 夜雨聆风
夜雨聆风





CPO为何势在必行?AI算力逼出来的光互联革命
CPO这两年一直很热,但很多人对它的理解还停留在一个概念:好像只要和光模块、交换机、AI数据中心沾边,就能讲CPO。
其实真正的问题不在于CPO有多新,而在于AI算力集群已经把传统数据中心互联体系逼到了极限。
简单说,AI数据中心现在最缺的东西,不只是GPU,而是更低功耗、更高带宽、更短路径的数据传输方式。
CPO的出现,就是为了解决这个问题。
01|先看AI数据中心到底长什么样
训练大模型,需要成千上万块GPU同时运行。单块GPU再强,也无法独立完成超大规模模型训练,真正的算力来自大量GPU之间的协同。
这些GPU需要不断交换数据。模型参数、梯度、训练结果,都要在GPU之间高速流动。一旦通信跟不上,GPU就会等待,算力就会被浪费。
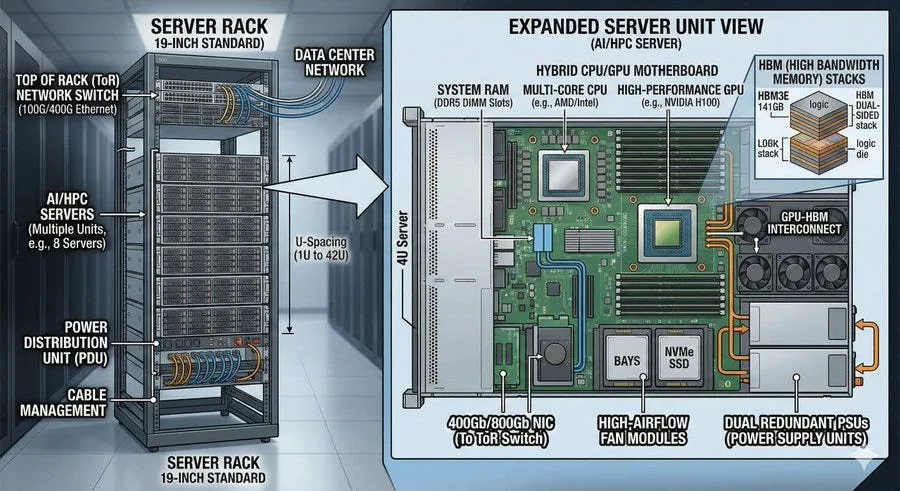
数据中心看起来像一个巨大的“算力工厂”,但它的底层结构其实很标准:一个个机架并排摆放,再由多排机架组成一个区域。
服务器机架大约两米高,里面垂直安装多台服务器。每台服务器内部有CPU、内存、存储设备,也会配置多张GPU卡。很多AI服务器一台就有4张、8张甚至更多GPU。
机架里除了服务器,还会安装网络交换机。交换机可以理解为数据流量的调度中心,它负责把服务器产生的数据收集、整理,再发送到其他设备。由于交换机经常放在机架顶部,所以被称为ToR交换机,也就是Top of Rack交换机。
机架之所以重要,是因为电源、散热、布线、维护都围绕机架展开。哪怕是最先进的AI集群,最终也要落到这个基础结构上。
理解了机架,才能理解后面的通信瓶颈。
02|GPU之间通信,短距离靠铜,长距离靠光
AI数据中心的核心问题是GPU之间必须高速通信。通信距离不同,使用的介质也不同。
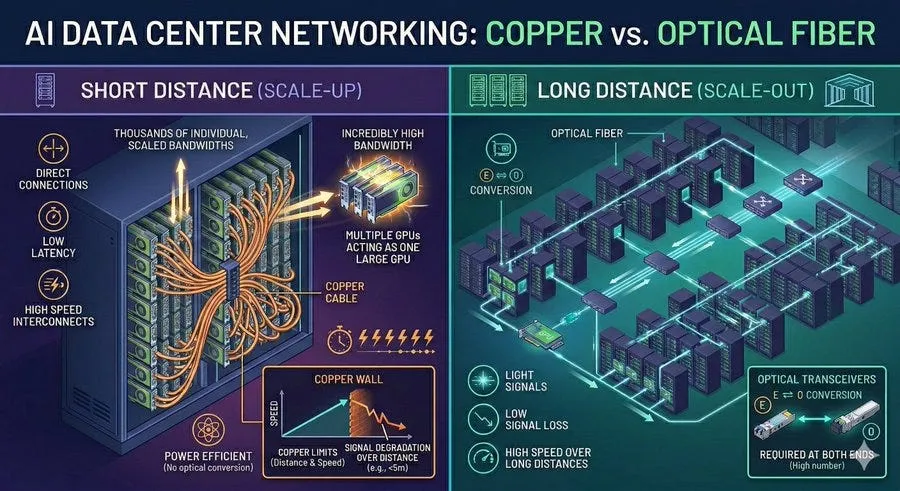
短距离传输,铜缆仍然有优势。比如同一台服务器内部、同一机架内部,甚至相邻机架之间,电信号通过铜缆传输,成本低,结构简单,维护方便,短距离下功耗也相对可控。
在机架内部,GPU之间会通过高带宽互连技术进行通信。它们可以被连接成一个更大的计算单元,这就是所谓的纵向扩展网络。这里距离短,电信号传输还可以承受。
