 夜雨聆风
夜雨聆风





技术解读:OpenAI GPT-Image-2 技术分析
OpenAI GPT-Image-2 技术突破分析
9B自回归引擎+7B扩散解码器混合架构 · Interleaved-MRoPE空间编码 · DeepStack深层对齐 · 视觉链式推理 · MXFP4量化部署
提示:文章阅读用时约15分钟。
一、引言:视觉生成范式转移
在生成式人工智能的演进史中,视觉生成模型的发展轨迹始终伴随着对底层架构能力的不断试探与突破。从早期的生成对抗网络(GAN)到主导了过去数年的去噪扩散概率模型(DDPM),AI 图像生成技术在实现照片级真实感和通用场景构建方面取得了举世瞩目的成就。然而,直至 2026 年初,包括 DALL—E3、Midjourney v6 以及 Google 的 Imagen 3 在内的纯扩散架构模型,始终面临着几项难以逾越的工程与理论瓶颈:复杂空间推理能力的严重缺失、长距离空间依赖(Long—range spatial dependencies)的断裂,以及最为业界诟病的图像内文本渲染(即“乱码”与“异化”问题)1。这些固有的系统性缺陷,将图像生成模型长期局限于“创意脑暴工具”或“装饰性配图生成器”的范畴,阻碍了其向要求绝对精确性的企业级工作流(如 UI 原型设计、产品包装、学术图表构建)的渗透4。
2026 年 4 月 21 日,OpenAI 正式发布了名为 gpt—image—2 的新一代视觉大模型,并同步在 ChatGPT 平台推出了 ChatGPT Images2.0 更新6。这一模型的问世不仅是参数规模的简单扩张,更标志着一种底层技术范式的彻底转移。OpenAI 首次在官方语境中将视觉媒体的定位从“装饰”提升为“语言”,赋予其与自然语言同等的严密逻辑与语义深度7。大量来自第三方评估平台(如 LM Arena)的盲测数据以及开发者社区的早期实测表明,gpt—image—2 在标准排版基准测试中达到了惊人的 99% 字符级准确率9,实现了原生的多语言高保真文本渲染(涵盖中日韩、印地语、孟加拉语等复杂非拉丁语系)1,并支持最高达 4K(超过 800 万像素)的超高分辨率原生输出8。
更为深远的突破在于,该模型彻底摆脱了过去“盲目抽卡”式的单次前向传递生成模式,引入了原生代理推理机制(Agentic Reasoning),使其具备了真正的“视觉思考”能力10。这种跨越式的进步并非源于单一维度的技术改良,而是由底层混合架构的重构、空间位置编码的革新、跨模态对齐深度的拓展、合成训练数据的精细化,以及基于人类反馈的视觉强化学习等一系列颠覆性创新共同促成的。本报告将深入剖析 gpt—image—2 取得这些重大突破的底层技术逻辑,揭示其从传统扩散工具向“视觉思维伙伴”(Visual Thought Partner)演进的科学机制。
技术章节导航
01
引言
视觉生成范式的根本性转移
02
架构重构
9B AR + 7B DiT 深度混合架构
03
空间对齐
Interleaved-MRoPE + DeepStack 双引擎
04
认知进化
视觉链式推理与代理思考模式
05
训练重构
结构化合成数据与视觉RLHF
06
基础设施
MXFP4量化 + 智能路由
07
商业化能力
原生4K + 溯源防御 + 竞品对标
08
结论与展望
从”艺术试玩”到”生产力基础设施”
范式判断
OpenAI首次在官方语境中将视觉媒体的定位从”装饰”提升为”语言”,赋予其与自然语言同等的严密逻辑与语义深度
gpt-image-2彻底摆脱了过去”盲目抽卡”式的单次前向传递生成模式,引入了原生代理推理机制(Agentic Reasoning),使其具备了真正的”视觉思考”能力。
标志着视觉大模型从”艺术图像生成”进入了严肃的”信息资产制造”阶段
ℹ
提示
关键性能指标:标准排版基准测试字符级准确率达 99%,原生多语言高保真渲染(中日韩/印地语/孟加拉语等),最高 4K(800万+像素)原生输出,常规质量设定下生成耗时仅约 3秒,低于竞品10-15秒。
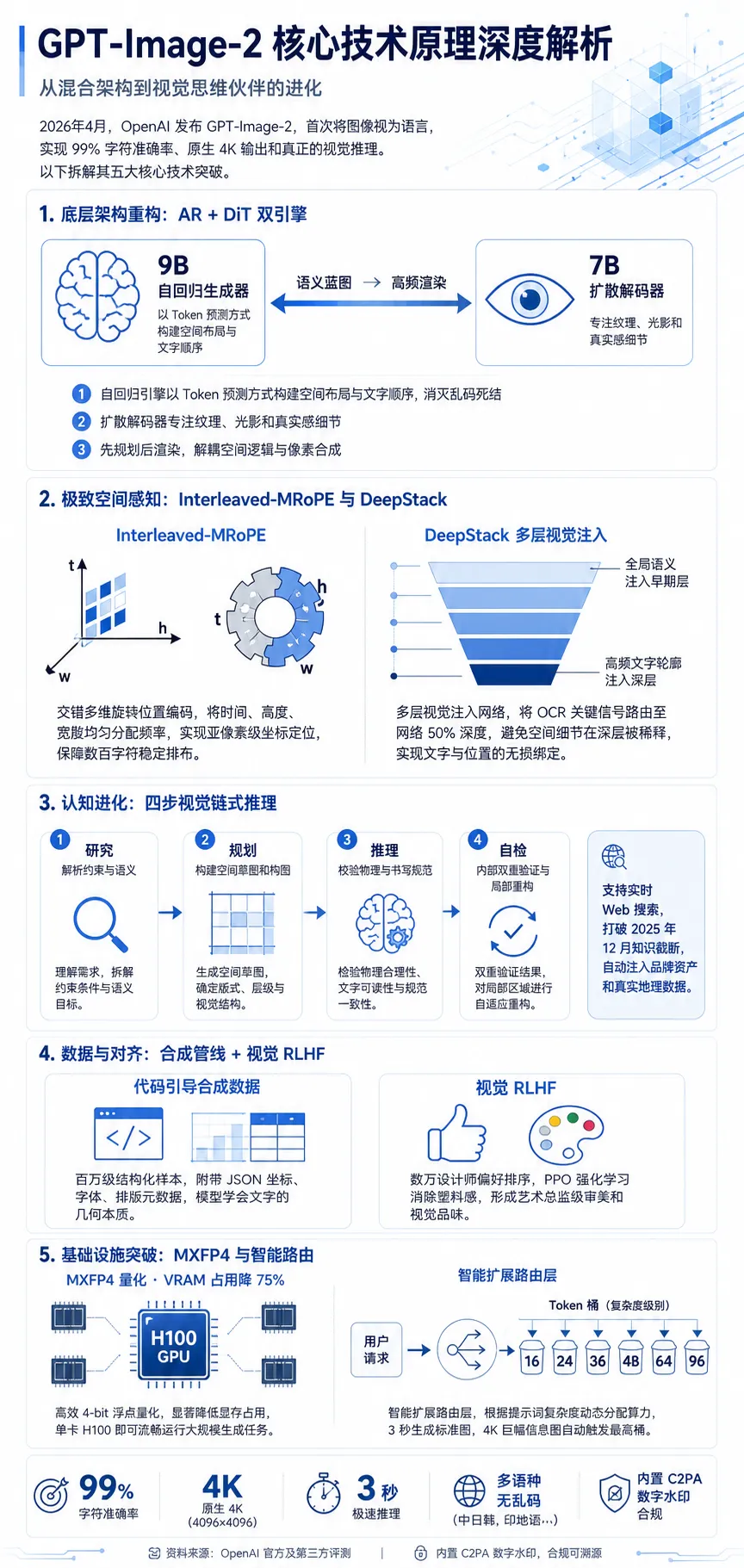
二、底层架构重构:自回归与扩散变压器(AR + DiT)的深度混合
要理解 gpt—image—2 为何能彻底解决文本乱码和构图失控问题,必须首先审视其底层网络架构的根本性重组。在此之前,行业主流(包括已经被 OpenAI 于 2026 年 3 月 4 日正式退役的 DALL—E 3)主要依赖纯扩散模型12。纯扩散架构通过在潜空间中逐步去除高斯噪声来合成图像,这种机制极其擅长捕捉像素间的局部连续性(如光影过渡和皮肤纹理),但在处理长序列的全局逻辑和绝对空间坐标时表现出固有的无力感2。当用户指令包含多对象的严格排布或特定单词的拼写时,扩散模型往往会丢失条件信息,导致特征错误绑定(例如将红色的汽车和蓝色的背景混淆为蓝色的汽车),或将明确的字母扭曲为不可读的象形符号4。
架构
纯扩散模型(DDPM)
过渡型混合架构
9B AR生成器 + 7B DiT解码器(深度混合)
推理延迟
>10秒,跨节点分布式部署
~6秒,多卡集群
~3秒,单H100即可
空间推理能力
复杂空间布局失效,特征错误绑定
部分改善
Interleaved-MRoPE + DeepStack,亚像素级精准控制
文本渲染
严重乱码问题
基本可读
99%字符级准确率,多语言排版
输出分辨率
1024×1024,需后处理升采样
最高4K
原生4K(4096×4096),无需升采样
量化技术
传统16-bit浮点
8-bit
MXFP4原生量化,VRAM占用降低约75%
2.1 双流架构:9B 自回归生成器与 7B 扩散解码器的协同
为了从根本上克服长距离空间依赖的挑战,gpt—image—2 摒弃了纯粹的扩散范式,转而采用了一种高度创新的混合架构。该架构将大型语言模型(LLM)无可匹敌的自回归(Autoregressive, AR)语义逻辑能力与扩散变压器(Diffusion Transformer, DiT)的高频视觉合成能力进行了单流级(Single—stream)的深度解耦与协同2。
具体而言,模型内部包含一个规模约 90 亿参数(9B)的自回归生成器,以及一个 70 亿参数(7B)的扩散解码器2。这种双层引擎设计的核心逻辑在于“先规划,后渲染”: 自回归生成器首先接管用户输入的复杂提示词,利用其强大的自然语言理解能力,将视觉空间进行离散化处理。它以逐个 Token 预测的方式(类似于 GPT—5.4 生成文本),在低频维度上构建出整张图像的“语义级建筑蓝图”2。在这个阶段,系统主要处理全局组合逻辑、对象的相对坐标以及文本边界框(Bounding Box)内字符的确切顺序。这直接解决了传统模型在排版时“不知字在何处”或“不知词由何构”的致命缺陷3。
