 夜雨聆风
夜雨聆风





AI算力全解析:从芯片到云端,从硬件到软件,一文读懂大模型的“心脏”与“灵魂”
为什么现在互联网上都在说“算力就是智能时代的水电煤?”,当你在对话框问一个问题,AI几秒内就能给出答案;用AI 生成图片、刷到精准短视频推荐,这些背后其实都藏着同一个“隐形功臣”-算力。它是数字世界的劳动力,是所有AI 应用的底层动力,而支撑这份动力的,正是硬件设备(身体)和软件设备(灵魂)的共同作用:硬件承接所有计算任务,软件指挥硬件高效干活。没有硬件,软件是空中楼阁;没有软件,硬件只是一堆废铁。今天我们从零看懂这对“算力 CP”,解锁 AI 快速响应的核心密码。

一、硬件设备:AI算力的“身体”(从芯片到集群的完整体系)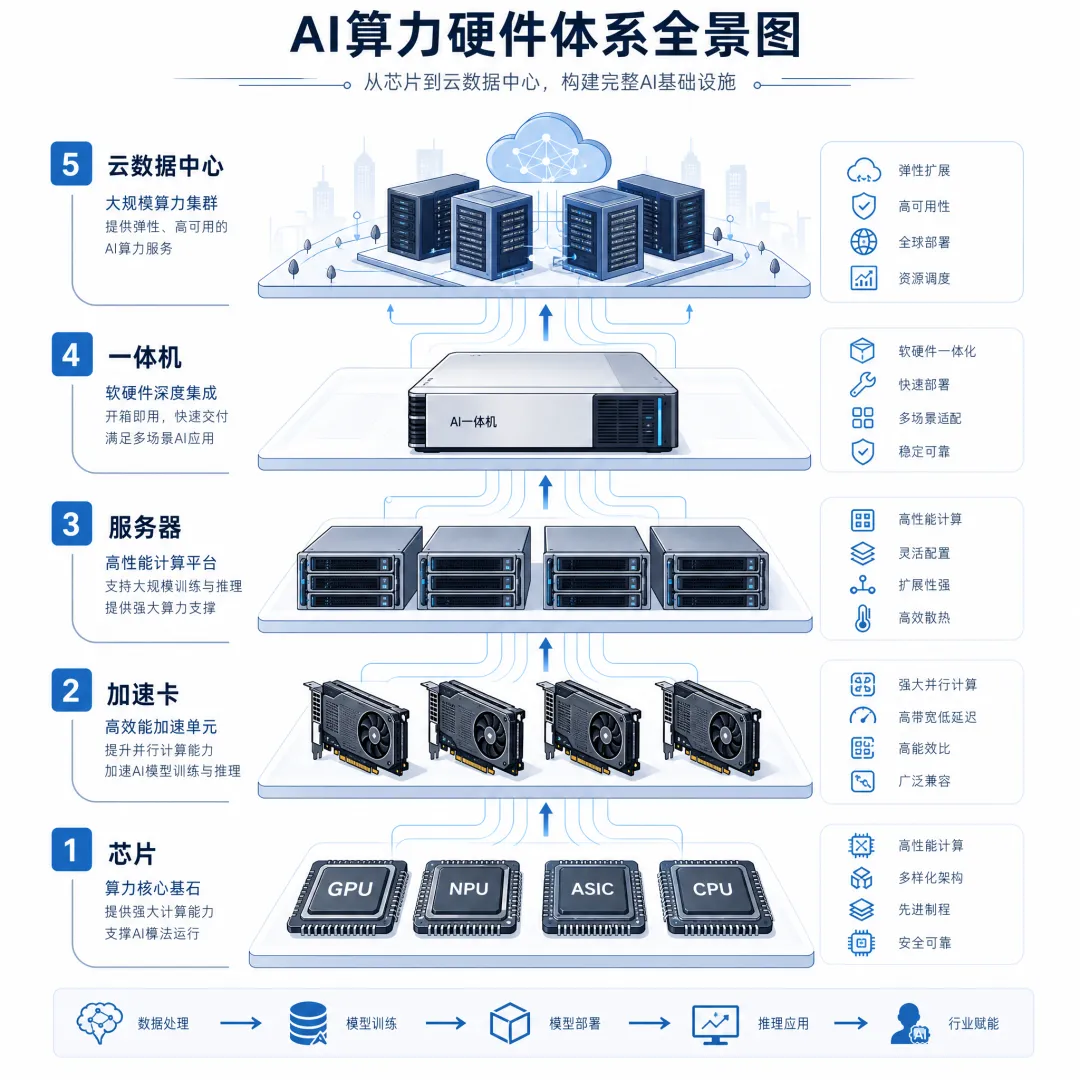
硬件是AI 赖以生存的物质基础,就像人的身体,从微观的“神经元”(芯片)到宏观的“器官系统”(数据中心),每一环都缺一不可,共同决定算力的“天花板” 和“稳定性”。
1.计算核心:大脑的“神经元”(算力的心脏)
负责执行海量数学运算,是AI 思考的核心,不同芯片各司其职、分工协作:
CPU:全能指挥官
我们电脑、手机里都有的“中央处理器”,擅长复杂逻辑判断和任务调度(操作系统运行、业务协调),但面对AI所需的海量重复计算时效率不高。它就像公司CEO,不做具体杂活,却要统筹 GPU、NPU 的工作,处理数据预处理、内存管理等关键环节。比如Intel最新处理器集成NPU后,手机端AI任务延迟直接降低30%以上。
