第34章 AI 软件栈全景
先说结论
AI 软件栈真正难的地方,不在于层数多,而在于每一层都在决定能力能否被下一层稳定接住。
从上层框架到底层编译、运行时和硬件执行路径,任何一层的错配都可能把纸面上的模型能力变成系统中的性能损耗和稳定性问题。
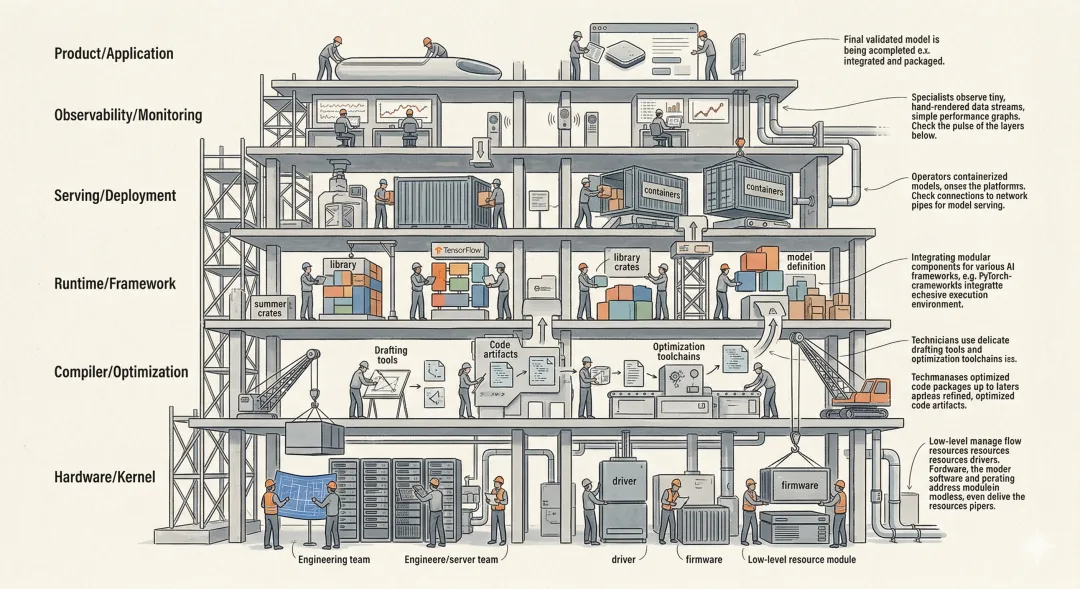
插图 第34章 AI 软件栈协同工地图
模型只是 AI 软件栈中最耀眼的一层,真正把能力送到用户手里的,是整条栈从上到下的共同配合。
1. 为什么必须单独画出这张全景图
如果只看新闻和演示,人们很容易误以为 AI 世界几乎等于模型世界。
这种看法在传播层足够有效,但在工程上会造成严重错觉。
因为一旦系统进入真实使用场景,问题会迅速分散到许多层:
如果没有一张完整的软件栈地图,团队很容易把所有问题都粗暴归类为“模型问题”或“硬件问题”。
而现实往往更复杂:真正的失真,常常发生在层与层之间。
所以这章的意义,不是再列一遍术语,而是帮助读者建立一种全栈视角。
图34-1 AI 软件栈不是一层模型,而是一条从表达走到交付的兑现链
这张图最重要的价值,在于把“模型在中间”而不是“模型等于全部”这件事看清。
上层决定问题如何被交给系统,下层决定问题如何被机器真正执行,旁边的观测和评测体系则决定这套链路能不能被长期维护。
2. 框架层解决的是“如何表达”和“如何组织实验”
研究者和工程师在这里定义模型结构、训练逻辑、损失函数、数据流和实验过程。
它让人不必直接面对每一条底层执行细节,而能在较高层次组织想法。
同时它也承担了实验管理和工作流组织的功能,让模型迭代成为可能。
它给出的是意图和结构,后面还有很长一条链路,要负责把这些意图压缩成真实执行。
把框架等同于整套 AI 软件栈,是许多认知混乱的源头。
图34-2 框架层负责表达意图和组织实验,但不直接兑现全部性能
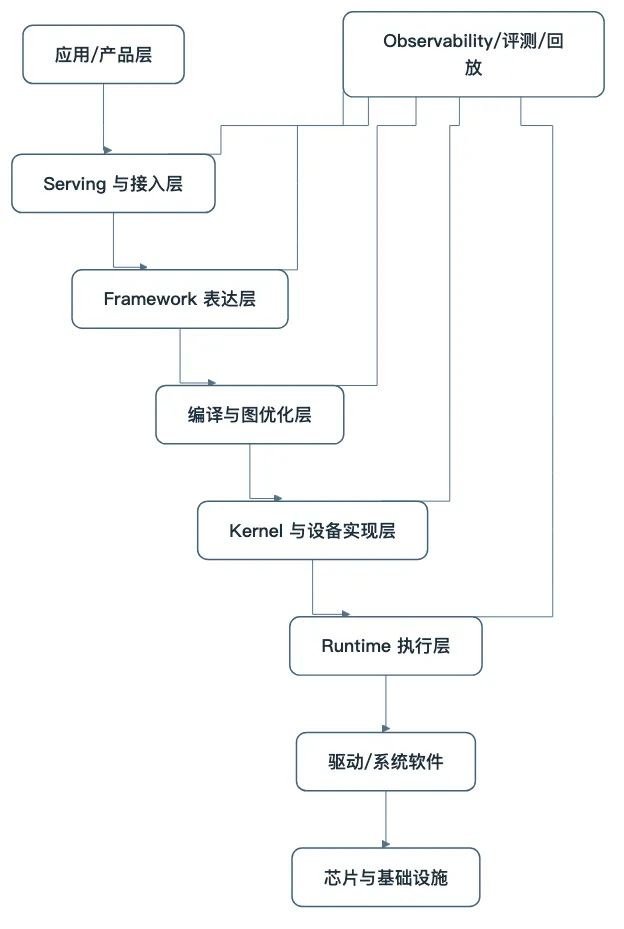
3. 编译层、kernel 层和 runtime 层,共同决定“能跑成什么样”
编译层负责把高层表达重新整理成更适合目标硬件的结构。
图优化、算子融合、布局变换、设备映射,都属于这一层的重要工作。
kernel 层负责把某个具体算子真正实现到足够贴近硬件。
它关心的是底层执行效率,是每一次矩阵乘、归约、拷贝、激活函数究竟如何落到设备上。
