 夜雨聆风
夜雨聆风





光进铜退:AI算力互连正在换一条路
铜线里的电子还在排队,光纤中的光子已经抄了近道。算力竞赛的下半场,胜负手不在芯片本身,而在芯片之间那条路有多快。
支撑在AI时代的三大支柱中(算力、存力、运力),计算层负责生成处理能力,决定了人工智能可执行任务的规模。互连层则实现处理能力的传输,主导着计算资源协同运作的效率。
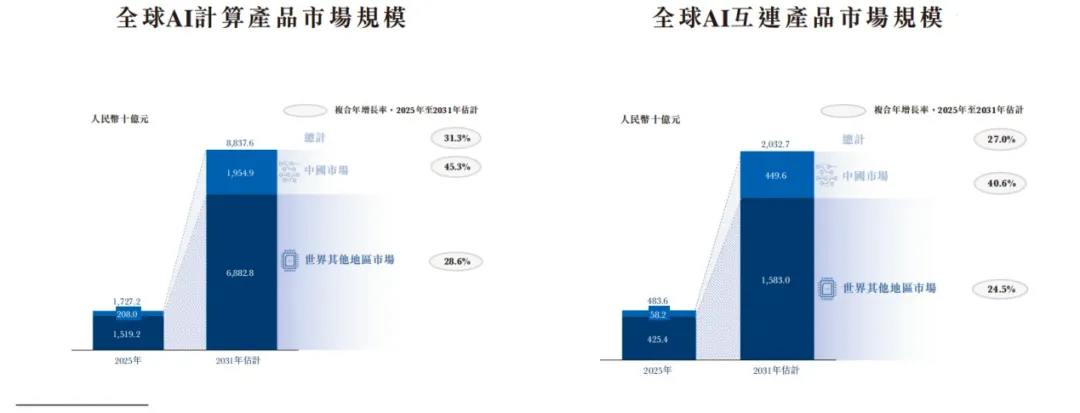
 全球算力基础设施仍以电计算及电互连为主,但已达到极限
全球算力基础设施仍以电计算及电互连为主,但已达到极限
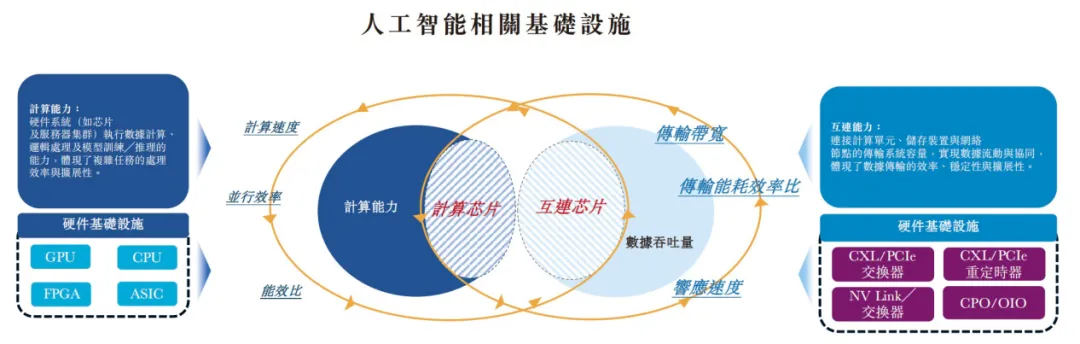
受限于摩尔定律及其他物理极限,传统电系统在成本、可扩展性、性能及能耗方面的瓶颈日益凸显,进一步加剧算力短缺问题。
「物理极限」的限制:
电计算长期遵循摩尔定律,但如今已面临显著的物理极限。随着单芯片制程的快速进步,晶体管缩放正逼近物理极限,当节点进入7纳米及以下领域时,微缩技术开始面临量子隧穿、电迁移及散热等物理极限,纯粹的几何尺寸缩减已无法带来显著性能提升,自2015年起每个新节点带来的性能改善幅度明显放缓,这限制着单芯片算力的增长。
「内存墙、功耗墙」问题突出:
同时,带宽及功率限制进一步制约单芯片的计算效率,诸如「内存墙」(处理器速度与内存带宽差距扩大)及「功耗墙」(处理器的热量及能耗限制)等问题日益突出。
 「铜互连、传统光模块」无法解决行业痛点
「铜互连、传统光模块」无法解决行业痛点
为缓解上述限制,业界已转向使用铜线互连多颗电计算芯片。然而,铜互连的物理特性在传输距离及带宽方面存在固有限制,仅能实现「短距离、低带宽」传输。
另一种广泛采用的替代方案是传统光模块,其主要功能是延长发射端与接收端之间的传输距离,但难以解决成本及延迟问题,仅能实现「长距离、高成本、高延迟」传输。
