 夜雨聆风
夜雨聆风





220万颗恒星,AI 一口气筛完!RAVEN 从 NASA 数据里「捞」出 100 多颗隐藏行星
Warwick 大学天文团队造了一条 AI 流水线 RAVEN,把 NASA TESS 卫星前四年拍到的 220 万颗恒星光变数据全部过了一遍——检测信号、机器学习排雷、统计验证,三步串联,直接确认 100 多颗系外行星,其中 31 颗是全新发现。最狠的部分:它找到了轨道周期不到一天的极端行星,还有理论上「不该存在」的海王星沙漠区天体。
AI 下场找行星,这次来真的
过去我们听到「AI + 天文」,脑子里浮现的画面大概是:大模型读了一堆论文,输出一段总结。
这次完全不同。
Warwick 大学的天文学家团队发布了一个叫RAVEN的系统,干的活儿是——直接从 NASA 的 TESS 卫星观测数据里,把藏在恒星光变曲线中的行星信号挖出来,验证它们到底是真行星还是误报,然后交给人类做最终确认。

▲ Wes Roth 转发了这条消息:RAVEN 验证了 100+ 系外行星,含 31 颗新发现
直接看数字:100 多颗系外行星被验证,31 颗是此前从未确认过的新世界。
这不再是 AI 在旁边打下手。它站到了科学发现链条的正中间。
220 万颗恒星,人眼根本看不过来
先说 TESS。
TESS 是 NASA 的凌日系外行星巡天卫星(Transiting Exoplanet Survey Satellite),2018 年发射,专门盯着天上的恒星看:如果一颗行星从恒星前面经过,恒星亮度就会出现一次微小的、周期性的下降。这叫凌日法(transit method)。

▲ NASA TESS 任务主页:这颗卫星已经进入延伸任务阶段
原理简单,问题在于规模。
TESS 前四年观测了超过220 万颗恒星。每颗恒星都有自己的光变曲线,里面可能有行星凌日信号,也可能是噪声、仪器误差、双星系统的假警报。几百万条曲线摆在那里,天文学家一条一条看?
不可能。
这就是 RAVEN 出场的理由。
RAVEN 做了什么:三步流水线,从信号到行星
