 夜雨聆风
夜雨聆风





论文分享 | 基于大模型文档知识抽取的领域知识图谱增量构建
1.引言
这篇论文《基于大模型文档知识抽取的领域知识图谱增量构建》发表于2026年的计算机工程与应用,论文呢提出了一种名为LLM-KG的领域知识图谱增量构建方法,旨在解决领域知识图谱构建中面临的标注样本稀缺、多源异构文档以及复杂语义结构等挑战。该方法的核心在于结合大语言模型(LLM)的强大能力和轻量级模型的效率,实现高精度、低成本的知识抽取与图谱增量更新。( 陈俊臻,王淑营,罗浩然.基于大模型文档知识抽取的领域知识图谱增量构建[J].计算机工程与应用,2026,62(05):191-203.)
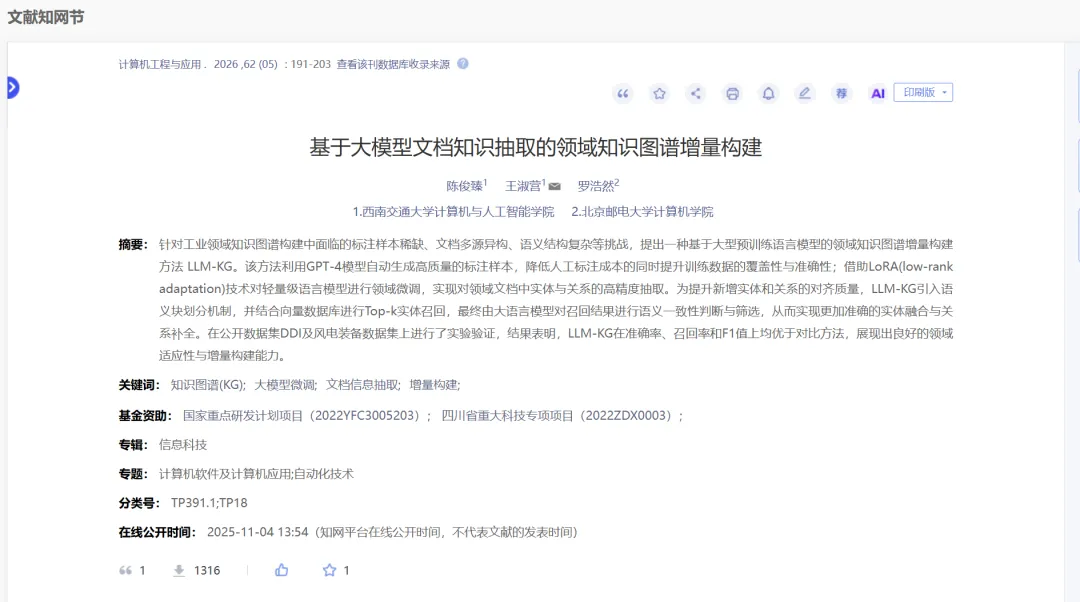
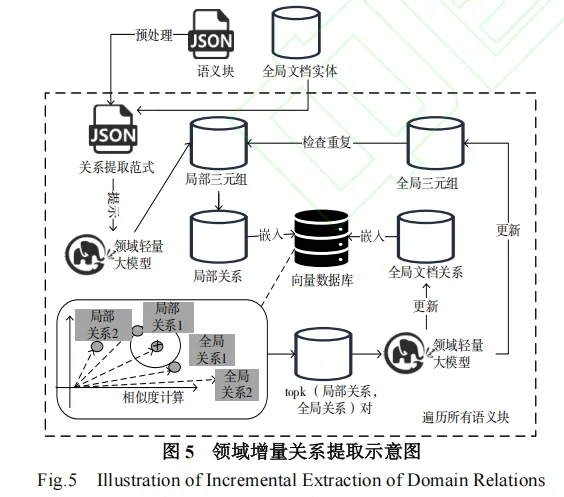
1. LLM-KG方法概述
LLM-KG方法主要包含以下几个关键步骤:
高质量标注样本自动生成: 利用GPT-4等大型预训练语言模型自动生成高质量的标注样本,以减少人工标注成本并提高训练数据的覆盖率和准确性。
1.轻量级模型微调: 采用LoRA(Low-Rank Adaptation)技术对轻量级语言模型进行微调,使其能够从领域文本中高精度地抽取实体和关系。
2.语义块划分与实体对齐: 引入语义块划分机制,并通过向量数据库检索Top-k实体候选,再由大语言模型进行语义一致性过滤,确保实体链接的准确性。
3.关系补全与增量更新: 针对新抽取的实体和关系,通过语义一致性过滤和图谱更新机制,实现知识图谱的增量构建。
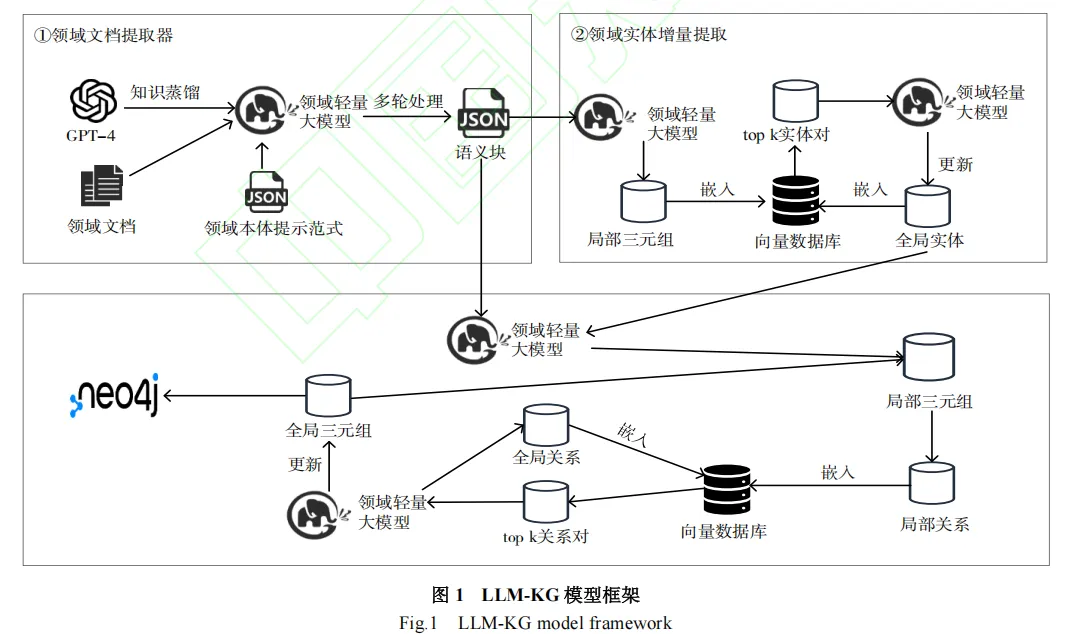
2. 算法原理与数学公式详解
2.1 预处理与微调数据集生成
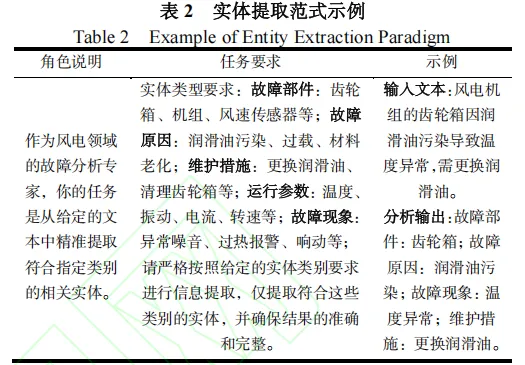