GPU:并行计算主力军
原是渲染游戏画面的“图形处理器”,因拥有数千个小型计算核心,能同时处理大量相似任务(如矩阵运算),成了AI训练和推理的核心。像 GPT-4 训练需数万张 GPU,2026 年英伟达 B200GPU(Rubin 架构)每秒能完成5千万亿次运算,是前代的3倍。
ASIC:专用特种兵
功能固定的“定制芯片”,能效比极高,专为特定AI任务设计:
TPU(张量处理器):谷歌自研ASIC,专为TensorFlow框架优化,是其云服务的核心算力引擎;
NPU(神经网络处理器):手机、智能摄像头等边缘设备的 “专属引擎”,模拟人类神经元工作,低功耗下快速完成推理 ;苹果 A18 Pro的NPU算力达35TOPS,高通最新芯片飙升至75TOPS,7年性能暴涨 58倍;华为昇腾310芯片功耗仅8W,却能支撑医疗影像识别、自动驾驶感知等。
FPGA:灵活变形金刚
电路可制造后重新配置,适合算法未定型、需快速迭代的场景(如科研阶段的新型AI 模型测试),兼顾灵活性和算力效率。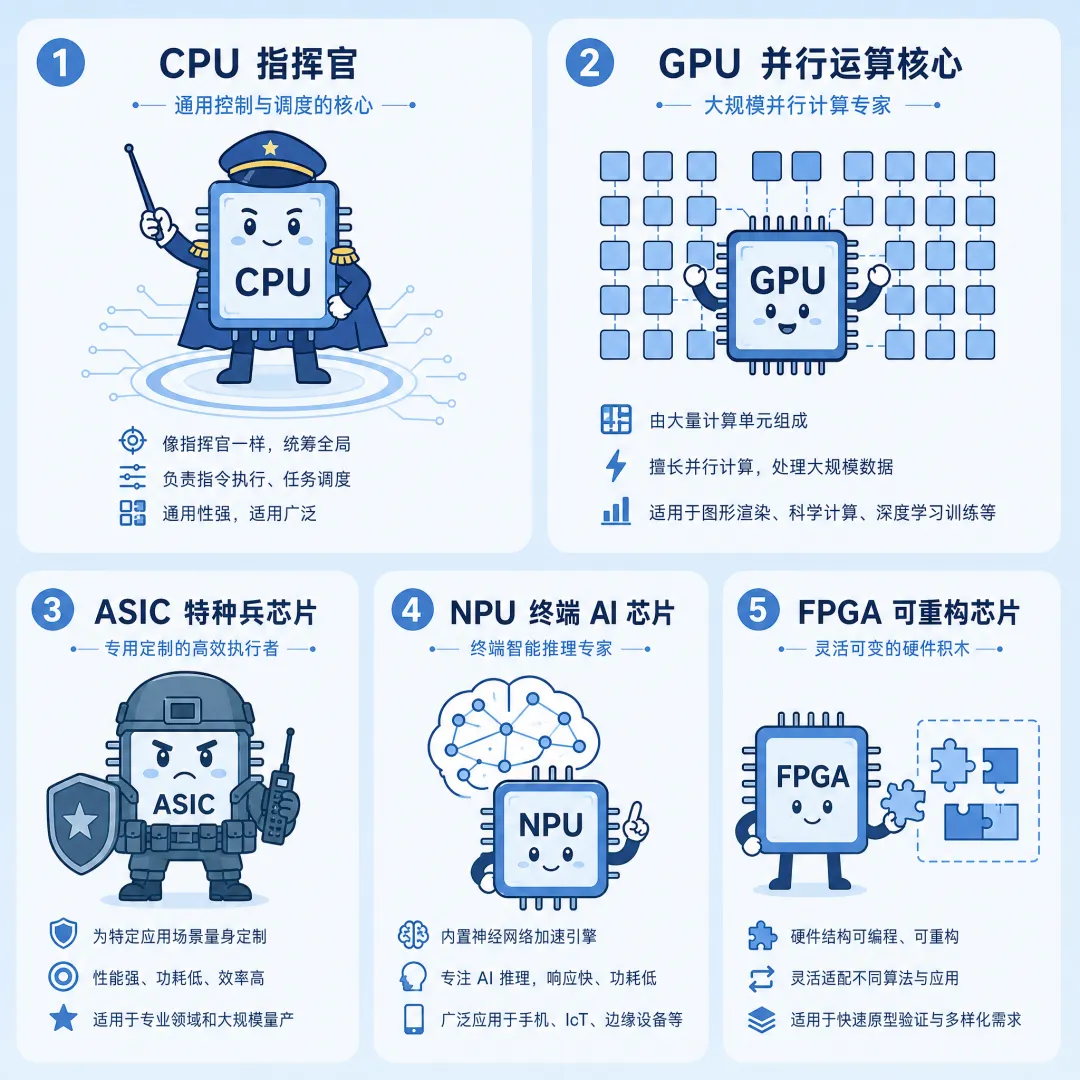
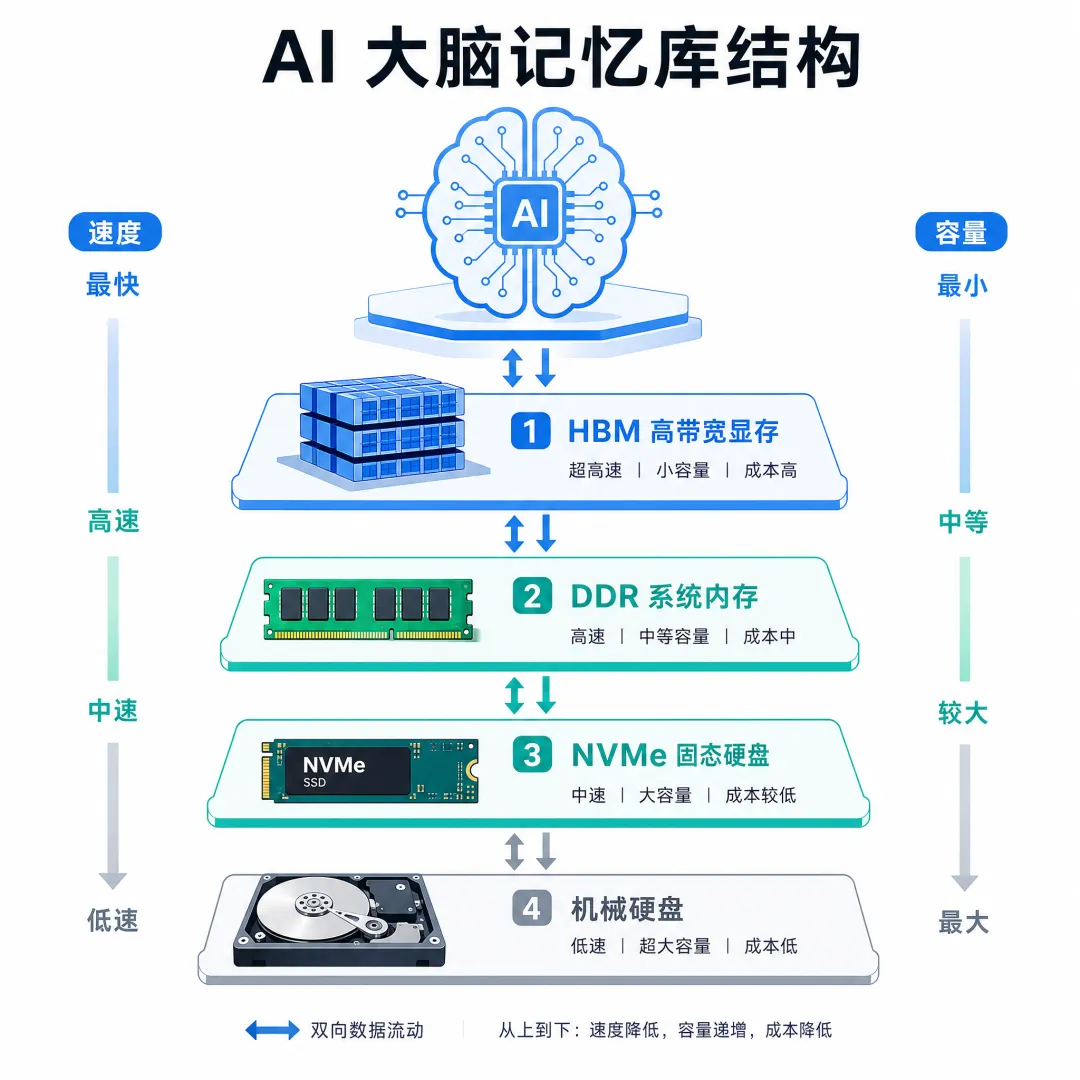
2. 记忆与存储:大脑的 “记忆库”
