 夜雨聆风
夜雨聆风





小龙虾总失忆?你可能仅用了OpenClaw memory 30%的能力!
OpenClaw 记忆系统基于一个简单而强大的哲学:写文件即记忆。没有隐藏状态,没有黑盒存储——模型只能记住写入磁盘的内容。所有记忆以纯 Markdown 文件形式存储在 Agent Workspace 中,可审计、可编辑、可追溯。
小提示:如果你只关注为啥失忆的原因,请直接食用第4节。
总体架构和流转如下图
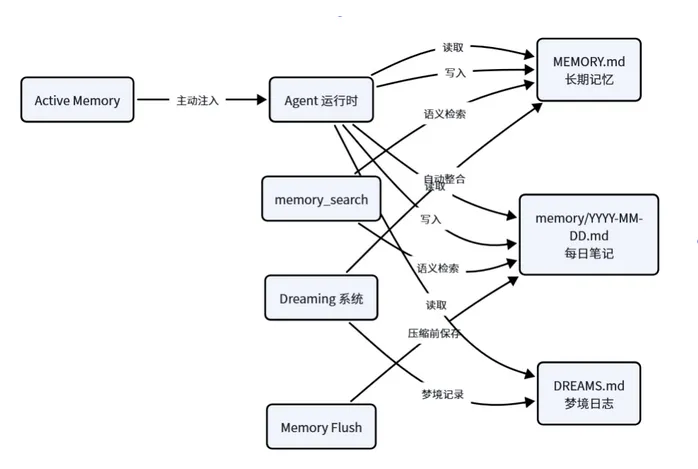
1. 总览
OpenClaw 的记忆系统建立在以下核心原则上:

2. 核心三层记忆文件
OpenClaw 的记忆体系由三层文件构成,各司其职:
|
记忆文件 |
类型 |
加载时机 |
说明 |
|---|---|---|---|
|
MEMORY.md |
长期记忆 |
DM 会话启动 |
精炼、持久的事实、偏好、决策。不是原始日志,是经过整理和提炼的”精华”。类似人类的长期记忆。 |
|
memory/YYYY-MM-DD.md |
每日笔记 |
今天+昨天自动 |
详细的日常观察、会话摘要、原始上下文。类似日记或工作笔记。被 memory_search 索引。 |
|
DREAMS.md |
梦境日志 |
按需读取 |
Dreaming 系统生成的梦境摘要和回顾。供人类审阅 Agent 的”梦”。 |

3. 记忆工具
Agent 通过两个核心工具与记忆系统交互:

两个工具均由memory plugin 提供,默认使用 memory-core 插件。
4. 记忆搜索机制
4.1 混合搜索架构:两条通路
OpenClaw 的记忆搜索设计了一个双引擎架构——当配置了 embedding provider 时,memory_search 会同时启用两条检索通路:
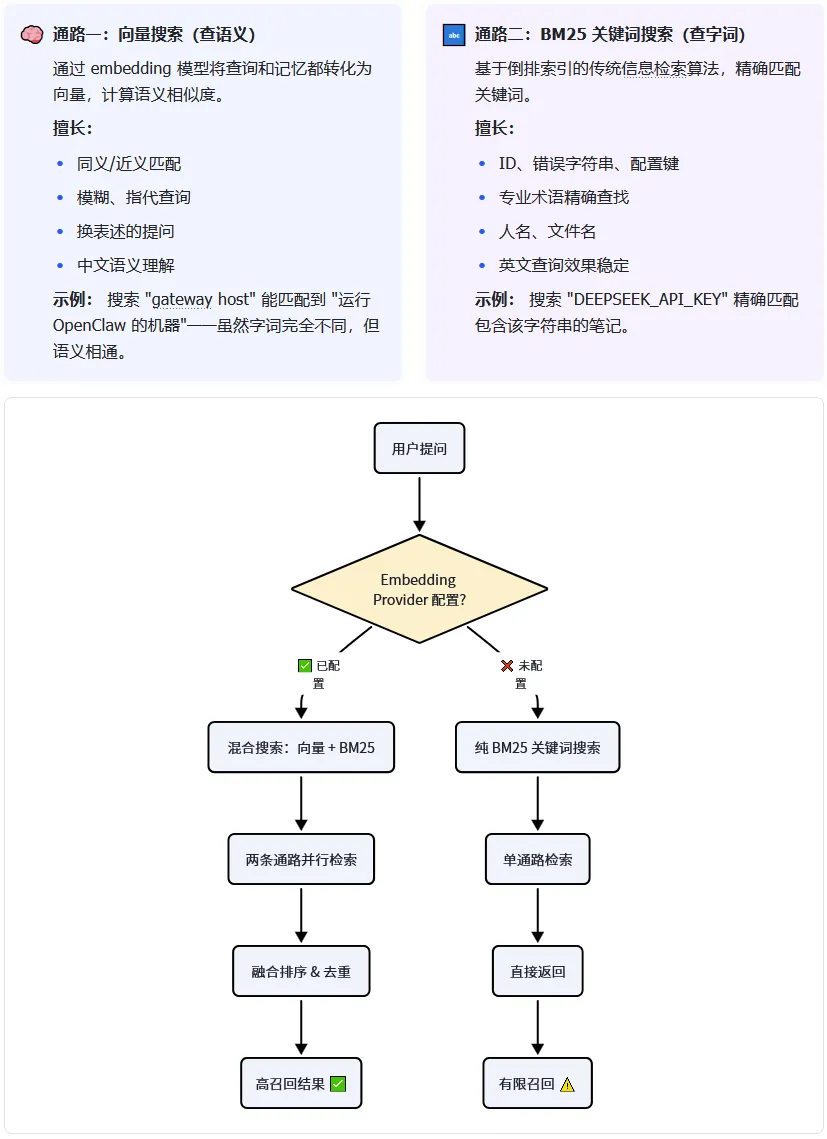
4.2 现实:很多人其实只用了一条通路

