夜雨聆风
夜雨聆风





企业内部知识助手实战(上):从 6 份制度文档跑通一条完整 RAG 链路
本文重点
01这篇只讲一个可运行项目:企业内部知识助手。
02重点不是贴代码,而是拆清楚完整 RAG 链路。
03权限很重要,但它只是文档治理、检索、生成和评测中的一环。
04这一篇是上篇:先把 baseline 项目讲透,下篇再接 LangFlow、LangChain、LangGraph 和 LangSmith。
老板视角
企业知识库不是“把资料塞进 AI 里”,而是把企业的制度、流程、经验和决策沉淀成一层可被模型使用的组织记忆。
01把知识变成资产
制度、流程、项目经验、客户资料和历史决策,不再散在群聊、网盘和少数人脑子里,而是变成可查询、可追溯、可授权的组织知识层。
02减少关键人依赖
老板真正关心的不是员工能不能问机器人,而是业务不再卡在“谁知道”“问哪个部门”“之前怎么定的”这些信息摩擦上。
03统一管理口径
差旅、费用、合同、IT 权限、薪酬、预算这些规则,必须让不同部门得到同一套有来源、有版本、有权限边界的答案。
04看见组织盲区
哪些问题被反复追问、哪些问题没有答案、哪些制度互相冲突、哪些知识已经过期,都会变成管理层可以持续改进的信号。
对老板来说,企业知识库的价值不是“问答体验更炫”,而是让组织里的知识可以被复用、被审计、被度量,并最终降低管理成本。
一句话结论
企业内部知识助手不是“向量库 demo”,而是一条从文档治理到检索、生成、权限和评测的完整工程链路。
先说结论。
关键判断
企业 RAG 不是“向量库 + prompt”。
它更像一条工程流水线:文档源进入系统后,先做文档解析和 metadata 建模,再做 chunk、embedding 和索引;用户提问时,系统会做 query rewrite、hybrid retrieval、rerank 和上下文组装;最后才进入 answer generation、引用控制、格式控制、拒答和评测回归。
权限过滤在这条链路里很关键,但它不是全部。真正难的是:每一层都会影响最终答案质量。
这次我们用一个可运行项目来讲:enterprise-rag-knowledge-assistant/。
读者拿到 GitHub 仓库后,不需要先理解全部代码,只要完成四件事:安装依赖、建立索引、分别用普通员工和 HR 身份提问、最后跑一次评测集。
当前这版项目的实际运行结果如下:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
| 召回
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这个结果不是说 demo 已经生产可用。
它说明:我们先用一个最小但完整的项目,把企业 RAG 该有的技术切面跑出来。
一、为什么选“企业内部知识助手”
如果只是做 PDF QA,项目很容易变成:
1.切文档。
2.入向量库。
3.召回 top-k。
4.塞给模型回答。
这个流程能演示 RAG,但解释不了企业里真正麻烦的问题。
企业内部知识助手更适合做实战样例,因为它天然包含多种 RAG 难点:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这个项目里的数据源就是 6 份内部制度文档:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以这不是“权限系统文章”,而是完整 RAG 项目文章。权限只是其中一个安全层。
二、完整项目怎么切分

项目目录对应的是一条 RAG 链路。看代码时,不要先看某个类怎么写,而要先看这些工程职责有没有拆开:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这张表比任何架构图都重要。
关键判断
企业 RAG 不是一个函数,而是一组可替换、可评测的模块。后面无论接 LangChain、LangGraph、Qdrant、LangSmith,边界都应该清楚。
三、文档解析:先把文件变成带治理信息的数据对象

很多 demo 会直接把文件内容读出来,然后切 chunk。
企业 RAG 不能这样做。
原因是:企业文档不是普通文本,它至少带有这些信息:
1.文档 ID。
2.标题。
3.所属部门。
4.密级。
5.允许访问的角色。
6.允许访问的用户。
7.版本号。
8.生效日期。
比如薪酬制度这类敏感文档,进入索引前不能只保存正文,还要保存一组治理字段:它属于 HR 部门,密级是 confidential,只允许 HR 和财务角色访问,版本是 2026 版,生效日期是 2026 年 1 月 1 日。
这些字段不是给文章看的。
它们会直接影响:
|
|
|
|---|---|
| doc_id |
|
| title |
|
| department |
|
| security_level |
|
| allowed_roles |
|
| allowed_users |
|
| version |
|
| effective_date |
|
项目里的 loader 会校验这些字段,缺少必要 metadata 就直接报错。
这条规则很朴素,但很关键:
没有 metadata 的文档,不应该进入企业 RAG 索引。
