 夜雨聆风
夜雨聆风





网络风险溢价的来源:AI解开网络安全与股票回报的谜题
论文《Disentangling the sources of cyber risk premia》(2026年2月3日)用最前沿的机器学习技术,首次把企业年报里的“网络安全”文字拆解成可量化的风险分数,并证明:网络风险越高的公司,股票长期回报反而越高!
1. 引言:网络风险到底是成本还是机会?
网络攻击越来越频繁,网络保险和安全解决方案成本高昂,但市场到底怎么给这些风险定价?这是个老大难问题。
作者的核心创新:用自然语言处理(NLP)+机器学习,把企业10-K年报(美国上市公司年度报告)里的文字转化成“网络风险分数”,再结合资产定价模型,看这些分数能不能解释股票回报。
数据覆盖:2007年1月至2023年12月,7079家美股公司,每月回报、财务比率、行业分布一应俱全。
关键发现(提前剧透):
-
他们从MITRE ATT&CK(全球最权威的网络攻击知识库)中提炼出4大类网络威胁。 -
高网络风险分数的股票组合,年化超额回报显著为正。 -
长短仓“网络风险因子”在所有主流因子模型中都稳健存在,还能显著提升定价能力。 -
市场其实不区分具体网络风险类型,而是把它们当成一个整体的“聚合网络风险”来定价。
2. 文献回顾
2.1 文本情感分析与金融应用
论文回顾了从Antweiler & Frank(2004)到Hassan et al.(2019)、Sautner et al.(2023)的一系列工作:文本能预测市场回报、政治风险、气候风险等。
重点介绍了Paragraph Vector (doc2vec)模型(Le & Mikolov, 2014),以及它在10-K分析中的应用(Adosoglou et al., 2021;Calomiris & Mamaysky, 2019)。
2.2 网络风险与股票回报
-
Jamilov et al. (2023):用词典法测网络风险,证明高风险公司期权保护成本更高。 -