随后,这份具备严格拓扑逻辑的潜在表示图谱会被传递给 7B 扩散解码器。由于无需再分心处理复杂的语义对齐和空间规划,扩散解码器能够将全部算力集中于高频细节的合成上,精准填补材质的微观纹理、复杂场景的光线散射、物理上合理的景深模糊以及光影的一致性2。这种混合架构不仅保留了语言模型在遵循极端复杂、多子句指令上的绝对优势,更通过 DiT 架构消除了早期自回归视觉模型常见的“块状伪影”,实现了无与伦比的照片级真实感3。
空间与视觉特征对齐两大核心技术
Interleaved-MRoPE(交错多维旋转位置编码)
通过轮询轮询机制将特征维度均匀分配给时间、高度、宽度坐标轴。每个注意力头内三维轴均获得完整频率频谱覆盖,注意力衰减模式与语言模型在长文本上的推断行为高度一致,实现亚像素级绝对坐标定位
DeepStack(多层视觉注入网络)
摒弃单阶段投影,采用多层级分流式特征路由:全局语义注入早期层建立场景宏观理解,高分辨率文本轮廓与微观拓扑直接路由到网络深层(~50%深度),OCR路由敏感度峰值精准推迟,实现”内容”与”位置”的深层绑定
三、空间与视觉特征对齐核心技术:Interleaved—MRoPE 与 DeepStack
如果说混合架构为 gpt—image—2 提供了强大的逻辑骨架,那么其在空间感知与多模态特征融合层面引入的两项尖端技术——交错多维旋转位置编码(Interleaved—MRoPE)和多层视觉注入网络(DeepStack),则是赋予其“像素级精确控制力”的神经元18。
3.1 Interleaved—MRoPE:打破降维惩罚的全频段坐标系
在自回归引擎处理图像时,必须将二维或三维的视觉信息展平为一维序列。传统模型广泛使用的旋转位置编码(RoPE)原本是为自然语言的一维序列设计的。当强行将其扩展至多维视觉数据(包含时间维度 、高度 、宽度 )时,简单的分块或叠加处理会导致严重的频率利用不均——所有的空间或时间信息往往被挤压到高频维度,使得模型无法在长距离上维持稳定的坐标感知19。这种坐标感知能力的崩塌,正是过去模型无法在同一幅图像中稳定绘制数百个微小字符(如漫画中的日文对白或复杂学术报告中的表格数据)的核心原因7。
gpt—image—2 的底层主干网络(与同期 Qwen3—VL 等前沿架构类似)全面实装了 Interleaved—MRoPE(交错多维旋转位置编码)方案18。该方案在 Q/K(Query/Key)线性投影阶段,通过精密的轮询(Round—robin)机制,将特征维度以交错的方式均匀分配给时间、高度和宽度坐标轴22。 其数学机制极其精巧:对于给定的复平面 ,系统通过取模运算 来严格分配当前操作的坐标轴(、 或 ),并根据该轴选择对应的绝对位置进行旋转计算21。这一机制的工程学意义在于,它确保了在任何一个注意力头(Attention Head)内部,时间、高度和宽度轴都能获得完整的频率频谱覆盖(Full frequency spectrum)21。由此带来的直接红利是“位置连贯性”(Positional coherence)的大幅跃升:注意力机制在图像三维空间距离上的衰减模式,变得与语言模型在长文本序列上的推断行为高度一致。这使得 gpt—image—2 能够提供绝对精密的亚像素级坐标定位,从根本上保障了生成复杂结构图、工程设计图纸及高密度排版物料时的空间刚性。
3.2 DeepStack 架构:穿透 OCR 路由瓶颈的深层对齐
在解决“把东西画在哪里”之后,模型还需解决“如何理解画的是什么”的问题。早期多模态大型模型(LMM)普遍采用“单阶段投影”(Single—stage projection)技术,即通过一个简单的投影层,将视觉主干网络(Vision Transformer, ViT)提取的视觉特征一次性注入到语言模型的极早期计算层中(通常位于网络深度的 6% 至 25% 处)20。 这种粗暴的早期融合策略迫使网络在同一个层级同时处理极其抽象的高层语义逻辑和极其细微的局部空间细节。最新的因果干预和主成分分析(PCA)研究揭示,这种单阶段注入会导致光学字符识别(OCR)等高度依赖空间精确性的信号在深层前向传播中被严重稀释甚至完全丢失24。
gpt—image—2 及其底层多模态引擎(如 GPT—5.4 主干)引入了革命性的 DeepStack 技术,彻底重构了视觉到语言的注入流20。DeepStack 摒弃了单点注入,转而采取多层级、分流式的特征路由策略: 模型将 ViT 提取的抽象全局语义特征注入到自回归网络的早期层,以建立对场景的宏观理解;同时,将包含高分辨率文本轮廓和微观拓扑结构的高频空间特征直接路由到网络深层20。实证研究表明,在采用 DeepStack 架构的模型中,OCR 的路由敏感度峰值(即路由瓶颈)被精准推迟到了网络大约 50% 深度的中段(Mid—depth)24。在这个深度上,模型已经完成了对指令的充分语义解析,能够毫无干扰地将明确的文本概念映射为具有极高保真度的像素簇。 正是得益于 DeepStack 在“内容(What)”与“位置(Where)”之间的深层绑定,gpt—image—2 才能够完美生成诸如包含无数精细数据点的仪表盘截图、极具真实感的浏览器框架,甚至是可以直接用于商业演示的移动端 APP 原型界面,真正实现了从文本理解向空间语义的无损穿透4。
视觉链式推理四步管线(Thinking Mode)
🔍 深度研究与约束解析 Research
对提示词进行极限拆解,识别物理实体、语义关系、风格约束。能理解”康托尔对角线证明”等高阶学术概念的内在逻辑结构
🎯 空间规划与视觉层次构建 Plan
在潜在空间中构建无形草图网格,规划构图平衡、视觉引导线,预先计算各元素绝对像素占比。支持8张图像的角色一致性和场景连贯性生成
⚖️ 逻辑推演与物理规则校验 Reason
计算光源投射角度、验证阴影物理规律、检查透视正常性、核实多语言文本书写规范
✅ 内部双重验证与自回归修正 Double-check
最终输出前执行自我交叉核对,将潜在结果与提示词每一个子句比对,对拼写错误、肢体畸形、构图失调等致命伪影进行毫秒级局部重构与纠错
四、认知维度进化:视觉链式推理与代理思考模式
算法架构的革新赋予了 gpt—image—2 强大的执行力,而“思考机制”的引入则赋予了它作为独立“创意代理”(Creative Agent)的认知能力6。这是生成式视觉模型历史上的第一次,系统不再是被动响应提示词的“画笔”,而成为了具备自主规划、反思与纠错能力的“视觉思维伙伴”11。
4.1 四步视觉链式推理管线(Visual Chain—of—Thought)