AI需要“记住”海量模型参数和数据,对存储的速度、容量要求极高,就像人的工作记忆、长期记忆分工:
HBM(高带宽内存):GPU 的高速缓存
紧邻GPU的“贴身工作台”,速度极快(带宽达 TB/s 级别),专门存放 GPU 正在处理的核心数据,确保 GPU 不会因等数据“饿死”。比如英伟达H100GPU搭载HBM3内存,带宽达 3.35 TB/s,让大模型训练速度提升 2 倍。
DDR 内存:系统主内存
相当于“书桌”,容量比 HBM 大但速度较慢,用于存放暂时不用的数据和程序。AI大模型训练常用 DDR5 内存,联想问天服务器的 3TB TruDDR5内存,能同时容纳10个7B参数模型的临时数据,比普通内存快3倍。
显存:GPU的专属记忆
GPU的专用内存,存放模型参数和中间结果,容量、带宽直接决定GPU性能:RTX 4090 有24GB GDDR6X 显存,带宽 1008 GB/s,能流畅跑 32B 参数模型;显存仅6GB的显卡,连7B模型都装不下。
简单记忆:显存不够=“桌面太小放不下文件”(直接卡壳);带宽不够 =“桌面到 GPU 的通道太窄”(数据传得慢)。
硬盘:长期资料库
负责永久存储训练数据、模型文件,就像家里的衣柜。AI 场景常用 NVMe 协议的 SSD 固态硬盘(比机械硬盘快 10 倍),比如三星 990Pro SSD,能让大模型加载速度提升 50%,避免训练时“等数据”。