在集群计算及超节点环境中,芯片间通信时延至关重要,而光模块无法有效降低时延或提高芯片利用率。此外,光模块成本相对较高,故并非最理想的解决方案。
博通、英伟达等领先公司已开始跨越传统光模块,探索包括共封装光学(CPO)在内的先进光互连技术,以突破该等限制并增强算力。
 AI算力的提升路径
AI算力的提升路径
提升单芯片性能:
采用新兴计算技术,如光计算,其利用光子的传播特性,在无电阻情况下,可实现更高带宽及更低传输延迟,这是其相较于电计算的突出优势。采用光电混合架构,其中光信号进行高速传输及乘积累加运算,电子电路处理逻辑及控制,提供的计算性能显著超越传统电模型。
同时,电计算因遵循摩尔定律,已面临显著的物理极限,限制着单芯片算力的增长,而光计算则不受类似限制。
最后在封装上,通过芯片集成技术而不是倚赖大型单片式裸晶,不仅提高制造良率及降低成本,亦能实现异构单元(如CPU、GPU及NPU)的无缝集成,构建了高度协作的计算环境,大幅提升计算能力及应用灵活性。
进行集群扩展:
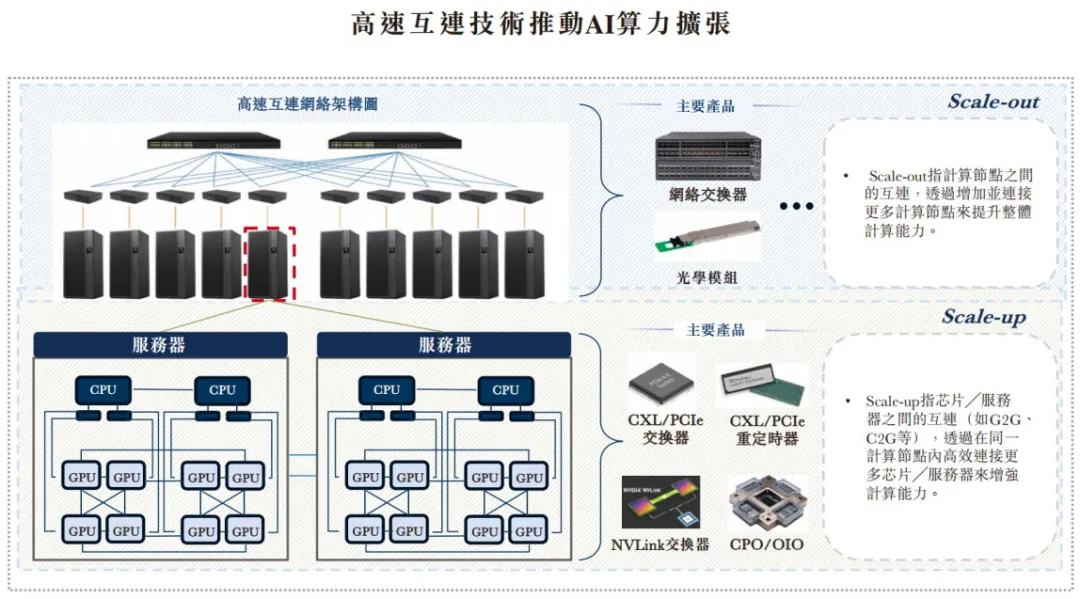
高速互连作为基础架构,通过Scale-up及Scale-out两个维度扩充AI计算能力,共同促成由数千台设备组成的庞大GPU集群的无缝形成,从根本上维持人工智能能力的持续增长。
英伟达CEO黄仁勋明确表示:“光互连和先进封装集成是下一代人工智能基础设施的基石,能够提升大规模AI网络的能效和弹性。”
光互连技术,通过光信号连接各类计算设备(包括GPU、CPU、xPU、交换机及存储芯片),依应用场景分为Scaleout与Scale-up两大类。
 Scale out
Scale out
Scale-out光互连主要用于计算节点间的连接,其链接成千上万台服务器,使其作为一个统一系统运行,从而实现大规模并行处理,将计算任务分配至包含数万个GPU的集群。目前已广泛部署于数据中心及AI训练集群,成为业界标准配置。