当 ChatGPT Plus、Pro 或 Business 订阅用户调用 gpt—image—2 的“思考模式”(Thinking Mode)时,系统彻底打破了传统文本到图像工具“提示即渲染”的线性死板流程,转而执行一套类似于人类高级视觉设计师的隐式四步链式推理(Chain—of—Thought)计算循环10:
一、深度研究与约束解析(Research):在渲染任何一个像素之前,系统底层集成的 o 系列逻辑引擎会首先对提示词进行极限拆解。它会识别并理解所有物理实体、复杂的语义关系以及细微的风格约束(如“包豪斯极简风格”、“特定的情绪基调”或“严格的色彩对冲”)10。它甚至能理解诸如“康托尔对角线证明”等高阶学术概念的内在逻辑结构31。
二、空间规划与视觉层次构建(Plan):随后,模型在潜在空间中构建一个无形的草图网格,规划整体场景的构图平衡、视觉引导线(Leading lines),并预先计算各元素的绝对像素占比10。这种前置规划是其能够在一个提示词下一次性生成多达 8 张具有极其严格的角色一致性和场景连贯性图像(如用于漫画分镜或故事板设计)的基石11。
三、逻辑推演与物理规则校验(Reason):模型会对预设的空间关系进行物理逻辑演算,检查光源的投射角度是否统一、阴影是否符合物理规律、背景透视是否正常,并核实嵌入的文本是否符合目标语种的书写规范7。
四、内部双重验证与自回归修正(Double—check): 这是传统模型绝对缺失的环节。在最终结果输出前,gpt—image—2 会执行内置的自我交叉核对机制。它将生成的潜在结果与初始提示词的每一个子句进行比对。一旦发现诸如拼写错误、人物肢体畸形或构图比例失调等致命伪影(Artifacts),它会在毫秒级时间内触发自回归分支进行局部重构与自我纠错10。
4.2 实时 Web 搜索集成:击碎知识截断壁垒
任何静态训练的模型都必然面临知识老化的问题。官方文件确认,gpt—image—2 的底层静态知识库截断日期为 2025 年 12 月7。在高度依赖时效性的商业广告设计和新闻视觉解释场景中,这种知识滞后往往是致命的。
为了彻底消除这一盲区,gpt—image—2 的“思考模式”被赋予了实时的 Web 代理搜寻能力7。当用户指令中包含需要验证的时事热点、新兴品牌资产或最新科技产品时(例如要求生成一张“2026 年巴黎奥运会后续影响的报告配图”或“带有最新款科技产品外观的海报”),其推理引擎会主动悬停生成进程,转而向搜索引擎发起实时数据查询请求10。模型会自动抓取、筛选并分析最新的现实世界数据、官方品牌 Logo 设计规范以及活动场馆的真实地理风貌,并将这些实时更新的真值(Ground Truth)注入到视觉合成管线中7。这使得 gpt—image—2 不仅是一个想象力引擎,更是一个具备事实核查能力的法证级视觉重现平台。
五、训练范式的重构:结构化合成数据与视觉 RLHF 对齐
再卓越的算法架构,如果没有高质量的训练数据作为给养,也只能产出平庸的结果。gpt—image—2 在文本排版和复杂界面生成上的降维打击,直接反映了 OpenAI 在数据工程流水线上的彻底革新。
5.1 从粗糙图文对向代码驱动的合成管线(Synthetic Pipelines)跃升
以往的视觉模型主要依赖于从互联网上抓取的数以十亿计的图像—文本对(如 LAION 及其衍生数据集)。这些数据集的特征是规模巨大但信噪比极低——图像通常只配备了几句粗略描述,完全缺乏对图像内部细粒度几何结构、文本内容、绝对坐标以及字体属性的元数据标注。如果模型在训练中从来没有被明确告知一张海报上具体哪个像素块对应哪个英文字母,那么它自然无法学会正确的书写。
为了赋予 gpt—image—2 精确渲染多语言致密文本(Dense Text)和 UI 控件的能力,研究团队采用了类似 ChartNet 框架的“代码引导的合成数据生成管线”(Code—guided synthesis pipeline)20。 在此管线下,模型训练所用的并非单纯的抓取图片,而是由自动化脚本批量渲染出的数百万个高保真复杂场景(涵盖学术图表、金融仪表盘、企业级网页原型、印刷级杂志封面等)。更为关键的是,这种合成手段能够同步产出极度丰富的结构化元数据(Structured Metadata)20。每一张训练样本在进入神经网络时,都附带了极其详尽的 JSON 格式解析树:不仅描述了图像包含一只杯子,还明确标注了杯子上印制的文本字符串内容、精确的二维包围盒(Bounding Box)坐标、排版行距参数甚至所使用的字体类别20。 在极其严苛的损失函数逼迫下,模型不再仅仅是将像素随机排列以欺骗判别器,而是被迫理解了各种人类文字(从拉丁字母的平滑曲线到汉字的复杂拓扑,再到阿拉伯语和印地语的连写规则)的几何本质和排版规范10。实测结果证明,这种基于结构化合成数据的监督学习,使得 gpt—image—2 在生成复杂的日文漫画分镜对话框或韩文商业宣传单时,能够展现出与母语设计师无异的排版水准1。
5.2 重塑视觉审美:基于人类反馈的视觉强化学习(Vision RLHF)
技术层面的精准只是及格线,而商业层面的成功则需要模型具备高级的审美意趣。在生成式 AI 领域,消除机器生成的“塑料感”(Plastic feel)和“生硬拼接感”一直是一个玄学难题。为此,OpenAI 将此前在 LLM 领域大放异彩的强化学习人类反馈(RLHF)技术,深度适配并引入到了高维图像生成领域35。
在预训练结束后的对齐阶段,OpenAI 构建了极其庞大的视觉奖励模型(Reward Models, RMs)36。研究团队收集了数以百万计的、由专业设计师和艺术家提供的人类偏好排序数据。当模型面对相同的提示词生成多个候选图像时,人类评估者会根据极其严苛的设计基准——如主体焦点是否突出、文字边缘对比度是否易读、色彩搭配是否符合色彩心理学、背景光斑(Bokeh)是否自然、以及整体构图的和谐性——进行打分1。 随后,系统运用近端策略优化(PPO)等高级强化学习算法,不断利用奖励模型来微调生成策略引擎。这种持续的非监督梯度惩罚机制,强行扭转了模型对劣质像素和常见伪影的拟合倾向36。经过 RLHF 深度洗礼的 gpt—image—2,仿佛在内部形成了一个虚拟的“艺术总监”,其输出的图像不再是冰冷元素的机械堆砌,而是展现出极强的情感张力、恰如其分的留白艺术,以及符合商业级发表标准的“视觉品味”(Visual Taste),彻底跨越了人工智能生成的恐怖谷(Uncanny Valley)1。
六、基础设施突破:计算效率优化与智能路由部署