RAVEN 的关键在于,它把过去需要不同团队、不同工具、分好几步完成的工作,压缩成了一条端到端的自动化流水线。
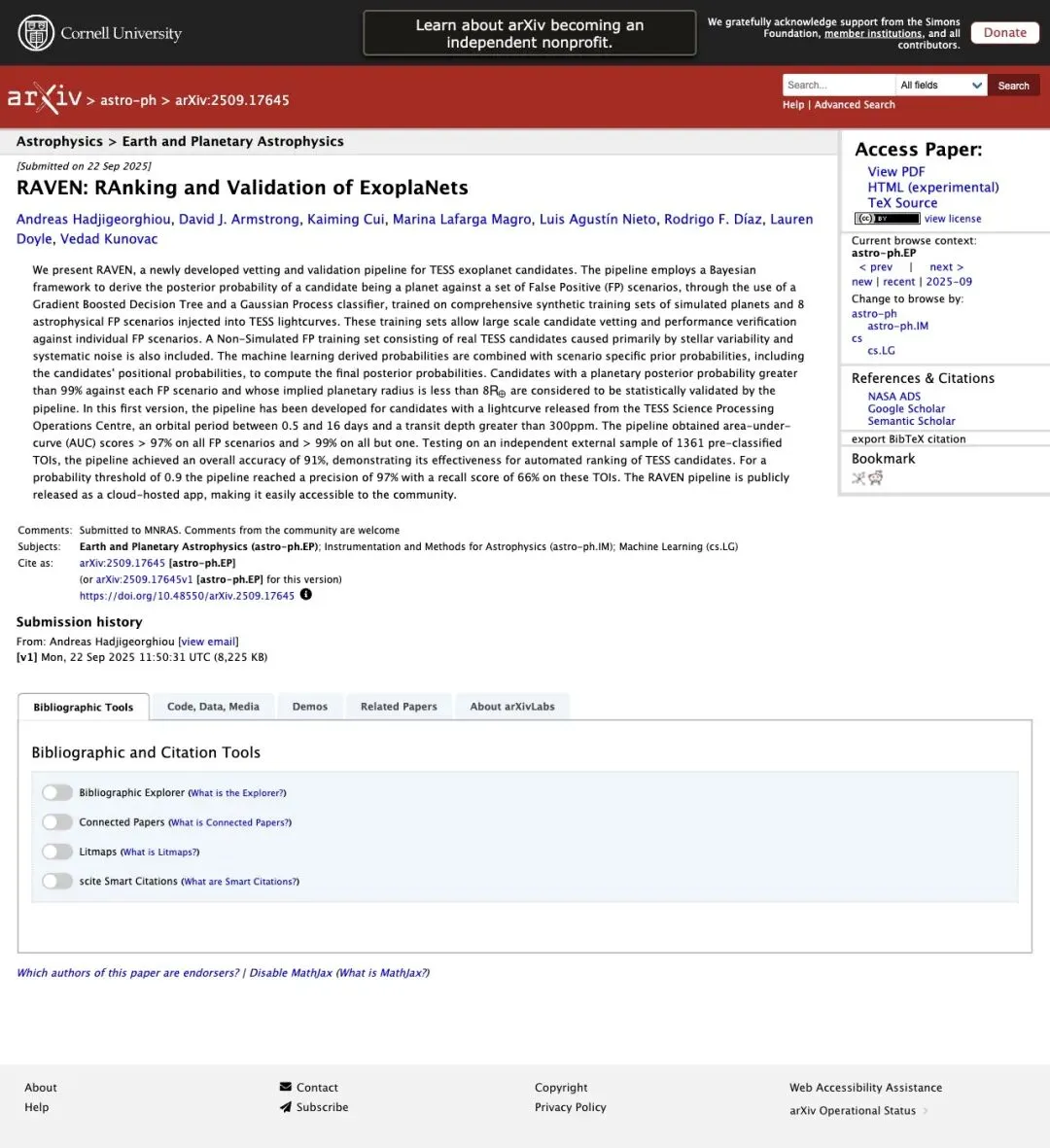
▲ RAVEN 论文已在 arXiv 发布,标题就叫”Ranking and Validation of ExoPlanets”
具体来说,三个阶段:
第一步:Detect(检测)。从 TESS 光变曲线里自动搜索可能的凌日信号。220 万颗恒星,RAVEN 把每一条都扫了。
第二步:Vet(排雷)。用机器学习模型把明显的假信号踢掉。最常见的误报来源是食双星(eclipsing binary stars)——两颗恒星互相遮挡,光变曲线和行星凌日长得很像,但本质完全不同。RAVEN 的模型专门训练过,能把这类噪声挡在门外。
第三步:Validate(验证)。对剩下的候选目标做统计验证,计算”这个信号确实来自行星”的置信度。只有通过验证的,才会被标记为已确认行星。
这三步跑完,RAVEN 从海量数据中确认了 100 多颗系外行星,并且识别出上千个值得进一步研究的候选目标。
31 颗新行星,有些在理论预言「不该存在」的地方
100 多颗验证行星里,最引人注目的是 31 颗此前从未被确认的新世界。
其中一部分是超短周期行星(ultra-short-period planets)——轨道周期不到一天,也就是说,这些行星绕主星一圈只需要不到 24 小时。它们离恒星近到难以想象,表面温度极高,对行星形成和迁移理论有重要意义。
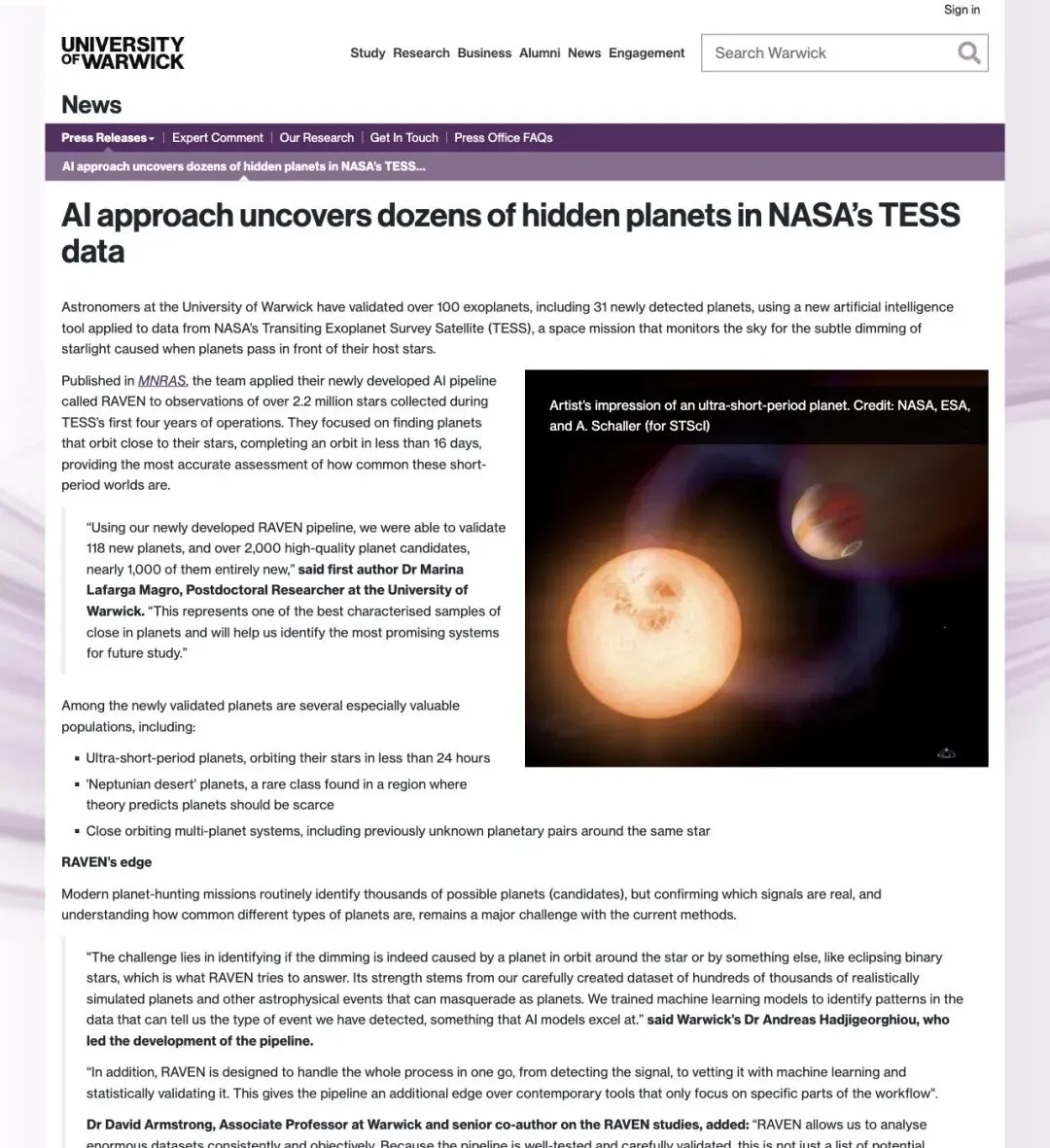
▲ Warwick 大学官方新闻稿:”AI approach uncovers dozens of hidden planets in NASA’s TESS data”
还有一个更有意思的类别:海王星沙漠(Neptunian desert)里的行星。
这个”沙漠”是天文学的一个理论预测区域。按理说,在离恒星很近的轨道上,海王星大小的行星应该极为稀少——因为恒星的强辐射会剥离行星外层大气,让它们没法保持海王星级别的气体包层。但 RAVEN 偏偏在这个区域找到了行星。