生产里,文档解析可以替换成 Unstructured、Docling、LlamaParse、LangChain DocumentLoader,或者 SharePoint / Google Drive / Confluence connector。
但无论底层工具怎么换,最后都要落成一个带 metadata 的文档对象。
四、Metadata:不只是权限,也是检索、引用和评测底座
很多人把 metadata 只理解成权限。
实际上,metadata 在 RAG 里有四个作用:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
项目里的 chunk 不只是 content 和 embedding。
它还保留:
|
|
|
|---|---|
| chunk_id |
|
| doc_id |
|
| title |
|
| section |
|
| department |
|
| security_level |
|
| allowed_roles |
|
| allowed_users |
|
| version |
|
| effective_date |
|
| contextual_text |
|
比如模型回答“普通员工在上海出差,住宿标准上限为每晚 650 元”时,用户还需要知道这句话来自哪里。
所以答案里会带来源信息,例如:来源:《差旅报销制度 2026》/城市住宿标准/v2026.1。
这不是靠模型凭空生成的,而是靠 metadata 支撑的。
五、Chunk:不能只按字数切,要保留业务边界
Chunk 是 RAG 里最容易被低估的一层。
很多 demo 会按固定字符数切,比如 500 字一个 chunk,重叠 50 字。
这在普通文章里可能能用,但在企业制度里很危险。
比如差旅制度里的“城市住宿标准”同时包含一线城市定义、普通员工上海住宿上限 650 元、部门负责人上海住宿上限 850 元。
这段应该尽量作为同一个语义块存在。
如果硬切,可能只剩一句“部门负责人在上海出差,住宿标准上限为每晚 850 元”。
这句话本身没错,但上下文不完整:
1.哪份制度?
2.哪个章节?
3.哪个版本?
4.普通员工标准是多少?
5.一线城市定义是什么?
项目里的做法是:
1.先按二级标题 ## 切 section。
2.section 太长时,再按段落切。
3.给每个 chunk 加 contextual text。
一个普通 chunk 只包含正文。
一个 contextual chunk 会额外带上文档名、章节、部门、密级、版本和生效日期,例如“文档《差旅报销制度 2026》;章节:城市住宿标准;版本:v2026.1;生效日期:2026-01-01”。
Anthropic 的 Contextual Retrieval 讨论的正是这个问题:chunk 脱离文档上下文以后,检索和回答都会变差。
所以 chunk 不是随机文本碎片。
它应该是 可引用、可授权、可解释的证据单元。
生产中还可以继续升级:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
六、Embedding:先用可复现 baseline,再换真实模型
这个项目没有一开始就接 OpenAI、Gemini 或 BGE。
它先用本地 hash embedding 做 baseline。
原因很简单:GitHub 用户不用 API key、不下载模型,也能跑完整链路。
这不是生产 embedding,但它保留了真实 embedding 的接口:文本进入模型,变成向量,再用于相似度召回。
生产里可以替换成:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
OpenAI 官方文档里,text-embedding-3-small 默认 1536 维,text-embedding-3-large 默认 3072 维,也支持通过 dimensions 参数降维。
但 embedding 选择不是“维度越大越好”。
真实要权衡:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以 embedding 要和 chunk、query rewrite、rerank、eval 一起调。
单独换一个更贵模型,不一定解决问题。
七、索引层:dense、sparse、metadata filter 要一起考虑

当前项目为了可运行,把索引存成本地文件。
它里面保存:
1.schema version。
2.embedding model 名称。
3.向量维度。
4.chunks。
5.每个 chunk 的 metadata。
6.每个 chunk 的 embedding。
生产里,这一层通常会换成真实存储:
|
|
|
|---|---|
| pgvector |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
选型时不要只问“谁性能最好”。
更实际的问题是:
1.metadata filter 好不好用?
2.能不能按租户、部门、角色过滤?
3.dense vector 和 sparse search 能不能混合?