将一个拥有极其庞大参数量且需要处理 4K 分辨率的混合模态巨兽推向全球数亿规模的 API 市场和 C 端应用,绝不仅是算法实验室里的纸上谈兵。这需要极其恐怖的基础设施工程优化能力。gpt—image—2 在保持极高质量输出的同时,成功实现了商业化级别的低延迟和规模化并发。
6.1 推理架构优化:MXFP4 量化与 H100 硬件极限压榨
尽管 gpt—image—2 的模型结构比其前代产品复杂了数个数量级,但其实际生成时间却被大幅压缩。测试数据显示,在常规质量设定下,生成一张标准图像的耗时仅约 3 秒,其运行速度相比过渡版本 GPT—Image—1.5 提升了近两倍,更是远超需要 10—15 秒渲染时间的竞品(如 Google 的 Nano Banana Pro)9。
这种反常识的性能飙升,源于极端的模型量化技术与底层硬件架构的完美融合。相关技术分析和针对同架构开源模型的拆解表明,支撑 gpt—image—2 推理底座的核心引擎广泛采用了极其前沿的 MXFP4(Micro—scaling Formats 4—bit)原生量化格式27。 这种微缩放格式使得模型能够将每个浮点参数的精度极限压缩至平均约4.25 位。通过精巧的缩放因子分配,模型在几乎不遭受任何生成保真度退化的前提下,将显存(VRAM)的物理占用削减了高达 75%41。这种极其夸张的内存带宽节约,使得 OpenAI 能够将庞大的自回归与 DiT 混合流,完整加载到单张 NVIDIA H100 GPU 的高速显存内进行无缝吞吐,彻底消除了跨节点通信延迟27。这种系统级的算力榨取,不仅保障了服务的高可用性,也使得 API 调用的单次成本被严格控制在了具有极高商业竞争力的范围(输入 Token 为 8 美元/百万,输出 Token 为 30 美元/百万)8。
| 模型 | 推理延迟 (标准分辨率) | VRAM 占用与硬件要求 | 量化技术推测 |
| DALL—E 3
|
|
|
|
| GPT—Image—1.5 |
|
|
|
| gpt—image—2 |
|
|
|
6.2 智能路由层:API 的动态算力分配机制
为了应对多模态应用中千变万化的用户需求,避免计算资源的闲置或浪费,OpenAI 为 gpt—image—2 设计了一个极具创新性的“智能扩展路由层”(Intelligent Routing Layer)8。这使得底层服务平台(如 Azure AI Foundry 和 OpenRouter)可以动态地为每一个单独的 API 请求分配最合理的系统资源,而无需开发者手动干预配置。
该路由层提供了两套并行的调度模式:
-
1. 模式1:传统尺寸映射(Legacy Size Selection)。 为了确保旧系统的无缝迁移,路由层可以拦截请求并自动匹配历史规格,将资源消耗划分到 smimage(小尺寸)、image(标准尺寸)和 xlimage(大尺寸)三个层级8。 -
2. 模式2:Token 容量桶动态调度(Token Size Bucket Selection)。 这是一个全新的精细化算力调配策略。系统基于提示词的语义复杂度和空间维度要求,在极短时间内计算出输出潜力,随后将任务动态派发到六个离散的 Token 桶中(容量分别为16,24,36,48,64, 96 桶)8。例如,生成一个没有复杂纹理和文本的抽象几何背景可能会被分发到极其轻量的 16 桶(近似映射回 smimage 规模);而当接收到一个长达千字、要求生成带有数十行多语言文字排版的 4K 复杂信息图表(Infographic)指令时,系统会瞬间激活 96 桶的满载算力(对应超配的 xlimage 容量)。这种架构不仅极致优化了系统的吞吐量,还确保了每一美元算力都花在刀刃上,提升了长尾极端指令的交付成功率8。
ℹ
提示
三大商业化能力:① 原生4K输出(4096×4096,宽高比≤3:1,无需后处理升采样)② 内嵌C2PA数字水印(防篡改凭证+加密指纹,法庭证据级溯源基础设施)③ Token容量桶动态调度(6个离散Token桶16/24/36/48/64/96,极简资源调配)
七、商业化能力重塑:原生 4K 解析、溯源防御与竞品降维打击
技术上的底层突破最终转化为产品侧的统治力。gpt—image—2 不仅在质量上确立了新标杆,更在商业合规性、工业级部署标准和竞品对比中展现出碾压性优势。
7.1 打破升采样魔咒的原生 4K 输出
长期以来,AI 图像模型在面对广告喷绘、印刷出版等高解析度应用场景时显得力不从心。早期的 DALL—E 系列和第一代模型通常只能在 1024×1024 或类似的低清像素网格中完成生成,当用户需要更高清的图像时,必须依赖于后处理系统中的升采样放大器(Upscaling Pipeline)。这种“注水”行为不可避免地会导致高频微小细节的严重劣化、文本边缘的模糊以及噪点伪影的放大13。
得益于混合自回归架构中 DiT 组件的高效合成能力,gpt—image—2 正式实现了真正的“单次前向原生 4K 分辨率”(Native 4K Resolution)。它不需要任何二次放大的妥协,能够在生成通道中直接输出高达 4096×4096 甚至更为极端的超高清解析度8。 不仅如此,OpenAI 彻底放开了僵化的宽高比例限制。系统遵循一个极度弹性的维度计算公式:只要请求的图像任何一边不超过极值 3840 像素,且长边与短边之比不超过3:1,同时两条边都严格对齐为 16 的倍数,模型即可在庞大的像素预算区间(655,360 像素底线至8,294,400 像素上限)内生成任何自定义尺寸的图像8。这意味着营销团队可以在单次 API 会话中,无缝输出能够完美适应 Instagram(1:1)、TikTok(9:16)、YouTube 封面(16:9)等各种不规则宽高比的商业物料10。
| 关键尺寸规则 | 技术参数红线限制 |
| 单边像素上限 |
|
| 像素数总预算 |
|
| 分辨率对齐法则 |
|
| 极限长宽比控制 |
|
7.2 内嵌数字水印:对抗知识产权诉讼的法律防御基建
在这个处于全球监管聚光灯下的时代,一项突破性的人工智能技术仅仅做到“好用”是远远不够的,它必须做到“合规”且“合法”。在 gpt—image—2 发布之际,OpenAI 及其主要合作伙伴在欧美面临着极其严峻的版权侵权诉讼(Litigation overhang),多方指控其在训练集构建过程中未经授权使用了受版权保护的商业素材9。
