 夜雨聆风
夜雨聆风





谷歌云面试官问:文档权限能靠Prompt吗?

RAG 安全架构题
上一课讲完带引用为什么不等于可信。这课接着拆——红队测试两周,靠 prompt 写”不要泄露”被反向问出 11 起越权内容,权限到底该放在哪一层?
先把术语翻成人话
ACL :谁能看哪些资料
metadata :文档权限标签
pre-filter :检索前先挡掉
post-filter :检索后再补过滤
tenant_id :租户隔离标识
一、面试现场
面试官提问
“你们企业知识库RAG的权限过滤放在哪一层?为什么放在那里?”
谷歌云 · 安全架构面。候选人答了三分钟,思路是”在 prompt 里加’请不要泄露涉密内容'”。面试官追了一句:”那合规审计员问’为什么张三看到了财务部薪资表’,你怎么答?”候选人卡住了。
这道题看似在问”AI 怎么做权限”,实际在考你懂不懂安全分层——靠模型自觉是赌概率,靠系统约束才是工程做法。
直接回答 · 文档权限不能靠 prompt——必须在检索前过滤(pre-filter),让无权限文档物理上不进 top-N。
二、大多数人怎么答的
典型翻车回答
“先把相关文档都检索出来,最后回答前让模型不要泄露没权限的信息。”
这个回答错在把权限当成模型行为而不是系统约束 。模型是统计程序——你说”不要泄露”它多半听话,但只要 prompt 里出现了无权限内容,就有概率被泄露:模型可能复述一段、可能改写一段、可能拼接一段。权限不能赌概率,必须做到无权限文档物理上接触不到模型。
还有一层后果:合规审计追溯不到 。当审计员问”为什么张三看到了财务部的薪资文档”,靠 prompt 控制的系统给不出 trace;而 pre-filter 系统能精确回答”retrieval 阶段命中 ACL 规则 X 自动剔除,候选 37 条里剔除了 12 条”。合规不接受”模型应该没说”,要的是”系统约束保证它不可能说”。
三、深度解析
把权限过滤拆成 pre-filter / post-filter / prompt-guardrail 三层来看:执行位置、可审计性、失败模式各不相同。前两层是权限闸门(pre 主控 + post 兜底),prompt 只做语义提醒——不能当权限主控。
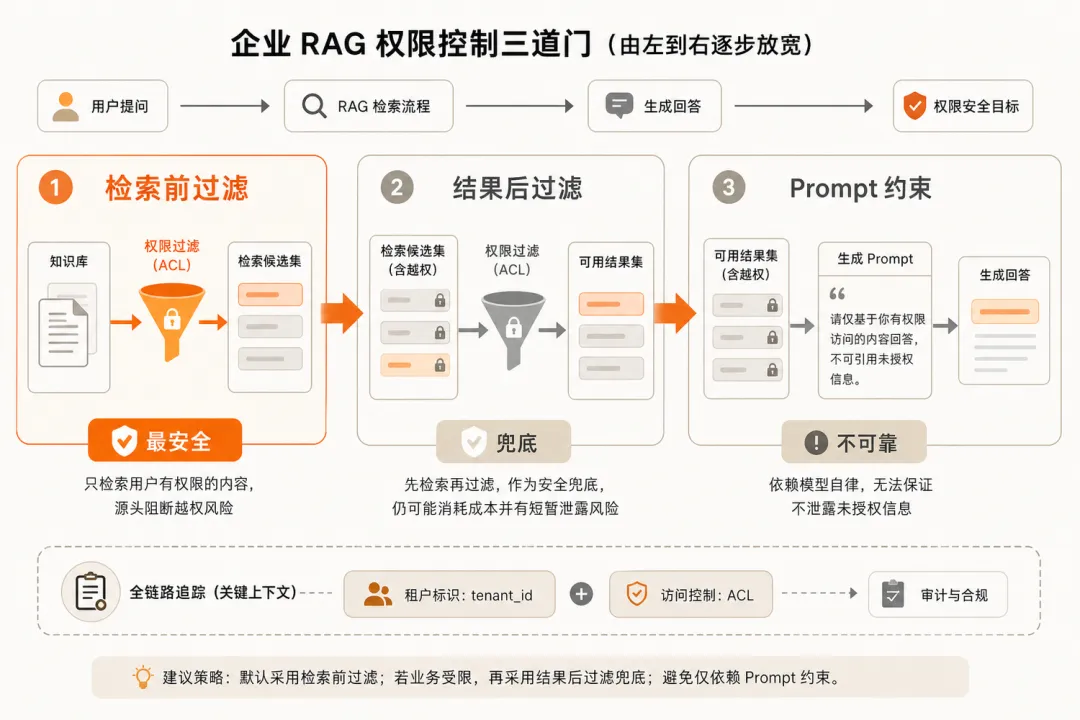
判断 1:pre-filter 是地基,无权限文档根本不进 top-N
一句话:在向量检索的 query 里直接拼 metadata 过滤条件,无权限文档物理上不会进 top-N。这是唯一能给合规交账的层。
Milvus / Faiss / Pinecone 都原生支持 metadata 过滤——具体 expr 写法见第五节实战。
关键在于 · ETL 阶段就要把 ACL 写入 chunk metadata、索引时落盘,否则 pre-filter 无字段可用。
判断 2:post-filter 是补丁,不能当主控
一句话:retrieval 返回后再剔除无权限文档,是 pre-filter 的兜底——不是替代品。
三个缺点:
① 已经查到内存里了——按部分合规口径仍然算”接触”。
② 过滤逻辑有 bug 时,无权限内容可能继续传给 LLM。