“Using our newly developed RAVEN pipeline, we were able to validate 118 planets, and over 2,500 other promising candidates, with nearly 1,000 of them orbiting bright stars — ideal targets for future atmospheric studies.”
「用我们新开发的 RAVEN 流水线,我们验证了 118 颗行星和超过 2500 个候选目标,其中近 1000 个围绕明亮恒星运行——它们是未来大气研究的理想对象。」
——Warwick 大学 Martin Callaghan 博士
这些发现不只是给天体目录加了几个编号。它们在测试我们对行星系统如何形成和演化的基本认知。
这件事的真正意义:AI 进入了「数据发现」环节
▲ Astronomy Now 报道标题:Artificial intelligence uncovers more than 100 new worlds in NASA data
回到更大的图景。
过去几年,AI 在科研里的角色大多是辅助性的——读论文、写代码、做实验设计、生成假设。但 RAVEN 干的事情不一样:它直接参与了科学发现本身。
天文学的结构性问题是:数据量远超人类的处理能力。TESS 一个卫星就产出了几百万条光变曲线,未来的巡天项目(比如 PLATO、Roman Space Telescope)数据量只会更大。如果每个候选信号都要人类手动筛查、交叉验证,真正卡住科学发现的,已经变成了”谁来看数据”。
RAVEN 给出了一个答案:让 AI 先把人类看不完的数据筛一遍,把最值得关注的候选对象推到研究者面前。
这个逻辑不只适用于天文学。蛋白质组学、气候科学、材料科学,都面临同样的困境——海量观测数据里藏着稀疏的异常信号,人眼和传统方法已经跟不上数据增长的速度。
RAVEN 验证了一个正在成形的范式:AI 处理噪声,人类做最终判断。科学发现的入口,正在被重新定义。
— END —