为了在法律风暴中建立起一道商业防火墙,并打消企业客户对于资产侵权风险的顾虑,gpt—image—2 放弃了前代产品“事后补救”的策略,直接在底层神经架构中融合了下一代出处分类器(Provenance Classifiers)和类似 SynthID 级别的隐藏不可见数字水印机制9。 每当模型渲染一张商业级图像时,它会自动在文件的深层元数据中烧录防篡改的 C2PA 凭证,并在像素的高频空间中织入人眼不可察觉但可通过特定算法识别的加密指纹序列48。这种法庭证据级的溯源基础设施(Provenance Tooling),使得任何一张由 gpt—image—2 生成的物料都具备了一条清晰且在法律意义上可防守的证据链条(Defensible paper trail)9。这一突破不仅表明 OpenAI 在技术上趋于成熟,更向全球企业用户和监管机构释放了其拥抱“负责任的人工智能(Responsible AI)”的战略信号,从而彻底扫清了企业级市场大规模采纳该技术的法律障碍。
7.3 横向对比:对行业竞品的代差碾压
将视角拉长,gpt—image—2 的综合表现实际上已经打破了整个多模态领域的生态平衡。在此之前,行业内普遍存在性能妥协。例如,早前退役的 DALL—E 3 依赖简单的提示词拼接,常出现意象的生硬揉捏且根本无法解决乱码问题12;Google DeepMind 的 Imagen 3 虽然在光影的临床级真实感和材质表现上独树一帜,并针对企业批量操作推出了“Fast”变体,但在复杂多条件约束提示词的遵循度和长文本的生成稳定性上存在显著的逻辑缺陷3。
而目前市场上唯一被认为能对 gpt—image—2 构成实质性挑战的模型,是 Google 在 2025 年末推出的“Nano Banana Pro”(即 Gemini3.1 Flash Image 系统)14。该模型不仅首创了原生 4K 支持,还具备令人瞩目的 14 张多图参考编辑能力以及强大的 SynthID 鉴真系统39。 然而,在经过广泛的盲测与高压提示词的严格评估后,业内一致认为 gpt—image—2 实现了“弯道超车”。当面临极其严苛的致密文本渲染测试(Dense Text Rendering,例如生成密密麻麻的网页长文截图或精细包装的营养成分表标签)时,Nano Banana Pro 开始出现字母换位或扭曲的衰退现象,而 gpt—image—2 则凭借其坚如磐石的自回归加 DeepStack 架构保持着近乎绝对的保真度3。这种对文本信息的统治级控制力,标志着视觉大模型从单纯的“艺术图像生成”进入了严肃的“信息资产制造”阶段。
终极判断
gpt-image-2的诞生宣告生成式AI跨过”艺术试玩”的门槛,成为重塑商业文明和知识传播底座的核心”生产力基础设施”
当图像中的微小文字可以达到99%的绝对清晰,当系统可以根据一句话瞬间渲染出可用级别的产品UI原型、带有繁复中日韩文字系统的跨国海报时,对于全球技术生态参与者而言,适应并利用这一”视觉思维伙伴”将不再是可选项,而是维持商业竞争优势的绝对必要条件。
八、结论与工业界深远影响的展望
纵观全局,OpenAI 推出的 gpt—image—2 之所以能够取得震撼行业的颠覆性突破,其本质原因在于研发理念的彻底转变。它不再迷信传统图像生成领域中“单纯扩充扩散模型参数规模”的线性延展路径,而是以前所未有的气魄,将大语言模型(LLM)的严密推理引擎深度植入到了高维度的像素海洋中。
从架构上看,9B 自回归引擎与 7B 扩散解码器的完美嵌合,将长跨度空间规划与高频像素合成的职责进行了高度专业化的解耦,一举消灭了困扰行业数年的“文本乱码”死局;在特征感知层面,Interleaved—MRoPE 彻底修复了多维空间感知的降维缺陷,而 DeepStack 技术则成功避开了早期的 OCR 路由劫持陷阱,让抽象语义能够完美穿透到亚像素级的物理边界;在认知体系上,带有自我反思与网页验证功能的四步链式“思考机制”,让机器真正懂得了物理法则与客观真理;最后,由合成数据管线与大规模视觉 RLHF 构成的严酷训练场,塑造了其超越常人的排版直觉和视觉美学品味。加上底层极致压榨 H100 效能的 MXFP4 量化部署、智能化的扩展路由分发机制,以及能够抵御商业法律诉讼的出处溯源系统,这一切共同缔造了一个没有明显短板的多模态巨无霸。
gpt—image—2 的诞生,绝非仅仅是为设计师提供了一把更为锋利的修图工具,而是正式宣告了内容生产与软件工程工作流的全面重构。当图像中的微小文字可以达到 99% 的绝对清晰,当系统可以根据一句话瞬间渲染出可用级别的产品 UI 原型、带有极其繁复中日韩文字系统的跨国海报,且保持极致的风格连贯性时,生成式 AI 便跨过了“艺术试玩”的门槛,成为重塑商业文明和知识传播底座的核心“生产力基础设施”。对于全球的技术生态参与者而言,迅速适应并深入利用这种兼具高阶逻辑推理与极端像素级精细控制的“视觉思维伙伴”,将不再是一个前卫的技术实验选项,而是维持其商业生存能力与核心竞争优势的绝对必要条件。
一句话总结
gpt-image-2的成功本质在于研发理念的彻底转变——不再迷信单一模型规模的线性延展,而是将LLM的严密推理引擎深度植入高维像素海洋
9B AR + 7B DiT的混合架构解决空间规划问题,Interleaved-MRoPE解决坐标感知问题,DeepStack解决OCR路由瓶颈问题,视觉CoT解决思考验证问题,Vision RLHF解决审美问题。每一层都在补足前一代技术的致命短板,最终催生了一个没有明显短板的多模态巨无霸。
深度技术报告
关注获取更多AI技术深度分析
持续跟踪多模态大模型、视觉生成、AI基础设施等前沿技术发展与工程实践分析。
本文基于OpenAI官方文档、LM Arena、arXiv及多家技术媒体的公开资料综合整理
引用的著作
-
1. OpenAI launches ChatGPT Images2.0 with improved text rendering: Availability, price and more, 访问时间为 四月23, 2026, https://timesofindia.indiatimes.com/technology/tech—news/openai—launches—chatgpt—images—2—0—with—improved—text—rendering—availability—price—and—more/articleshow/130431396.cms -
2. GLM—Image User Guide: Production—Ready Integration — Fal.ai, 访问时间为 四月23, 2026, https://fal.ai/learn/devs/glm—image—user—guide—production—integration -
3. GPT Image 2 vs Imagen3: Which AI Image Generator Wins in 2026 …, 访问时间为 四月23, 2026, https://www.mindstudio.ai/blog/gpt—image—2—vs—imagen—3 -