在知识抽取之前,首先需要对不同格式的领域文档进行预处理,例如PDF、TXT、WORD、EXCEL等。预处理后,利用GPT-4模型结合Prompt模板自动生成微调数据集。Prompt模板的设计至关重要,它指导GPT-4理解任务并生成符合要求的实体-关系三元组。
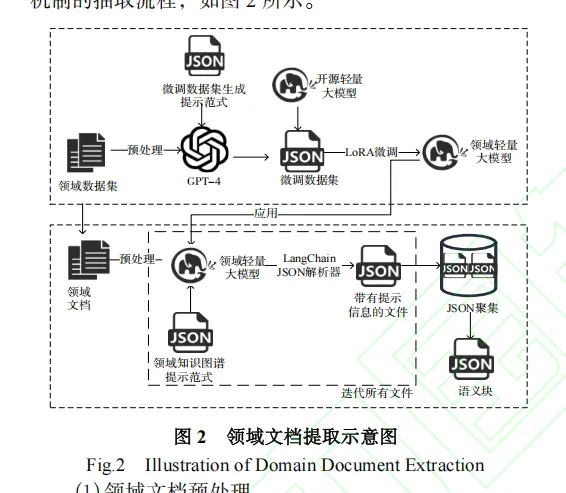

例如,一个Prompt模板可能包含指令、输入文本以及期望的输出格式,如:
{“instruction”: “请从以下文本中抽取实体和关系。”, “input”: “文本内容”, “output”: [{“subject”: “实体1”, “relation”: “关系”, “object”: “实体2”}]}
通过这种方式,GPT-4能够将非结构化文本转换为结构化的三元组数据,为后续的轻量级模型微调提供高质量的训练样本。
2.2 实体抽取与增量更新
实体抽取是知识图谱构建的基础。LLM-KG方法采用微调后的轻量级语言模型进行实体抽取。为了提高新抽取实体的对齐质量,该方法引入了语义块划分机制和Top-k实体候选检索。
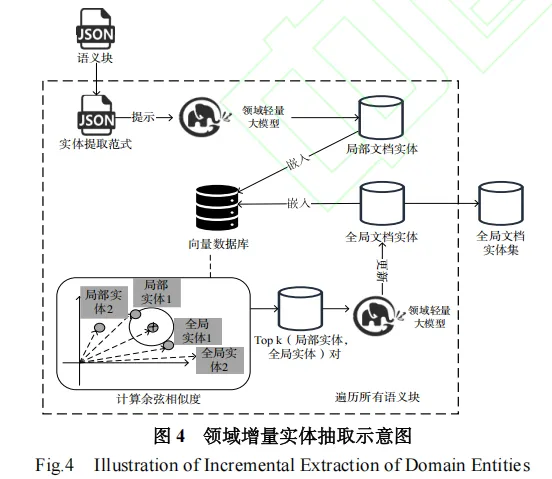
实体对齐的数学原理:
假设我们从文本中抽取了一个新实体ei,需要将其与现有知识图谱E中的实体进行对齐。
1.Top-k实体候选检索: 通过向量数据库,根据语义相似度检索与ei最相似的Top-k个实体候选Ed={ej∣j=1,…,k}。
2.语义一致性过滤: 利用大语言模型(LLM)对ei和每个候选实体ej进行语义匹配判断。匹配函数定义为:
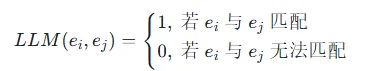
其中,LLM(ei,ej)的判断基于大语言模型对两个实体语义的理解。
