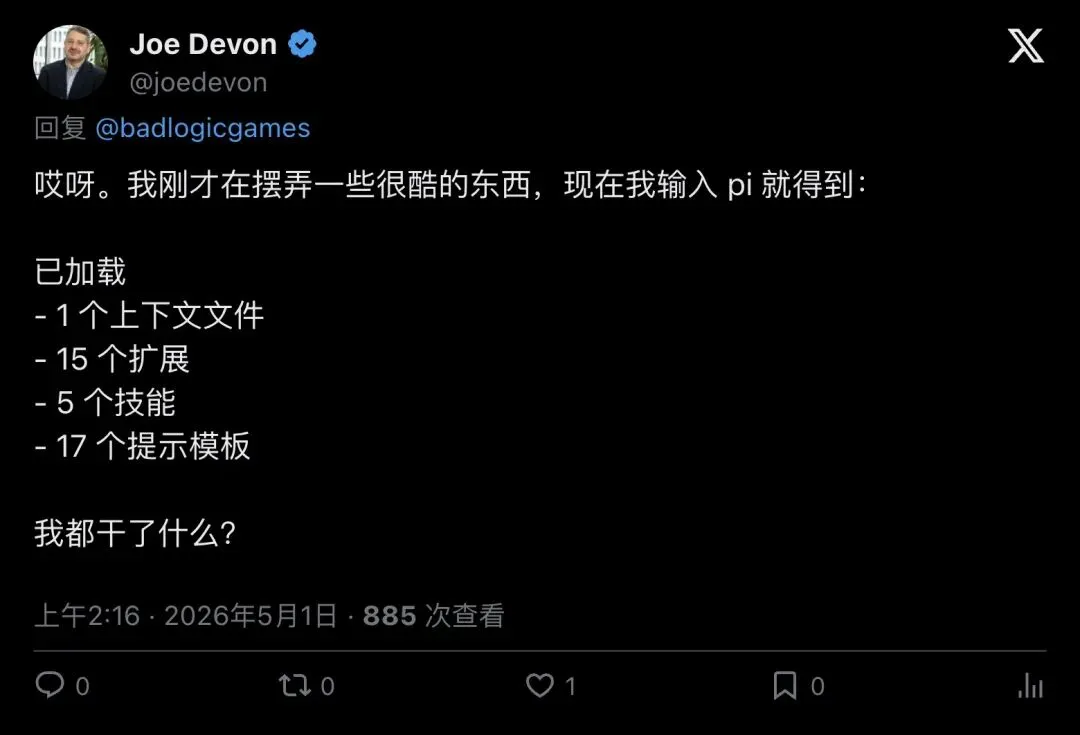
▲ Joe Devon 的自嘲:15 个扩展 + 5 个技能 + 17 个模板,agent 还没干活就先背上了一书包
这就是过去两年 agent 生态的缩影。每个扩展都很好用,每个 skill 都很酷,每个模板都有道理。但堆在一起会怎样?
对云端大模型来说:多花点钱,感知不明显。
对本地模型来说:所有工具定义都会被塞进前缀,前缀越长 prefill 越慢,而且一旦工具列表每轮有变动,cache 复用直接废掉。
Sherlock 用一句话做了最精准的总结:
“Local models are also very sensitive to context usage and throughput and prompt processing size, so having a smaller set of tools and prompts exponentiates.”