4.权限变更后,索引怎么同步?
5.删除文档后,向量和缓存是否能删除?
6.trace 里能否记录检索细节?
7.备份恢复怎么做?
RAG 的索引层不是“存向量”这么简单。
它是召回、权限、成本和运维的交叉点。
八、BM25:兜住金额、编号、岗位、城市这些精确词
企业知识库里有很多精确词。
比如:
1.P6
2.1000 元
3.90 天
4.上海
5.系统 Owner
6.VP
7.12%
8.18%
这些词靠 embedding 不一定稳。
所以项目实现了一个简化 BM25。
分词时会抽:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
BM25 的价值是:
当用户问题里有金额、编号、岗位、城市、制度关键词时,系统不能只依赖语义相似。
Anthropic 在 Contextual Retrieval 里也强调过 contextual BM25 的价值,尤其是错误码、专有名词、精确字符串这类场景。
在企业 RAG 里,BM25 不是过时技术。
它是 embedding 的必要补充。
九、Hybrid retrieval:不是口号,而是多路信号合并
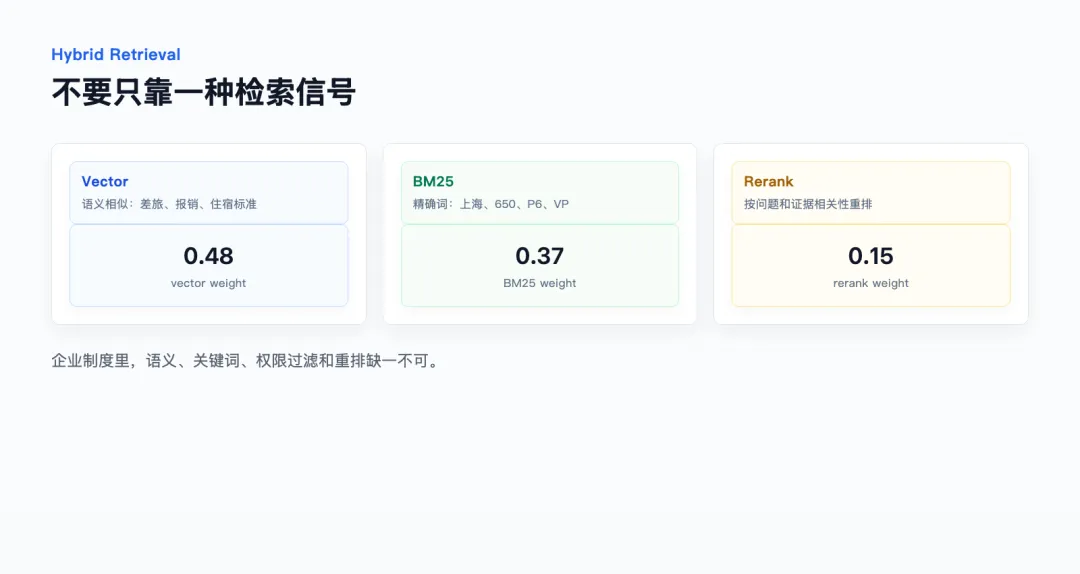
项目里的 hybrid retrieval 由三路信号组成:
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
也就是说,最终排序不是只看向量相似度。
这个设计是为了覆盖三种情况:
语义问题。 “出差酒店能报多少”不一定直接出现“住宿标准”,vector 有帮助。
精确问题。 “P6”“1000 元”“90 天”必须靠 BM25 兜底。
业务规则。 如果 chunk 的 section 是“住宿”“发票”“VPN”“薪酬”“预算”“合同”,它应该在相关问题里获得一定加分。
当前 rerank 是规则版,不是生产版。
生产里可以换成:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
这里最重要的是接口意识:
初召回、rerank、最终上下文,不应该混成一步。
十、Query rewrite:能提高召回,也会制造误伤

Query rewrite 的作用是把用户自然语言补成更适合检索的表达。
比如用户问:“我去上海出差,酒店一晚最多能报多少?”