Scale-out利用网络交换机及光模块连接多个独立节点,将其整合为一个庞大的集中式计算资源池,因此Scale-out强调跨集群的可扩展性及协同能力,但无需在整个计算集群内维持严格的内存一致性,从而简化互连复杂性。
 Scale-up
Scale-up
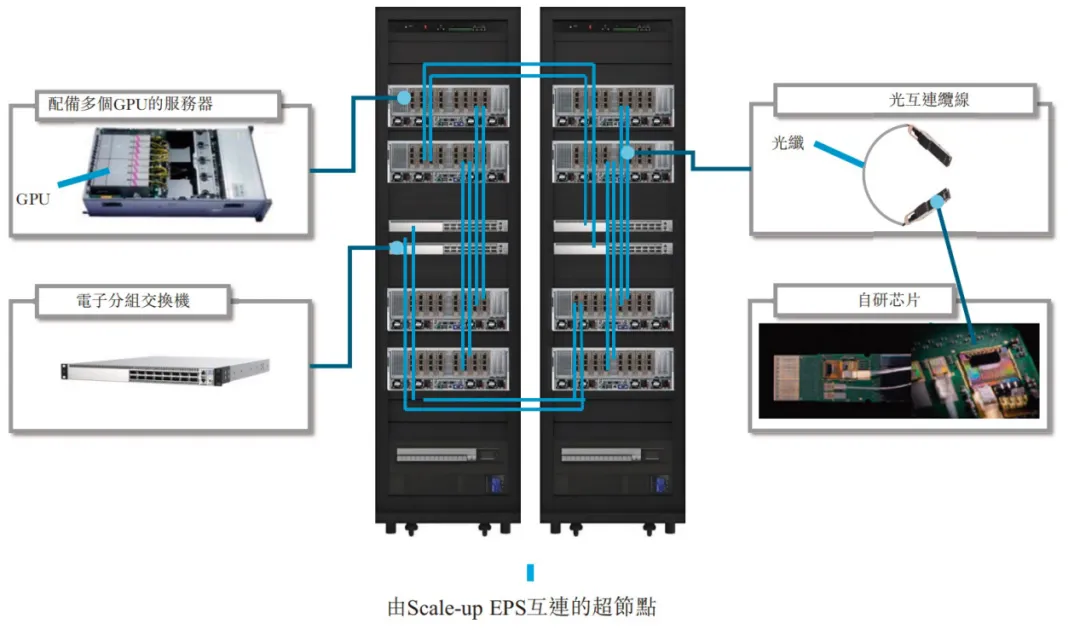
Scale-up光互连专注于单个服务器或计算节点内芯片间的高速互连。通过紧密耦合多个GPU以一个更大的处理器运行,从而提升单节点的算力。
Scale-up架构倚赖CXL、NVLink及CPO等关键技术,以最大限度实现单个计算节点内数据传输效率及资源协同效应。
Scale-up的核心要求是内存一致性互连,确保所有处理器共享统一的内存视图。维持一致性需要GPU之间频繁通信,因此互连必须提供极高带宽、低延迟,并支持专用硬件协议,这对大语言模型训练至关重要。
1)封装形态
就封装形态而言,规模化Scale-up光互连产品主要包括:线性可插拔光模块(LPO)、近封装光学(NPO)、共封装光学(CPO)。
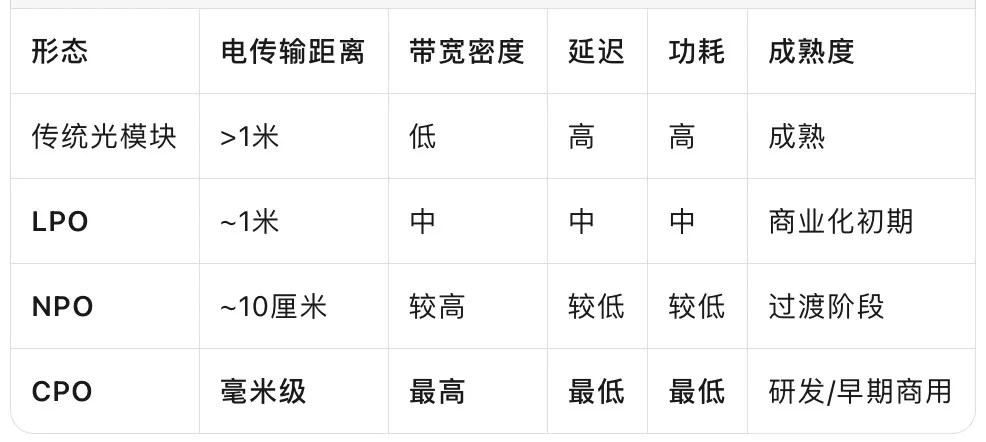
①LPO
采用简化的线性驱动架构,是目前超节点中长距离板间及机柜间连接的主流方案。
与依赖数字信号处理器(DSP)改善信号完整性的传统可插拔光学器件不同,LPO采用精简的线性驱动架构,将信号处理功能转移至主机系统。该架构可降低延迟、减少功耗,并在广泛应用的可插拔封装内实现成本效益。
②NPO
近封装光学将光模块从服务器面板移至靠近GPU板卡的位置,将铜线传输长度从一米以上缩短至约十厘米,缩短电气走线距离,提升信号完整性与传输效率,是迈向CPO的重要过渡形态。此架构无需数字信号处理芯片(DSP),能够降低延迟,并将互连密度提升两至三倍。
