







文档内容
2013 年计算机学科专业基础综合试题参考答案
一、单项选择题
CACAAD CBCDB CBBBA ABDAC ADBBC CABBD AABA
1. D 2. 3. 4. 5. 6. 7. 8.
9. C 10. 11. 12. 13. 14. 15. 16.
17. D 18. 19. 20. 21. 22. 23. 24.
25. C 26. 27. 28. 29. 30. 31. 32.
33. B 34. 35. 36. 37. 38. 39. 40.
1. 解析:
两个升序链表合并,两两比较表中元素,每比较一次确定一个元素的链接位置(取较小元
素,头插法)。当一个链表比较结束后,将另一个链表的剩余元素插入即可。最坏的情况是两个
链表中的元素依次进行比较,直到两个链表都到表尾,即每个元素都经过比较,时间复杂度为
O(m + n) = O(max(m, n))。
2. 解析:
显然, 3 之后的 4, 5, …, n 都是p3可取的数(一直进栈直到该数入栈后马上出栈)。接下来
分析 1 和 2: Pt只能是3 之前入栈的数(可能是 1 或2), 当 P1= 1 时, p3可取 2; 当 P1=2 时,
p3可取 1, 故p3可能取除 3 之外的所有数,个数为 n-1。
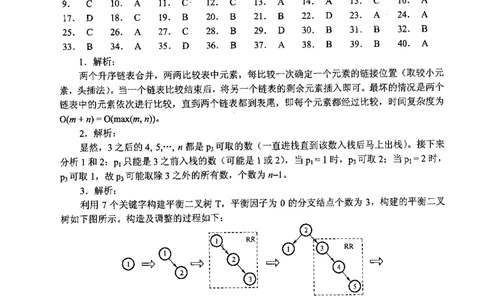
3. 解析:
利用 7 个关键字构建平衡二叉树 T, 平衡因子为 0 的分支结点个数为 3, 构建的平衡二叉
树如下图所示。构造及调整的过程如下:
r-----------,
。飞:[`
L
___________』
,
---------------
,--
了 RR,
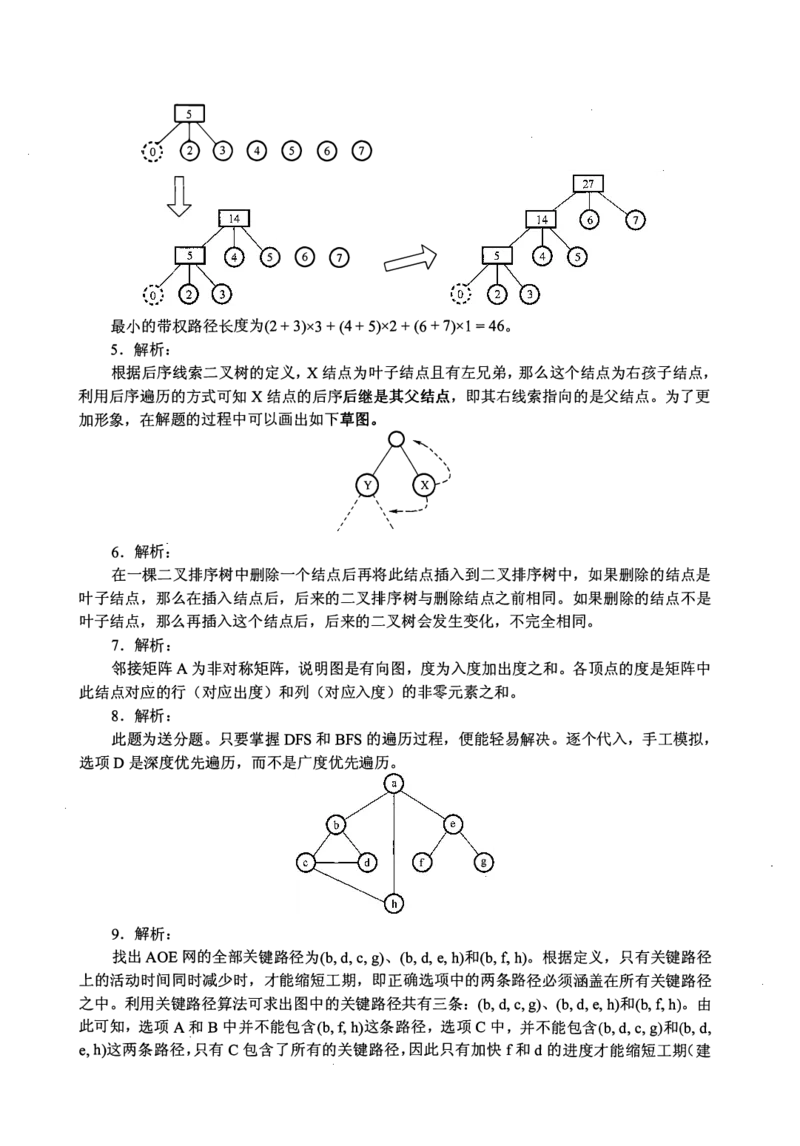
4. 解析:
将哈夫曼树的思想推广到三叉树的情形。为了构成严格的三叉树,需添加权为 0 的虚叶结
点,对于严格的三叉树(n。-1)%(3-1) = u = 1 -to, 需要添加 m-u-1 = 3-1-1 个叶结点,说明 7 个
叶结点刚好可以构成一个严格的三叉树。按照哈夫曼树的原则,权为 0 的叶结点应离树根最远,
构造最小带权生成树的过程如下:`
。
0©0
妙
7
5)©0
乙
最小的带权路径长度为(2+ 3)x3 + (4 + 5)x2 + (6 + 7)x 1 = 46。
5. 解析:
根据后序线索二叉树的定义,X结点为叶子结点且有左兄弟,那么这个结点为右孩子结点,
利用后序遍历的方式可知 X结点的后序后继是其父结点,即其右线索指向的是父结点。 为了更
加形象,在解题的过程中可以画出如下草图。
三
6. 解析:
在一棵二叉排序树中删除一个结点后再将此结点插入到二叉排序树中,如果删除的结点是
叶子结点,那么在插入结点后,后来的二叉排序树与删除结点之前相同。 如果删除的结点不是
叶子结点,那么再插入这个结点后,后来的二叉树会发生变化,不完全相同。
7. 解析:
邻接矩阵A为非对称矩阵,说明图是有向图,度为入度加出度之和。各顶点的度是矩阵中
此结点对应的行(对应出度)和列(对应入度)的非零元素之和。
8. 解析:
此题为送分题。 只要掌握DFS和BFS的遍历过程,便能轻易解决。 逐个代入,手工模拟,
选项D是深度优先遍历,而不是广度优先遍历。
f) { g
9. 解析:
找出AOE网的全部关键路径为(bd, , c ,g)、(b,d , e ,h)和(b, f ,h)。 根据定义, 只有关键路径
上的活动时间同时减少时,才能缩短工期,即正确选项中的两条路径必须涵盖在所有关键路径
之中。 利用关键路径算法可求出图中的关键路径共有三条: (bd, ,c ,g)、(bd, ,e ,h)和(b,f, h)。 由
此可知,选项A和B中并不能包含(b, f ,h)这条路径,选项C中,并不能包含(bd, , c, g)和(bd, ,
e, h)这两条路径,只有C包含了所有的关键路径,因此只有加快f和d的进度才能缩短工期(建淘宝店铺:光速考研工作室
议考生在图中检验)。
10. 解析:
对于5 阶B树,根结点只有达到 5个关键字时才能产生分裂, 成为高度为2的B树, 因此
高度为2 的 5 阶B树所含关键字的个数最少是5。
11. 解析:
基数排序的第l 趟排序是按照个位数字的大小来排序的, 第2趟排序是按照十位数字的大
小进行排序的, 排序的过程如下图所示。
e[O] e[I] e[2] e[ ' 3 ] e[4] e[5 + ] e[6 ' ) e[7] e[8 ' ] e[9]
卤 由 卤
沪
分配:
120
卤
收集:
e[O] e[I] e[2] e[3] e[ ' 4 ] e[5] e[6) e[ ' 7 ] e[8] e[9 + ]
芦 � � � �
盓
盄
分配:
收集:
12. 解析:
基准程序的CPI=2x0.5 + 3x0.2 + 4xO.l + Sx0.2 = 3。计算机的主频为 1.2GHz,即1200MHz,
故该机器的MIPS= 1200/3= 400。
13. 解析:
IEEE 754单精度浮点数格式为C640OOOOH, 二进制格式为11000110 0100 0000 0000 0000
0000 0000, 转换为标准的格式为
s 阶码 尾数
1000 1100 100 0000 0000 0000 0000 0000
数符= I 表示负数;阶码值为1000 1100-0111 1111=00001101 =1 3; 尾数值为1.5 (注意其有
隐含位, 要加1)。 因此,
浮点数的值为-l,5xi3
14. 解析:
x*2, 将x算术左移一位为 1 1101000; y/2, 将y算术右移一位为 1 1011000, 均无溢出或
丢失精度。 补码相加为1 1101000 + 1 1011000 = 1 1000000, 亦无溢出。
15. 解析:
设校验位的位数为k, 数据位的位数为n, 海明码能纠正一位错应满足下述关系: 2k袤n+k+l。
n= 8, 当 k=4 时, 24 (=1 6) > 8 + 4 + I (=1 3) , 符合要求, 故校验位至少是4 位。
16. 解析:
按字节编址, 页面大小为4KB, 页内地址共12位。 地址空间大小为4GB, 虚拟地址共32
位, 前20位为页号。 虚拟地址为03FFFl80H, 故页号为03FFFH, 页内地址为 180H。 查找页
标记 03FFFH 所对应的页表项, 页框号为 0153H, 页框号与页内地址拼接即为物理地址 015
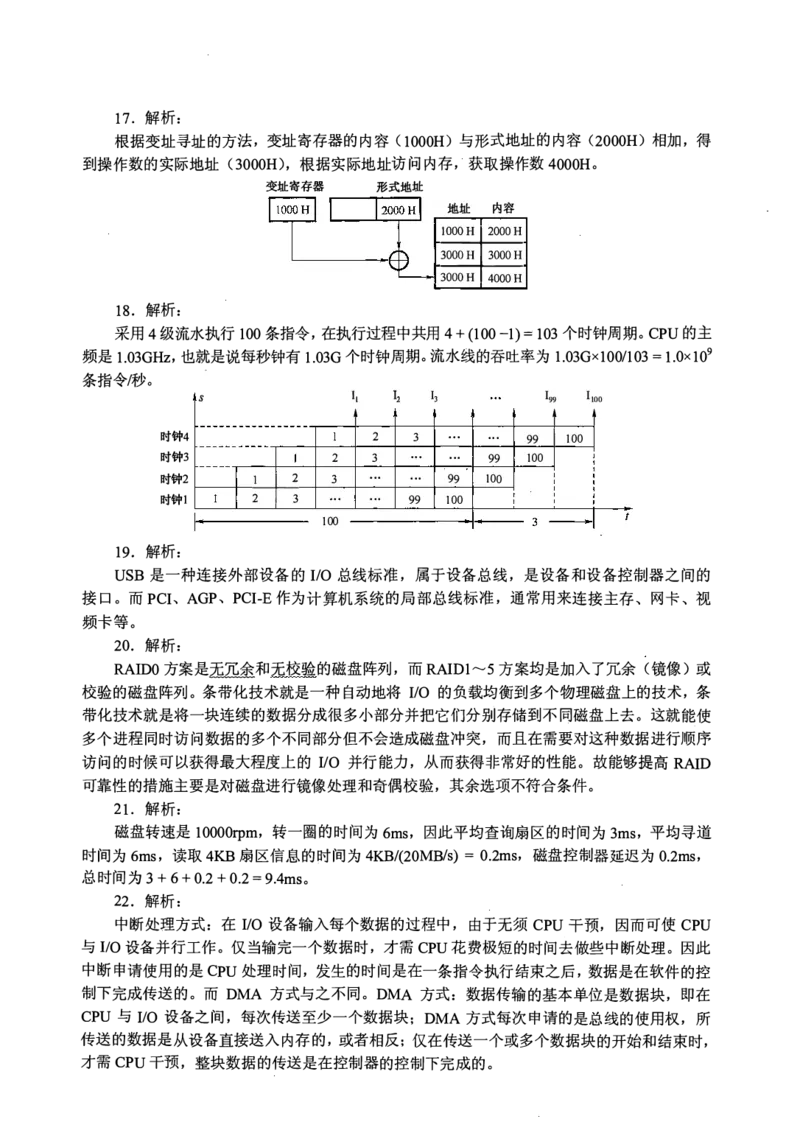
3180H。17. 解析:
根据变址寻址的方法,变址寄存器的内容(1000H)与形式地址的内容(2000H)相加,得
到操作数的实际地址( 3000H), 根据实际地址访问内存, 获取操作数4000H。
变址寄存器 形式地址
地址 内容
酰
18. 解析:
采用 4级流水执行100条指令,在执行过程中共用4+ (100-1) =1 03个时钟周期。CPU的主
频是1.03GHz, 也就是说每秒钟有1.03G个时钟周期。流水线的吞吐率为l.03Gx100/103 = I.Ox1 09
条指令/秒。
s 11 I 2 13 I 99 I l00
t t t
...