3. 整机与集群:从 “细胞” 到 “器官”(硬件的集成形态)
单个芯片无法“裸奔”,需集成到复杂系统中才能发挥作用:
AI 加速卡:算力基本单元
把GPU/ASIC 芯片、HBM 内存、散热模块封装在一起的 “显卡式组件”,可直接插在服务器主板上,是 AI 算力的最小功能单元 — 比如英伟达 A100 加速卡,单卡算力达19.5TFLOPS,是AI服务器的核心配件。
AI 服务器:算力主机
将多块(通常8 块)AI 加速卡通过高速总线(如 NVLink)连接,搭配强性能CPU和大容量内存,构成完整计算机。企业可通过它搭建本地算力平台,可支持中大规模AI训练。
智算一体机:开箱即用的解决方案
把服务器、存储、网络设备和预装软件集成在一个机柜中,相当于“预制好的算力小屋”。企业买回去插上电就能跑 AI 任务,省去硬件适配麻烦,适合中小企业私有化部署 —— 比如联想问天 WR5215 G5 智算一体机,搭载第五代 AMD 芯片,支持 8 张 GPU,自带 3TB 内存和 45 个硬盘位。
云服务器算力设备:云端共享算力池
云厂商(阿里云、AWS 等)将成千上万台 AI 服务器通过超高速网络(如 InfiniBand)连接,做成 “算力出租屋”。我们用 ChatGPT、AI 绘图时,其实是在租用云端算力 —— 阿里云 ECS 云服务器能弹性调整 GPU 数量,个人用户花几十块就能用 1 天高端算力,不用买昂贵硬件,实现 “按需付费”。