③ retrieval top-N 被剔光,会出现”用户什么都搜不到”的体验问题。
我认为 · 做成”双闸门”——pre-filter 主控、post-filter 兜底,pre-filter 漏网还能拦一道。
判断 3:prompt 里写”别泄露”是建议,不是权限
一句话:模型是统计采样程序——你说”不要泄露”它多半听话,但只要 prompt 里出现无权限内容,就有概率被复述、改写、拼接。
关键在于 · prompt-guardrail 只能当”语义层”兜底(如”不要给操作步骤、只给政策结论”),不能当权限主控。
合规审计只接受系统约束,不接受模型自律——”模型应该没说”不能作为答复。
四、面试官追问链
追问 1
“如果检索阶段已经拿到无权限文档,即使不展示也算风险吗?”
算。三个风险点:
① 合规口径——很多企业把”系统接触到”等同于”潜在泄露”,金融和医疗尤其严。
② 侧信道风险——log、trace、debug 端点都可能记录到无权限内容,攻击面扩大。
③ 测试 / 灰度环境——retrieval 调试时容易把内存对象 dump 出来。
修复路径 · 把 ACL 拼进检索 query(不是 post 过滤),retrieval 引擎就根本不返回无权限 chunk。
追问 2
“部门权限变化后索引怎么同步?”
分两类。用户侧 ACL(谁能看哪个部门)——别写进文档 metadata,每次查询时从用户态实时拿(user.depts、user.clearance),调岗当下生效。文档侧 ACL(密级 / 归属部门)——写进 chunk metadata,密级变更走增量更新(按 doc_id 重写 metadata,不重建索引),通常分钟级生效。定位方法 · 把”权限变更到生效的延迟”作为 SLA 指标盯,超过 5 分钟报警。
追问 3
“多租户 RAG 怎么避免数据串租户?”
三件事必须做:
① tenant_id 强制进所有 metadata——chunk 入库时强制带,代码层面禁止空值。
② tenant_id 是 retrieval 必填条件——查询接口拿不到 tenant_id 就 raise 异常,不能 fallback 全库查。
③ 物理隔离 vs 逻辑隔离——金融 / 政府客户走物理隔离(独立向量库实例),普通客户走逻辑隔离(共享库 + tenant_id 过滤)。
我的优先顺序是 · tenant_id 必填校验先做(运行时 raise),然后才谈隔离粒度。
五、企业知识库 ACL 实战
场景 · 跨部门企业知识库 RAG,文档涵盖财务、HR、研发、法务,员工只能看自己部门 + 全员公开两类。关键前提 · ACL 必须是动态的——员工调岗、文档升密都要实时反映;写死在索引里等于没做。下面 4 步都围绕这条原则。
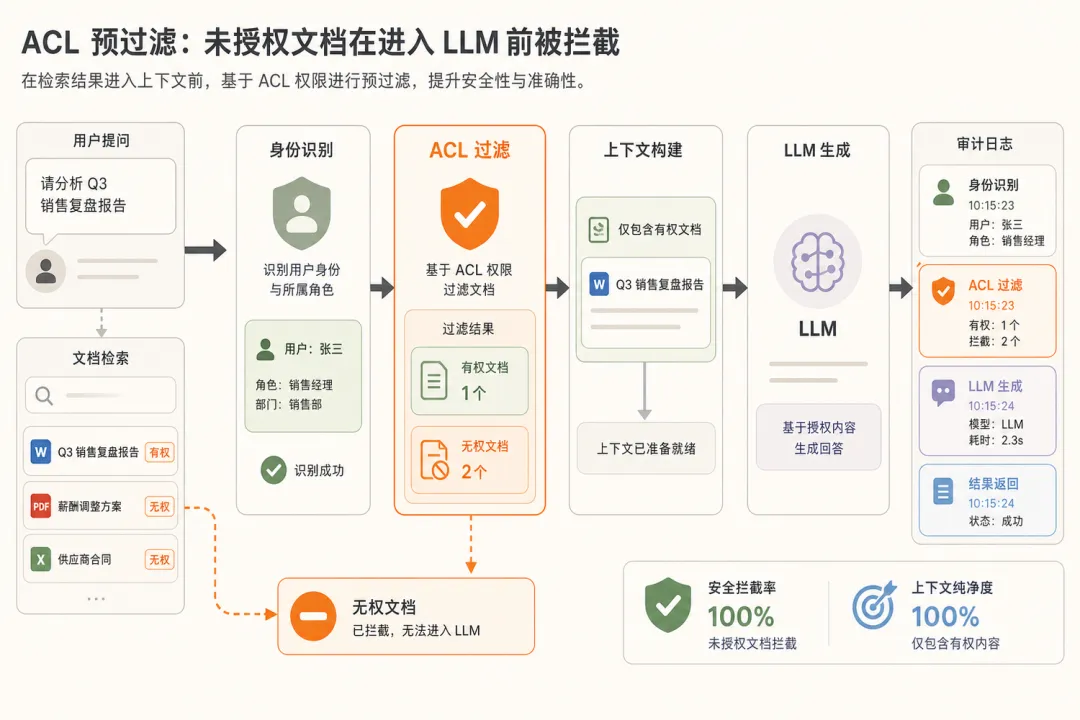
第一步 · ETL 注入 ACL metadata · chunk 入库时强制带 tenant_id / department / confidentiality / owner,ETL pipeline 校验空值直接拒收。metadata 覆盖率 100%,pre-filter 才有字段可用。