「本地模型对上下文使用量、吞吐量和提示处理大小极其敏感,所以精简工具集和提示词,带来的收益是指数级的。」
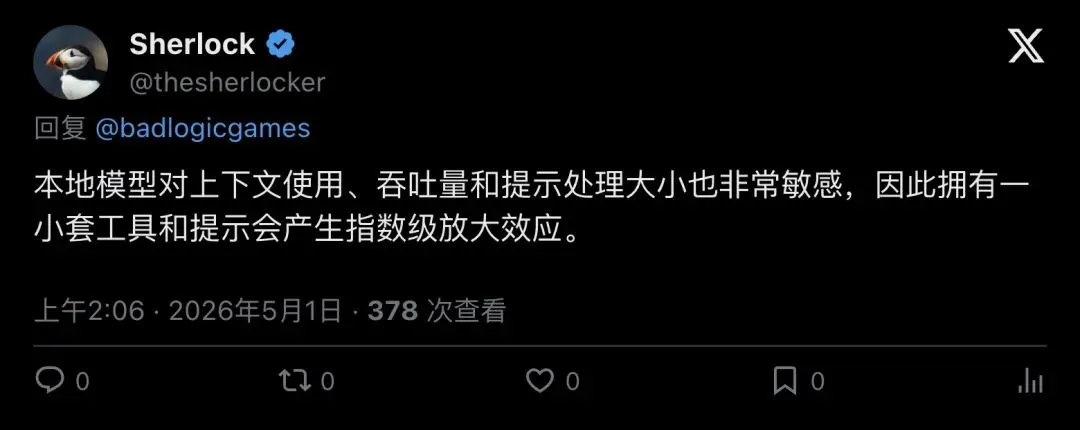
▲ Sherlock:精简工具和提示,对本地模型的收益是指数级的
注意这个词——指数级。砍掉的每一个不必要的工具,省下的都不仅仅是那几十个 token 的工具定义,还有因此带来的更稳定的前缀、更高的 cache 命中率、更短的 prefill 时间。
技术底层:Prefix Cache 到底是怎么回事
说了半天 prefix cache,它到底是个什么东西?
简单说:模型处理过的前缀部分,会把计算结果(KV cache)存下来。下一次请求如果前缀相同,就直接复用,不用重新算。
vLLM 官方文档里的原话:
“Prefix caching kv-cache blocks is a popular optimization in LLM inference to avoid redundant prompt computations.”
“we cache the kv-cache blocks of processed requests, and reuse these blocks when a new request comes in with the same prefix.”
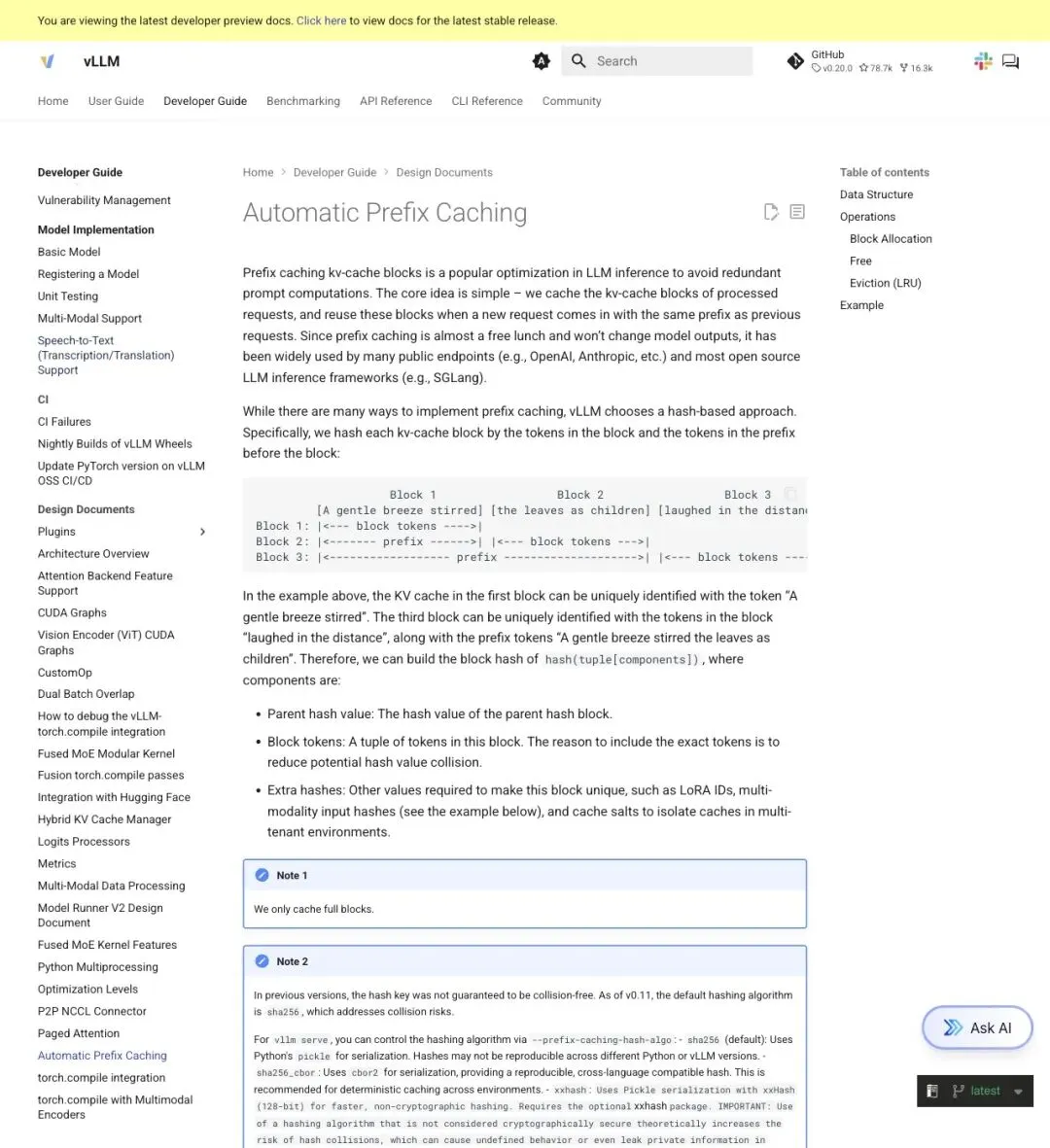
▲ vLLM 官方文档:prefix caching 几乎是”白捡的性能”,前提是前缀保持稳定
