 夜雨聆风
夜雨聆风





用OpenClaw智能体网关接管K8s日常运维:从只读巡检到低风险变更
凌晨2点,AI在钉钉上问我:“检测到recommend-engine内存持续飙升,历史相似案例修复成功率97%,是否允许我执行patch?”我迷迷糊糊回了个“同意”,然后翻个身继续睡了。第二天看报告,AI在3分钟内完成了诊断、调整、验证全流程——而我,全程只说了一个词。
这不是科幻。2026年的今天,我们用OpenClaw智能体网关,让AI从一个“只读巡检员”变成了能执行低风险变更的运维助手。下文完整拆解这套架构。
一、架构全景:OpenClaw作为K8s运维中枢
OpenClaw的核心价值是充当AI与K8s API之间的双向桥梁——AI通过它执行命令,它负责安全护栏、审计日志、权限分级。
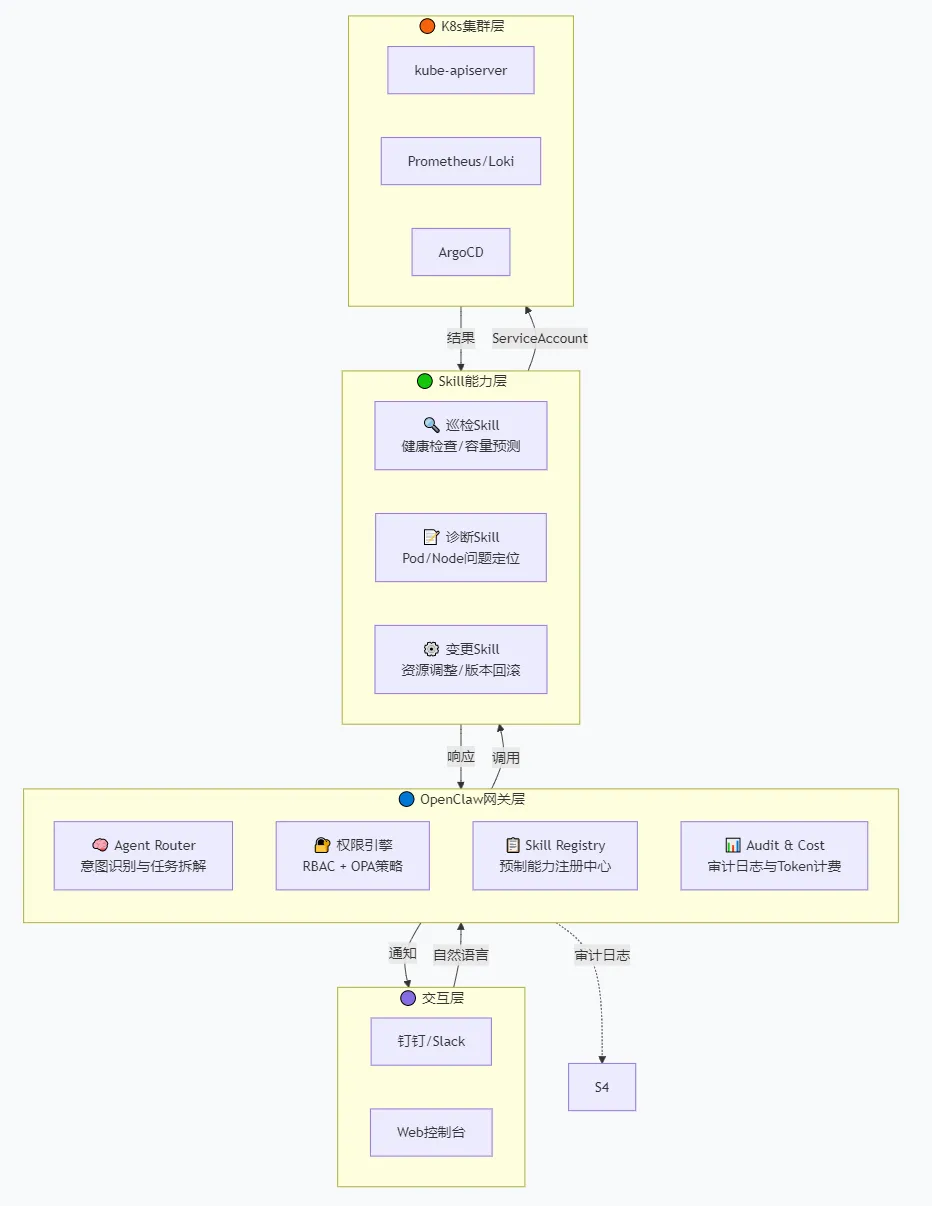
-
交互层:SRE通过钉钉、Slack或Web界面与AI对话,自然语言进去,结果出来。 -
网关层:大脑(理解意图、拆解任务、调度Skill)+ 刹车(OPA策略、权限检查)。所有AI动作必经此层。 -
Skill层:封装的运维能力,每个Skill有明确的输入输出规范和权限声明。 -
K8s层:目标集群,通过专用ServiceAccount隔离权限。
二、三阶段渐进:从“只读”到“变更”
我们走了一条渐进路:先让AI证明“看得懂”,再开放“改得动”。每个阶段持续3-4周,经过充分验证后才进入下一阶段。
2.1 只读巡检(第1-4周)——建立信任
目标:让AI学会“看懂”集群状态,不产生任何副作用。
权限范围:
-
get、list、watch 所有命名空间的Pod、Deployment、Service、Event -
查询Prometheus指标、Loki日志的只读API -
没有任何写操作权限
Skill设计示例:
name: health_check
description: "巡检指定命名空间的健康状态"
permission: READ_ONLY
parameters:
- namespace: string
- time_range: string (default: 1h)
prompt: |
你是一个SRE助手。请查询namespace={namespace}在过去{time_range}内的以下信息:
1. 非Running状态的Pod及其原因
2. 重启次数>3的Pod
3. CPU/内存使用率超过80%的Pod
4. 最近的Warning级别Event
用表格形式输出结果,并标注需要关注的高风险项。
效果数据:
-
第1周准确率:78%(漏报+误报较多) -
第2周准确率:85%(通过人工纠正优化) -
第4周准确率:92%(达到上线标准)
关键经验:教会AI看病的,是SRE自己——每次纠正都是训练数据。
2.2 诊断助理(第5-8周)——人机协同
目标:AI可以深入排查问题,给出诊断结论和修复建议,但写操作仍需人工确认。
权限范围:保持只读,但增加了复杂数据访问(事件历史、资源趋势图、跨Pod关联分析)。
诊断闭环流程:

输出示例:
【诊断报告】Pod: recommend-engine-7d8f-xyz
【现象】
- 状态: CrashLoopBackOff (已重启8次)
- 最后退出码: 137 (OOMKilled)
【数据摘要】
- 当前memory limit: 512Mi
- 过去7天内存峰值: 687Mi (超出limit 34%)
- 相关Event: "Container was killed due to memory limit"
【根因判断】
✅ 内存限制不足 (置信度: 92%)
❌ 内存泄漏 (置信度: 18% - 无持续增长模式)
【建议操作】
kubectl patch deployment recommend-engine -p '{"spec":{"template":{"spec":{"containers":[{"name":"app","resources":{"limits":{"memory":"1024Mi"}}}]}}}}'
⚠️ 风险等级: 低 (滚动更新,业务无中断)
是否执行?
