 夜雨聆风
夜雨聆风





AI圣经04 《word2vec:词,是怎么变成向量的》

📚 AI 圣经 · 系列导览这是「AI 圣经」系列第 04 篇。我会带你逐篇精读撑起今天所有大模型的 21 篇经典论文,分 5 个阶段层层递进(本篇已高亮):
- 阶段一 · 地基
:P01《Attention Is All You Need》 · P02 Bahdanau Attention · P03 seq2seq · P04 word2vec · 本篇 - 阶段二 · 预训练范式
:P05 BERT · P06 GPT-1 · P07 GPT-2 · P08 GPT-3 · P09 T5 - 阶段三 · 规模与效率
:P10 Scaling Laws · P11 Chinchilla · P12 LoRA · P13 FlashAttention · P14 MoE - 阶段四 · 对齐与推理
:P15 InstructGPT(RLHF)· P16 思维链 CoT · P17 DPO · P18 Constitutional AI - 阶段五 · 检索与 Agent
:P19 RAG · P20 ReAct · P21 Toolformer
本篇论文:《Efficient Estimation of Word Representations in Vector Space》· Mikolov, Chen, Corrado, Dean 2013。地址 arXiv:1301.3781(arxiv.org/abs/1301.3781)。其余各篇论文地址,随当期文章给出。
太长不读计算机不认识字,只认识数字。word2vec(2013)的办法是:让一个词的意思「藏」在它周围常一起出现的词里,再用一个极简单的小网络,把每个词压成一串几百位的数字(一个「向量」)。意思相近的词,数字也相近——近到「国王−男人+女人」算出来的那串数字,最接近「王后」。它没发明词向量这个想法,但第一次让它便宜到能在 16 亿词的语料上「不到一天」跑完,从此成了今天 AI 搜索、推荐、RAG 的共同地基。
上篇回顾 · 先答一题上一篇 seq2seq,我们说它把「整句话」压成一个「思想向量」交给解码器去翻译。那么往下挖一层:句子是由词组成的,单个词又是怎么变成向量、让机器能「算」它的意思的?有意思的是,回答这个更底层问题的论文(word2vec, 2013),其实比 seq2seq(2014)还早一年。这一篇,我们就回头补上这块地基。
01在计算机眼里,每个词都是一座孤岛

先想一个最朴素的问题:计算机怎么「存」一个词?
最老实的办法叫 one-hot(独热编码——给每个词发一个专属编号,这个词那一位是 1、其余全是 0)。假设词典里有 5 万个词,「猫」是第 372 号,那「猫」就是一串 5 万位、只有第 372 位是 1 的数字;「狗」是第 8211 号。问题来了:在这种表示里,「猫」和「狗」的距离,跟「猫」和「混凝土」的距离完全一样——每个词都是一座孤岛,机器看不出「猫」和「狗」更像。
更要命的是,当时已有的解法很贵。2013 年前,主流的神经网络语言模型(NNLM、RNNLM)确实能学出带语义的词向量,但它们都带一个非线性隐藏层,算起来极慢——论文里提到,那类模型当时只能在「几亿词、向量维度 50 到 100」这个规模里打转,再大就跑不动了。
word2vec 这篇论文,冲的就是「又好又便宜」:它在摘要里直接放话——用一个新架构,从 16 亿(1.6 billion)词的语料里学出高质量词向量,用时不到一天。在 2013 年,这是个夸张的数字。
02一个词的意思,藏在它身边的词里

word2vec 靠什么把词从「孤岛」连成「地图」?靠语言学里的一句老话:看一个词跟哪些词做伴,就知道它什么意思。
「猫」周围常出现「喵」「抓」「鱼」「宠物」,「狗」周围常出现「汪」「咬」「骨头」「宠物」——它们的邻居高度重合,所以意思相近;「混凝土」的邻居是「钢筋」「浇筑」「工地」,跟前两者几乎不沾边。于是,只要让机器去学「每个词的邻居长什么样」,意思相近的词自然会被放到相近的位置上。
这就是词向量的核心直觉:把每个词放进一个几百维的连续空间里(论文主实验用 300 维),训练目标就是让「邻居像」的词坐标也靠得近。训练完,你得到的不是一个编号,而是一串能比远近、甚至能做加减法的坐标。
word2vec 最出圈的画面,就是这种加减法:「国王」−「男人」+「女人」,算出来的那串数字,最接近「王后」。这里要说句老实话:king−man+woman≈queen 这个著名例子,最早出自同一批作者同年的姊妹论文(NAACL 2013《Linguistic Regularities》),本篇只是把它当「已知现象」引用了一下。本篇真正的贡献,不在于发现这个魔法,而在于——让算出这种词向量的成本,降到人人跑得起。
03两个互为镜像的小模型:CBOW 和 Skip-gram