Florackis et al. (2023):基于10-K“Item 1.A风险因素”部分的余弦相似度,构建网络风险指标,高风险组合年化溢价8.3%。 -
Celeny & Maréchal (2023):用doc2vec+MITRE ATT&CK,构建整体网络风险分数,高风险组合年化超额回报高达18.72%!
本论文是在Celeny & Maréchal (2023)基础上升级:不再只给一个总分,而是拆解成4个子分数,试图回答“不同网络风险类型是否被市场区别定价?”
3. 数据与方法
3.1-3.2 数据来源
3.3 MITRE ATT&CK知识库
全球网络安全“圣经”,包含14个战术(Tactics)、785个子技术(Sub-techniques)。作者以此作为“网络威胁词典”。
3.4 网络风险分数构建
- 准备与侦察(Preparation and Reconnaissance)
- 持久化与规避(Persistence and Evasion)
- 凭证移动(Credential Movement)
- 命令与数据操纵(Command and Data Manipulation)
3.5-3.6 资产定价检验
-
单变量排序:按网络分数分成5个组合。 -
双变量排序:控制规模、账面市值比、市场beta。 -
Fama-MacBeth横截面回归。 -
时间序列GRS检验 + Barillas & Shanken (2018)贝叶斯因子选择。
4. 主要结果
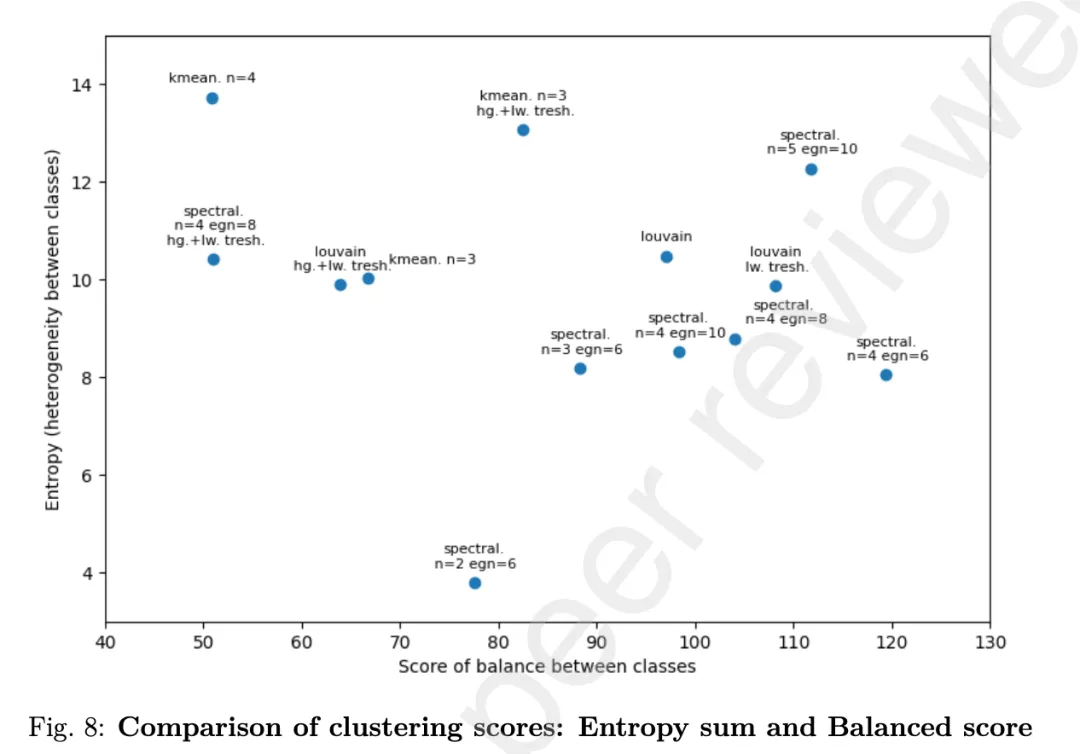
4.1 聚类结果
成功把14个战术聚成4个逻辑清晰的超级战术,异质性低、平衡性好。
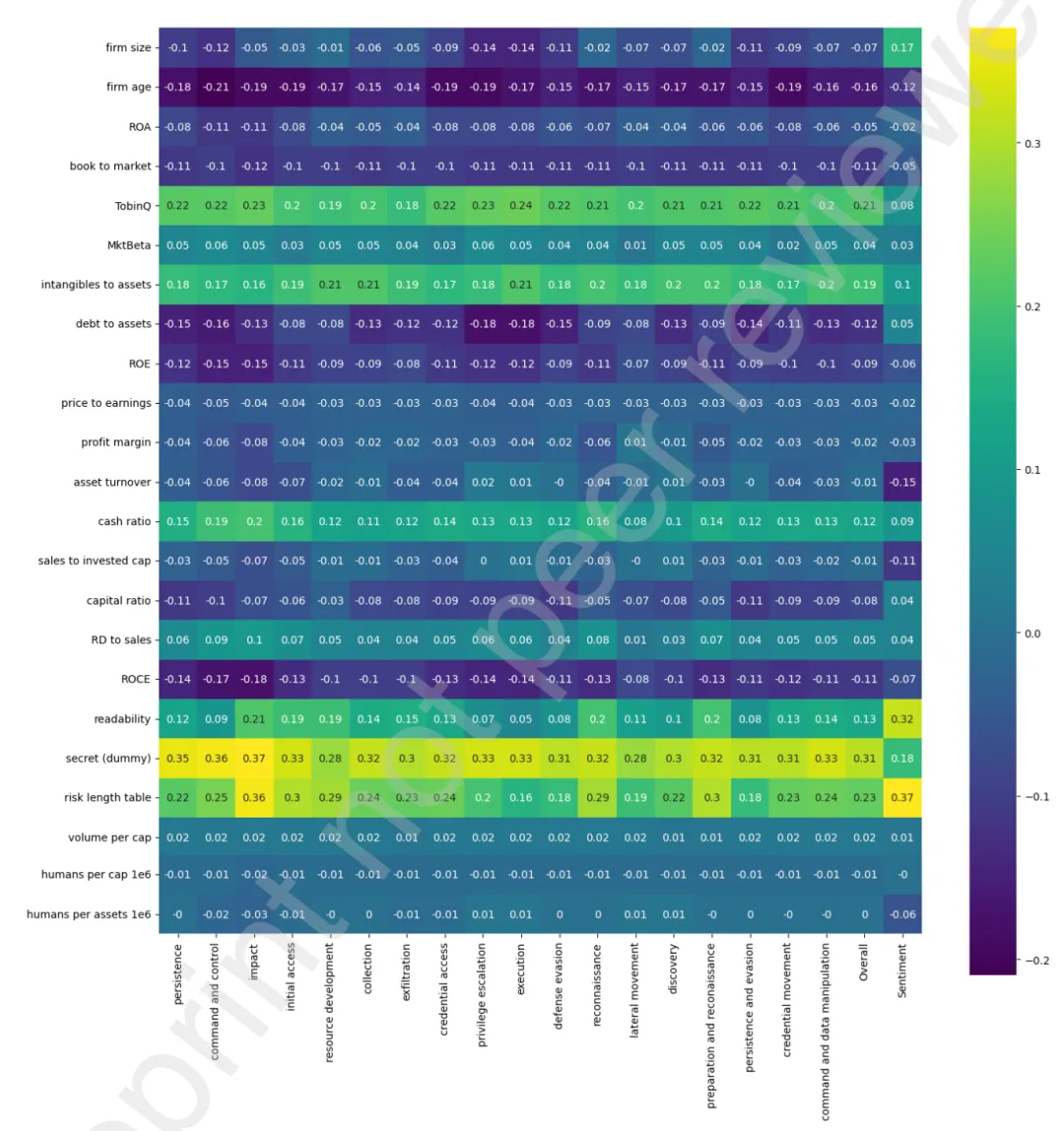
4.2 网络分数的统计特征
-
分数随时间缓慢上升(2007-2023年增长0.04)。 -
行业差异显著:商业设备、电信传输行业分数最高。 -
各子分数高度相关,但与传统财务特征几乎不相关(最高相关系数仅0.36,与1.A节长度)。