GPU到机架顶部交换机之间,通常也可以使用铜缆。现在800G速率下,无源铜缆大约可以覆盖三米左右,有源铜缆可以做到五米左右。
问题在于,速率越高,铜缆越吃力。
高速电信号在电缆、连接器、电路板走线中传输时,会出现衰减和失真。速度越快,信号越脆弱,补偿电路越复杂,功耗和热量也随之上升。
这就是业内常说的“铜线极限”。
长距离传输就要靠光纤。比如跨机架、跨机房、跨数据中心楼层,传输距离几十米甚至数百米,铜缆很难胜任,光纤成为标准选择。
因为光纤的优势很明显,传输距离远、损耗低、带宽高、线缆轻,适合大规模布线。但光纤有一个绕不开的环节就是GPU和交换芯片本质上处理的是电信号,光纤传输的是光信号,所以中间必须进行电光转换和光电转换。
承担这个转换任务的,就是光模块。
在一个拥有数十万块GPU的数据中心里,光模块数量可以达到数百万个。光模块越多,功耗越高,热量越大,故障点也越多。
这为CPO埋下了伏笔。
03|真正的瓶颈,藏在交换机里面
很多人理解AI数据中心通信,只看到“铜缆”和“光纤”的区别,但真正关键的瓶颈,发生在交换机内部。
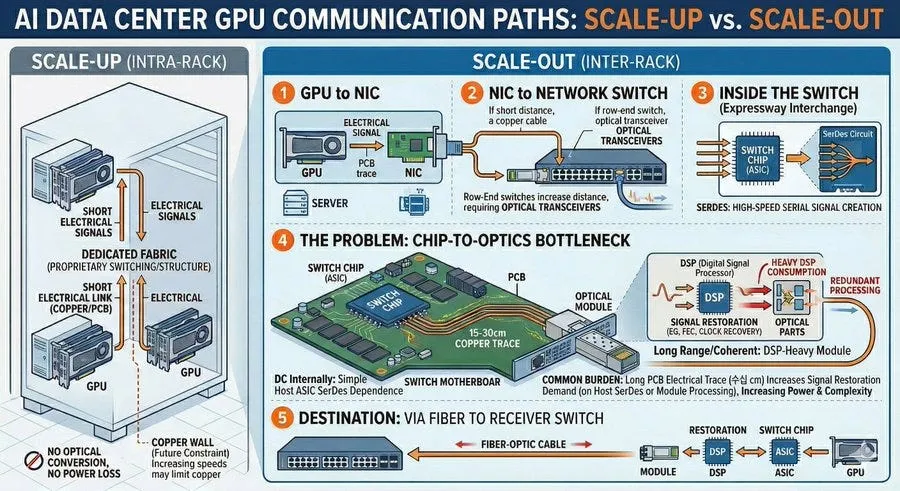
当一块GPU需要把数据发送到另一个机架中的GPU,数据路径大致是这样:
1. GPU先把数据传给服务器内的网卡;
2. 网卡再把数据送到网络交换机。交换机内部的ASIC芯片负责决定数据该往哪里走。ASIC可以理解为交换机的大脑,它不断接收数据、判断路径、转发数据。
3. ASIC内部有一个关键电路,叫SerDes(Serializer/Deserializer 的缩写,中文常译为“串行器/解串器”)。它的作用是把芯片内部数据转换成高速串行信号,再向外发送。
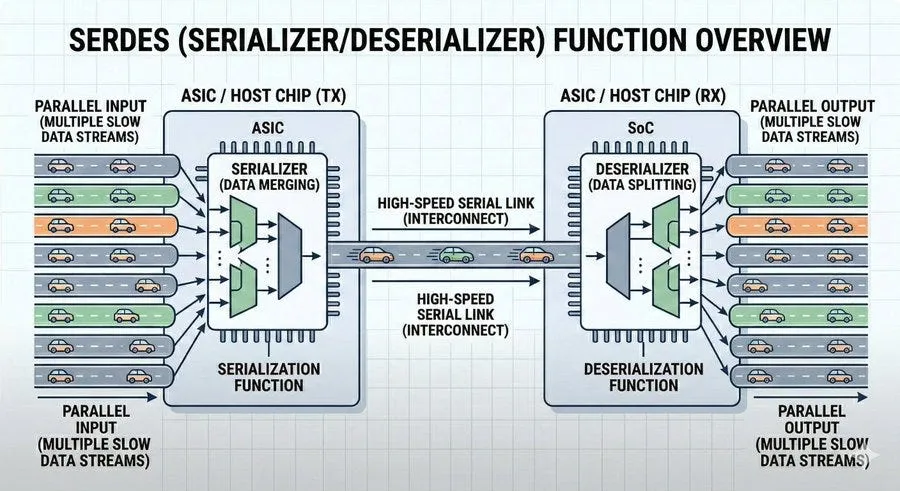
4. 问题来了。在传统交换机中,ASIC输出的高速电信号,并不会马上变成光信号。它需要先穿过交换机电路板,走大约15到30厘米,最后到达插在前面板上的光模块。
这15到30厘米,看起来不长,但在高速信号世界里已经很要命。
速率越高,电信号越容易衰减。为了让信号到达光模块时还能被正确识别,系统就必须加入一整套“抢救机制”:DSP负责恢复失真的波形,时钟恢复负责重建采样节奏,Retimer负责重新生成信号,FEC负责纠错。