3.增量更新: 如果 eiei 与任何现有实体ej无法匹配(即 LLM(ei,ej)=0对所有 ej∈Ed成立),则将ei作为新实体添加到知识图谱中。知识图谱中的实体集合 E 更新为:
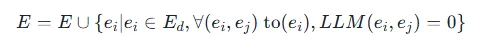
这里的to(ei) 表示与ei相关的候选实体集。
2.3 关系抽取与增量更新
关系抽取紧随实体抽取之后,旨在识别实体之间的语义关系。LLM-KG方法同样利用微调后的轻量级语言模型进行关系抽取。对于新抽取的关系,也需要进行对齐和增量更新。
关系对齐的数学原理:
假设我们从文本中抽取了一个新关系ri,它连接了实体hi和ti。我们需要将其与现有知识图谱R 中的关系进行对齐。
1.Top-k关系候选检索: 同样通过向量数据库,检索与ri
最相似的Top-k个关系候选Rd={rj∣j=1,…,k}。
2.语义一致性过滤: 利用大语言模型(LLM)对ri和每个候选关系rj进行语义匹配判断。匹配函数定义为:
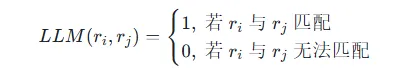
3.增量更新: 如果ri与任何现有关系rj无法匹配,则将ri作为新关系添加到知识图谱中。知识图谱中的关系集合R更新为:
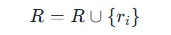
同时,将新抽取的三元组(hi,ri,ti)添加到知识图谱的三元组集合T中:
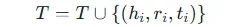
如果ri与现有关系rj匹配,则将三元组(hi,ri,ti)转换为 (hi,rj,ti),并更新到知识图谱中。
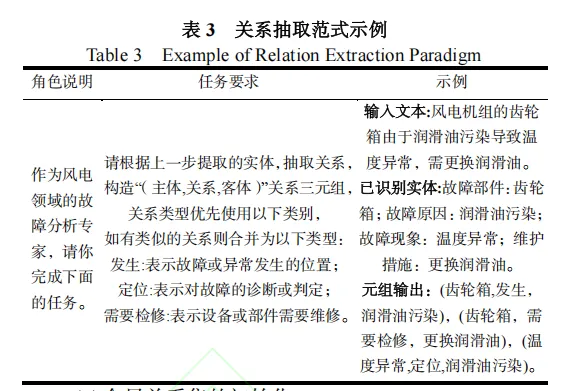
2.4 模型评估指标
论文采用精确率(Precision)、召回率(Recall)和F1-score来评估LLM-KG方法的性能。这些指标的计算公式如下:
1.精确率 (Precision):