4. 供电与冷却:身体的 “循环系统”(算力的保障)
强大算力意味着巨大能耗和热量,就像人运动需要呼吸、降温:
功耗:硬件的耗电量
AI芯片是“电老虎”,一次大型模型训练可能消耗一座小型城镇数月的电量。因此,算力功耗效能比(每瓦特电力产生的算力,单位TOPS/W)成为核心指标,数值越高越 “划算”。比如高通最新 NPU 效能比 1 TOPS/W,比上一代高 50%;华为昇腾 310 芯片功耗仅 8W,却能支撑复杂推理任务。
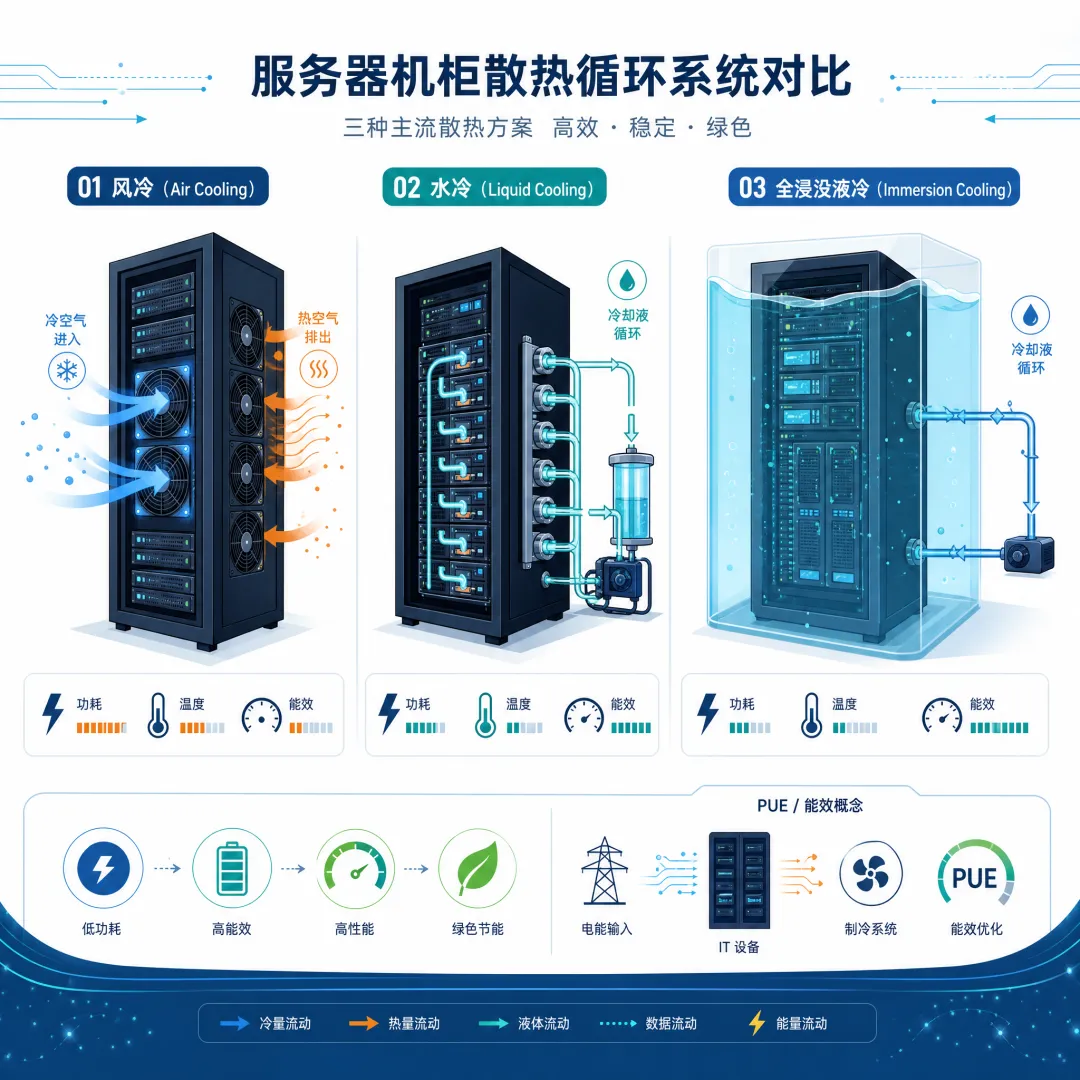
冷却设备:算力的空调
芯片高速运算会发热,不降温会“中暑”:
风冷:普通电脑的风扇,适合小型设备(台式机跑小模型);
液冷:用冷却液带走热量,适合大型集群—— 郑州超算枢纽的 6 万卡集群用液冷技术,温度控制在 30℃以下,PUE 低至 1.02,比风冷节能 20%;谷歌用 AI 智能调控冷却系统,让数据中心能耗降低 40%。
联想问天服务器的“海神液冷技术”,能让 GPU 满负荷运行时温度降低 15℃,同时节省 25% 电费。
二、软件设备:AI 算力的 “灵魂”(让硬件活起来)
硬件提供潜力,软件负责释放潜力–就像给身体注入灵魂。

1. 底层驱动与固件:硬件的 “本能”
固件(Firmware):硬件的出厂设置