内存怎么管理、异步怎么推进、任务怎样排队、设备怎样协调、执行怎样复用,很多决定吞吐与延迟的细节都在这里。
同样一张模型图,最终究竟能在某块硬件上跑成什么样。
图34-3 编译、kernel、runtime 共同决定“同一模型最终能跑成什么样”
模型结构没变、芯片也没换,但系统性能还是可能差很多。真正变化的,往往正是中间这条兑现链。
4. Serving 与 observability,决定模型是研究对象还是产品能力
很多团队把主要精力投入到训练和推理本身,却低估了模型进入线上服务之后的复杂度。
Serving 层要解决的,不只是“把模型 API 暴露出来”,还包括:
没有前者,模型难以稳定服务;没有后者,团队无法长期维护。
图34-4 Serving 与 Observability 决定模型能否成为长期维护的产品能力
5. AI 工程真正难的地方,往往发生在层与层之间
很多人喜欢用单层视角理解系统,原因很简单:单层视角更容易归责。
效果不好,怪模型;速度不够,怪硬件;资源占用高,怪框架。
kernel 写得不错,但 runtime 调度差
这说明 AI 工程的本质,并不是某一层单独优秀,而是整条栈的协同质量足够高。
真正强的团队,通常不是只会训练模型,而是能够跨层理解问题、跨层定位问题、跨层优化问题。
很多组织之所以会在 AI 项目里长期低效,不是因为缺某一层专家,而是因为每一层都倾向于把问题往旁边推。框架层说是硬件没跟上,底层说是模型写得不友好,服务层说是 runtime 抖动,业务层说是模型能力不稳。全栈视角真正稀缺的地方,就在于它能阻止这种层间甩锅,把问题重新压回真实链路。
如果把这件事压得更工程一点,可以得到一组非常明确的连带关系:
编译、kernel、runtime 任何一层失真,都会把上层意图变成性能损耗或稳定性问题
serving 一旦排队和调度策略失效,再强的单机能力也会被堵成无响应队列
observability 如果无法定位问题根因,整条链就会越来越难维护
在这条长链里,从框架到底层驱动,只要其中任何一层失稳,问题就会沿着整条栈往上放大,最后在用户最容易看到的位置暴露出来。
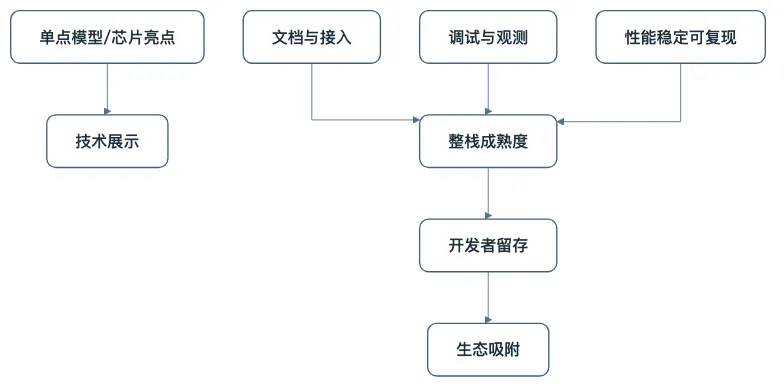
6. 平台竞争,表面比模型和芯片,深处比整条栈的成熟度
在产业竞争里,外界更容易关注模型排行榜和硬件峰值。
这些体验从来不是单层提供的,而是整条软件栈共同提供的。