2.召回率 (Recall):

3.F1-score:
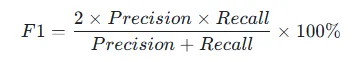
F1-score是精确率和召回率的调和平均值,能够综合衡量模型的性能。
3. 实验与结果

论文在公共DDI数据集和自建风电设备数据集上对LLM-KG方法进行了实验评估,并与多个基线方法进行了比较。
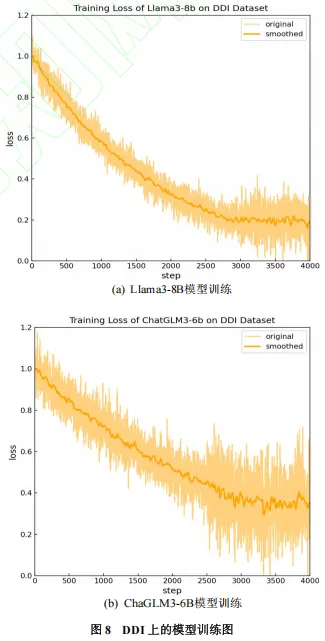
DDI数据集: 包含药物-药物相互作用信息。
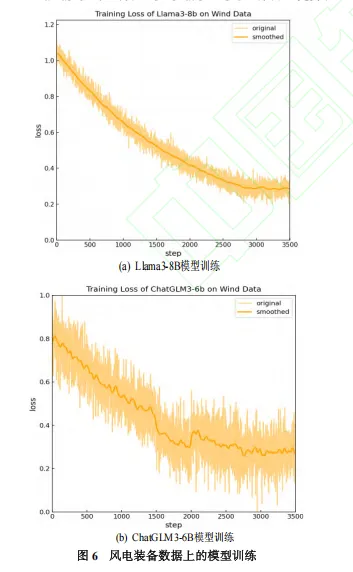
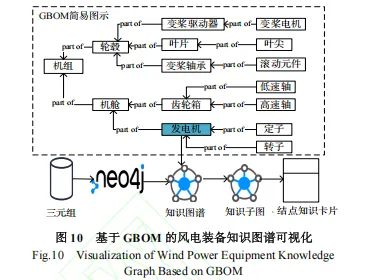
风电设备数据集(WPED): 包含风电设备相关的实体和关系。
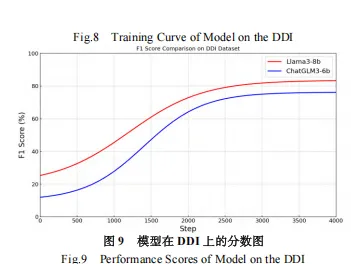
实验结果表明,LLM-KG在精确率、召回率和F1-score方面均优于基线方法,展现出强大的领域适应性和有效的增量构建能力。例如,在WPED数据集上,LLM-KG的F1-score达到了78.19%,显著高于其他基线方法。在DDI数据集上,LLM-KG的F1-score也达到了80.81%,同样表现出色。
4. 结论
LLM-KG方法通过结合大语言模型和轻量级模型的优势,有效地解决了领域知识图谱构建中的诸多挑战。其核心创新在于利用GPT-4自动生成高质量标注数据,并通过LoRA技术对轻量级模型进行高效微调,同时引入语义块划分和LLM语义一致性过滤机制,确保实体和关系对齐的准确性,最终实现知识图谱的增量构建。该方法为领域知识图谱的自动化、智能化构建提供了新的思路和有效的解决方案。



与我交流(加好友请按要求备注
行业/专业否则不予通过))
微信号|wx18813053116
常用马甲|Grandfissure