固化在硬件内部的低级程序,负责硬件初始化和基本控制—比如服务器的 BIOS 固件,启动时会检测内存、硬盘是否正常;华为昇腾芯片的固件,能在低负载时让芯片进入 “节能模式”。
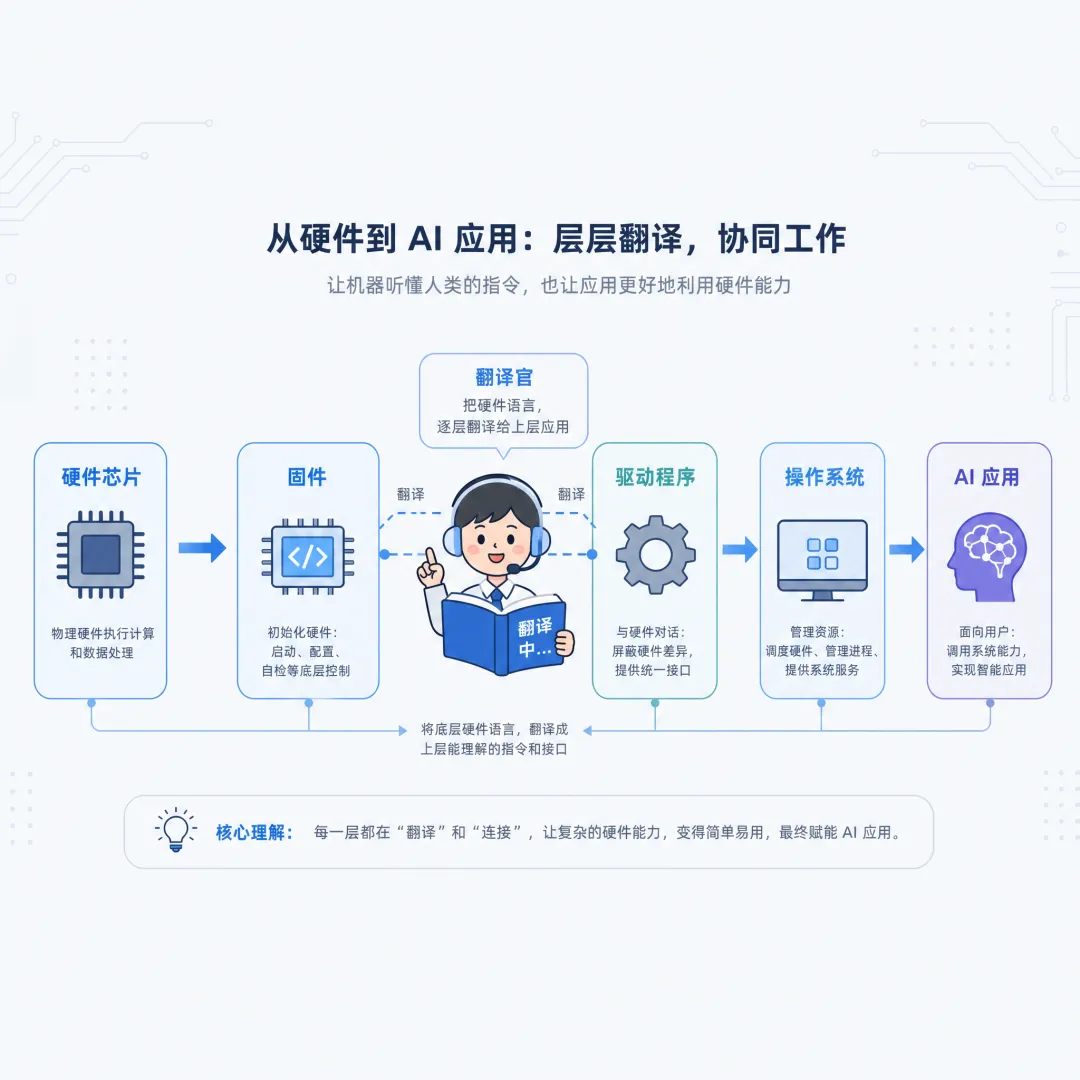
驱动程序(Driver):软硬件的翻译官
连接操作系统和硬件的“桥梁”,将上层指令翻译成硬件能理解的语言。没有驱动,GPU 就是废铁:英伟达的 CUDA 平台不仅是驱动,更是完整的并行计算平台和编程模型,让PyTorch、TensorFlow 框架能完美调用 GPU 算力,更新驱动后 AI 推理速度常提升 10%-20%;如果驱动不兼容,会出现 “软件认不出 GPU” 的情况。
2. 计算架构与平台:系统的 “骨架”
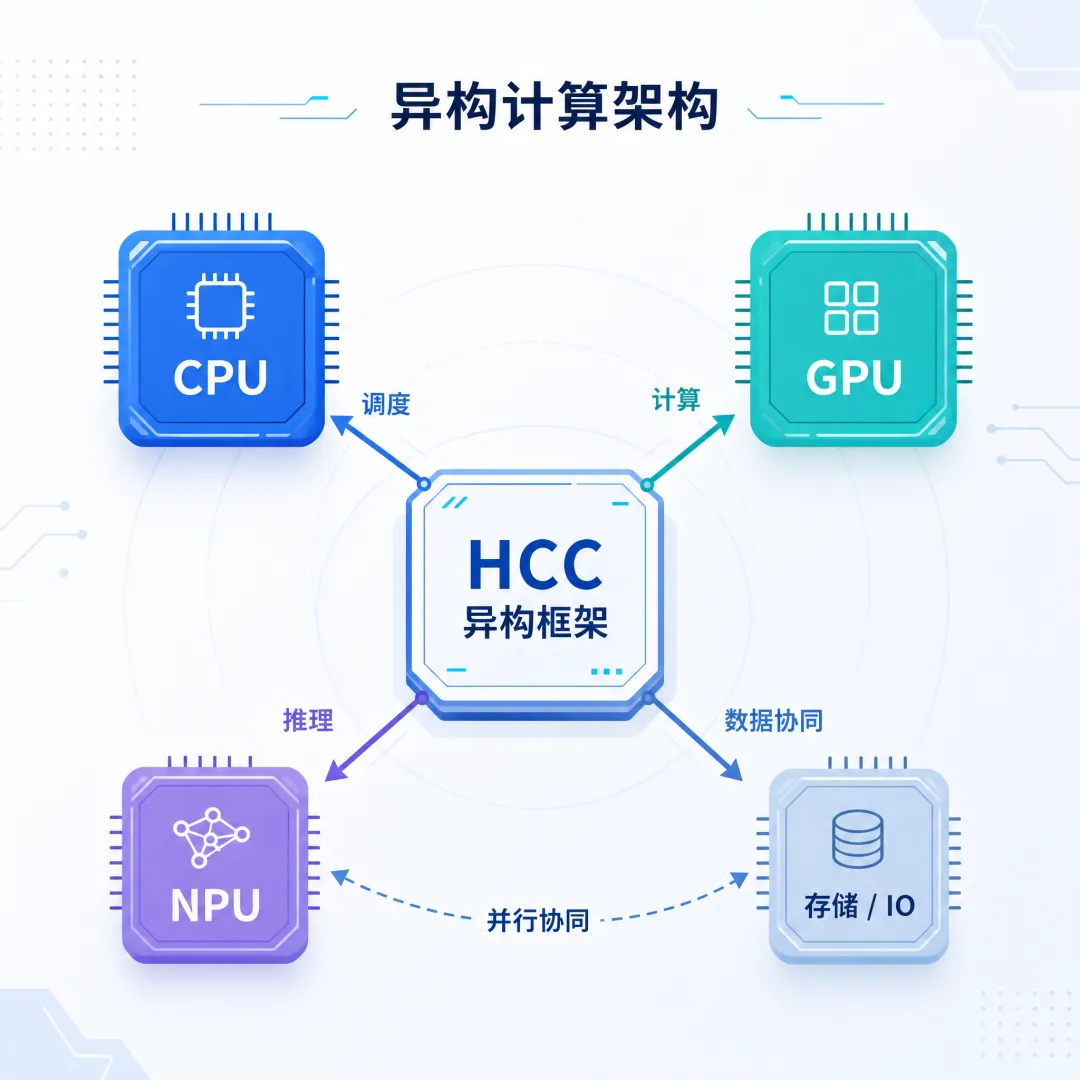
异构计算:多芯片协同干活
现代AI系统的标准架构 —— 让CPU、GPU、NPU等不同芯片各司其职:CPU 负责逻辑控制,GPU 负责大规模计算,NPU 负责低功耗推理,实现整体性能最优化。比如手机拍照时,CPU 调度任务,NPU 快速完成图像优化,无需调用 GPU 就能低功耗运行。
HCC(异构计算架构):广义的调度框架
指代管理和调度异构硬件的软件体系,华为的CANN(异构计算架构)就是为昇腾芯片打造的软件栈,功能类似CUDA,能高效调度昇腾芯片的算力,支撑大规模AI任务。
3. 生态适配:应用的 “土壤”