系统会补一条改写,例如:“上海、一线城市、差旅、住宿标准、住宿上限、报销”。
实际 debug 召回里,第一名是 travel_policy_2026#s02p01,章节是“城市住宿标准”,分数是 0.959。
这说明 query rewrite 对召回有帮助。
但它也会误伤。
我在调项目时遇到过一个真实问题:早期规则里只要看到“审批”,就扩展“合同审批、法务、财务、VP”。结果用户问 VPN 审批时,会误召回合同制度。
所以 query rewrite 不是越多越好。
它必须被 eval 约束。
每次改写规则变化,都应该重新跑完整评测集。
如果 recall_at_k 变好,但 required_terms_rate、forbidden_retrieval_rate 或答案质量变差,就不能上线。Query rewrite 的价值不是“看起来更聪明”,而是在不扩大误召回和安全风险的前提下,提高真实业务问题的命中率。
十一、Context assembly:召回 top-k 不等于最终上下文

很多 RAG 系统只讨论 top-k。
但真正要问的是:
哪些 chunk 最终进入模型上下文?顺序是什么?格式是什么?
通常至少有三层:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
当前 demo 没有接 LLM,但 answer 层已经做了一个简化 context assembly:
1.先找分数最高的 primary document。
2.优先使用同一文档里的相关 chunk。
3.如果证据不足,再引入分数足够高的其他文档。
4.最终生成引用列表。
这一步看起来简单,但很关键。
很多系统“召回文档对了,答案仍然不对”,问题就出在 context assembly:
1.放进模型的 chunk 太多,核心证据被淹没。
2.chunk 顺序不对,模型先看到了次要证据。
3.表格没有转成模型能理解的结构。
4.同一制度不同版本混在一起。
5.引用 id 和正文没有绑定。
所以不要只调 top-k。
要把“初召回 top-k”“rerank top-n”“最终 context token”分开调。
十二、Answer generation:不只是让模型写一段话
Answer generation 是 RAG 的产品层。
当前 demo 为了让链路可复现,没有调用 LLM,而是做 extractive answer baseline。
它主要做三件事:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
比如 alice 问上海住宿标准,回答会带出结论“普通员工在上海出差,住宿标准上限为每晚 650 元”,并附上引用 travel_policy_2026#s02p01。
生产里,这一层可以换成 LLM。
但换成 LLM 后也要控制:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
所以 answer generation 不是“把 context 塞给模型”。
它决定用户最终看到什么。
十三、ACL / 权限过滤:只是其中一层,但必须做对
现在再讲权限。
权限不是整篇文章的全部,但它是企业 RAG 的硬门槛。
当前 demo 的权限很简单:
|
|
|
|---|---|
| allowed_roles |
|
| allowed_users |
|
检索时先把 chunk 分成两组:
1.当前用户可访问的 allowed chunks。
2.当前用户不可访问的 blocked chunks。
真正参与检索和回答的是 allowed chunks。
普通员工 alice 问:“公司的 P6 薪酬范围和年终奖系数是多少?”
默认回答是:“权限不足:你无权访问相关材料,当前问题没有可引用的授权证据。”
debug 模式下可以看到内部命中:blocked_by_acl=compensation_policy_2026_restricted。
但普通用户不应该看到这个字段。
因为在真实企业里,文档名本身也可能是敏感信息。
这里的原则是:
权限过滤发生在 retrieval 前或 retrieval 中,而不是交给模型在 prompt 里自觉保密。
生产权限会更复杂:
1.租户权限。
2.部门权限。
3.项目权限。
4.客户权限。
5.数据密级。
6.临时授权。
7.审批状态。
8.离职和转岗回收。
9.文档系统 ACL 增量同步。
但无论复杂到什么程度,权限都应该是检索边界,不应该只是提示词。
十四、Eval:RAG 不能只靠看一条答案

评测集是一组 golden questions。
每条 case 包含:
|
|
|
|---|---|
| query |
|
| user_id |
|
| expected_doc_ids |
|
| forbidden_doc_ids |
|
| should_refuse |
|
| required_terms |
|
| tags |
|
比如普通员工问薪酬,should_refuse=true。
HR 问薪酬,should_refuse=false,并要求答案包含 48、72、1.3、1.8。
项目当前评测指标包括:
|
|
|
|---|---|
| recall_at_k |
|
| mrr |
|
| ndcg_at_k |
|
| citation_coverage |
|
| forbidden_retrieval_rate |
|
| permission_leak_rate |