大多数人配置 OpenClaw 时:
-
✅ 会配 API key、选模型
-
✅ 会设飞书、微信等通道
-
❌ 几乎不会主动配置 embedding provider
而 embedding 的配置是零感知的——不报错、不警告、系统照样跑。你只是感觉”记忆好像不太好用”,但说不清为什么。
OpenClaw 文档提到:
OpenClaw auto-detects your embedding provider from available API keys. If you have an OpenAI, Gemini, Voyage, or Mistral key configured, memory search is enabled automatically.
所以如果你碰巧配了 OpenAI/Gemini/Voyage/Mistral 的 key,向量搜索就自动开了。 但如果你只配了 vLLM 或本地模型,就需要手动配置 embedding。
4.3 缺失向量索引的真实代价
一句话结论:没有向量搜索,记忆召回质量会损失约 50%-70% 的”自然回忆”能力。(重要的事情说3遍)
少了向量搜索,等于从”理解你问什么”退化到”只能精准匹配关键词”。
真实场景对比
|
你的提问 |
笔记里写的 |
有向量? |
无向量? |
|---|---|---|---|
|
“上次面试怎么样” |
“凯哥有个技术面试” |
✅ 命中 |
❌ 关键词无交集,查不到 |
|
“那个配置问题解决了没” |
“DNS 解析故障已修复” |
✅ 命中 |
❌ 查不到 |
|
“gateway host 是什么” |
“运行 OpenClaw 的机器” |
✅ 命中 |
❌ 查不到 |
|
“查一下 DEEPSEEK_API_KEY” |
“DEEPSEEK_API_KEY 环境变量” |
✅ 命中 |
✅ 也命中(精确匹配) |
影响程度分级

4.4 支持的 Embedding Provider
|
Provider |
说明 |
|---|---|
|
Bedrock |
AWS Bedrock 托管的 embedding 服务 |
|
Gemini |
Google Gemini 文本嵌入 |
|
GitHub Copilot |
GitHub Copilot 集成嵌入 |
|
Local (GGUF) |
本地 GGUF 模型,约 0.6 GB,完全离线运行 |
|
Mistral |
Mistral AI 嵌入服务 |
|
Ollama |
通过 Ollama 运行的本地嵌入模型 |
|
OpenAI |
OpenAI text-embedding 系列 |
|
Voyage |
Voyage AI 高质量嵌入 |
OpenClaw 会自动从已配置的 API key 检测 embedding provider,无需手动指定。
4.5 质量优化
|
机制 |
说明 |
|---|---|
|
时间衰减 |
旧笔记逐渐降低排名权重,半衰期 30 天;MEMORY.md 等常青文件永不衰减 |
|
MMR 多样性 |
当多条笔记覆盖相同主题时,减少冗余结果,确保搜索结果多样化 |
4.6 配置建议

