 夜雨聆风
夜雨聆风





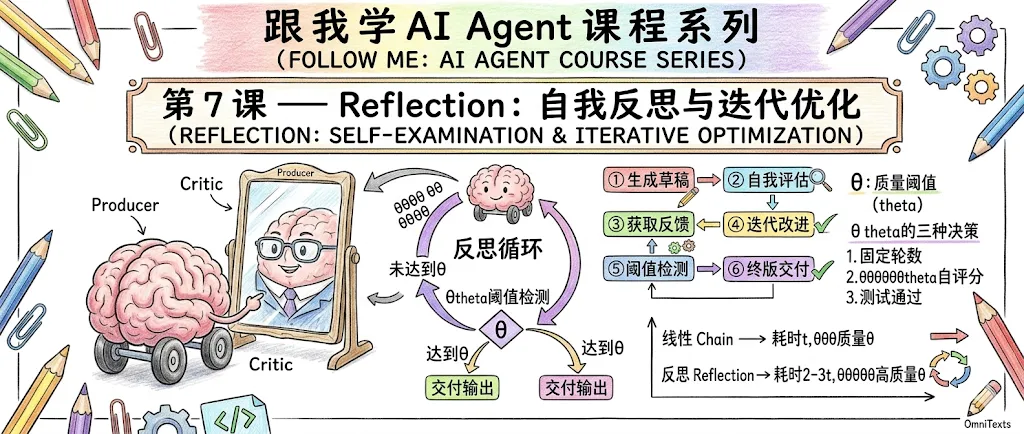
跟我学 AI Agent : 第 7 课 — Reflection:自我反思与迭代优化
模块: 模块三:高级编排与规划 | 难度: ⭐⭐ | 预计时长: 2.5 小时参考: Agentic Design Patterns: A Hands-On Guide to Building Intelligent Systemspi-mono API: pi-mono hooks,session tree
🪞 “未经审视的输出不值得交付。”
—— 改编自苏格拉底
开篇故事:一个”差一点就对了”的程序员
想象你让 AI 帮你写一段阶乘函数。它自信地输出了代码:
deffactorial(n):return n * factorial(n - 1)乍一看没问题——递归,简洁。但它缺少基准条件,调用会无限递归直到栈溢出。
如果我们能让 Agent 不只生成一次就交付,而是自己检查、发现错误、再来一轮呢?
这就是 Reflection(反思)模式 的核心思想:让 Agent 成为自己的评审者。
核心概念
什么是 Reflection 模式?
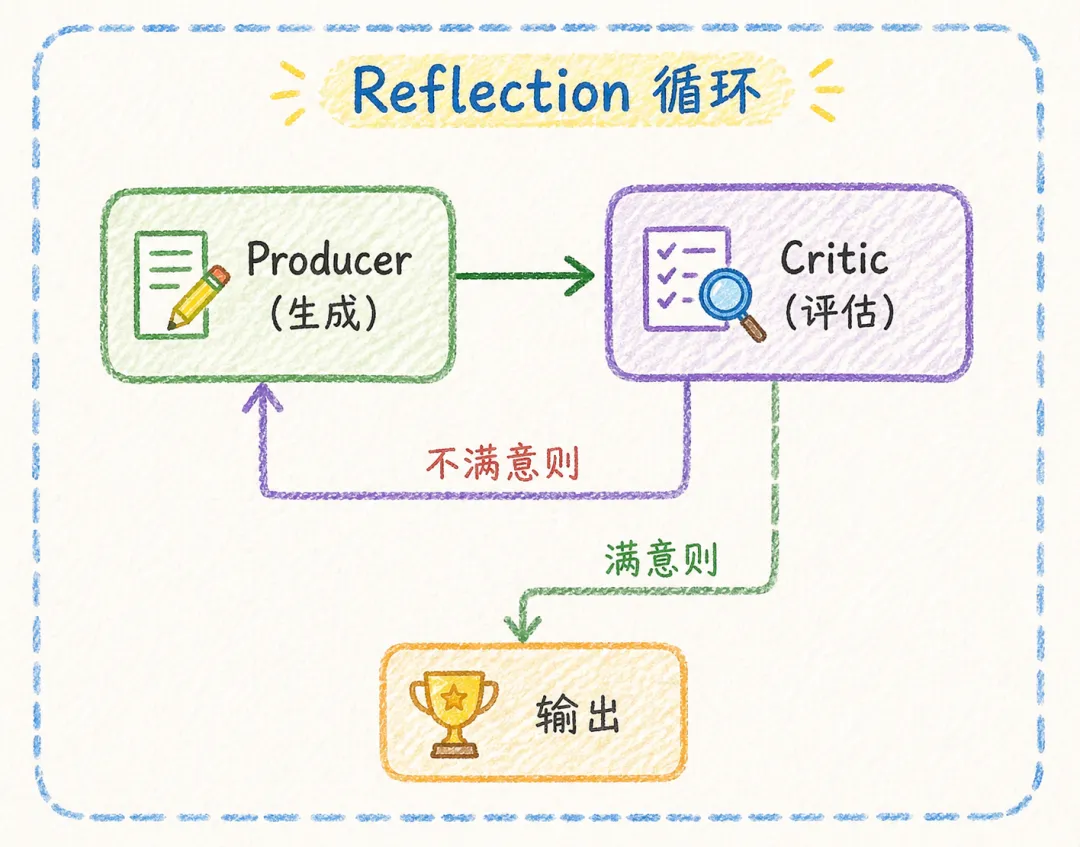
Reflection 模式让 Agent 在生成输出后,主动审视和改进自己的工作。它不是一个独立的”反思 Agent”,而是同一个 Agent 在生成和评估之间切换角色,形成迭代循环。
Producer-Critic 模型
Reflection 的经典实现是 Producer-Critic(生产者-评论家) 架构:
|
|
|
|
|
| Producer |
|
|
|
| Critic |
|
|
|
关键洞察:Producer 和 Critic 可以是同一个 LLM,通过不同的 Prompt 切换角色。
六大应用场景
总结一下 Reflection 的六大典型用例:
-
1. 创意写作 — 生成文章后自评结构、语气、逻辑连贯性 -
2. 代码生成 — 编写代码后检查边界条件、类型安全、性能 -
3. 问题求解 — 得到答案后验证推理步骤、检验结果 -
4. 文本摘要 — 摘要后检查是否遗漏关键信息 -
5. 任务规划 — 制定计划后评估可行性和遗漏步骤 -
6. 对话系统 — 回复前评估是否真正回答了用户问题
何时使用 Reflection?
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
权衡:Reflection 以延迟换质量。每一轮反思大约使处理时间翻倍,但通常 2-3 轮就能显著提升输出质量。
架构解析
反思循环的三个关键组件
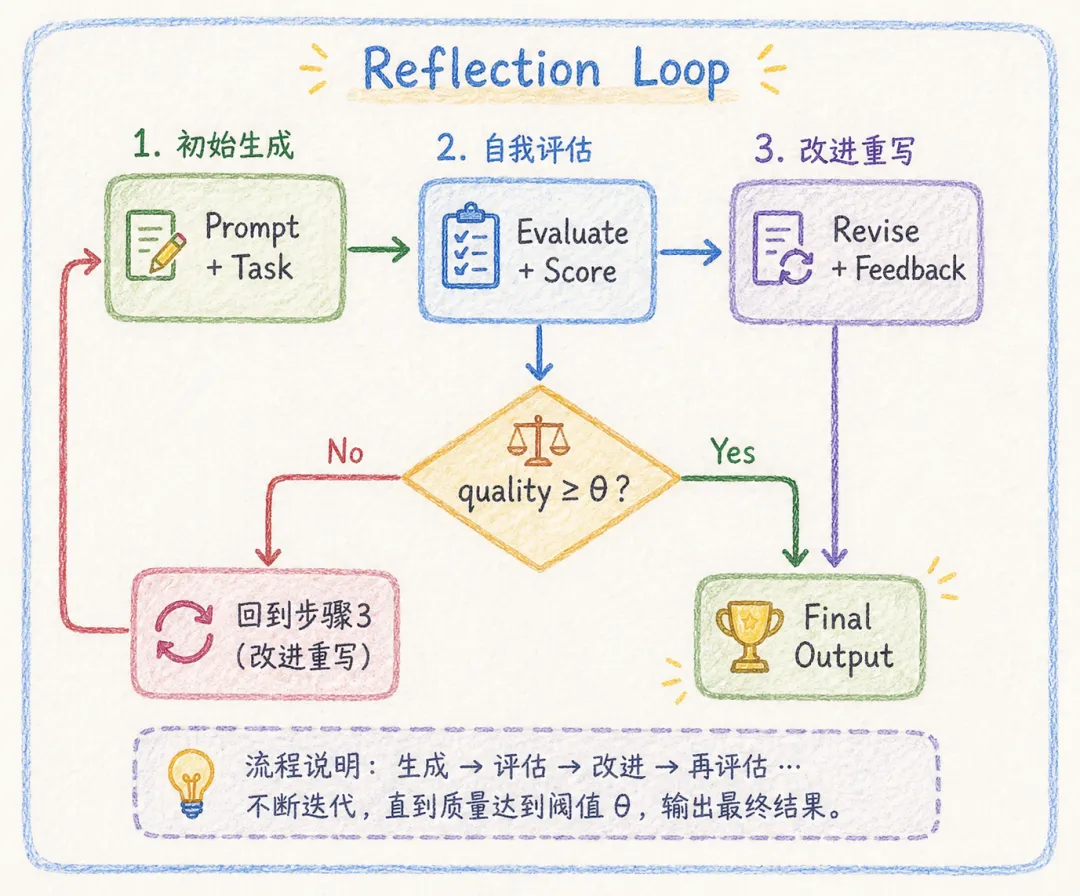
θ(theta)是质量阈值——决定何时停止迭代。可以设为:
-
• 固定轮数(如最多 3 轮) -
• 满足特定标准(如代码通过所有测试) -
• LLM 自评分数达到阈值
与其他模式的关系
-
• Reflection + Prompt Chaining = 先分解子任务,每个子任务内部做反思 -
• Reflection + Multi-Agent = Critic 作为独立 Agent,拥有不同的工具和知识 -
• Reflection + Tool Use = Critic 调用测试工具(如运行代码)来验证输出
代码实战:pi-mono 实现 Reflection