硬件平台的成功,关键看软件生态是否丰富—— 就像植物需要肥沃土壤:
框架支持:是否兼容PyTorch、TensorFlow 等主流 AI 框架?比如英伟达因CUDA生态,几乎完美支持所有主流框架,成为开发者首选;
模型库与工具:是否有丰富的预训练模型、调试优化工具?国产华为昇腾通过提供torch_npu迁移工具,让开发者只需修改极少代码,就能从NVIDIA平台平滑过渡,逐步构建自己的生态;
国产突围:寒武纪、燧原等国产芯片,正通过与百度飞桨、华为MindSpore框架深度适配,解决“硬件强、生态弱”的问题,已在互联网、政务等场景大规模应用。

三、关键概念:必懂的“算力名词”(从 0 解释)
1. 核心参数:看懂算力 “性能说明书”
算力单位:FLOPS/TOPS
衡量算力强弱的“速度单位”:1 FLOPS = 每秒 1 次浮点运算,1 TOPS = 每秒 1 万亿次运算。手机 NPU 算力 35 TOPS = 每秒 35 万亿次 AI 运算;超算集群 10E FLOPS = 每秒 1000 万亿亿次运算(1E=1000P,1P=1000T)。
通算vs 智算
通算:传统计算模式,以CPU 为核心,处理办公、编程等通用任务(比如我们的电脑);
智算:专为AI 设计,以 GPU/ASIC 为核心,处理大规模并行计算任务(比如智算中心),效率比通算高 10 倍以上 —武汉人工智能计算中心的300P智算算力,训练大模型比普通通算服务器快100倍。