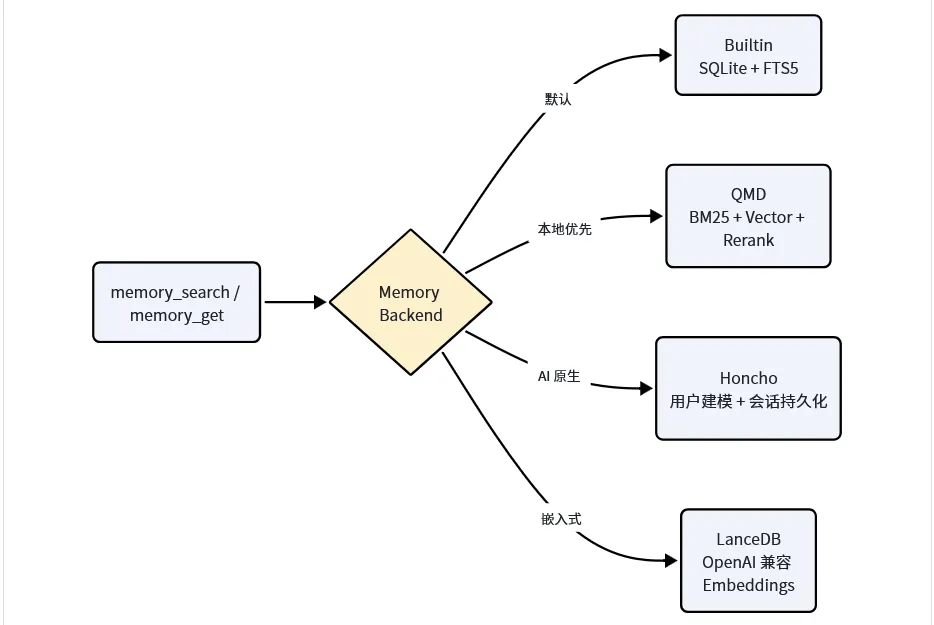
5. 记忆后端引擎
OpenClaw 支持多种记忆后端引擎,可根据需求选择:
|
引擎 |
特性 |
|---|---|
|
Builtin(默认) |
SQLite 后端,存储在 \`~/.openclaw/memory/<agentId>.sqlite\`。提供 FTS5 关键词搜索、向量搜索、混合搜索、CJK 支持。无需额外依赖,开箱即用。 |
|
QMD |
本地优先搜索侧车,结合 BM25、向量搜索、reranking。支持索引 workspace 外的目录、索引会话记录。安装: \`npm install -g @tobilu/qmd\` |
|
Honcho |
AI 原生跨会话记忆,提供用户建模、会话持久化、多 agent 感知。以插件形式安装。 |
|
LanceDB |
本地嵌入支持,OpenAI 兼容 embeddings。适合需要高性能向量检索的场景。 |
6. Dreaming 系统(梦境记忆整合)
Dreaming 是 memory-core 中的后台记忆整合系统。默认禁用。
6.1 三个阶段
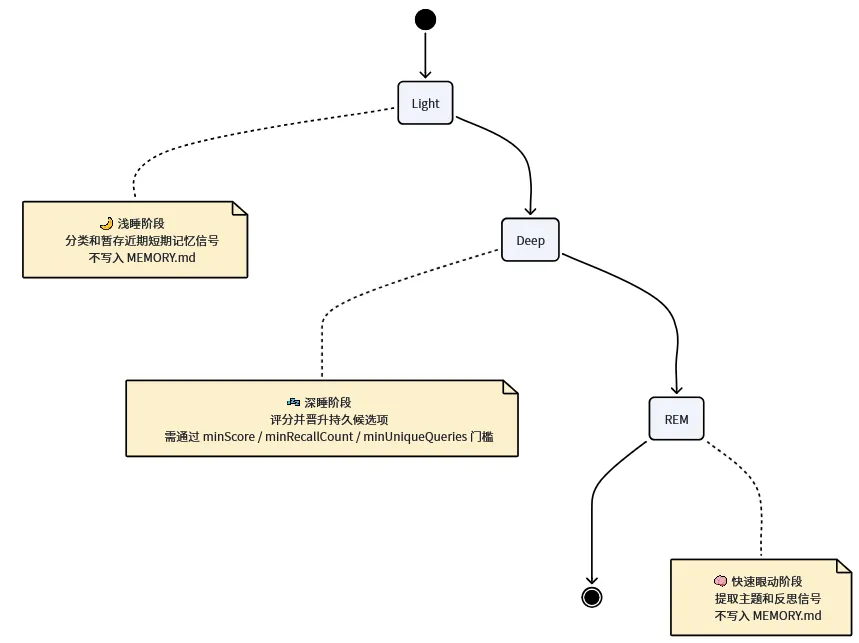
|
阶段 |
名称 |
职责 |
是否写入 MEMORY.md |
|---|---|---|---|
|
Light |
浅睡 |
分类和暂存近期短期记忆信号 |
❌ |
|
Deep |
深睡 |
评分并晋升持久候选项到 MEMORY.md |
✅ |
|
REM |
快速眼动 |
提取主题和反思信号 |
❌ |
6.2 Deep 排名信号(六项加权)
晋升到 MEMORY.md 需要候选项通过多维度评分:
|
信号 |
权重 |
含义 |
|---|---|---|
|
Frequency |
0.24 |
条目积累的短期信号数 |
|
Relevance |
0.30 |
条目检索质量平均值 |
|
Query diversity |
0.15 |
触发条目的不同查询 / 天数上下文 |
|
Recency |
0.15 |
时间衰减新鲜度 |
|
Consolidation |
0.10 |
多日重复强度 |
|
Conceptual richness |
0.06 |
概念标签密度 |