③CPO
将光引擎与交换机ASIC或AI加速芯片紧密集成于同一封装或基板内,使互连距离缩短至毫米级,实现最高带宽密度与最低能耗,被视为下一代超大规模集群的核心解决方案。
相较于近封装光学,该方案可实现带宽提升,并显著降低延迟。另一方面,共封装光学存在较大的技术复杂性,如先进光学封装、电学封装及协同设计方法的要求。
2)交换架构
①OCS(光路交换)
OCS(光路交换/全光交换)是一种无需光电/电光(O/E/O)转换,直接实现光信号在光纤端口间切换的技术。目前,仍处于产业化的初期。
通过OCS连接实现计算节点间的大规模交换与流量调度,相比传统电交换具备更低功耗与更大端口扩展能力,从而支撑超大规模AI计算集群的网络互连。
目前,OCS主要有MEMS、液晶、压电、硅波导四大技术路线,MEMS方案作为谷歌自研方案商用节奏最快,其次是液晶方案。
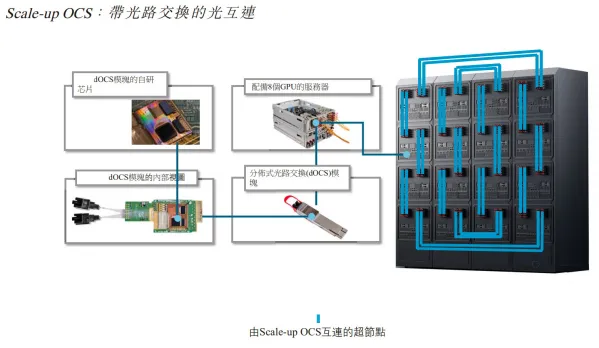
举个例子:一个AI训练集群有1000台服务器,每台8块GPU。OCS就像光信号的总调度台,当服务器A的第3块GPU需要和服务器B的第7块GPU通信时,OCS直接拉一条专属光纤通道,让两个GPU”隔空对话”,不用经过层层电交换机转接。

产品演进趋势:
Scale-up光互连产品形态的演进,反映了交换架构与封装集成两个基本维度。交换架构决定了延迟与能效的极限,而封装形态则决定了带宽密度与传输效率。

-
在交换层面,目前主流的「光传输加电子交换」模式仍依赖电子芯片进行路由,限制了可扩展性与能效。为满足超低延迟及高带宽需求,业界正朝着全光交换迈进,省去反复的光电转换,从而显著降低延迟与能量损耗。
-
在封装层面,集成已从LPO发展至NPO,最终迈向CPO,持续缩短电传输路径,并提升带宽密度与能效。