所以许多平台最终胜出,并不只是因为某一个点特别领先,而是因为它们把整条链做得更顺、更稳、更可持续。
开发者真正记住的平台,也几乎总是那种“问题容易定位、性能大致可预期、升级不会反复打断工作”的平台。也就是说,软件栈成熟度的价值,最后会表现成一种很朴素的感受:这个平台值得把时间押上去。
软件栈的成熟度,往往决定平台能不能从“技术展示”走向“生态吸附”。
图34-5 平台竞争深处比的,是整条软件栈的成熟度而不是单点高光
7. 关于 AI 软件栈,几个高频误解
真正完整的栈还包括编译、kernel、runtime、serving、observability 等许多部分。
很多平台价值不是死在上限不够,而是死在中间层不成熟。
8. 这一章是上册软件部分的总收束
从程序与抽象,到编译器、操作系统、驱动、runtime,再到数据结构、分布式和云计算,我们其实一直在回答同一个问题:
AI 从来不是一个孤立模型,而是一整套层层兑现、层层约束、层层放大的软件体系。
下一章《软件定义硬件价值》会进一步把这张图和硬件世界重新接起来,为上册收束。
延伸阅读建议
推荐起点:Bryant / O’Hallaron《Computer Systems: A Programmer’s Perspective》、Hennessy / Patterson《Computer Architecture: A Quantitative Approach》适合把这些底层章真正串成系统。
继续延伸:Martin Kleppmann《Designing Data-Intensive Applications》适合继续补并发、分布式、数据中心和平台化这条现实主线。
检索关键词:computer architecture、ISA、compiler、operating system、distributed systems、data center。
9. 本章小结
AI 软件栈不是单一框架,而是由框架、编译、kernel、runtime、serving、observability 等多层构成。
编译层、kernel 层和 runtime 层共同决定模型在真实硬件上的执行质量。
Serving 和 observability 让模型从研究对象变成长期可维护的产品能力。
AI 工程真正的难点,常常发生在层与层之间,而不是某一层内部。
AI 的真实能力,从来不是由某一层单独创造出来的,而是由整条软件栈共同兑现出来的。
 夜雨聆风
夜雨聆风