利用 pi-mono 的特性,下面的例子展现了 Reflection 在 pi-mono 中的三种落地方案,与当前生成环境中的常用模式非常吻合:
|
|
|
|
|
|
显式循环: 在应用层控制 Producer/Critic 交替,判断阈值后 exit |
|
|
|
Hooks 拦截:onResponse让 Agent 每次输出后自动进入反思状态 |
|
|
|
Session Tree 分支:fork()保留原始输出,在分支上做反思,最后可选 merge |
|
示例 1:基础反思循环 — 代码生成与自检
import { Agent, AgentTool } from"@mariozechner/pi-agent-core";// 定义评估工具:运行代码并检查结果const codeEvaluator = AgentTool({name: "evaluate_code",description: "执行一段 Python 代码并返回运行结果和错误信息",parameters: {code: { type: "string", description: "要执行的 Python 代码" },test_cases: { type: "string", description: "测试用例 JSON" } },execute: async (args) => {// 在沙箱中执行代码,返回结果// 实际实现需要安全的执行环境returnJSON.stringify({passed: true,errors: [],output: "代码执行成功,所有测试通过" }); }});// Producer Agent:生成代码const producer = newAgent({name: "CodeProducer",model: "gpt-4",systemPrompt: `你是一个资深程序员。根据需求编写代码。要求:- 处理所有边界条件- 添加类型注解- 包含错误处理`,tools: [],thinkingLevel: "high"});// Critic Agent:审查代码const critic = newAgent({name: "CodeCritic",model: "gpt-4",systemPrompt: `你是一个严格的代码审查专家。审查给定的代码,从以下维度评估:1. 正确性:逻辑是否正确,边界条件是否处理2. 安全性:是否有注入风险或敏感数据泄露3. 性能:时间/空间复杂度是否合理4. 可读性:命名、注释、结构是否清晰输出格式:- score: 1-10 分- issues: 具体问题列表- suggestions: 改进建议`,tools: [codeEvaluator],thinkingLevel: "high"});示例 2:完整的反思循环编排
import { Agent } from"@mariozechner/pi-agent-core";asyncfunctionreflectionLoop(task: string,maxIterations: number = 3,qualityThreshold: number = 8): Promise<string> {let currentOutput = "";let feedback = "";for (let i = 0; i < maxIterations; i++) {// Step 1: 生成(第一轮是初始生成,后续轮是改进)const generatePrompt = i === 0 ? task : `${task}\n\n以下是之前的输出:\n${currentOutput}\n\n请根据以下反馈改进:\n${feedback}`;const genResult = await producer.run(generatePrompt); currentOutput = genResult.text;// Step 2: 评估const criticPrompt = `请审查以下输出:\n\n${currentOutput}\n\n原始任务:${task}`;const criticResult = await critic.run(criticPrompt);// Step 3: 解析评估结果const evaluation = JSON.parse(criticResult.text);console.log(`第 ${i + 1} 轮 — 评分: ${evaluation.score}/10`);// Step 4: 质量达标则提前退出if (evaluation.score >= qualityThreshold) {console.log(`✅ 质量达标,提前退出`);return currentOutput; } feedback = evaluation.suggestions; }console.log(`⚠️ 达到最大迭代次数 ${maxIterations},返回当前最佳版本`);return currentOutput;}// 使用示例const result = awaitreflectionLoop("写一个 Python 函数,计算列表中所有偶数的平方和,要求处理空列表和非整数输入",3, // 最多 3 轮8// 质量阈值 8/10);示例 3:利用 pi-mono hooks 实现自动反思
pi-mono 的 hooks 机制让我们可以在 Agent 的特定生命周期节点注入反思逻辑:
import { Agent, AgentHooks } from"@mariozechner/pi-agent-core";const reflectiveAgent = newAgent({name: "ReflectiveWriter",model: "gpt-4",systemPrompt: "你是一个技术文档撰写专家。",// pi-mono hooks:在每次 Agent 完成响应后触发反思hooks: {// Agent 完成一轮输出后自动触发onResponse: async (agent, response) => {// 如果响应中包含 [DRAFT] 标记,说明需要反思if (response.text.includes("[DRAFT]")) {const reflectionPrompt = `请以评论家视角审视以下草稿,指出不足并给出改进建议:\n\n${response.text}`;const improved = await agent.run(reflectionPrompt);return improved; // 用改进版本替代原始输出 }return response; } },thinkingLevel: "high"// 启用深度思考模式});示例 4:使用 Session Tree 做反思分支
pi-mono 的 session tree 特性特别适合 Reflection 场景——每次反思可以产生一个分支,保留完整的改进历史:
import { Agent } from"@mariozechner/pi-agent-core";const agent = newAgent({name: "ReflectiveCoder",model: "gpt-4",systemPrompt: "你是一个代码编写专家,每次输出后会自我检查。"});// 创建主 sessionconst session = agent.createSession();// 第一轮:初始生成const draft = await session.run("写一个快速排序函数");// 创建分支 session 进行反思(保留原始 session 不变)const reviewBranch = session.fork();// 在分支上做反思改进const review = await reviewBranch.run(`请检查你刚才写的代码,找出所有问题并修复`);// 如果分支更好,合并回主线const improved = await reviewBranch.run(`基于你的审查意见,输出最终改进版本`);console.log("原始版本:", draft.text);console.log("改进版本:", improved.text);关键要点
-
1. Reflection 的本质是 Producer-Critic 循环:同一个 Agent 在生成和评估之间切换,迭代改进输出 -
2. 六大典型场景:创意写作、代码生成、问题求解、摘要、规划、对话——凡是可客观评估的任务都适合 -
3. 质量与延迟的权衡:每轮反思约使延迟翻倍,但 2-3 轮通常就能显著提升质量 -
4. 质量阈值 θ 决定何时停止:固定轮数、测试通过、或自评分达标 -
5. pi-mono 的 hooks 和 session tree 是实现反思的利器: -
• hooks.onResponse实现自动反思 -
• session.fork()保留改进历史 -
• thinkingLevel: "high"提升反思深度 -
6. 不是万能的:实时场景、简单任务、无客观标准的场景不适合
练习
练习 1:基础反思循环
使用 pi-mono 实现一个 “自我改进的摘要器”:
-
• 给定一篇长文,Agent 生成摘要 -
• Critic 角色评估:是否遗漏关键论点?逻辑是否连贯? -
• 至少迭代 2 轮,对比每轮摘要质量的变化
练习 2:质量阈值实验
修改 reflectionLoop 函数,对比以下两种终止策略的效果:
-
• 固定 3 轮迭代 -
• 动态阈值(评分 ≥ 8 时提前退出)用同一组任务测试,哪种策略在质量和效率之间取得了更好的平衡?
练习 3:Session Tree 分支对比
利用 pi-mono 的 session.fork() 实现 “A/B 反思”:
-
• 分支 A:让 Critic 只关注代码正确性 -
• 分支 B:让 Critic 只关注代码性能 -
• 对比两个分支的最终输出有何不同
延伸阅读
-
• Reflexion: Language Agents with Verbal Reinforcement Learning (Shinn et al., 2023) -
• Self-Refine: Iterative Refinement with Self-Feedback (Madaan et al., 2023)
-
源代码:https://github.com/OmniTexts/learning-ai-agent