怎么做到「又快又便宜」?答案简单到有点反直觉:把贵的那层砍掉。前人模型慢,慢在那个非线性隐藏层;word2vec 干脆不要它,只留一个最薄的结构。砍完之后,论文给了两个互为镜像的训练法:
- CBOW(连续词袋)
:用周围的词猜中间这个词。比如挖空「今天天气真□」,让模型根据「今天/天气/真」猜出「好」。论文里它一次看「前 4 个 + 后 4 个」共 8 个邻居;因为是把邻居向量平均、不管谁先谁后,所以叫「词袋」。 - Skip-gram
:反过来,用中间这个词猜周围的词。给「好」,让模型预测它周围可能是「今天/天气/真/呀」。

一句话记区别:CBOW 是「完形填空」,Skip-gram 是「由一个词联想一圈词」。直觉上 CBOW 更快、在常见词上稳,Skip-gram 慢一些但在生僻词和语义关系上更强(下一节的数据会印证)。它们都没有隐藏层,所以快得惊人:论文里 CBOW 在 Google News 数据上训练约一天、Skip-gram 约三天;作为对照,此前一个 RNNLM 在单核 CPU 上要跑大约八周。
04它真的学懂了吗:向量会做加减法,又快又准
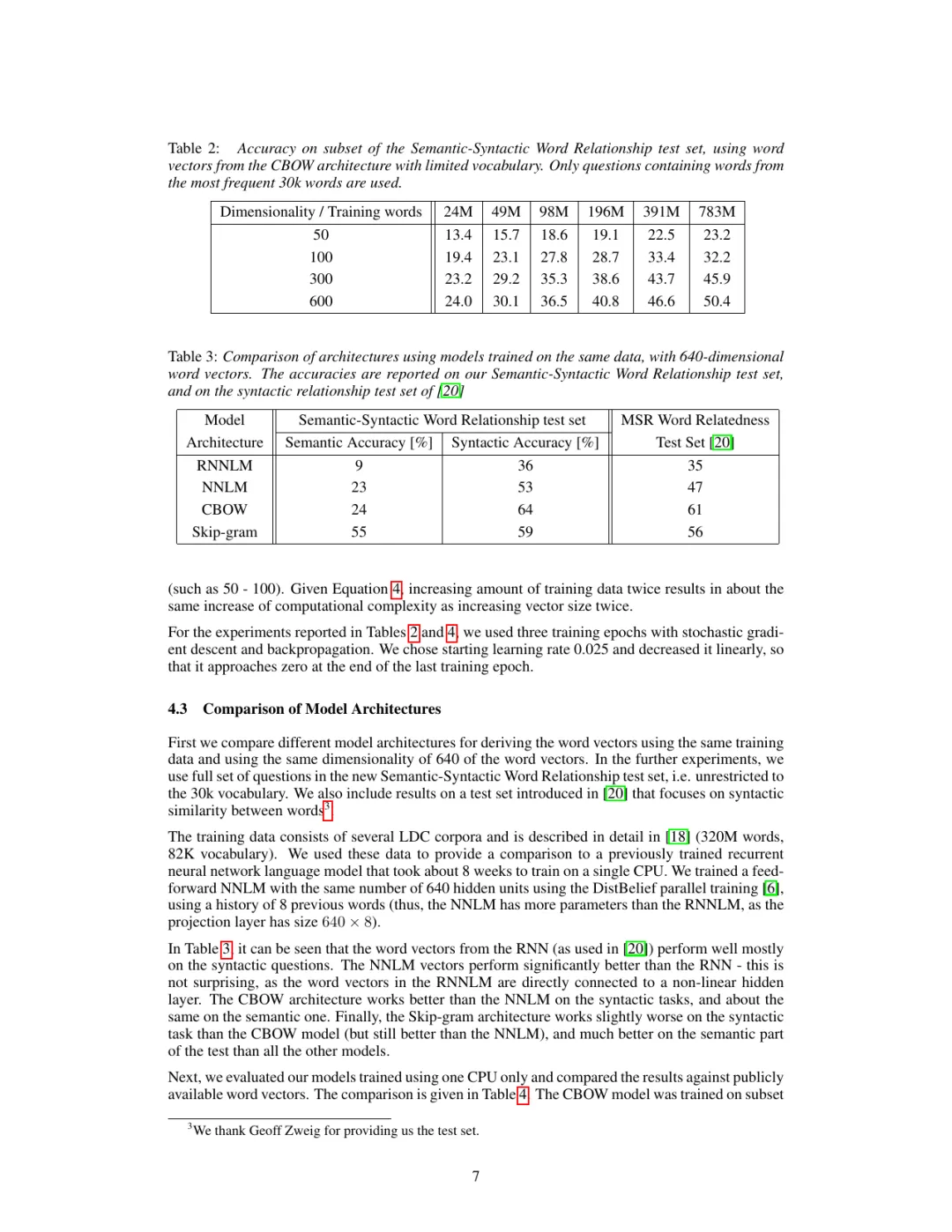
「意思近坐标近」听着玄,怎么验证机器是真懂还是装懂?作者做了件硬核的事:造了一套约 1.95 万道题的考卷(8869 道语义题 + 10675 道句法题,分 5 类语义关系 + 9 类句法关系)。
题目长这样:「北京之于中国,相当于东京之于( )」「大之于最大,相当于小之于( )」。机器答题的方式,就是做那个向量加减法——向量(东京) − 向量(中国) + 向量(北京),看算出来的坐标最接近哪个词。必须一字不差命中才算对(答个近义词都算错),所以这卷子很严。
结果很说明问题(同样数据、同样 640 维下):老的 RNNLM 语义题只对 9%、句法题 36%;NNLM 语义 23%、句法 53%;CBOW 语义 24%、句法 64%(句法最强);Skip-gram 语义 55%、句法 59%——语义理解上把其他模型甩开一大截。