4. GPT Image2: Why Text Rendering in AI Images Is the Real Breakthrough — Beginners, 访问时间为 四月23, 2026, https://discuss.huggingface.co/t/gpt—image—2—why—text—rendering—in—ai—images—is—the—real—breakthrough/175377 -
5. GPT—Image—2 Leak: Is This the Next Breakthrough in AI Image Generation?, 访问时间为 四月23, 2026, https://www.vasundhara.io/blogs/gpt—image—2—leak—ai—image—generation—breakthrough -
6. ChatGPT Images2: Why OpenAI Built a New Image Model After Killing Sora, 访问时间为 四月23, 2026, https://www.cnet.com/tech/services—and—software/chatgpt—images—2—release—openai—news/ -
7. OpenAI's ChatGPT Images2.0 is here and it does multilingual text, full infographics, slides, maps, even manga — seemingly flawlessly | VentureBeat, 访问时间为 四月23, 2026, https://venturebeat.com/technology/openais—chatgpt—images—2—0—is—here—and—it—does—multilingual—text—full—infographics—slides—maps—even—manga—seemingly—flawlessly -
8. Introducing OpenAI's GPT—image—2 in Microsoft Foundry, 访问时间为 四月23, 2026, https://techcommunity.microsoft.com/blog/azure—ai—foundry—blog/introducing—openais—gpt—image—2—in—microsoft—foundry/4500571 -
9. OpenAI launches GPT—Image—2 with near—perfect text rendering and …, 访问时间为 四月23, 2026, https://startupfortune.com/openai—launches—gpt—image—2—with—near—perfect—text—rendering—and—twice—the—speed—of—its—predecessor/ -
10. GPT—image—2 officially released: A complete beginner's guide to OpenAI's next—generation image generation model — Apiyi.com Blog, 访问时间为 四月23, 2026, https://help.apiyi.com/en/gpt—image—2—official—launch—beginner—complete—guide—en.html -
11. With the launch of ChatGPT Images2.0, OpenAI now "thinks" before …, 访问时间为 四月23, 2026, https://thenewstack.io/chatgpt—images—20—openai/ -
12. Azure OpenAI image generation models — Microsoft Learn, 访问时间为 四月23, 2026, https://learn.microsoft.com/en—us/azure/foundry/openai/how—to/dall—e -
13. Goodbye DALL—E: Enter GPT Image 2 | SuperMaker AI, 访问时间为 四月23, 2026, https://supermaker.ai/blog/gpt—image—2—guide/ -
14. ChatGPT Images2.0 — Hacker News, 访问时间为 四月23, 2026, https://news.ycombinator.com/item?id=47852835 -
15. GLM—Image Prompt Guide: Mastering Text—to—Image Generation with Precision — Fal.ai, 访问时间为 四月23, 2026, https://fal.ai/learn/devs/glm—image—prompt—guide -
16. Introducing OpenAI GPT Image 2 Text—to—Image on WaveSpeedAI, 访问时间为 四月23, 2026, https://wavespeed.ai/blog/posts/introducing—openai—gpt—image—2—text—to—image—on—wavespeedai/ -
17. GPT Image2: Complete Guide to OpenAI's Image Model in 2026, 访问时间为 四月23, 2026, https://www.befreed.ai/blog/gpt—image—2—guide—2026 -
18. Call for Submission: Qwen3 VL MoE for MLPerf Inference v6.0 — MLCommons, 访问时间为 四月23, 2026, https://mlcommons.org/2026/02/vlm—inference—shopify/ -
