 夜雨聆风
夜雨聆风





Palantir官方文档—为什么需要本体Ontology
在数字化浪潮席卷全球的今天,企业每天都在产生海量数据。然而,现实却是:数据越堆积越多,决策却越来越难。数据分散在数十甚至数百个异构系统中,各部门对同一业务概念的理解各不相同,AI 模型因缺乏业务上下文而频频“幻觉”。
Palantir 认为,要解这道题,不能靠堆叠更多的工具和报表,而要从根源上重构数据与业务之间的映射关系——这也正是 Ontology(本体) 诞生的初衷。
一、问什么需要本体Ontology?
要理解为什么需要 Ontology,首先要看清传统数据平台中普遍存在的问题。
1.1 传统模式的四大问题
|
|
|
|---|---|
| 语义不统一 |
cust_nm,业务人员无法直接理解 |
| 逻辑不一致 |
|
| 只读问题 |
|
| AI落地困难 |
|
1.2 Ontology 如何破局
|
|
|
|---|---|
|
|
|
| 逻辑不一致 |
|
|
|
|
|
|
|
二、Ontology 的业务价值
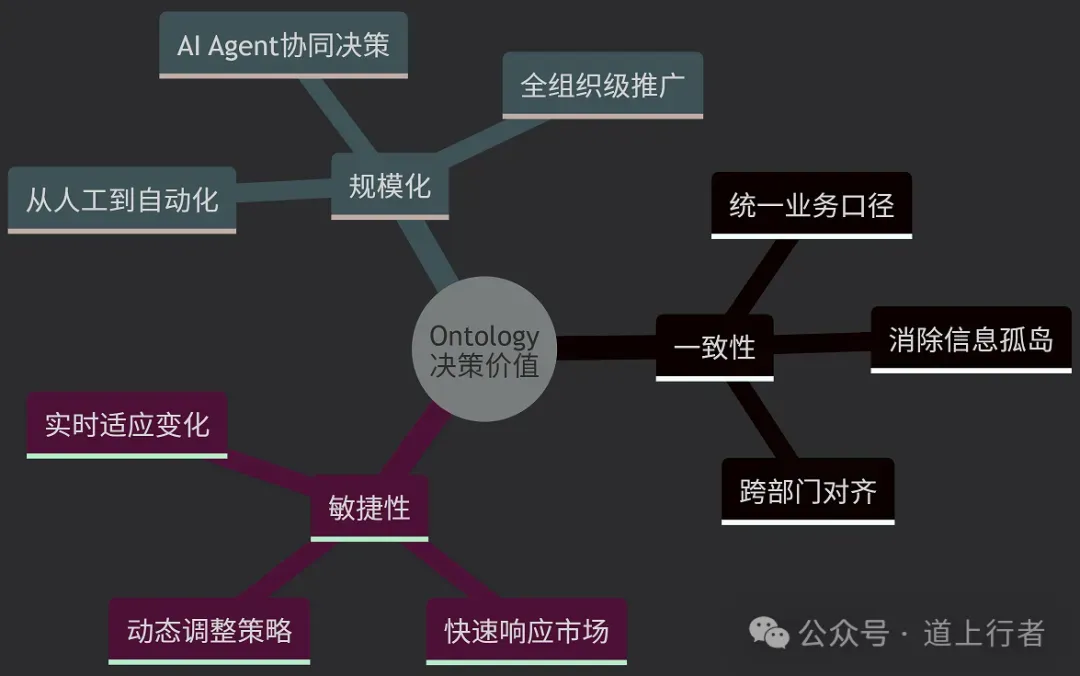
2.1 决策层面的价值
Ontology 的最终使命是支撑更好的决策。它让企业能够基于不断变化的内部和外部条件,做出尽可能好的、通常是实时的决策。具体体现在以下三个方面:
2.2 AI 层面的价值
在 AI 时代,Ontology 的价值愈发凸显。它让人和 AI 代理能够安全地推演各种“场景”(Scenarios),在统一的管控下自由尝试和决策,最终将可行性方案以安全、可控的方式写回真实的业务环境中。
通过 Ontology SDK,开发商可以生成与业务模型完全一致的 SDK(支持 Python、Java 和 TypeScript),直接在自己的开发环境中使用 Ontology 的力量。这就意味着,一个企业级的 AI 应用——从数据读取到逻辑推理,再到最终的行动执行——可以在 Ontology 的统一语义底座上快速搭建,而无需为每一个应用场景“从零建模”。
三、Ontology vs 知识图谱:澄清常见误解
很多人会将 Ontology 与知识图谱(Knowledge Graph)混为一谈。事实上,两者虽然都涉及“实体”和“关系”,但其设计哲学和应用范畴有着本质的区别。为了更清晰地理解 Ontology 的独特定位,这里用表格对比其与传统知识图谱的区别:
|
|
|
|
|---|---|---|
| 核心目标 |
|
|
| 语义表达能力 |
|
极强
|
| 对外操作能力 |
|
读写兼备
|
| 是否能被 AI 理解 |
|
是
|
| 安全与治理 |
|
内置全生命周期
|
|
|
|
|
|---|---|---|
| 建模对象 |
|
|
| 核心组成 |
|
|
| 动态能力 |
|
活的
|
| 典型场景 |
|
|
Ontology 更类似于 Java 中的面向对象建模——你需要先定义清晰的类、接口、属性和方法,构建出一个严格的、可执行的结构框架,再去承载具体的业务数据。而知识图谱则更侧重于“从非结构化数据中抽取知识”,擅长发现隐性的关系网络。
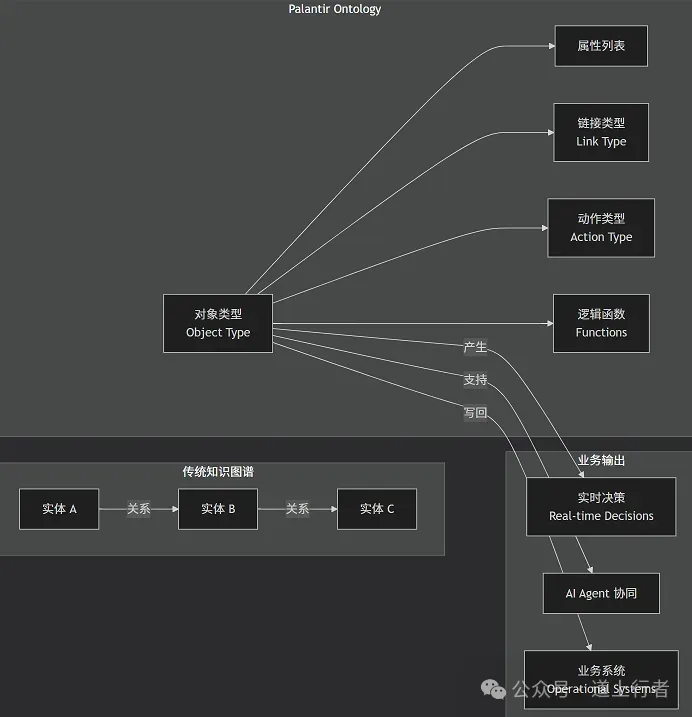
附Ontology 关键要素
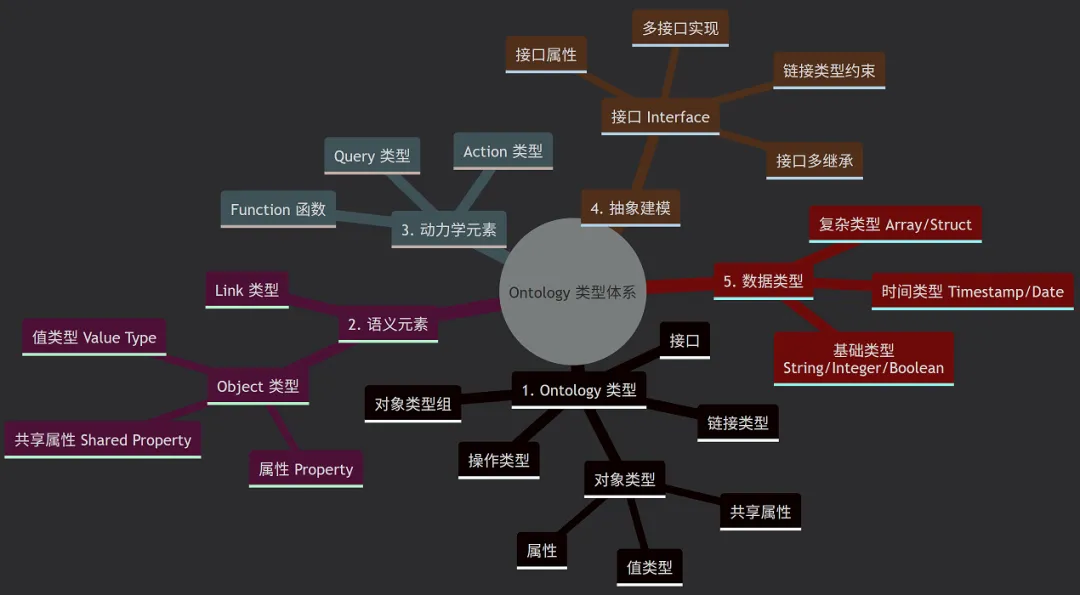
四、结语
创建 Ontology 的终极目的,并非仅仅为了管理数据或为了商业噱头。它要解决的是一个更根本的问题:如何让数字化系统真正理解企业的业务逻辑,并在此基础上,与人和 AI 一起做出实时、准确、可执行的决策,既如何让人与人、人与AI之间对齐语义。
对于一个现代企业而言,数据是“记录”,报表是“反映”,而 Ontology 则是“理解”与“行动”的交汇点。随着 Palantir AIP 的深化应用,Ontology 正在成为连接人类智慧与人工智能的“语义操作系统”。它让每一个人——无论是业务分析师、数据科学家、CTO、CEO还是AI Agent——都能用自己的语言相互无歧义的对话,从而让技术的进步真正转化为组织的竞争优势。
正如 Palantir 所定义的:“创建 Ontology,就是创建企业的数字孪生骨架。”有了这副骨架,一切数据、模型、逻辑和行动才能形成一个有机能动的躯体,企业才能真正从“数据驱动”走向“决策智能”。
Palantir Ontology的成功说明信息化建设要以整体论为主,还原论为辅,否则将会陷入迷途。

附:来源
-
Palantir 官方文档:The Ontology System
-
Palantir 开发者社区:Ontology 专题讨论
-
Palantir 博客:Ontology 深度解析系列