 夜雨聆风
夜雨聆风





传统软件测试 vs AI大模型测试 全维度深度对比
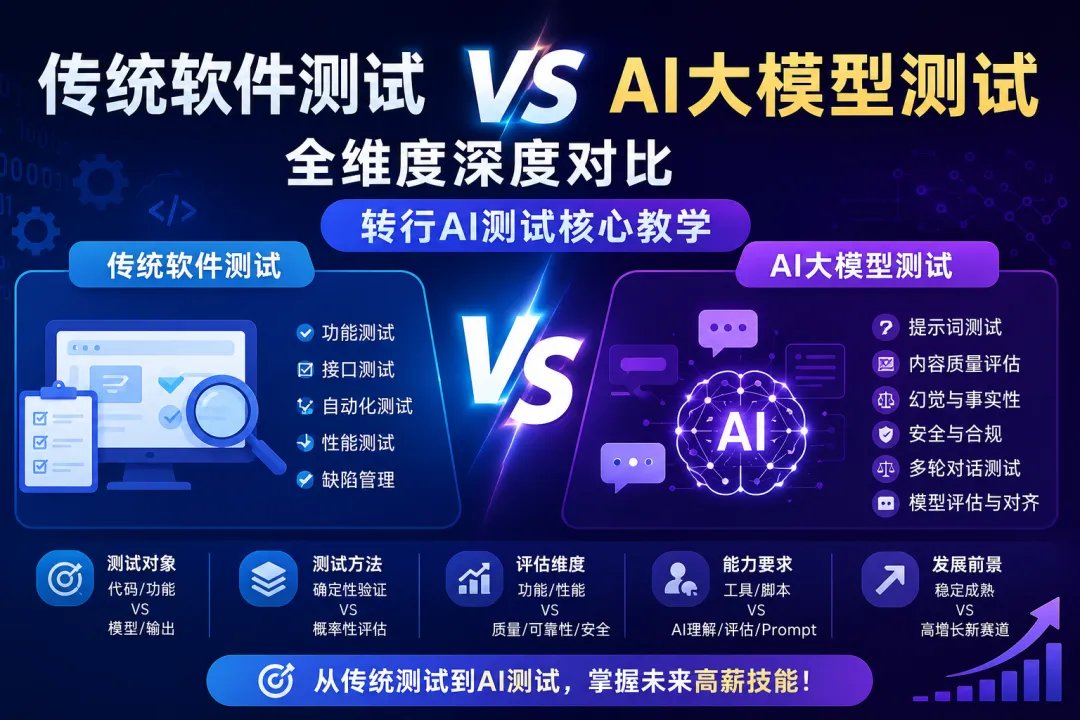
对于从传统软件测试转行AI测试的从业者来说,能否彻底理解传统测试与AI测试的核心差异,是能否通过面试、胜任岗位的核心关键。绝大多数转行面试的首轮必问、深挖追问、项目考察,全部建立在这一组差异之上。
很多转行人员的核心误区:把AI产品当成普通Web/APP产品去测,沿用固定用例、固定预期结果、固定缺陷判定逻辑,最终导致测试漏测、评判不准、无法应对AI不确定性问题。
本文将从核心本质、测试对象、预期结果、测试流程、用例设计、缺陷定义、迭代模式、性能指标、安全测试、工具体系、落地难点11个维度,系统性拆解两者差异,同时附面试标准口述答案,可直接用于面试背诵+工作落地。
一、核心本质差异:确定性系统 VS 概率性系统(最核心区别)
1. 传统软件测试:测试「确定性逻辑」
传统软件(Web、APP、后端接口、小程序)是规则驱动、代码硬编码实现的系统。
所有功能逻辑、分支判断、业务流程,都是开发人员通过代码固定写死的,输入相同、环境相同、操作相同,输出结果100%唯一、可复现、可精准预判。
示例:登录功能、下单功能、支付接口、查询列表,只要参数一致,返回结果永远一致。
传统测试的核心目标:验证代码逻辑是否符合需求文档,杜绝程序BUG、逻辑错误、异常报错。
2. AI/大模型测试:测试「概率性智能系统」
AI大模型、NLP对话、CV识别、RAG知识库问答,是数据驱动、概率生成式系统,无固定代码分支逻辑。
相同输入、相同环境、相同模型版本,每次输出结果大概率不一致,没有唯一标准答案,只有「优质答案」和「劣质答案」的区别。
示例:同一问题多次询问AI,每次话术、语序、细节都会不同;相同图片识别,偶尔出现精度偏差。
AI测试的核心目标:验证模型输出的准确性、逻辑性、安全性、鲁棒性、一致性,控制概率性风险,保证整体服务质量达标。
面试口述精简版
传统测试是对确定性代码逻辑的验证,输入固定、输出唯一,只要符合需求就是正确;AI测试是对概率性生成结果的评测,没有唯一标准答案,核心是把控输出质量、安全和稳定性。
二、测试对象与核心逻辑差异
1. 传统测试对象
人工编写的业务代码、功能模块、接口、页面交互、数据库逻辑。测试核心是业务流程、代码逻辑、交互体验。
核心特征:需求明确、逻辑固定、边界清晰、结果可控。
2. AI测试对象
预训练大模型、微调模型、向量知识库、Prompt工程、多轮上下文、推理服务、RAG检索链路。
测试核心不再是“代码对错”,而是模型能力、生成质量、知识准确度、风控能力、推理逻辑。
核心特征:无固定逻辑、依赖训练数据、结果随机、能力随版本迭代波动。
三、测试用例设计差异(转行最大难点)
1. 传统测试用例:固定、精准、全覆盖
依托等价类、边界值、场景法、错误推测法设计,每条用例都有唯一预期结果。
用例核心结构:输入步骤 + 前置条件 + 唯一预期结果。
测试标准:实际结果与预期结果一致则通过,不一致则是BUG。
2. AI测试用例:场景化、批量化、评测化
无法设计固定预期结果,用例设计逻辑彻底重构,核心从「校验结果一致」变成「校验结果质量达标」。
AI用例核心设计维度:
-
Prompt多样性覆盖:同义不同话术、长短句、口语化、书面化提问
-
边界场景覆盖:超长文本、模糊提问、无意义提问、歧义问题
-
安全场景覆盖:诱导提问、越狱提问、敏感内容试探
-
多轮上下文覆盖:多轮对话、话题跳转、上下文遗忘场景
-
知识库匹配覆盖:RAG场景下的精准问答、超纲问答、过时知识问答
AI用例无固定预期,只有评测标准:准确、完整、逻辑通顺、无幻觉、无违规、上下文一致。
四、缺陷(BUG)定义与判定差异
1. 传统测试BUG:定义绝对、无争议
凡是实际结果与需求/设计文档不一致,100%判定为BUG,判定标准统一、无争议、可精准复现。
典型BUG:页面报错、接口500、参数报错、数据错乱、功能不可用。
2. AI测试缺陷:定义相对、依赖场景、存在争议