这些技术当然有效,但带来了功耗增加、温度升高、设计复杂度增加、成本增加等代价。
换句话说,传统架构最大的问题,是电信号在转换成光信号之前,走了太多路。
这就是CPO要解决的核心矛盾。
04|CPO的本质:把光引擎搬到芯片旁边
CPO,全称Co-Packaged Optics,共封装光学。
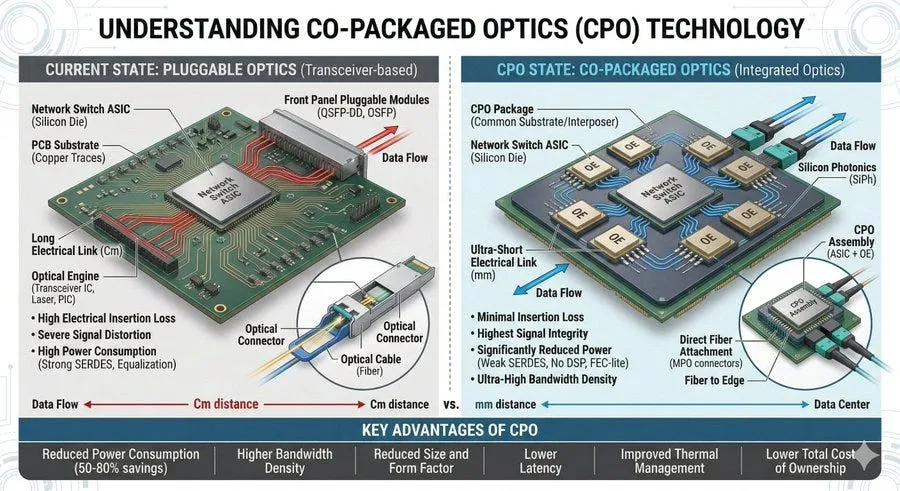
它的思路非常直接,既然问题出在电信号走得太远,那就把电光转换的位置往前挪,尽量靠近交换芯片。
传统方案是:芯片 → 电路板走线15到30厘米 → 前面板光模块 → 光纤
CPO方案变成:芯片 → 几毫米短距离连接 → 封装内光引擎 → 光纤
变化就发生在这里。
过去,电信号要在电路板上跑15到30厘米,现在只需要跑几毫米。这个距离缩短之后,很多问题会被一起解决。
第一,SerDes可以从高功耗的长距离SerDes,变成低功耗的超短距离SerDes。原来为了支撑较长电气链路,需要复杂的均衡和补偿电路;CPO把距离缩短到几毫米后,信号质量好得多,补偿压力自然下降。
第二,DSP可以大幅简化,甚至部分场景下可以取消。传统光模块中,DSP是功耗大户,很多时候会消耗模块接近一半的功率。CPO把光引擎放到芯片附近,电信号还没严重衰减就完成转换,DSP的存在感自然下降。
第三,前面板空间被释放。传统交换机的端口数量受前面板物理空间限制,速率越高,端口越多,面板越紧张。CPO把光模块从前面板搬走,端口密度的约束会明显缓解。
第四,组件数量减少。过去一台交换机需要大量可插拔光模块,每个模块都是一个独立器件,也是一个潜在故障点。CPO把光引擎集成到封装内,系统结构会更紧凑,可靠性也有机会提升。
所以CPO的价值,不是单点技术优化,而是对数据中心互联架构的一次重构。
05|为什么AI越发展,CPO越难绕开
AI大模型训练对数据中心提出了三个极端要求:更高带宽、更低延迟、更低功耗。
这三件事同时出现,就会把传统架构推到极限。
带宽越高,电信号越难传。过去可以承受的电路板走线、连接器和线缆,在1.6T、3.2T甚至更高速率下都会变成瓶颈。电信号跑得越远,系统付出的纠错、均衡、重定时成本越高。
功耗压力更严峻。AI数据中心本来就是耗电大户,GPU、CPU、内存、散热系统已经消耗大量电力。如果网络互联部分继续维持高功耗,整个数据中心的能源效率会被拖累。