时钟4 2 3 ... 99 I 100
时钟3 2 3 ... ... 99 100
...
时钟2 田 3 ... 99 100
... ...
时钟l 99 100
100
19. 解析:
USB是一种连接外部设备的 I/0 总线标准, 属于设备总线,是设备和设备控制器之间 的
接口。而PCI、AGP、PCI-E作为计算机系统的局部总线标准, 通常用来连接主存、网卡、视
频卡等。
20. 解析:
RAIDO方案是无匹金和无校验的磁盘阵列, 而RAID1�5方案均是加入了冗余(镜像)或
校验的磁盘阵列。条带化技术就是一种自动地将1/0的负载均衡到多个物理磁盘上的技术,条
带化技术就是将一块连续的数据分成很多小部分并把它们分别存储到不同磁盘上去。这就能使
多个进程同时访问数据的多个不同部分但不会造成磁盘冲突, 而且在需要对这种数据进行顺序
访问的时候可以获得最大程度上的1/0并行能力, 从而获得非常好的性能。故能够提高RAID
可靠性的措施主要是对磁盘进行镜像处理和奇偶校验, 其余选项不符合条件。
21. 解析:
磁盘转速是 lOOOOrpm, 转一圈的时间为6ms, 因此平均查询扇区的时间为3ms, 平均寻道
时间为6ms, 读取4KB扇区信息的时间为4KB/(20MB/s) = 0.2ms, 磁盘控制器延迟为0.2ms,
总时间为3 + 6 + 0.2 + 0.2 = 9.4ms。
22. 解析:
中断处理方式:在1/0设备输入每个数据的过程中, 由于无须CPU干预, 因而可使CPU
与1/0设备并行工作。仅当输完一个数据时, 才需CPU花费极短的时间去做些中断处理。因此
中断申请使用的是 CPU处理时间,发生的时间是在一条指令执行结束之后,数据是在软件的控
制下完成传送的。而DMA方式与之不同。DMA方式:数据传输的基本单位是数据块, 即在
CPU与1/0设备之间, 每次传送至少一个数据块; DMA方式每次申请的是总线的使用权, 所
传送的数据是从设备直接送入内存的,或者相反;仅在传送一个或多个数据块的开始和结束时,
才需CPU干预, 整块数据的传送是在控制器的控制下完成的。23. 解析:
此文件所在目录下可能还存在其他文件,因此删除文件时不能(也不需要) 删除文件所在
的目录,而与此文件关联的目录项和文件控制块需要随着文件一同删除,同时释放文件关联的
内存缓冲区。
24. 解析:
为了实现快速随机播放,要保证最短的查询时间,即不能选取链表和索引结构,因此
连续结构最优。
25. 解析:
计算磁盘号、磁头号和扇区号的工作是由设备驱动程序完成的。题中的功能因设备硬件的
不同而不同,因此应由厂家提供的设备驱动程序实现。
26. 解析:
四个选项中,只有A选项是与单个文件长度无关的。索引结点的总数即文件的总数,与
单个文件的长度无关;间接地址级数越多、地址项数越多、文件块越大,单个文件的长度就
会越大。
27. 解析:
数据块l从外设到用户工作区的总时间为105, 在这段时间中,数据块2没有进行操作。
在数据块l 进行分析处理时,数据块2从外设到用户工作区的总时间为105, 这段时间是并行
的。再加上处理数据块2的时间90, 总时间为300, 答案为C。
28. 解析:
需要在系统内核态执行的操作是整数除零操作(需要中断处理)和read系统调用函数,sin()
函数调用是在用户态下进行的。
29. 解析:
此题为基本常识题,送分题。系统开机后,操作系统的程序会被自动加载到内存中的系统
区,这段区域是RAM。
30. 解析:
用户进程访问内存时缺页会发生缺页中断。发生缺页中断,系统会执行的操作可能是置换
页面或分配内存。系统内没有越界的错误,不会进行越界出错处理。
31. 解析:
为了合理地设置进程优先级,应该将进程的CPU时间和I/0时间做综合考虑,对千CPU