Anthropic 的官方文档也印证了同一个原则,而且明确指出:工具定义(tools)、系统提示(system)、消息历史(messages)全部属于被缓存和比较的前缀链路。
“Prompt caching references the entire prompt — tools, and system, and messages — in that order up to the cached breakpoint.”
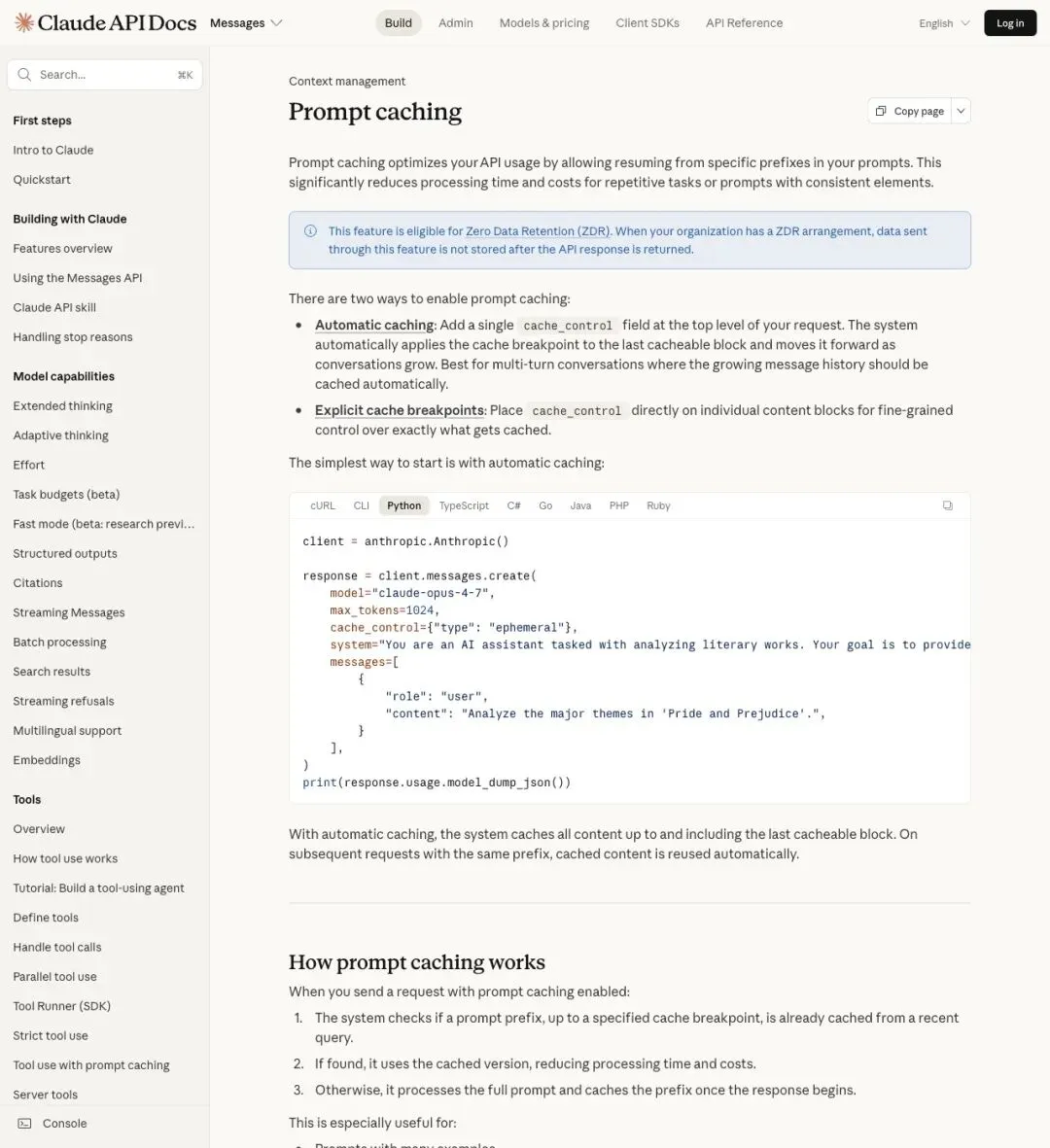
▲ Anthropic 官方文档:tools + system + messages 全在缓存链路里
翻译成大白话:
- 工具定义变了 → 前缀变了 → cache 废了
- 系统提示变了 → 前缀变了 → cache 废了
- 在前缀里塞了动态内容 → 每轮前缀都不一样 → 每轮都在冷启动
在云端,这些成本被基础设施吸收了,你只感觉”贵了一点”。但在本地,这些成本会直接变成:首 token 更慢、每轮都像重启、上下文一长就卡死。
真正该砍的三刀
把整个讨论串拆开来看,Mario 那条推文其实是在同时指出三个问题,每个都有具体的实战含义:
第一刀:系统提示要短、要稳。2.5 万 token 的系统提示在云端能用,在本地就是灾难。而且”长”只是一半的问题,”每轮都在变”才是致命的。把静态规则固定下来,把动态信息挪到消息层,别放在系统层,光这一步就可能让 prefill 时间砍一半。