空间也越来越紧。交换芯片带宽不断提升,前面板需要承载更多端口,但机箱尺寸不可能无限扩大。可插拔光模块模式在高带宽时代会越来越拥挤。
这三个压力叠加,最终指向同一个方向:必须缩短高速电信号路径,把电光转换前移。
CPO因此变得越来越重要。
它不是为了制造一个新概念,而是AI集群规模扩大后,传统架构被迫升级的结果。
06|CPO会先从哪里落地
CPO最先落地的场景,大概率是横向扩展网络里的高端交换机。
原因很简单,这里的瓶颈最严重。
大模型训练需要成千上万块GPU跨机架通信,后端网络承载了巨大的数据交换压力。交换机带宽持续提升,前面板端口密度、光模块功耗、电气链路损耗都会同步放大。
下一步,CPO也可能向网卡层面延伸。
新一代AI数据中心架构中,交换机位置可能发生变化,网卡到交换机之间的连接距离也会变长。过去能用铜缆解决的部分连接,未来可能也需要光互联。届时,将光引擎集成到网卡附近,也会成为一个方向。
再往后看,随着GPU之间互联带宽继续上升,CPO甚至可能逐步影响纵向扩展网络。现在机架内部短距离通信还可以依靠铜缆和电互连,但当速率继续翻倍,铜线极限迟早也会逼近。
所以CPO的扩散路径,大致会从高端交换机开始,再向网卡、加速卡、甚至更靠近计算芯片的位置推进。
07|CPO改变的不只是光模块
CPO真正重要的地方,在于它会改变整个光互联产业链的价值分配。
传统可插拔光模块时代,光模块插在交换机前面板上,模块厂商围绕封装、光器件、电芯片、散热和测试建立能力。
CPO时代,光引擎被放进封装体系,位置更靠近交换芯片。产业链的技术重心会向更高集成度迁移。
这会带来几类变化。
光引擎的重要性上升。它不再只是一个独立模块里的组件,而是要进入更复杂的封装系统,对尺寸、功耗、热管理、可靠性提出更高要求。
硅光、薄膜铌酸锂、激光器、光学透镜、FAU、光纤连接、封装测试等环节都会被重新评估。谁能适应更高集成度、更低损耗、更强散热和更高一致性,谁就更有机会在下一代架构里占位置。
传统光模块厂商也会面临变化。可插拔光模块不会马上消失,但高端AI交换机上的增量机会,可能逐步向CPO、LPO、硅光等新形态倾斜。未来的竞争不只拼产能和客户,也拼平台化能力、封装能力和与交换芯片厂商协同的能力。