|
| refusal_accuracy |
|
| over_refusal_rate |
|
| required_terms_rate |
|
| latency_p95_ms |
|
这比“答案看起来还行”要可靠得多。
生产里可以继续接:
1.LangSmith:trace、dataset、regression eval。
2.Ragas:context precision、context recall、faithfulness。
3.DeepEval:answer relevancy、faithfulness、contextual precision。
4.Azure AI Foundry evaluators:groundedness、relevance、retrieval。
5.自定义敏感信息扫描。
6.LLM-as-judge。
7.线上失败样本回放。
OpenAI / Morgan Stanley 案例里最值得学的不是“用了大模型”,而是 eval-driven rollout。
RAG 没有 golden set,就没有上线资格。
十五、为什么现在还不直接上 LangGraph / DeepAgents

这篇属于 LangChain 系列,但 baseline 没有一上来就接 LangChain、LangGraph、DeepAgents。
原因是:先把 RAG 链路本身拆清楚。
LangChain 官方文档把 RAG 分成 two-step RAG 和 agentic RAG。
|
|
|
|---|---|
|
|
|
|
|
|
Anthropic 在 Building Effective Agents 里也强调:先用最简单可行方案,只有确实需要时再引入 agentic complexity。
所以这个项目的路线应该是:
|
|
|
|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
什么时候需要 DeepAgents?
不是问“上海住宿标准是多少”,而是类似“帮我判断这个客户合同能不能走标准审批”:系统需要先查合同制度,再查客户行业,再查历史类似合同,再查当前审批人,最后给出风险点和审批建议。
这才是 agentic RAG 的场景。
所以这里的判断是:
先把普通 RAG 做硬,再把 agentic layer 加上去。
十六、真实案例给这个项目提供了什么依据
这篇不是为了堆大公司名字。
真实案例的作用,是校准工程设计。
OpenAI / Morgan Stanley 案例说明:
企业知识助手要靠 eval 和 regression suite 上线。
所以项目里保留了一套 golden questions 和回归评测脚本。
Microsoft Azure AI Search 的 document-level access control 说明:
RAG 和 agentic systems 需要文档级权限,查询时要排除无权文档。
所以项目里把权限判断放在检索边界,而不是只放在提示词里。
Anthropic Contextual Retrieval 说明:
chunk 丢上下文会导致检索失败,contextual embeddings + contextual BM25 + reranking 能显著降低 failure。
所以项目里有 contextual_text、BM25 和 hybrid retrieval。
Google Vertex AI RAG Engine 和 Agentspace 说明:
企业 RAG 正在变成 corpus、metadata、connector、permission、reranking、agent workflow 的组合能力。
所以这个项目没有把 RAG 写成一条 prompt chain,而是拆成模块。
十七、这一篇的核心结论
最后只记住这一句
企业 RAG 的实战难点,不是“接上向量库”,而是把每个 chunk 变成可检索、可授权、可引用、可评测的证据单元。
01先拆链路
文档解析、metadata、chunk、embedding、索引、检索、生成、权限和评测要分层。
02再做替换
LangChain、LangGraph、LangSmith、向量库和 reranker 都应该替换在清楚的工程边界上。
03最后进生产
上线前要用 golden questions 证明召回、引用、拒答、权限和关键事实没有退化。
下一篇预告
下篇继续这个同一个项目:把它接进 LangFlow、LangChain、LangGraph、LangSmith,做成更接近生产形态的企业知识助手。
1.把 baseline pipeline 换成 LangChain Runnable
2.用 LangFlow 画出可视化流程
3.用 LangGraph 拆 query rewrite、retrieval、answer、eval 节点
4.接入真实 embedding、向量库和 reranker
5.用 LangSmith 记录 trace、dataset 和回归评测
6.把权限过滤和引用校验做成上线门禁
做到这里,才算真正从 RAG 文章进入 RAG 工程。
我们会持续迭代企业 AI 落地应用,沉淀一线项目里的实战经验、踩坑记录和方法论。如果你也在关注企业 AI、RAG、Agent 和 LangChain 生态,欢迎持续关注,后面会继续拆具体案例。关注不迷路~
参考资料
添加微信,加入企业 AI 落地交流群
一起交流企业 AI、RAG、Agent 和 LangChain 生态的一线落地经验。