第二刀:工具别堆,按需加载。15 个扩展 + 17 个模板听起来很全能,但每一个工具定义都在吃前缀空间,都在影响 cache 稳定性。对本地模型来说,”能力越全”有时候反而意味着”每一个能力都更慢”。
第三刀:别往前缀里塞动态变量。时间戳、轮次编号、环境摘要、自动记忆片段——这些看起来人畜无害的小信息,每一个都可能是 cache 命中率的隐形杀手。
这件事的更大背景
为什么这条推文能引发这么多共鸣?因为它精准地撞上了 2026 年 AI 圈最热的一个矛盾——大家都在把云端 coding agent 的玩法往本地搬,但云端成立的设计逻辑,搬到本地可能直接翻车。
云端的默认思路是:多加工具、多堆规则、多塞模板、多层记忆。模型够大、算力够强、cache 基础设施够好,这套打法就行。
但本地模型面对的是完全不同的约束:上下文窗口有限、prefill 速度敏感、KV cache 容量有限、没有厂商帮你兜底 cache 管理。在这个环境里,”全能”可能真的比”精准”更贵。
Reddit 那个发帖人的做法反而给出了一条更聪明的路:别堆功能,做减法。与其给 agent 塞 15 个扩展,不如写一个 plan-first skill 让它先想清楚再动手。与其在系统提示里塞万字说明书,不如让前缀保持稳定,让 cache 真正帮上忙。
结果呢?8GB 显存的笔记本,跑 35B 模型,做真实项目,15-30 token/s。
这才是这条讨论真正想说的:本地模型的天花板,很多时候被 agent 的”运行时包袱”人为压低了。把包袱卸掉,天花板可能比你想象的高得多。
— END —