19. Today, we officially launch the all—new Qwen3—VL series — the most powerful vision—language model in the Qwen family to date. In this generation, we've made major improvements across multiple dimensions: whether it's understanding and generating text, perceiving and reasoning about visual content, supporting longer context lengths, understanding spatial relationships and dynamic videos, or interacting with AI agents, 访问时间为 四月23, 2026, https://qwen.ai/blog?id=99f0335c4ad9ff6153e517418d48535ab6d8afef&from=research.latest—advancements—list -
20. Granite4.0 3B Vision: Compact Multimodal Intelligence for Enterprise Documents, 访问时间为 四月23, 2026, https://huggingface.co/blog/ibm—granite/granite—4—vision -
21. Interleaved—MRoPE: Multimodal Positional Encoding — Emergent Mind, 访问时间为 四月23, 2026, https://www.emergentmind.com/topics/interleaved—mrope -
22. Revisiting Multimodal Positional Encoding in Vision–Language Models — arXiv, 访问时间为 四月23, 2026, https://arxiv.org/html/2510.23095v3 -
23. Revisiting Multimodal Positional Encoding in Vision–Language Models — arXiv, 访问时间为 四月23, 2026, https://arxiv.org/html/2510.23095v1 -
24. Where Vision Becomes Text: Locating the OCR Routing Bottleneck in Vision—Language Models — arXiv, 访问时间为 四月23, 2026, https://arxiv.org/html/2602.22918v2 -
25. Where Vision Becomes Text: Locating the OCR Routing Bottleneck in Vision—Language Models — arXiv, 访问时间为 四月23, 2026, https://arxiv.org/html/2602.22918v1 -
26. Top Qwen—Image Alternatives in 2026 — Slashdot, 访问时间为 四月23, 2026, https://slashdot.org/software/p/Qwen—Image/alternatives -
27. Models — OpenRouter, 访问时间为 四月23, 2026, https://openrouter.ai/models -
28. IBM Releases Granite4.0 3B Vision: A New Vision Language Model for Enterprise Grade Document Data Extraction — MarkTechPost, 访问时间为 四月23, 2026, https://www.marktechpost.com/2026/04/01/ibm—releases—granite—4—0—3b—vision—a—new—vision—language—model—for—enterprise—grade—document—data—extraction/ -
29. ChatGPT Images2.0: Full Developer Breakdown (2026) — Build Fast with AI, 访问时间为 四月23, 2026, https://www.buildfastwithai.com/blogs/chatgpt—images—2—0—gpt—image—2—2026 -
30. OpenAI launches ChatGPT Images2.0, it can generate AI photos as good as real, 访问时间为 四月23, 2026, https://www.indiatoday.in/technology/news/story/openai—launches—chatgpt—images—20—it—can—generate—ai—photos—as—good—as—real—2899788—2026—04—22 -
31. Simon Willison on text—to—image, 访问时间为 四月23, 2026, https://simonwillison.net/tags/text—to—image/ -
32. GPT Image 2 | Image Generation and Editing API — Replicate, 访问时间为 四月23, 2026, https://replicate.com/openai/gpt—image—2 -
33. ChatGPT latest update: Finally gets text and object placement right in images, 访问时间为 四月23, 2026, https://www.hindustantimes.com/technology/chatgpt—latest—update—finally—gets—text—and—object—placement—right—in—images—101776861348731.html -
34. r/LLM — Reddit, 访问时间为 四月23, 2026, https://www.reddit.com/r/LLM/new/ -