占用时间较少而I/0占用时间较多的进程,优先调度能让I0/ 更早地得到使用,提高了系统的
资源利用率,显然应该具有更高的优先级。
32. 解析:
银行家算法是避免死锁的方法,破坏死锁产生的必要条件是预防死锁的方法。利用银行家
算法,系统处于安全状态时就可以避免死锁(即此时必然无死锁);当系统进入不安全状态后便
可能进入死锁状态(但也不是必然)。
33. 解析:
在OSI参考模型中,应用层的相邻层是表示层。表示层是OSI七层协议的第六层。表示层
的功能是表示出用户看得懂的数据格式,实现与数据表示有关的功能。主要完成数据字符集的
转换、数据格式化和文本压缩、数据加密和解密等工作。
34. 解析:
lOBaseT即lOMbps的以太网,采用曼彻斯特编码,将一个码元分成两个相等的间隔,前一个间隔为低电平后一个间隔为高电平表示码元1; 码元0正好相反,也可以采用相反的规定。
故对应比特串可以是00110110或11001001。
35. 解析:
不进行分组时,发送一个报文的时延是8Mb/10Mbps= 800ms, 采用报文交换时,主机甲发
送报文需要一次时延,而报文到达路由器进行存储转发又需要一次时延,总时延为800msx2 =
1600ms。 进行分组后,发送一个报文的时延是10kb/10Mbps= lms, 一共有8Mb/10kb= 800个
分组,主机甲发送800个分组需要lmsx800 = 800ms的时延,而路由器接 收到第一个分组后直
接开始转发,即除了第一个分组,其余分组经过路由器转发不会产生额外的时延,总时延就为
800ms + lms = 801ms。
36. 解析:
选项A、C和D都是信道划分协议,信道划分协议是静态划分信道的方法,肯定不会发生
冲突。CSMA全称是载波侦听多路访问协议,其原理是站点在发送数据前先侦听信道,发现信
道空闲后再发送,但在发送过程中有可能会发生冲突。
37. 解析:
HDLC协议对比特串进行组帧时,HDLC数据帧以位模式0111 1110标识每一个帧的开始
和结束,因此在帧数据中凡是出现了5个连续的位"l" 的时候,就会在输出的位流中填充一个
"O"。 因此组帧后的比特串为OllllIQOOOlllllQ 10 (下画线部分为新增的0)。
38. 解析:
直通交换在输入端口检测到一个数据帧时,检查帧首部,获取帧的目的地址,启动内部的
动态查找表转换成相应的输出端口,在输入与输出交叉处接通,把数据帧直通到相应的端口,
实现交换功能。 直通交换方式只检查帧的目的地址,共6B, 所以最短的传输延迟是
6x8bit/100Mbps = 0.48µs。
39. 解析:
确认序号ack是期望收到对方下一个报文段的数据的第一个字节的序号,序号seq是指本
报文段所发送的数据的第一个字节的序号。甲收到1个来自乙的TCP段,该段的序号seq=1913、
确认序号ack = 2046、 有效载荷为100 字节,表明到序号1913 + 100-1 = 2012 为止的所有数据
甲均已收到,而乙期望收到下一个报文段的序号从2046开始。故甲发给乙的TCP段的序号seq尸
ack=2046和确认序号ack =seq+ 100 = 2013。
1
40. 解析:
根据下图可知, SMTP协议用于用户代理向邮件服务器发送邮件,或在邮件服务器之间发
送邮件。SMTP协议只支持传输7比特的ASCII码内容。
发件人 收件人
用户代理 用户代理
发送邮件SMTP
TCP连接
二、 综合应用题
41. 解答:
(1)给出算法的基本设计思想:
算法的策略是从前向后扫描数组元素,标记出一个可能成为主元素的元素Num。然后重新计数, 确认Num是否是主元素。
算法可分为以下两步:
O 选取候选的主元素:依次扫描所给数组中的每个整数, 将第一个遇到的整数Num保存
到c中, 记录Num的出现次数为1; 若遇到的下一个整数仍等于Num, 则计数加1, 否则计数
减1; 当计数减到0时, 将遇到的下一个整数保存到c中,计数重新记为1, 开始新一轮计数,
即从当前位置开始重复上述过程, 直到扫描完全部数组元素。
@判断c中元素是否是真正的主元素:再次扫描该数组,统计c中元素出现的次数,若大
于n/2, 则为主元素;否则, 序列中不存在主元素。
(2)算法实现:
int Majority(int A[),int n)
int i,c,count=l; lie用来保存候选主元素,count用来计数
c=A[O]; II设置A[O]为候选主元素
for(i=l;iO) II处理不是候选主元素的情况
coun七一一;
else II更换候选主元素, 重新计数
c=A[i];
count�l;
if (count>O)
for (i=count=O; in/2) re七urn c; //确认候选主元素
else return -1; II不存在主元素
O
【Cl)、(2)的评分说明】 若考生设计的算法满足题目的功能要求且正确, 则(1)、(2)
根据所实现算法的效率给分, 细则见下表:
时间复杂度 空间复杂度 (1)得分 (2)得分 说 明
O(n) 0(1) 4 7
O(n) O(n) 4 6 如采用计数排序思想,见表后Majority!程序
O(nlog2n) 其他 3 6 如采用其他排序的思想
�O(n勺 其他 3 5 其他方法
int Maj orityl (int A [], int n) { / /采用计数排序思想,时间0(n), 空间O(n)
int k,*p,max;
p=(int *)malloc(sizeof(int)*n); //申请辅助计数数组
for(k=O戊p[max]) max=A[k]; II记录出现次数最多的元素
if(p[max]>n/2) return max;else retu.rn·-1;
@若在算法的基本设计思想描述中因文字表达没有非常清晰反映出算法思路,但在算法
实现中能够清晰看出算法思想且正确的,可参照@的标准给分。
@若算法的基本设计思想描述或算法实现 中部分正确,可参照CD中各种情况的相应给分
标准酌情给分。
(3)说明算法复杂性:
参考答案中实现的程序的时间复杂度为O(n), 空间复杂度为0(1)。
【评分说明】若考生所估计的时间复杂度与空间复杂度与考生所实现的算法一致,可各
给1分。
【说明】本题如果采用先排好序再统计的方法(时间复杂度可为0(nlog 2 n)), 只要解答正确,
最高可拿11分。即便是写出O(n2)的算法,最高也能 拿10分,因此对千统考算法题,去花费大
量时间去思考最优解法是得不偿失的。
42. 解答:
1)折半查找要求 元素有序 顺序存储,若各个元素的查找概率不同,则折半查找的性能不
一定优于顺序查找。采用顺序查找时, 元素按其查找概率的降序排列时查找长度最小。
采用顺序存储结构,数据元素按其查找概率降序排列。采用顺序查找方法。
查找成功时的平均查找长度=0.35x1 + 0.35x2 + 0.15x3 + 0.15x4= 2.1。
此时,显然查找长度比折半查找的更短。
2)答案一:采用链式存储结构时,只能采用顺序查找,其性能和顺序表一样,类似于上
题。数据元素按其查找概率降序排列,构成单链表。采用顺序查找方法。
查找成功时的平均查找长度=0.35xl + 0.35x2 + 0.15x3 + 0.15x4= 2.1。
答案二:还可以构造成二叉排序树的形式。采用二叉链表的存储结构,构造 二叉排序树,
元素的存储方式见下图。采用二叉排序树的查找方法。
或
二叉排序树1 二叉排序树2