AI没有绝对的BUG,只有劣质输出、能力缺陷、风险问题。核心判定标准:是否影响用户体验、是否产生错误引导、是否存在安全风险。
AI专属缺陷类型(传统测试完全没有):
-
模型幻觉:编造虚假数据、虚假案例、虚假结论
-
逻辑谬误:前后矛盾、推理错误、因果倒置
-
上下文遗忘:多轮对话丢失上文信息
-
知识滞后:回答内容与最新知识库不符
-
安全越狱:绕过风控输出违规内容
-
回答冗余/简略:内容不完整、废话过多
重点:AI缺陷很难100%复现,大多为概率性偶现问题,这是与传统测试最大的区别之一。
五、完整测试流程差异
1. 传统测试流程
需求评审 → 用例设计 → 用例评审 → 版本提测 → 功能执行 → 回归测试 → 上线
核心:围绕版本迭代、功能变更开展测试,无变更无需回归。
2. AI测试流程
需求评审 → 评测维度梳理 → 测试数据集/Prompt集构建 → 批量评测 → 专项测试(幻觉/安全/上下文) → 版本对比评测 → 回归评测 → 上线灰度监控
核心特点:
-
即使代码无变更、仅模型权重更新,也需要全量评测回归
-
依赖批量数据集测试,无法单条手动覆盖所有场景
-
上线后必须持续监控模型漂移、输出质量衰减
六、回归测试逻辑差异
1. 传统回归:精准回归、高效可控
迭代更新哪个功能,就回归哪个功能,用例固定、结果固定,自动化脚本可稳定复用。
2. AI回归:全量评测、防能力退化
AI模型微调、版本升级后,大概率会出现“新能力上线、旧能力退化”的问题(灾难性遗忘)。
因此AI回归不能只测新增场景,必须批量跑基准测试集,对比新旧版本的准确率、违规率、幻觉率,保证整体质量不下降。
七、性能测试指标差异
1. 传统性能指标
响应时间、TPS、QPS、并发数、CPU、内存、磁盘IO,侧重服务吞吐能力。
2. AI性能指标(专属核心指标)
除基础服务性能外,新增大量模型专属指标:
-
首字时延(TTFT):大模型流式输出首个字符的耗时(核心用户体验指标)
-
单字输出速度、总推理耗时
-
显存占用、推理算力消耗
-
批量推理吞吐量、长文本推理稳定性
八、安全测试维度差异
1. 传统安全测试
SQL注入、XSS、越权、接口篡改、密码泄露等,侧重系统和数据安全。
2. AI安全测试
在传统安全基础上,新增内容安全与模型安全,也是面试高频考点:
-
Prompt注入、恶意诱导、越狱攻击
-
模型输出涉政、色情、暴力、谣言、歧视内容
-
隐私泄露、知识库数据泄露
-
偏见输出、价值观扭曲问题
九、自动化测试差异
1. 传统自动化
脚本断言固定,判断结果相等即通过,适合稳定功能回归。
2. AI自动化
无法做固定断言,核心是智能评测自动化:通过代码批量发送Prompt,通过评测模型/RAGAS等工具,自动判断回答是否准确、是否违规、是否存在幻觉,实现批量回归。
十、迭代与风险差异
1. 传统软件风险
代码BUG、功能异常、服务崩溃、数据错误,风险点明确、可提前规避。
2. AI产品风险
模型幻觉、知识错误、价值观问题、随机劣质输出、模型漂移、能力退化,风险隐蔽性强、概率触发、无法彻底根除,只能持续优化和风控拦截。
十一、总结:转行AI测试的核心认知升级
从传统测试转AI测试,不是替换工具,而是替换思维:
1. 从「找代码BUG」升级为「评测模型质量、控制智能输出风险」;
2. 从「固定预期用例」升级为「场景化、批量化、基准化评测」;
3. 从「可复现、绝对判定」升级为「概率性、相对性、对比式质量判定」;
4. 从「功能迭代测试」升级为「模型版本质量守护、防止能力退化」。
附:面试满分口述总结(直接背诵)
传统测试针对确定性代码系统,输入固定、输出唯一,测试核心是校验功能逻辑是否符合需求,BUG可精准复现、判定标准绝对;而AI测试针对概率性生成式大模型,无固定输出、无唯一标准答案,核心是评测模型输出的准确性、逻辑性、安全性和鲁棒性。在用例设计、缺陷判定、回归策略、性能指标、安全维度上都和传统测试有本质区别,AI测试更侧重批量评测、版本对比、风险把控和持续质量监控。