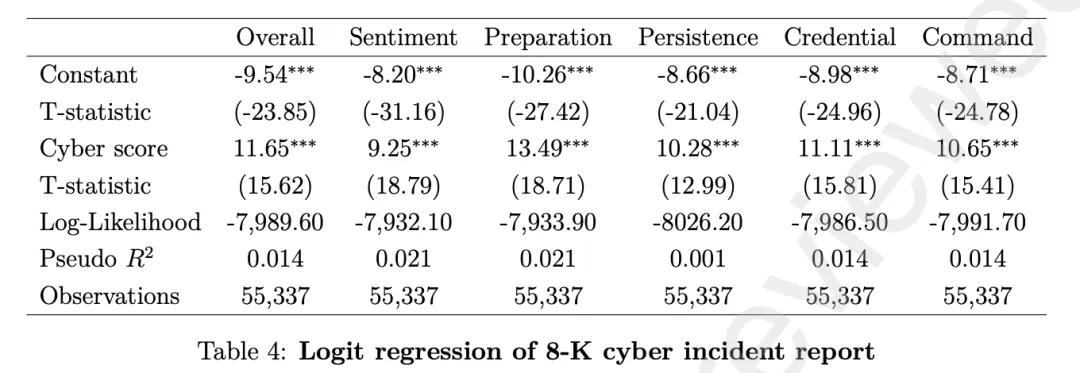
4.3 网络分数能预测真实网络事件
用Logistic回归预测10-K发布后12个月内8-K中出现“cyber”一词:
-
整体分数系数11.65(1%显著)。 - 准备与侦察子分数预测能力最强(系数13.49)。
-
分数从0.5提高到0.6,网络事件披露概率提升约7.3%。
4.4 网络分数独立于其他特征
多变量回归显示:
-
即使加入可读性、风险因素长度、员工/市值比等变量,网络分数仍高度显著。 -
不同子分数的回归系数符号和显著性不同,说明它们捕捉的是不同维度的风险。
4.5 投资组合表现
- 单变量排序:5个组合的超额回报随网络分数单调递增,发现得分最高的P5组平均月超额收益达1.44%,远高于低风险组的0.82%。
-
长短仓(P5-P1)年化Alpha在5-10%水平显著,经FF5、q-factor等模型检验仍稳健。 - 双变量排序:控制规模、价值、动量后,网络溢价依然存在。
- 横截面回归:网络子分数风险溢价在5%水平显著。
- 因子定价能力:加入网络因子后,GRS统计量显著下降;Barillas-Shanken贝叶斯方法显示,最优因子组合必然包含网络因子。
5. 结论与启示
论文最核心的结论有三点:
- 网络风险是有价的:投资者要求补偿,表现为正的风险溢价。
- AI能比人类更精准地读懂年报:doc2vec+MITRE ATT&CK的方法远超传统词典法。
- 市场目前还比较“粗放”:它把所有网络风险当成一回事,没有精细区分不同攻击路径。
对投资者的启示:
-
未来可以构建“网络风险因子”ETF,长期持有高网络风险(但基本面健康)的公司。 -
监管机构和公司应更主动披露具体网络威胁类型,帮助市场更高效定价。 -
随着SEC强制网络事件8-K披露(2024年起),网络风险分数的预测能力有望进一步验证。
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=6173935
PDF已更新,更多策略、资讯⬇️