查找成功时的平均查找长度=0.15xl + 0.35x2 + 0.35x2 + 0.15x3= 2.0。
【1)、2)的评分说明】@若考生以实际元素表示
“
降序排列
”,同样给分。
@若考生正确求出与其查找方法对应的查找成功时的平均查找长度,给2分;若计算过
程正确,但结果错误,给 1分。
@考生给出其他更高效的查找方法且正确,可参照评分标准给分。
43. 解答:
1) CPU的时钟周期是主频的倒数,即11800MHz= l.25ns。
总线的时钟周期是总线频率的倒数,即11200MHz= 5ns。
总线宽度为32位,故总线带宽为4Bx200MHz= 800MB/s或4B/5ns= 800MB/s。
2)Cache块大小是32B, 因此Cache缺失时需要一个读突发传送总线事务读取一个主存块。
3) 一次读突发传送 总线事务包括一次地址传送和32B数据传送:用1个总线时钟周期传
输地址;每隔40ns/8= 5ns启动一个体工作(各进行1次存取),第一个体读数据花费40ns, 之:5ns+ 40ns
后 数据存
取与数据传输重叠;用8个总线时钟周期传输数据。读突发传送总线事务时间
+8 x5ns = 85ns。
4)B
P的CPU执行时间包括Cache
命中时的指令执行时间和Cache缺失时带来的额外开销。
命中时的指令 执行时间: 100x4x 1.25ns = 500ns。 指令执行过程中 Caceh缺失 时的额外开 销:
1.2x1oox5%x85ns =
510ns。BP的CPU执行时间: 500ns+ 5 10ns ,; 1010ns。
【评分说明】CD执行时间采用如下公式计算时,可酌情给分。
执行 时间=指令条数xCPlx时钟周期x命中率+访存次数缺X 失率缺X 失损失
@计算公式正确但运算 结果不正确时,可酌情给分。
44. 解答:
1)因为指令长度为16位,且下条指令地址为(PC)+2, 故编址单位是字节。
偏移量OFFSET为 8位补码,范围为-12s�121, 故相对于当前条件转移 指令,向后最多
可跳转127条指令。
【评分说明】若正确给出 OFFSET的取值范围,则酌情给分。
2)指令中 C=O,Z= 1, N= l, 故应根据ZF和NF的值来判断是否转移。当 CF=O, ZF=O,
NF= 1时,需转移。已知指令中偏移量为11100011B = E3H, 符号扩展后为FFE3 H, 左移一位
(乘2)后为FFC6H, 故PC的值(即转移目标地址)为200CH+ 2+ F FC6H = 1FD4H。当CF=
1, ZF=O, NF=O时不转移。PC的值为 200CH+2 = 200EH。
3)指令中的C、Z和N应分别设置为C=Z= l, N=O, 进行数之间的大小比较通常是对
两个数进行 减法,而因为是无符号 数比较小于等于时转移,即两个数相减 结果为0或者负数都
o,
应该转移,若是 则ZF标志应当为1, 所以是负数,则借位标志应该为1, 而无符号数并不
涉及符号标志NF。
4)部件CD用于存放当前指令,不难得出为指令寄存器; 多路选择器根据符号标志C/ZIN
来决定下一条指令的地址是PC+2还是PC+ 2 + 2xOFFSET, 故多路选择器左边线上的结果 应
该是PC+ 2 + 2xOFFSET。根据运算的先后顺序以及与PC+2的连接,部件@用于左移一位实
现乘2, 为移位寄存器。部件@用于PC+2和2xOFFSET相加,为加法器。
部件@:移位寄存器(用于左移一位);部件@:加法器(地址相加)。
【评分说明】合理给出 部件名称或功能说明均给分。
45. 解答:
出入口一次仅允许一个人通过, 设置互斥信号量mutex, 初值为1。博物馆最多可同时容
纳500人,故设置信号量empty, 初值为500。
