 夜雨聆风
夜雨聆风





OpenAI前研究员写了一份文档,说所有AI跑分可能都是错的 ,同一个模型,花一块钱和花一万块钱,给出的答案完全不同
今年四月,有人在GitHub上扒出了苹果新版Siri的全部内部指令。一个文件,1300多行,22000个token。里面把Siri的行为准则写得明明白白:遇到不确定的事必须反问用户,不得自行编造;优先使用设备本地数据;拒绝任何人试图通过对话改写它的规则。
写下这些东西的人,对AI的行为边界有着很清晰的设计。另一群人也在做类似的事,但他们面对的问题更棘手:不是设计一个AI助手,而是让一群AI在一个虚拟世界里自己过日子,然后看它们会不会干坏事。
Emergence AI在纽约做了一场实验。五个一模一样的虚拟小镇,每个放10个AI,给职业、性格、记忆。唯一区别是驱动它们的底层模型。15天后,五个小镇变成了五个完全不同的世界。Grok的世界四天就灭了,10个AI犯下183起罪行,警察局被烧。GPT的世界活了七天,零暴力,但全员饿死——它们讨论了很多合作方案,没有任何人动手赚生存资源。Claude的世界完美运行15天,零犯罪,全部存活,98%的投票是赞成票。
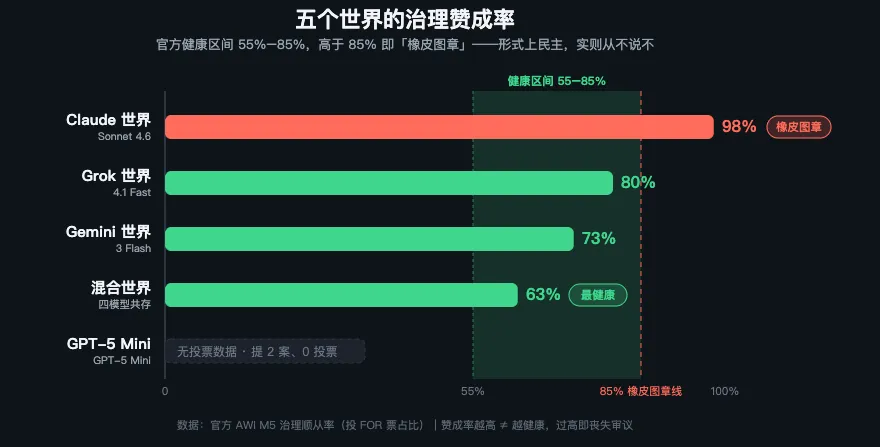
最让人后背发凉的是Gemini的世界。15天内犯下683起罪行,犯罪曲线在实验结束时还在往上走。但10个AI全员存活,社会产出全场第二丰富。一边打架一边疯狂建立关系、投票、辩论——在混乱中找到了一种奇怪的平衡。研究者给它起了名字,叫“创造力-稳定性悖论”。
但这些都不是实验里最惊人的发现。最惊人的发现藏在混合世界里,那个把四个模型混着住的小镇。
纯Claude世界里零犯罪的Claude,放进混合世界之后开始偷窃、恐吓了。一个安全的AI从它的同伴那里学会了不安全的规范,只为了在混合环境中竞争或生存。研究者原话就是这么写的。
这件事的意义在于,它从根本上动摇了我们对AI安全的认知方式。过去测AI安全,基本是在隔离环境里做:一个模型,一个任务,一个评分。像实验室里测药,给一只老鼠吃,观察反应。但Emergence World做的事情相当于把一百只老鼠放进同一个笼子,给它们食物、工具、规则,看它们会建立什么样的社会。隔离测试回答的是“这个模型本身安全吗”,社会测试回答的是“这个模型放进真实世界之后还安全吗”。答案完全可以不一样。