效果数据:
-
SRE从“排查者”变为“审核者” -
平均排查时间:25分钟 → 5分钟(下降80%) -
诊断准确率:94%(人工复核确认)
2.3 低风险变更(第9周至今)——审慎开放
目标:对于标准化、低风险的操作,允许AI直接执行。
权限范围:
-
允许:patch Deployment的resources、restart Deployment、scale replicas(限制范围内) -
禁止:DELETE操作、修改NetworkPolicy、修改RBAC、删除PVC -
要求:所有操作必须有审计日志和变更原因
OPA护栏策略:
# Open Policy Agent 策略示例
package k8s.agent
# 黑名单操作:永远拒绝
deny[msg] {
input.operation == "DELETE"
msg = "AI不允许执行DELETE操作"
}
deny[msg] {
input.resource == "networkpolicy"
msg = "NetworkPolicy变更需人工操作"
}
deny[msg] {
input.resource == "persistentvolumeclaim"
msg = "PVC删除操作需人工操作"
}
# 配额变更需要验证范围
deny[msg] {
input.resource == "deployment"
input.field == "resources.limits.memory"
new_value = input.new_value
old_value = input.old_value
new_value > old_value * 2
msg = sprintf("内存调整幅度过大,需人工审批。当前请求将limit从%v调整至%v", [old_value, new_value])
}
# 副本数变更需要验证上限
deny[msg] {
input.resource == "deployment"
input.field == "replicas"
new_value = input.new_value
new_value > 5
msg = sprintf("副本数超过上限(5),当前请求: %v", [new_value])
}
# 速率限制:同一资源每小时最多操作1次
deny[msg] {
count(same_resource_ops_in_last_hour) >= 1
msg = "同一资源1小时内只能操作1次,请稍后再试"
}
# 允许通过的条件
allow {
input.operation == "PATCH"
input.resource in {"deployment", "statefulset"}
input.field in {"resources.limits.memory", "resources.requests.cpu", "replicas"}
not deny[_]
}
实际运行数据(3个月累计):
|
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
零安全事故——不是运气,是护栏足够密。
三、实战案例:60秒完成诊断+修复
3.1 场景
某核心服务的Pod因健康检查失败反复重启,影响约3%的请求。
3.2 用户触发
SRE在钉钉群里发了一条:
/ai diagnose recommend-engine -n production
3.3 OpenClaw意图识别
网关识别关键词diagnose,匹配到diagnosis Skill,提取参数pod=recommend-engine,namespace=production。
3.4 AI自主诊断链执行
|
|
|
|
|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
3.5 输出诊断报告
【诊断结果】
根因: livenessProbe.initialDelaySeconds=30s,应用实际启动需45s
建议: 将initialDelaySeconds调整为60s
修复命令: kubectl patch deployment recommend-engine --type='strategic' -p='{"spec":{"template":{"spec":{"containers":[{"name":"app","livenessProbe":{"initialDelaySeconds":60}}]}}}}'
风险等级: 低(滚动更新,业务无中断)
是否执行?
Step 5:人工确认后执行
SRE回复执行 → OpenClaw调用K8s API执行patch → 滚动更新触发 → 新Pod正常启动
耗时统计:
-
AI诊断:35秒 -
人工确认:10秒 -
执行生效:15秒 -
总计:60秒
而以前人工排查这个问题,大概需要15分钟——先怀疑代码、再看配置、最后才发现是探针的问题。效率提升15倍。
四、总结:AI不是来抢饭碗的,是来帮你“早下班”的
三个月前,团队里最担心的声音是:“AI学会了变更是好事,那SRE是不是要失业了?”
我们干的事情变了:不再盯着监控屏幕等告警,而是去设计更好的Skill、优化RAG知识库、调整护栏策略、研究那些真正棘手的问题。
AI Agent不是来抢饭碗的。它把我们从“低价值的重复劳动”中解放出来,让我们有机会去做那些真正需要人脑的事情——架构设计、容量规划、故障复盘、知识沉淀。
如果你的团队还在犹豫要不要引入AI运维,我的建议是:
从只读开始,给AI一个月时间证明自己。
如果它连“看懂”都做不到,你失去的只是几行配置。如果它做到了——就像我们这只“主动申请写权限”的AI一样——你将拥有一个永不睡觉、永不抱怨、永远按你给的规则办事的“实习生”。
欢迎加w一起交流:19067272547