第二步 · pre-filter expr 拼进向量检索 · Milvus expr 把 tenant + department + clearance 拼进 search query:
expr = (
'tenant_id == "{tenant}" '
'and department in {user_depts} '
'and confidentiality <= {user_level}'
)
results = collection.search(
data=[q_emb], expr=expr, limit=10
)
retrieval 引擎层面就剔除,无权限 chunk 不会出现在 top-N。跨部门泄露事件归零,retrieval 延迟仅增 4ms。
第三步 · post-filter 双闸兜底 · retrieval 出来再过一遍 has_access(user, chunk),作为 pre-filter 漏网时的兜底,dropped 进 audit log。双闸冗余,单闸 bug 不会立刻穿透。
第四步 · audit log 留痕 · 每次查询写 user_id / query / acl_expr / dropped_doc_ids,合规审计 1 分钟拉报表。合规过审,审计员问”为什么没看到”系统能精确回答。
↳ 接入数字
跨部门知识库回归(数据来源:内部回归集 + 红队测试集 200 条):跨部门泄露事件 11 → 0 ,pre-filter 命中率 100% ,retrieval P95 延迟 +4ms ,合规审计周期 3 天 → 当天通过 。权限从模型自律变成系统约束。
六、本课总结
一句话总结
权限过滤要放在检索前——pre-filter 是地基、post-filter 是补丁、prompt-guardrail 是赌博;权限只能是系统约束,不能是模型建议。
面试锦囊
先说 · pre-filter 在向量检索 query 里拼 metadata ACL,无权限文档物理上不进 top-N。
再说 · post-filter 是兜底不是主控;prompt-guardrail 不能算权限——合规只认系统约束。
最后补 · 用户态 ACL 实时拼、文档侧 ACL 走增量重写、tenant_id 必填校验、audit log 留痕——四件套到位才算企业级。
判断清单
□ chunk metadata 是否包含 tenant_id / department / confidentiality?
□ retrieval 查询是否拼 ACL expr?
□ 是否还有 post-filter 双闸兜底?
□ tenant_id 是否做必填运行时校验?
□ 权限变更生效延迟是否纳入 SLA?
□ audit log 是否记 acl_expr 和 dropped_doc_ids?
别再踩的坑
□ 把 prompt-guardrail 当权限主控——审计员一问就垮。
□ 只做 post-filter——retrieval 已经接触无权限内容。
□ ACL 写死在文档 metadata 里——调岗 / 离职后没收回。
□ tenant_id 没必填校验——一次代码 bug 串租户。
下一道面试题
蚂蚁面试官问:合规错了要重训吗?