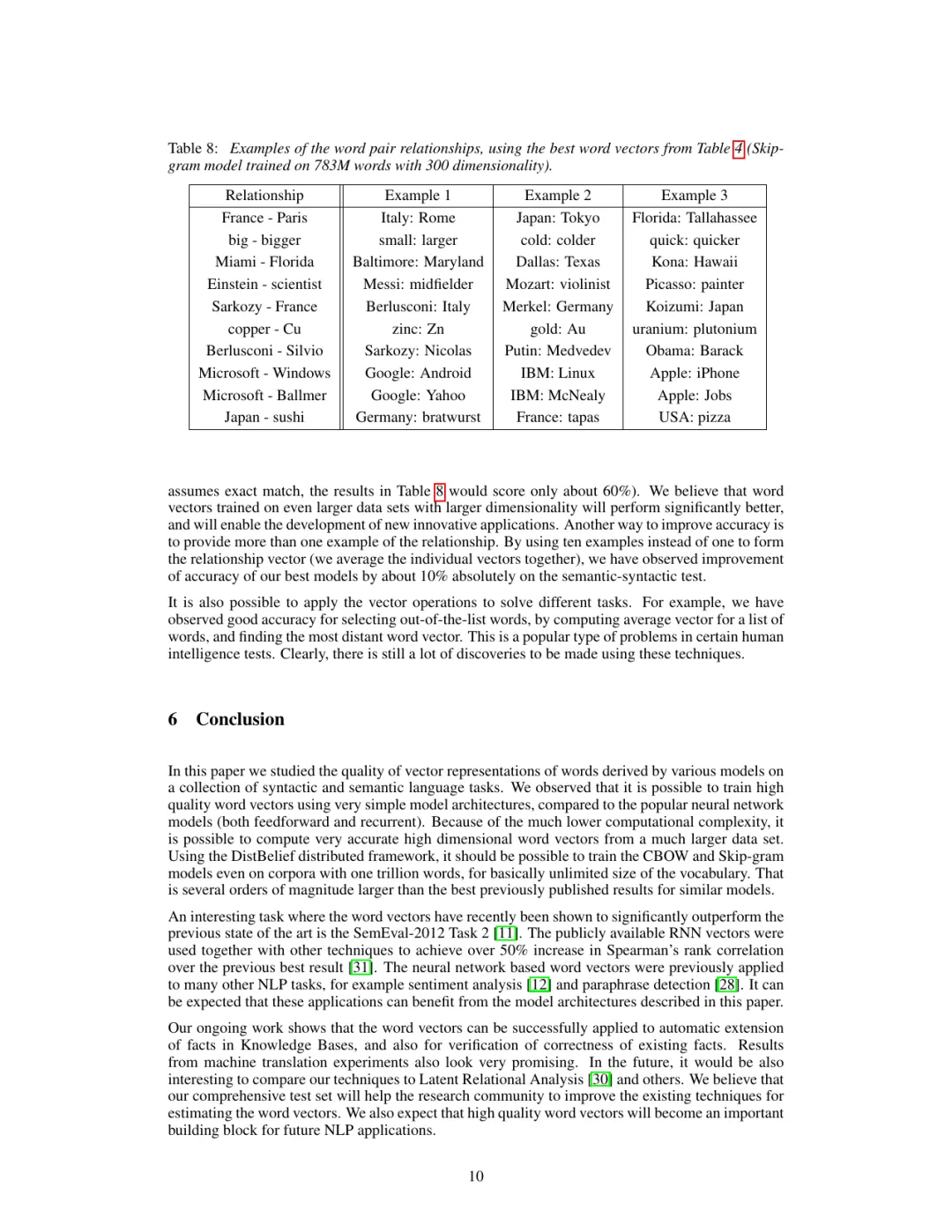
论文里它自己跑出来的招牌例子,是 biggest − big + small = smallest 和 Paris − France + Italy = Rome。也就是说,这串数字不只「记住」了词,还在没人教语法的情况下,自己学会了「首都—国家」「比较级—原级」这类关系——而且这些关系在空间里是同一个方向的平移。这是 word2vec 最惊艳的地方:没人告诉它什么叫首都,它从「谁和谁做伴」里自己长出了这个概念。
05从一串数字,到今天所有 AI 搜索的地基
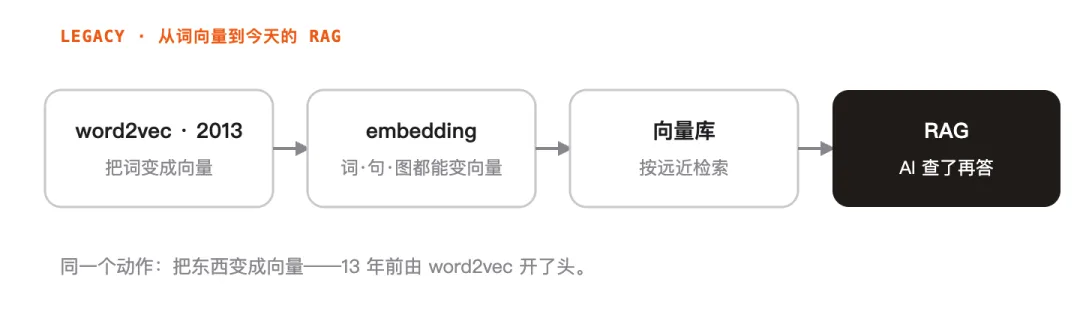
word2vec 的真正分量,不在它当年那几个百分点,而在它把「把东西变成向量」这件事变成了基础设施。
论文结尾就预言了用途:机器翻译、信息检索、问答系统。而这套思路后来被推广成一个更大的词——embedding(嵌入:把词、句子、整段文档、甚至图片,都「嵌」进同一个连续向量空间的统称)。词向量,是 embedding 这个大家族里最早、最经典的那一个。
这跟今天有什么关系?关系大了。现在最火的 RAG(检索增强生成——让 AI 先去资料库里查相关内容、再据此回答),第一步就是把每段文字算成向量、存进向量库,提问时再用向量的远近找出最相关的段落。最近就有人用 AI 把自己 500 多条飞书会议纪要全部向量化,做出懂自己偏好的个性化推荐;甚至有项目(PixelRAG)连网页截图都直接转成向量来检索——「万物皆可 embedding」的范式还在扩张,而它的起点,就是 13 年前这篇教机器「把词变成向量」的论文。
你每天用的 AI 搜索能搜到意思相近而不只是字面相同的结果、推荐系统能猜你喜欢、聊天机器人能听懂近义词——往下刨到底,都站在 word2vec 立的这块地基上。