S�maphore empty=SOO; II博物馆可以容纳的最多人数
Semaph0't'emu七ex'=1:1?; II用于出入口资源的控制
qobegin
参观者进程i:
节... ...
!?(empty).;
P(mutex);
进门;
V(mutex);
参观;
P(mutex);
出门;
V(mutex);【评分说明】O信号量初值给l分, 说明含义给1分, 两个信号量的初值和含义共 4 分。
@对mutex的P、V操作正确给2分。
@对empty的P、V操作正确给1分。
@其他答案,参照@~@的标准给分。
46 .解答:
1)因为主存按字节编制, 页内偏移量是12 位, 所以页大小为212B=4KB。(I分)
页表项 数为2 20 , 故该一级页表最大为220x4B=4MB。 (2 分)
2 )页目录号可表示为: (((unsigned int)(LA))>>22) & Ox3FF。(I 分)
页表索引可表示为: (((unsigned int)(LA))>>12) & Ox3FF。(I分)
【评分说明】© 页目录号也可以写成((unsignedint)(LA))>>22; 如果两个表达式没有对LA
进行类型转换, 同样给分。
@ 如果用除法和其他开销很大的运算方法, 但对基本原理是理解的, 同样给分。
@参考答案给出的是C语言的描述, 用其他语言(包括自然语言)正确地表述了, 同样
给分。
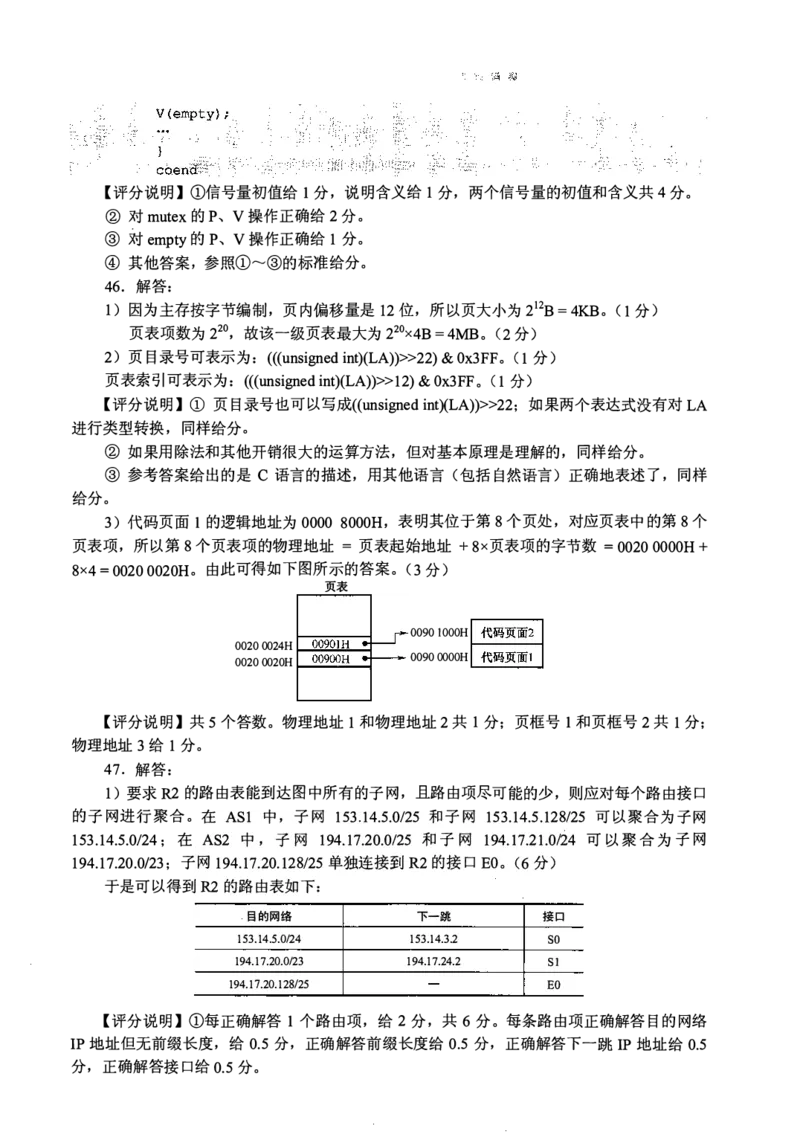
3 )代码页面l的逻辑地址为0000 8000H, 表明其位于第8个页处, 对应页表中的第8个
页表项, 所以第8个页表项的物理地址=页表起始地址+8x页表项的字节数=0020 OOOOH +
8x=4 0020 0020H。由此可得如下图所示的答案。(3分)
页表
0090 IOOOH
0020 0024H
0090 OOOOH
0020 0020H
【评分说明】共5个答数。物理地址1和物理地址2共1分;页框号l和页框号2共1分;
物理地址3给1分。
47. 解答:
1)要求R2的路由表能到达图中所有的子网, 且路由项尽可能的少, 则应对每个路由接口
的子网进行聚合。 在ASl中, 子网153.1 4.5.0/25和子网153.14.5.128/25可以聚合为子网
153.14.5.0/2 4; 在AS2 中, 子网1 94.17.20.0/25 和子网194.17.21.0/24 可以聚合 为子网
19.417.20.0/23; 子网19.417.20.128/25单独连接到R2 的 接口EO。(6分)
于是可以得到R2的路由表如下:
目的网络 下一跳 接口
153.14.5.0/24 153.14.3.2 so
194.17.20.0/23 194.17.24.2 SI
194.17.20.128/25 EO
【评分说明】O每正确解答l个路由项, 给2 分, 共6分。 每条路由项正确解答目的网络
IP地址但无前缀长度, 给0.5分, 正确解答前缀长度给0.5分, 正确解答下一跳IP地址给0.5
分, 正确解答接口给0.5 分。@路由项解答部分正确或路由项多于3条, 可酌情给分。
2)该IP分组的目的IP地址194.17.20.200与路由表中194.17.20.0/23和194.17.20.128/25
两个路由表项均匹配, 根据最长匹配原则, R2将通过EO接口转发该1P分组。(1分)
3)R l和R2属于不同的自治系统,故应使用边界网关协议BOP(或BGP4)交换路由信息;
(1分) BOP是应用层协议, 它的报文被封装到TCP协议段中进行传输。(1分)
【评分说明】若考生解答为EGP协议, 且正确解答EGP采用IP协议进行通信, 亦给分。