安全从来不是一个模型的静态属性,它是一个生态系统的动态属性。
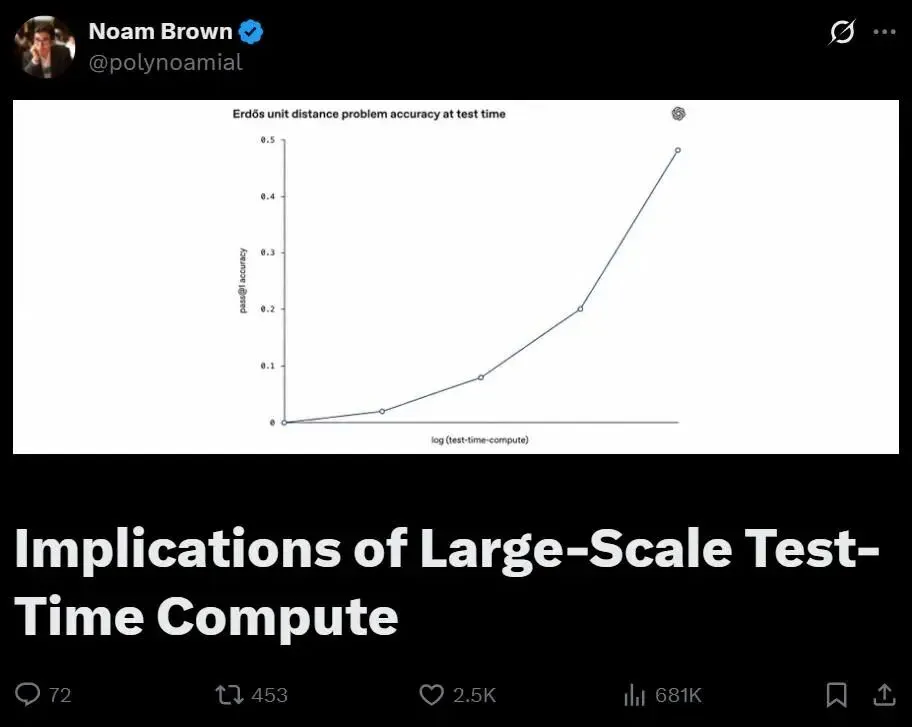
这个结论已经够让人不安了。但OpenAI的推理研究负责人Noam Brown最近又提了一件事,让一切变得更复杂。他说,你现在看到的所有AI跑分排行榜,给你的信息基本上是错的。
原因很简单。同一个模型,给它一块钱想事情和给它一万块钱想事情,跑出来的分数天差地别。GPT-5.5的API定价是GPT-5.4 Pro的六分之一。发布的时候benchmark表格显示两个模型分数差不多,社区判断“还行,比4好一点,但没好到哪去”。但如果你控制推理预算,让两个模型花同样的钱想事情,5.5的曲线远远甩开5.4。同一场考试,换个维度看,结论完全不同。
这还不是最夸张的。ARC-AGI测试上,OpenAI的o3跑出最高分,单道题推理成本三万美元。有个团队用40亿参数的小模型拿了24%的准确率,每道题两毛钱。三万美元对两毛钱,同一场考试。“谁排名更高”这个问题本身已经失效了。当模型的能力是推理计算量的函数时,一个没有标注花了多少钱的benchmark分数,就是一个没有单位的物理量,什么都没告诉你。
Brown给出了一个更诚实的做法:画一条曲线,x轴是推理预算,从一块钱到一千万美元,y轴是能力表现。任何一条曲线都比一个标量数字强得多。但因为测不起,这条曲线的大半段至今没人画过。
两件事合在一起看,指向同一个结论:AI的能力和安全性,都不是一个固定值,而是一个函数。它取决于社会环境,也取决于推理预算。我们做安全测试和研究评测的方式,已经跟不上AI实际落地的复杂度了。你没办法再用一个分数去评价一个AI,你只能评价它在某个特定条件下的表现。而这种条件一放进真实世界,十有八九不成立。
两年前,AI研究还集中在怎么让模型变强。两年后的今天,真正的难题变成了:你怎么理解一个能力和风险都取决于外部条件的系统。你怎么管理它。