✎读完自测:先别往下翻,试着答
主动回忆一遍才记得住(这点「小难度」是故意的)。三问,想好再看答案:
-
1. one-hot 编码最大的毛病是什么?word2vec 怎么解决它? -
2. CBOW 和 Skip-gram 的区别是什么? -
3. word2vec 凭什么比之前的模型快那么多?
答案1. one-hot 给每个词一个孤立编号,任意两个词的距离都相等,机器看不出「猫」和「狗」更像;word2vec 让「邻居相似」的词坐标也相近,于是意思相近的词在空间里离得近、还能比远近。2. CBOW 用周围的词猜中间词(完形填空),Skip-gram 用中间词猜周围的词(由一词联想一圈);CBOW 更快,Skip-gram 在语义和生僻词上更强。3. 它砍掉了前人模型里那个又贵又慢的非线性隐藏层,只留最薄的结构,于是能在 16 亿词的语料上「不到一天」跑完。
→一句话带走,和下一步
只记一句:word2vec 用「一个词的意思藏在邻居里」这个朴素直觉,加一个砍到最薄的小网络,第一次让「把词变成向量」变得又快又好,从此词向量(embedding)成了今天 AI 搜索、推荐、RAG 的共同地基。
到这里,「AI 圣经」系列的阶段一 · 地基就铺完了:从 Transformer(P01)、注意力的起源(P02)、seq2seq 的骨架(P03),到这一篇 word2vec 把最小的砖块——「词」——也变成了机器能算的向量。下一站我们进阶段二 · 预训练范式,看 BERT 和 GPT 是怎么在这块地基上盖起摩天大楼的。
想再深入一点荐读一个最优源:Jay Alammar 的图解博客《The Illustrated Word2vec》(jalammar.github.io),全程用图讲 Skip-gram,比论文好读得多。
互动钩子:你觉得「词的意思真的能被一串数字装下」吗?欢迎在评论区聊聊。