35. Transparency Note for Azure OpenAI in Microsoft Foundry Models, 访问时间为 四月23, 2026, https://learn.microsoft.com/en—us/azure/foundry/responsible—ai/openai/transparency—note -
36. Reinforcement learning from human feedback — Wikipedia, 访问时间为 四月23, 2026, https://en.wikipedia.org/wiki/Reinforcement_learning_from_human_feedback -
37. Reinforcement Learning from Human Feedback (RLHF): A Practical Guide with PyTorch Examples | by Sam Ozturk, 访问时间为 四月23, 2026, https://themeansquare.medium.com/reinforcement—learning—from—human—feedback—rlhf—a—practical—guide—with—pytorch—examples—139cee11fc76 -
38. Interpreting Black Box Reward Models — OpenAI Alignment Blog, 访问时间为 四月23, 2026, https://alignment.openai.com/argo/ -
39. GPT—image—2 vs Nano Banana Pro In—depth Comparison: Will the strongest status of Banana Pro be shaken?, 访问时间为 四月23, 2026, https://help.apiyi.com/en/gpt—image—2—vs—nano—banana—pro—image—model—showdown—en.html -
40. OpenAI: GPT—5.4 Image 2 — API Pricing & Providers — OpenRouter, 访问时间为 四月23, 2026, https://openrouter.ai/openai/gpt—5.4—image—2 -
41. OpenAI Just Released gpt—oss: A Free LLM That Beats Most Paid Models | Fello AI, 访问时间为 四月23, 2026, https://felloai.com/openai—just—released—gpt—oss—a—free—llm—that—beats—most—paid—models/ -
42. It's amazing how OpenAI missed its window with the gpt—oss release. The models would have been perceived much better last week. : r/LocalLLaMA — Reddit, 访问时间为 四月23, 2026, https://www.reddit.com/r/LocalLLaMA/comments/1mj011h/its_amazing_how_openai_missed_its_window_with_the/ -
43. OpenAI launches ChatGPT Images2.0 to rival Google's Nano Banana2, 访问时间为 四月23, 2026, https://www.neowin.net/news/openai—launches—chatgpt—images—20—to—rival—googles—nano—banana—2/ -
44. GPT—5.4 Image 2 — API Pricing & Providers | OpenRouter, 访问时间为 四月23, 2026, https://openrouter.ai/models/openai/gpt—5.4—image—2 -
45. Tag:"azure ai" | Microsoft Community Hub, 访问时间为 四月23, 2026, [https://techcommunity.microsoft.com/tag/azure%20ai](https://techcommunity.microsoft.com/tag/azure ai) -
46. OpenAI gpt—image—2 Launches: Native 4K + 30% Price Cut — API易文档中心 — APIYI, 访问时间为 四月23, 2026, https://docs.apiyi.com/en/news/gpt—image—2—launch -
47. GPT Image Generation Models Prompting Guide — OpenAI Developers, 访问时间为 四月23, 2026, https://developers.openai.com/cookbook/examples/multimodal/image—gen—models—prompting—guide -
48. GPT—5.4 Nano — API Pricing & Providers — OpenRouter, 访问时间为 四月23, 2026, https://openrouter.ai/openai/gpt—5.4—nano -
49. I spent a week running the 'President Test' on GPT—Image—2. Here is …, 访问时间为 四月23, 2026, https://www.reddit.com/r/LLM/comments/1ssdn0v/i_spent_a_week_running_the_president_test_on/ -
50. GPT Image2: What We Know So Far About OpenAI's Next Image Model | ImagineArt, 访问时间为 四月23, 2026, https://www.imagine.art/blogs/what—is—gpt—image—2