CGP 技术
计算图剪枝(Compute Graph Pruning),相当于给AI模型 “瘦身”,去掉没用的计算步骤,让算力消耗减少 30%,同时不影响效果,常用于手机端AI应用(AI拍照优化)。
2. 协同与未来:算力的发展趋势
软硬件协同设计:硬件为软件定制,软件为硬件优化。比如DeepSeek-V3 通过定制 AI 芯片、光互连网络,结合模型算子融合技术,训练时间缩短 75%;
绿色算力:能耗问题日益突出,除了液冷技术,“东数西算” 工程将数据中心建在绿电丰富的西部地区,实现 “数据向东走,能源向西流”,让算力更可持续;
算力普惠:通过“算力银行”“普惠算力券”,中小企业花 1/10 的钱就能租用超算级算力;全国一体化算力网跨省市调度资源,让武汉的数据在宜昌用绿电计算,成本降低 30%。
AI算力是一个从芯片、服务器到网络、软件的复杂巨系统,它就像一场由“身体”(硬件)和“灵魂”(软件)共同演绎的交响。从手机AI拍照(NPU+优化驱动)到工厂智能炼钢(智算集群 + 生态适配),从大模型对话(GPU+框架)到生物医药研发(超算+通算协同),算力正在重塑千行百业。你与AI的每一次对话,在屏幕另一端,是无数硬件组件高效运转、软件系统精准调度的结果。而随着技术的发展,这份“隐形动力”会越来越强、越来越普惠,让智能时代的每一个人都能受益。