Grounded Backfill
可以回放历史 memory/YYYY-MM-DD.md 笔记,生成结构化的回顾输出到 DREAMS.md。适用于初始化或追赶记忆整合的场景。
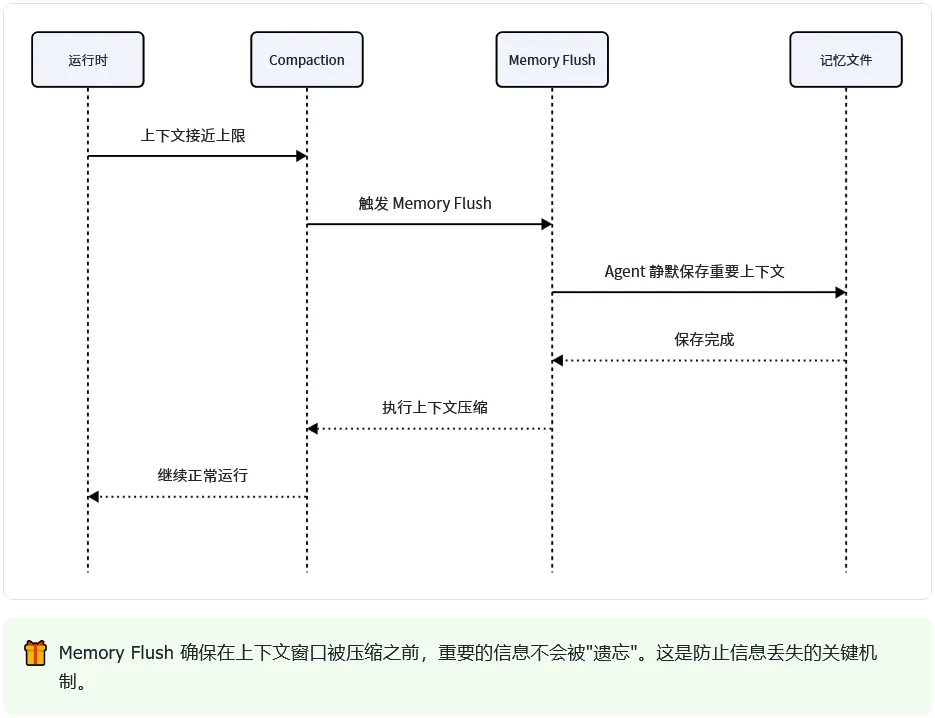
7. Memory Flush(自动记忆保存)
在 compaction(上下文压缩)之前,OpenClaw 会自动运行一个静默回合,提醒 agent 将重要上下文保存到记忆文件。默认开启。
8. Active Memory(主动记忆注入)
可选的 plugin-owned 阻塞记忆子 agent,在主要回复之前运行。
工作原理

与被动搜索不同,Active Memory 不依赖主 agent 决定何时搜索记忆——它主动搜索相关记忆并注入到会话中。

9. Commitments(推断的承诺)
短期的后续记忆。当你提到”明天的面试”,OpenClaw 可能会记住”面试后回访”。
|
特性 |
Commitments |
Cron 定时任务 |
|---|---|---|
|
触发方式 |
自动推断 |
手动设置 |
|
生命周期 |
短期、事件驱动 |
固定周期 |
|
来源 |
对话中的承诺和待办 |
用户明确指令 |
|
示例 |
“面试后回访” |
“每周一 9:00 检查日历” |

10. Memory Wiki(知识库层)
将持久记忆编译成带有确定性页面结构、结构化主张和证据、矛盾追踪、生成仪表板的知识库。
特性


11. CLI 工具
OpenClaw 提供了完整的命令行工具来管理记忆:
|
命令 |
说明 |
|---|---|
|
openclaw memory status |
检查索引状态和 embedding provider 配置 |
|
openclaw memory search “query” |
从命令行执行记忆搜索 |
|
openclaw memory index –force |
强制重建记忆索引 |
|
openclaw memory promote |
预览 Dreaming 晋升候选项 |
|
openclaw memory promote –apply |
应用晋升,将候选项写入 MEMORY.md |
总结:
OpenClaw 的记忆系统是一个多层次、多维度的记忆框架。从底层的文件存储,到中层的语义搜索和后端引擎,再到上层的 Dreaming 整合和 Active Memory 注入,每一层都在解决 Agent 跨会话记忆的某个核心问题。理解这个体系,就能更好地理解 OpenClaw 是如何”记住”事物的。