因此,向全光互连及CPO封装的转变并非偶然,而是对大规模AI计算系统性能需求的结构性回应。
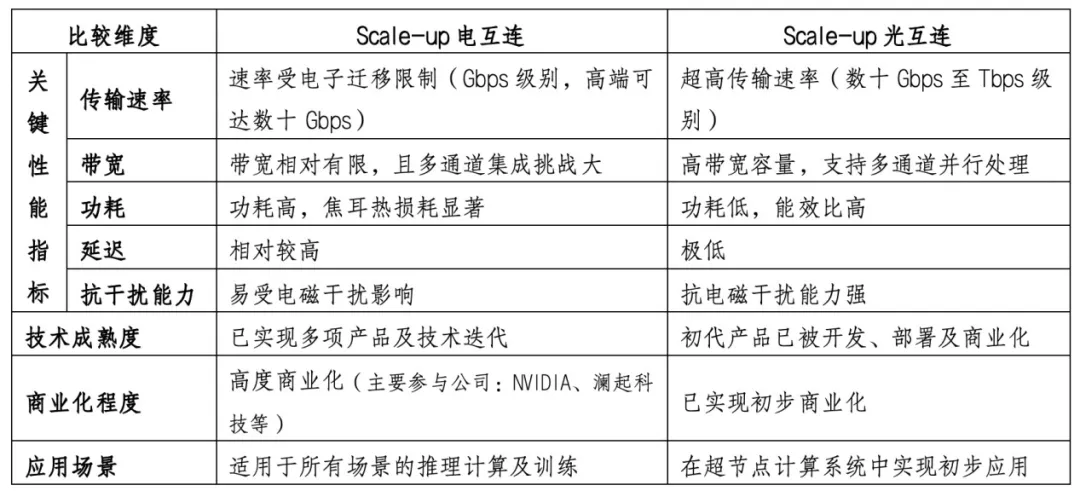
3)Scale-up光互连 VSScale-up电互连
现有短距连接市场仍以铜为传输介质的Scale-up电互连为主导技术。虽然仍被广泛使用,但受固有物理特性制约:随着传输距离延长,信号完整性会急剧衰减,而随着速度提高,功耗会显著上升。该等限制构成制约现代数据中心可扩展性、效率及成本效益的瓶颈。
光互连技术通过光传输数据,能够在更长距离上传递更高带宽,同时降低单比特功耗,从而突破上述障碍。
因此,预期Scale-up光互连将逐步取代传统电互连,成为Scale-up互连解决方案演进的必然方向。
 商业化障碍
商业化障碍
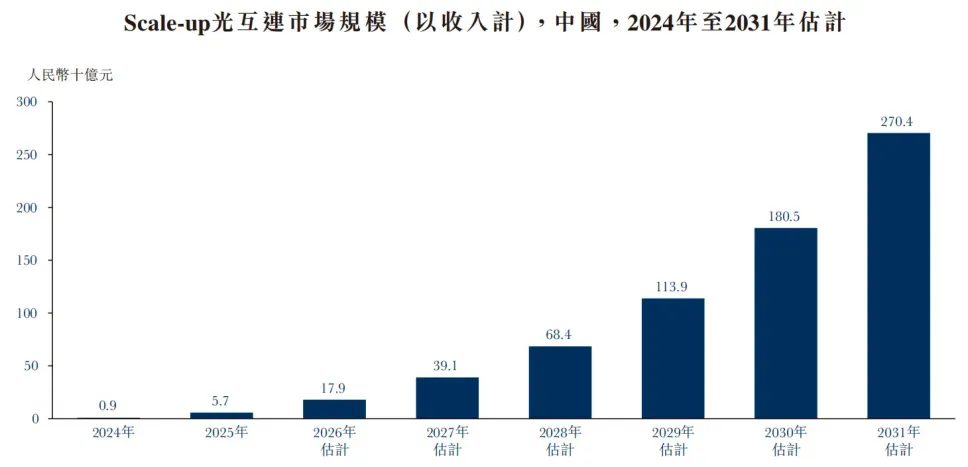
目前,中国的Scale-up光互连市场仍处于早期阶段,专注于超节点计算场景(即由大量GPU及其他加速器组成的可作为单一计算单元运行的集群),市场规模预计将从2025年的57亿元增长至2030年的1805亿元,复合年增长率为99.6%。
现阶段,数据中心内高速数据传输采用的光互连技术,已迈向大规模商用化的第一步,有效解决电互连的带宽瓶颈。光互连市场正处于关键的拐点。
但下游客户仍需要时间评估光互连解决方案如何有效满足其战略及技术要求,以及需要额外时间验证其在硬件、软件及系统集群间的兼容性及稳定性。因此,广泛的商业部署可能需要较长的时间才能实现。
2025年,中国Scale-up光互连市场中仅有两家公司实现大规模商业化,行业整体仍处于早期阶段,前两大参与者合共占总市场份额约99.8%。

长期而言,光计算与光互连的融合将催生全光架构,标志着从「电计算+光传输」模式向「全光计算」的转变。